

🍹 Insight Daily 🪺
Aitrainee | 公众号:AI进修生
腾讯混元联合腾讯音乐,搞了个新模型 HunyuanVideo-Avatar,能让照片直接“活”过来。
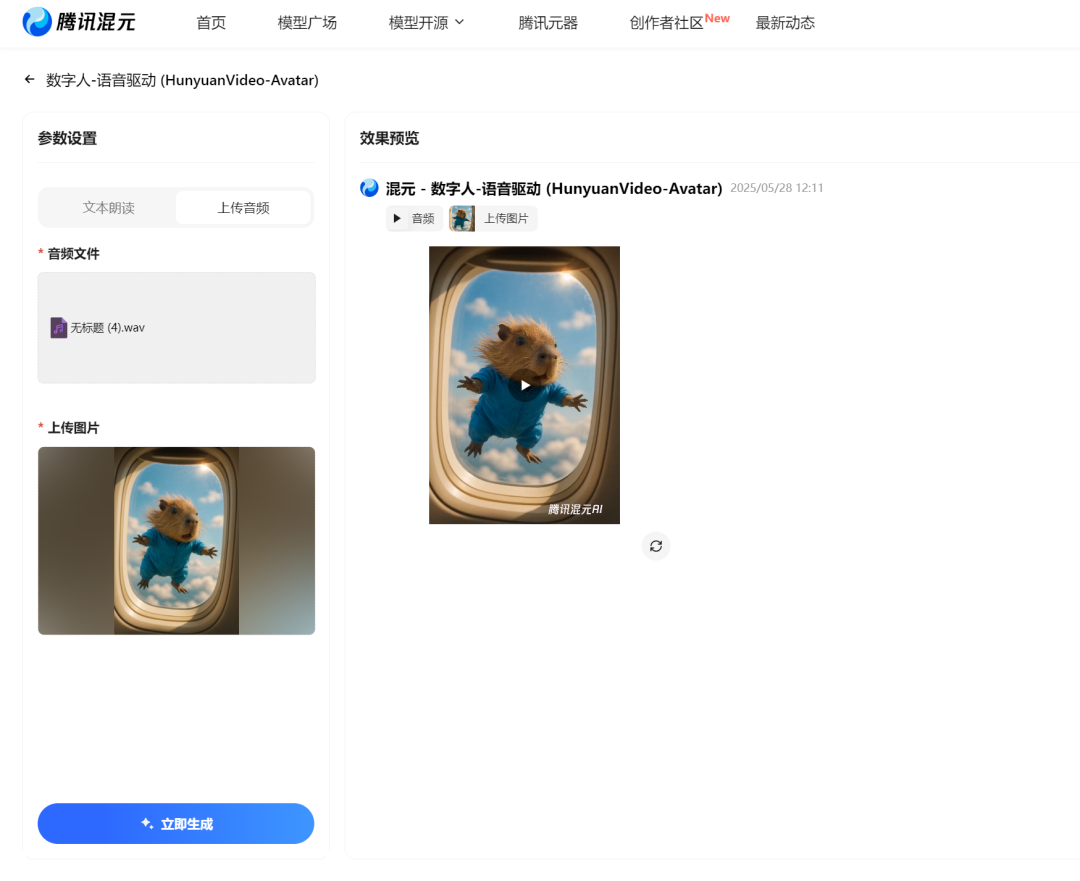

项目主页: https://hunyuanvideo-avatar.github.io Hugging Face 模型: https://huggingface.co/tencent/HunyuanVideo-Avatar GitHub 代码: https://github.com/Tencent-Hunyuan/HunyuanVideo-Avatar 在线体验: https://hunyuan.tencent.com/modelSquare/home/play?modelId=126 技术报告 (arXiv): https://arxiv.org/pdf/2505.20156
想让视频 动作丰富 吧,角色的形象又容易崩 。角色的 情绪 跟音频里的情绪,老是对不上号 。多个人一起说话 的场景,基本搞不定。
角色图像注入模块 (Character Image Injection Module): 以前很多方法是直接把参考图的特征加到视频里,这样虽然能保证形象一致,但动作就僵硬了。而且训练和推理的时候,条件容易不匹配。 HunyuanVideo-Avatar 这个新模块,换了一种方式注入角色特征(沿着通道维度注入,避免了直接在潜空间操作带来的动态性和一致性的权衡),目标是既能让动作流畅自然,又能牢牢锁住角色的样子。 他们对比了三种注入方式(Token Concat, Token Concat + Channel Concat, 以及他们自己的方法),发现他们的方法效果最好。 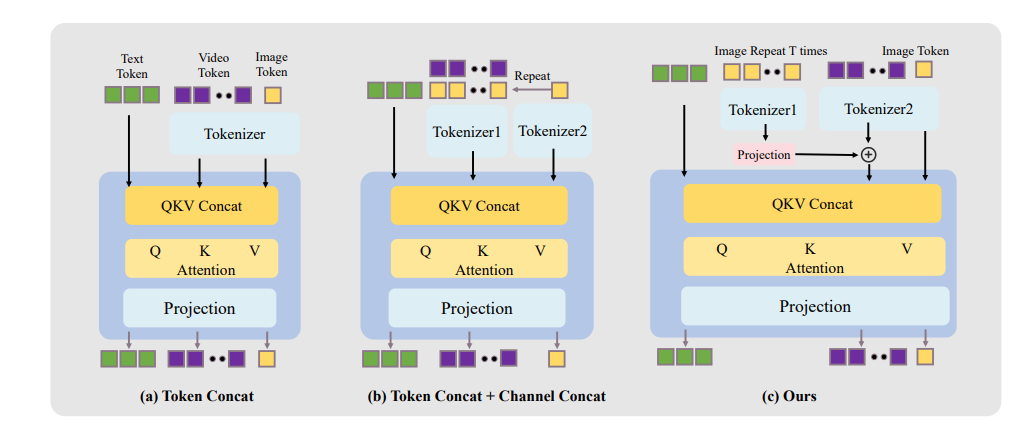
音频情绪模块 (Audio Emotion Module, AEM): 为了让角色的表情能跟音频里的情绪对上,他们搞了这个模块。它能从一张带有情绪参考的图片里提取情绪线索,然后把这些线索“传递”到生成的视频里。 这样,就能更精细地控制角色的情绪风格,让表情更真实。他们发现,把这个模块插到模型的 Double Block 里效果最好,能更好地捕捉和表达情绪细节。 面部感知音频适配器 (Face-Aware Audio Adapter, FAA): 多角色场景下,怎么让不同的人根据不同的音频说话,这是个大难题。FAA 就是干这个的。 它会在潜空间层面,用面部掩码把需要被音频驱动的角色“框”出来,然后通过交叉注意力机制,只把对应的音频信息注入到这个特定角色的面部区域。 这样,就能独立控制不同角色的口型和表情,实现更逼真的多角色对话效果。
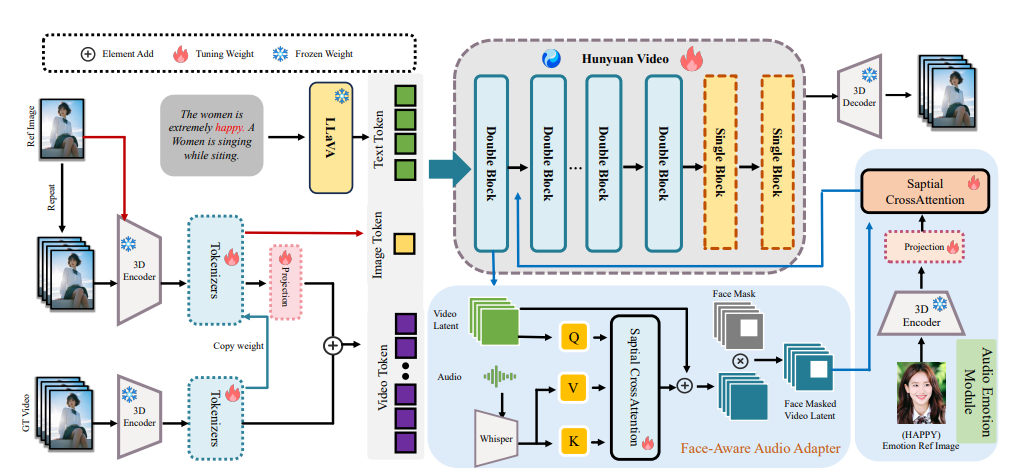
▲ 整体框架图
https://github.com/Tencent-Hunyuan/HunyuanVideo-Avatar
点这里👇关注我,记得标星哦~
(文:AI进修生)