


日前,全球权威大模型公开竞技场-Chatbot Arena评测榜单公布最新排名,腾讯混元旗舰大语言模型TurboS位列全球第7,在国内大模型中仅次于Deepseek。放眼国际,排在前面的也仅有谷歌Gemini、 OpenAI 以及xAI三家国际顶级机构。腾讯混元基础模型为什么能够取得这么亮眼的成绩?在技术上有哪些创新?答案就藏在最新发布的腾讯混元TurboS技术报告中。
随着大型语言模型(LLM)的飞速发展,模型能力与效率的平衡成为了前沿研究的关键议题。腾讯混元团队最新推出的混元TurboS模型,是一款新颖的超大型Hybrid Transformer-Mamba架构MoE模型。该模型通过Mamba架构在长序列处理上的卓越效率与Transformer架构在上下文理解上的固有优势的有机协同,实现了性能与效率的精妙平衡。
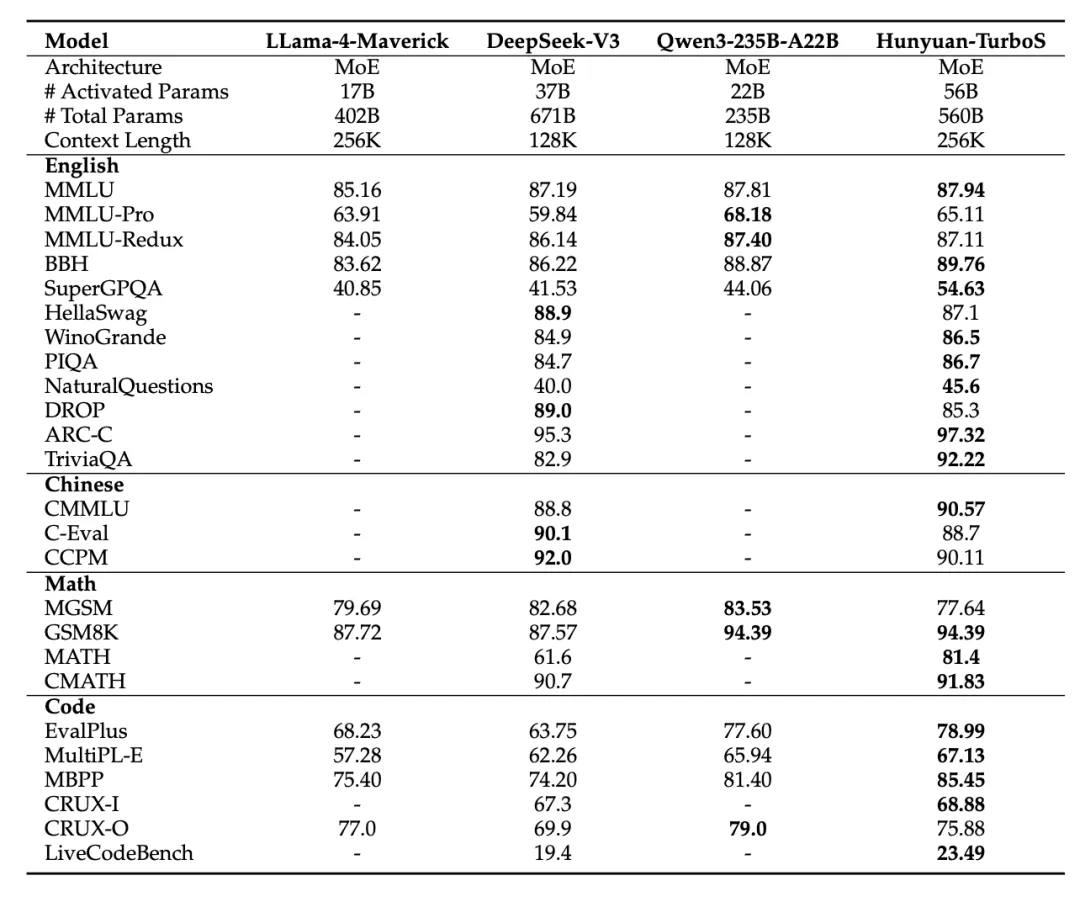
混元TurboS引入了创新的自适应长短思维链机制,能够根据问题复杂度动态切换快速响应模式与深度思考模式,从而优化计算资源分配。更重要的是,其模型激活参数达到了56B(总参数560B),是业界首个大规模部署的Transformer-Mamba专家混合(MoE)模型。
架构创新以及参数量的保证,让模型效果进步明显,国际最权威的大模型评测榜单LMSYS Chatbot Arena最新排名显示: 混元TurboS取得了整体1356的高分,在所有239个参赛模型中位列全球前7名。
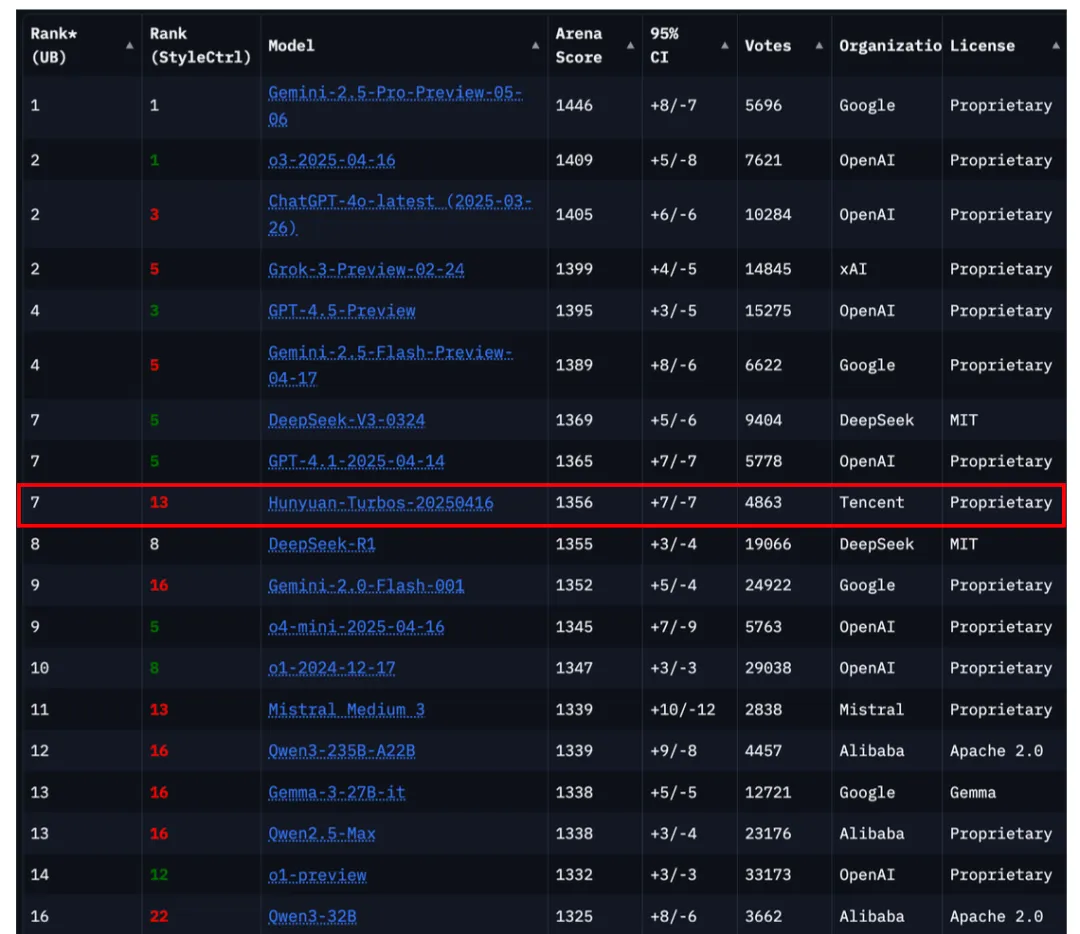
图:截自Chatbot Arena官网5 月 18 日排名
多语种能力方面表现突出,中文、法语、西班牙语并列排名全球第一,韩文排名全球第二。

以下,通过模型技术报告我们将逐一解开腾讯混元Turbo S的神秘面纱。
腾讯混元TurboS的核心创新体现在以下几个方面:
架构协同:巧妙地融合了Mamba架构处理长序列的高效性与Transformer架构卓越的上下文理解能力。这两种架构的结合,旨在取长补短,实现性能与效率的最大化。模型包含128层,采用了创新的“AMF”(Attention → Mamba2 → FFN)和“MF”(Mamba2 → FFN)模块交错模式。这种设计使得模型在拥有5600亿总参数(56B激活参数)的同时,保持了较高的运算效率。
自适应思维链 (Adaptive Long-short CoT):该机制是Hunyuan-TurboS的一大亮点。它借鉴了短思维链模型(如GPT-4o)的快速响应和计算友好特性,以及长思维链模型(如o3)强大的复杂推理能力。面对简单问题,TurboS自动激活“无思考”(no thinking)模式,以最小计算成本提供足够质量的答案;而当遇到复杂问题时,则自动切换至“思考”(thinking)模式,运用逐步分析、自我反思和回溯等深度推理方法,给出高准确度的回答。
先进的后训练策略:为了进一步增强模型能力,腾讯混元团队设计了包含四个关键模块的后训练流程:
1、监督微调(SFT):通过精心构建的百万级自然和合成指令数据进行微调。
2、自适应长短CoT融合:通过专门训练的教师模型和独特的强化学习框架,实现推理策略的自主选择、计算资源的有效分配,并通过无损压缩和重构长思维链来提升响应的可读性。
3、多轮推敲学习(Multi-round Deliberation Learning):SFT模型在模拟评估环境中与其他先进混元模型进行比较,通过多LLM裁判组和人类专家的评估驱动迭代优化。
4、两阶段大规模强化学习:利用GRPO,第一阶段聚焦于提升推理能力,第二阶段则致力于改善全领域的通用指令遵循能力。
本节将详细介绍预训练数据的处理、创新的模型架构设计,以及退火(Annealing)和长上下文预训练策略。

预训练数据的质量、数量和多样性对LLM的性能至关重要。相较于先前的混元Large模型,腾讯混元TurboS在数据处理上进行了显著增强。团队开发了全面的评估模型和数据混合模型,引入了包含数十个结构化领域标签的基础质量标准,确保了数据选择和整合的原则性。最终,腾讯混元TurboS在包含16万亿Token的语料上进行训练。
模型架构

混元TurboS的核心是一种混合架构,整合了Transformer、Mamba2和FFN组件,旨在实现训练和推理的效率与可扩展性。
1、宏观参数:模型总层数为128层,激活参数量56B,总参数量560B。其中,每个Attention、FFN、Mamba2块计为一层。
2、层级构成:FFN层占比50%,Attention层占比约5.5%,Mamba2层占比约44.5%。FFN层采用MoE结构,包含1个共享专家和32个专门专家,每个前向传播激活1个共享专家和2个专门专家。Mamba2层采用状态空间模型(SSM)架构,实现了序列长度的线性复杂度O(n)。
3、模块模式:“AMF”(Attention→Mamba2→FFN)被确认为一种优化的原子配置,有效平衡了效率。同时,结构中也采用了“MF”(Mamba2→FFN)模块以进一步提升效率。Hunyuan-TurboS采用了“AMF”和“MF”模块的交错架构。
退火阶段 (Annealing)
退火阶段的数据是异构混合的,包括高质量预训练数据、代码、数学、STEM相关语料、指令遵循数据(如长CoT数据)和其他合成样本。
长上下文扩展
预训练的最后阶段,采用课程学习策略逐步扩展模型的上下文窗口,从4K Tokens扩展到32K,最终到256K Tokens。
预训练模型评估
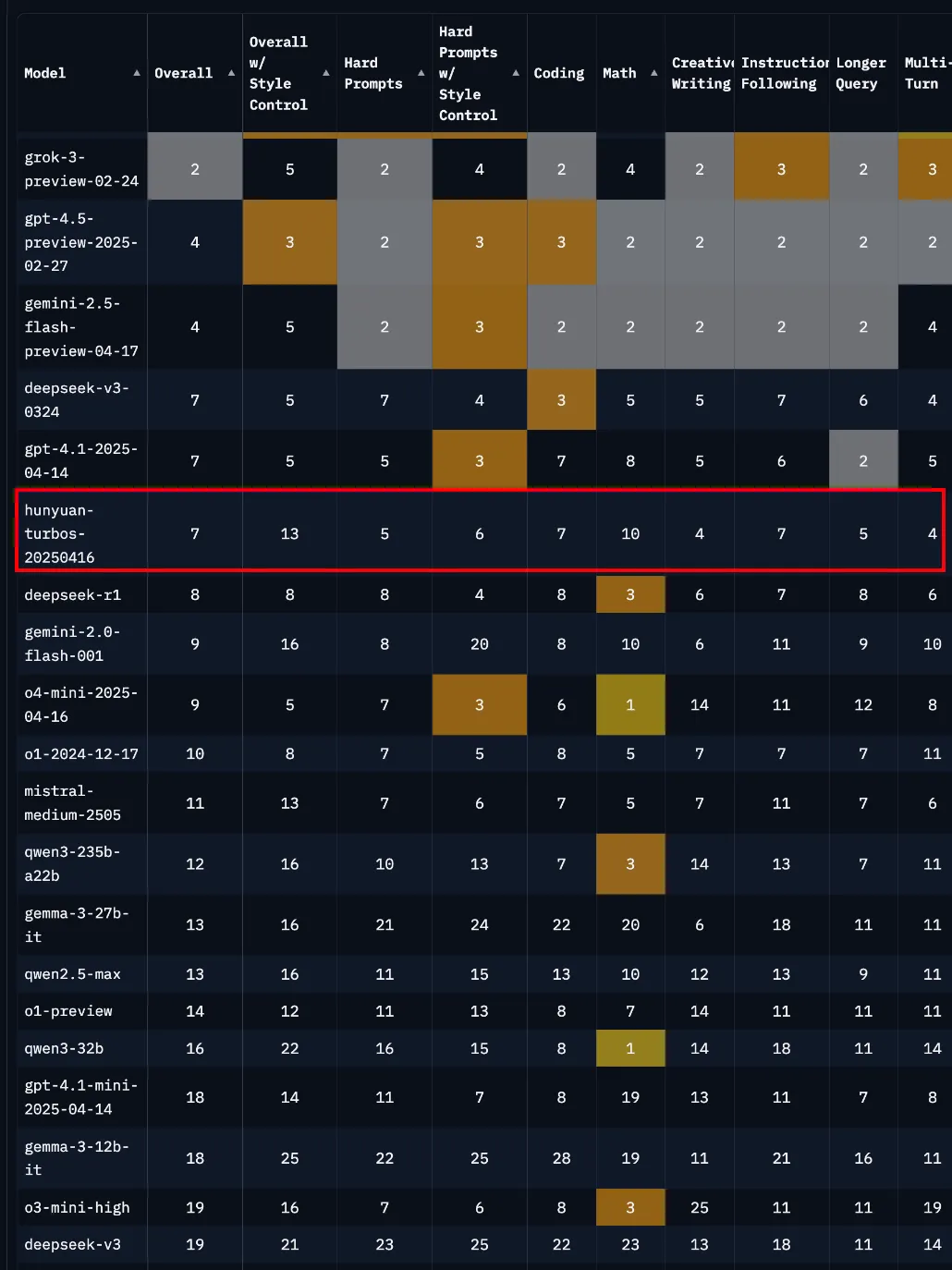
在23个广泛使用的基准上对预训练的腾讯混元TurboS进行了评估,结果显示其与SOTA模型相比具有强大的基础能力。
 注:表格中,其它模型的评测指标来自官方评测结果,官方评测结果中不包含部分来自混元内部评测平台
注:表格中,其它模型的评测指标来自官方评测结果,官方评测结果中不包含部分来自混元内部评测平台
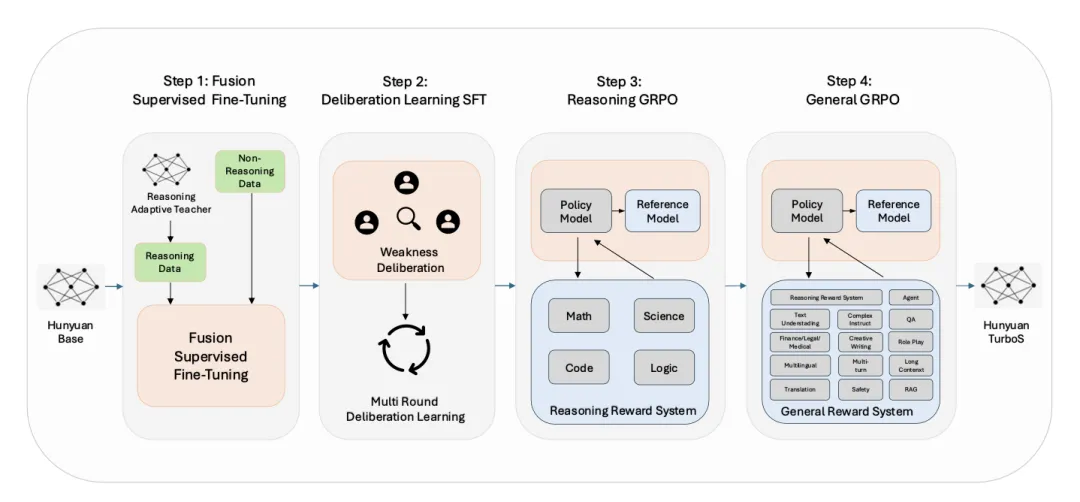
1、监督微调 (SFT)
SFT数据的质量和多样性对LLM在各类任务上的表现至关重要。混元TurboS的SFT数据被细致地划分为多个主题,为每个主题收集高质量样本并整合。
数据来源与构建
涵盖数学(教材、考试、竞赛)、代码(开源仓库代码片段转为指令对)、逻辑(公共/授权数据源,自动化合成)、科学(物理、化学、生物)、语言中心任务(理解、翻译、生成)、创意写作、英文及多语言、复杂指令、角色扮演、知识问答、多轮对话、金融/法律/医学以及安全等13个领域。
最终构建了百万级样本的SFT数据集(包含推理型和非推理型数据)。其中,需要较长CoT的复杂推理任务(数学、代码、科学、逻辑)会经过额外处理,采用内部教师模型,生成自适应长短CoT响应。非推理型数据则直接使用原始响应。
2、 自适应长短思维链融合 (Adaptive Long-short CoT Fusion)
该方法旨在让LLM能够根据问题复杂度自主决定使用长CoT还是短CoT,以及推理的深度,创造性地将两种推理模式融合进单一模型。先前研究表明长CoT在数学等推理领域特别有效,因此该方法主要应用于推理数据(数学、STEM等),而非推理数据主要使用短CoT模式。团队训练了一个自适应长短CoT融合教师模型,其训练分为两阶段:
自适应长短CoT SFT训练
首先,使用推理数据训练Hunyuan-Base得到一个短CoT模型。
然后,用此短CoT模型对所有推理数据进行推理并进行一致性检查。若短CoT模型回答正确,则直接作为训练样本。
若首次尝试错误,则将问题和短CoT的错误响应输入混元-T1(混元长链推理模型)继续生成后续推理过程和答案,并将此扩展的推理过程和答案转换为短CoT的响应风格。
重复此混元-T1生成过程,直至获得正确答案。
最后,将所有失败尝试与正确响应拼接,作为自适应长短融合教师模型的训练响应。用此数据训练Hunyuan-Base,得到自适应SFT模型。
自适应长短CoT的强化学习
此长短自适应奖励框架使LLM能根据问题难度选择合适的思考模式。
难度自适应奖励:在GRPO采样期间,为每个提示生成不同推理深度的响应。在线拒绝采样机制评估提示难度并选择合适的模式——复杂问题分配长CoT,简单问题分配短CoT。
长CoT压缩奖励:对于长推理链,在计算奖励时应用长度惩罚。当多条推理路径达到相同正确性时,较短的路径获得更高奖励,从而在保持准确性的同时最小化冗余。
3、推敲学习 (Deliberation Learning)
为进一步提升混元-TurboS的能力,团队提出了一种基于“反思学习”原则的人机协作迭代优化策略。该方法利用一个“数据飞轮”,模型通过相互竞争逐步改进,由强大的基于LLM的裁判和人类专家识别弱点,为后续SFT迭代提供信息。
训练强大的裁判LLM模拟人类标注者
基于腾讯混元TurboS开发和训练了一组裁判模型(Judge Models)。响应评估不依赖单一整体评分,而是跨多个预定义维度(准确性、有用性、无害性、连贯性、简洁性、指令遵循度)。每个裁判对成对比较提供维度评分和文本解释。通过多数投票或加权评分系统等共识机制聚合这些多维判断。
构建数据飞轮后训练腾讯混元TurboS
核心是一个通过竞争性评估和有针对性的SFT持续增强混元-TurboS能力的迭代改进循环。
裁判(Judging):使用混元-TurboS SFT模型和混元系列其他前沿模型(混元 Large, 混元 Turbo, 混元 T1)对精选训练集中的相同提示生成响应,然后由多LLM裁判组进行细致评估。
弱点推敲(Weakness Deliberation):通过人类专家和LLM监督识别模型弱点。领域专家审查复杂的比较结果和自动化系统可能遗漏的细微模型失败。
迭代SFT(Iterative SFT):根据弱点画像,为已识别的缺陷开发定制的训练批次,通常包含“失败数据”。这些数据由人类专家用高质量输出仔细标注,并增量添加到训练过程中。采用课程学习,随着模型掌握程度的提高逐步增加任务复杂度和技巧的微妙性。
为实现有效的强化学习,设计了一个围绕三个关键组件组织的通用奖励系统。
带参考答案的生成式奖励模型 (GRM)
比较候选答案与参考答案。对确定性解的任务(如闭卷问答),参考答案是真实答案;对开放式任务(如创意写作),提供精心策划的参考,GRM将其视为语义锚点而非精确匹配。GRM使用成对偏好方案训练。
答案一致性模型
轻量级分类器,验证生成答案是否与参考答案匹配(匹配为1,否则为0),用于数学等有标准答案的任务。
代码沙箱 (Sandbox)
支持36种编程语言的多语言代码沙箱,用于执行单元测试。
奖励聚合模块
整合特定领域规则产生统一评分,系统总共覆盖16个子主题和超过30个评分服务。
采用基于GRPO框架的增量式、领域聚焦的RL流程。这是一个两阶段策略:
两阶段GRPO训练策略
阶段一:推理GRPO。目标是逻辑、编码、数学和科学领域。混合30万训练数据(代码:数学:逻辑&科学 = 2:2:1)。由于SFT主干模型在这些任务上已表现强劲且输出熵较低,因此应用相对较小的KL散度约束以鼓励更广泛的探索。
阶段二:通用GRPO。优化扩展到通用任务,重点是平衡各领域性能。继续包含10%来自阶段一的推理数据。阶段一的超参数(如裁剪范围、学习率)基本保留,但增加KL散度惩罚系数以缓解灾难性遗忘。
*更多GRPO实施细节:
-
GRPO损失:在Token级别重新制定GRPO损失,显著提高KL稳定性。
-
提示过滤:过滤掉模型总是成功或失败的极端案例,保留不稳定的提示(模型采样输出差异大)作为理想的对抗样本。
-
采样:RL期间生成响应的采样温度设为1.0。较低温度会导致熵快速衰减,阻碍探索。
-
组奖励调整:对每个提示的响应组内重新缩放奖励,确保不良响应获得负优势,良好响应获得正优势,从而促进稳定的策略更新。
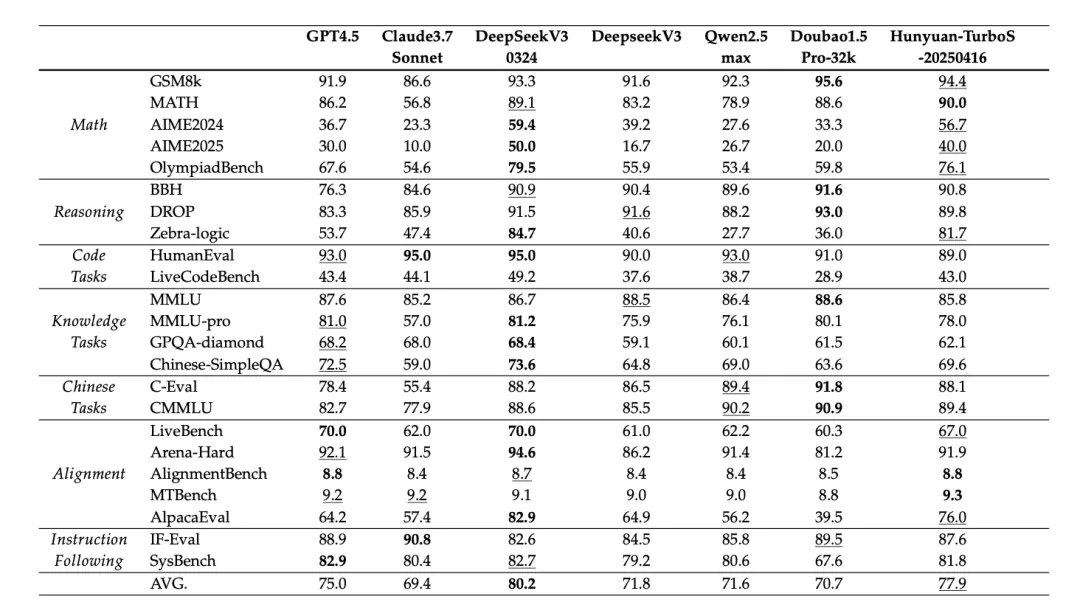
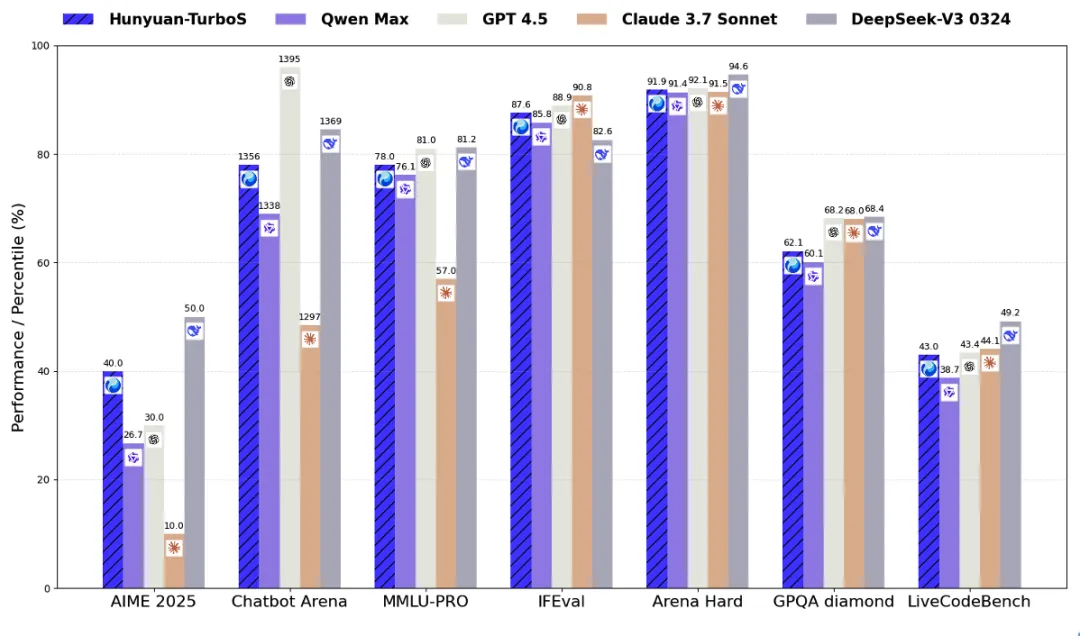
与业界领先的开源和闭源模型在关键基准上进行对比:
● 数学推理:在非推理模型中表现SOTA,仅次于DeepSeek-v3-0324。
● 逻辑推理:在BBH、DROP、Zebra-Logic等复杂基准上,与DeepSeek-V3-0324共同树立了新的性能标杆。
● 代码任务:与Qwen2.5-Max能力相当。
● 知识与中文任务:在知识密集型任务中表现SOTA,尤其在中文知识评估(C-Eval, CMMLU, C-SimpleQA)上表现强劲。
● 对齐任务:在AlpacaEval上平均得分比GPT-4.5高11.8分,在AlignmentBench和MTBench评估中均排名第一。
● 指令遵循:与Claude3.7和GPT-4.5相当。
自适应CoT的推理效率
在评估推理成本效益时,混元TurboS在所有评估模型中实现了最具成本效益的输出生成。
值得注意的是,模型在LMSYS Chatbot Arena上取得了与Deepseek-R1相当的性能,却仅使用了后者52.8%的Token量,证明了腾讯混元所提出的自适应长短思维链融合方法的有效性,也突显了腾讯混元TurboS在提供高性能LLM推理方面的卓越成本效益。
腾讯混元TurboS的训练与推理依赖于腾讯自研的高效基础设施。
强化学习训练框架 (Angel-RL):基于腾讯自研的大模型训练框架AngelPTM和推理框架AngelHCF全面集成了张量并行(TP)、流水线并行(PP)、专家并行(EP)、上下文并行(CP)和序列拼接优化,同时,上下文并行实现了串行和并行两种状态传递方法(下图),在采样端支持INT8量化,并且,利用腾讯定制的Starlink网络有效实现通信计算重叠。
针对RL训练中多模型导致GPU显存瓶颈的问题,设计了结合混合与专用资源分配的多模型RL工作流,并使用AngelPTM的ZeroCache技术(将去重模型状态卸载到CPU内存)降低GPU显存压力。

推理与部署 (AngelHCF):针对TurboS的Mamba混合架构,从三个关键维度实施了优化,最终相比纯Transformers MoE模型实现了1.8倍的加速:
1、Mamba Kernel优化:Prefill阶段利用Mamba2结构特性增强计算并行性;Decode阶段设计了SelectivescanUpdate Kernel以减轻显存带宽限制。
2、MoE优化:优先采用专家并行以缓解解码时显存瓶颈,智能冗余专家分配平衡GPU负载,优化通信与计算重叠。
3、混合架构精度优化:在Kernel层面为Mamba状态创新性地采用fp32精度,将混合架构的长文本生成质量提升至与全Attention模型相当的水平,在数学密集型和编程竞赛级推理任务中,Token消耗降低35%-45%(相比原始fp16/bf16)。
总结
腾讯混元团队在本报告中详细介绍了腾讯混元TurboS,这是一款创新的超大型混合Transformer-Mamba专家混合(MoE)模型,它独特地融合了Mamba在长序列处理上的高效率和Transformer卓越的上下文理解能力,采用了新颖的AMF/MF模块模式以及自适应长短思维链(CoT)机制。这款56B激活参数(560B总参数)的模型成为业界首个大规模部署的Mamba架构。
混元TurboS在LMSYS Chatbot Arena上获得1356分,并在23个自动化基准测试中平均得分77.9%,展现了强大性能。至关重要的是,腾讯混元TurboS在高性能和计算效率之间取得了有效平衡,以远低于许多推理模型的推理成本提供了强大的能力。这项工作为高效、大规模预训练模型树立了新范式,推动了易于获取且功能强大的人工智能系统的发展。
AICon 2025 强势来袭,5 月上海站、6 月北京站,双城联动,全览 AI 技术前沿和行业落地。大会聚焦技术与应用深度融合,汇聚 AI Agent、多模态、场景应用、大模型架构创新、智能数据基建、AI 产品设计和出海策略等话题。即刻扫码购票,一同探索 AI 应用边界!!

今日荐文
博士宿舍激情脑暴,革新了Scaling Law?Qwen和浙大联手推出新定律,直接干掉95.5%推理内存!
重磅!微软宣布开源Copilot!用 5000 万用户直接碾压 Cursor和Windsurf?
黄仁勋发力支持Agent、新设中国研发点,贾扬清Lepton被收购后现状曝光!
字节福利调整:多地禁止打包餐食回家、午休熄灯;Kimi回应“不如之前有人味儿”;黄仁勋确认H20已无法再改 | AI周报
突袭Cursor,Windsurf抢发自研大模型!性能比肩Claude 3.5、但成本更低,网友好评:响应快、不废话

你也「在看」吗?👇
(文:AI前线)