

作者:张倩
对于百度而言,既要保持长期主义的战略定力,也要在技术路径上灵活应变,这种「变与不变」的平衡或许正是其在这轮科技革命中的制胜之道。
2025 年,模型能力的重要性依然无需多言。
从预训练的角度来看,虽然连 OpenAI 前首席科学家 Ilya Sutskever 都说,预训练数据即将用尽,但海量的图像、视频等多模态数据资源依然有待挖掘。
从后训练的角度来看,强化学习新范式正在让 Scaling Law 焕发新生, 新一代的推理模型在数学、代码、长程规划等问题上不断取得新进展。
对于 AI 公司来说,保持对基础模型研发的投入依然非常必要。现阶段来看,这仍然是攀登智能高峰的本质所在。
而在这个领域,百度一直是一个不可忽视的力量。从 2019 年发布文心大模型 1.0 至今,文心大模型从知识和数据融合学习,到知识增强、知识点增强,从检索增强、对话增强、逻辑推理增强,到慢思考、多模态的技术演进并非偶然,而是早期技术探索形成的「积淀」持续推动的结果。正是这份「积淀」引领百度打造出超越 GPT-4o 的多模态大模型文心 4.5 Turbo,以及领先 DeepSeek R1、V3 的深度思考模型文心 X1 Turbo。这些技术发展,体现了百度在基础研究上「不变」的坚持与在 AI 快速迭代环境中适时求「变」的进取。

在前两天的百度 AI Day 上,百度集团副总裁吴甜深入解读了文心最新模型的创新技术,并回应了业界对百度文心大模型的诸多关注。通过她的分享,我们得以一窥百度在基础模型研发领域坚持的核心理念与技术演进路径,也更加清晰地认识到了评测数据背后那个真实且充满活力的飞桨文心生态。

进击的文心
在 AI Day 现场,吴甜演示了一个文心 X1 Turbo 解题的案例。这道题不光有文字描述,还有几何图,需要模型综合多模态信息进行推理。

从文心 X1Turbo 的回答来看,它思考解答这个题目的思路非常清晰,能够自主规划,识别图片中的明面信息和隐藏含义,再思考分析,反思每个选项答案的准确性,最后综合给出解题步骤和答案。这在一些权威基准测试中也得到了验证。文心 X1 Turbo 整体效果领先 DeepSeek R1、V3 最新版,略低于 OpenAI o1 满血版。
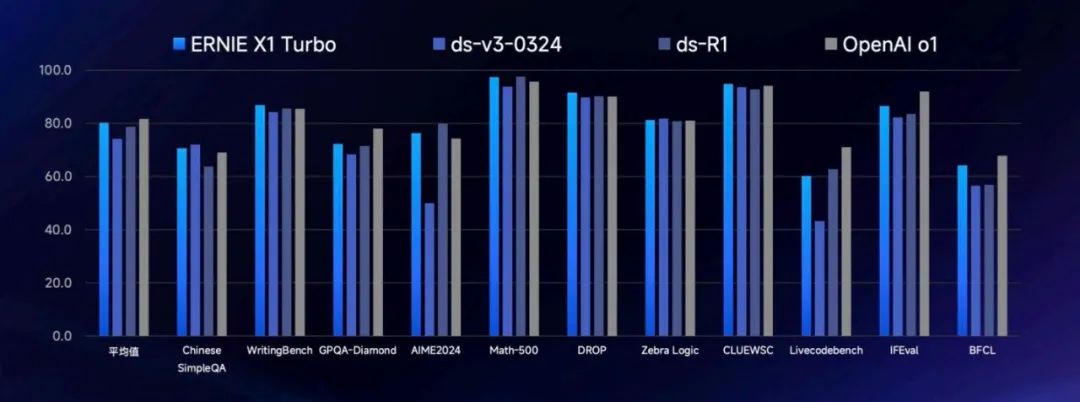
此外,来自中国信通院的大模型推理能力评估也显示,文心 X1 Turbo 在 24 项能力测试中表现突出 ——16 项获 5 分、7 项获 4 分、1 项获 3 分,综合评级达到「4 + 级」,成为国内首款通过该测评的大模型。评估结果还表明,该模型在逻辑推理、代码推理、推理效果优化等技术能力及工具支持度、安全可靠度等应用能力均获得满分。这样一个来自第三方的评测意味着,文心 X1 Turbo 已经站稳了国内推理模型的第一梯队。

除了推理能力,文心 X1 Turbo 和之前的文心 X1 之所以出圈,和它们的成本优势也密不可分。在能力相当的情况下,文心 X1 把价格打到了 DeepSeek R1 的一半;X1 Turbo 则更进一步,把价格打到了 DeepSeek-R1 的 25%,这让一些海外开发者羡慕不已。
一个搭建多年的全栈技术体系
用吴甜的话来说,无论是多模态还是深度思考,想做出好的效果都不是「一招制胜」,而是通盘的问题。好在,在百度多年构建起来的技术栈中,文心有很多「招式」可以用。
从多模态深度语义理解到多模态大模型
在国内,百度是最早开展多模态研究的 AI 公司之一。他们 2018 年就在「多模态深度语义理解」方面有所突破,例如视觉语义化和语音语义一体化。以此为基础,他们的技术路线一路演进,进入多模态大模型的时代。
吴甜提到,多模态大模型的核心难点之一在于如何有效地对多模态进行建模。围绕这一问题,他们从多个方向寻求突破,研制了:
-
多模态异构专家建模:充分照顾到不同模态的特性;
-
自适应分辨率视觉编码:解决不同分辨率视频在视觉编码上的差异化要求;
-
时空重排列的三维旋转位置编码:充分利用视频数据中的时空、时序信息;
-
自适应模态感知损失计算:根据不同模态的特性动态调整损失计算方式,解决模态间差异问题。
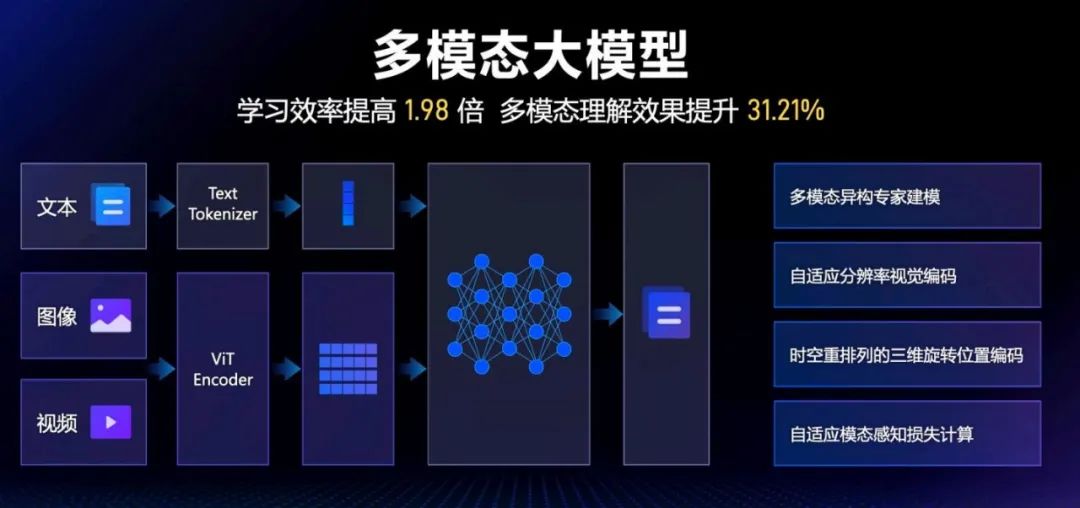
采用了这些技术之后,模型在训练过程中学习效率提高了 1.98 倍,多模态理解效果提升了 31.21%。
在她看来,多个模态之间是有相互增益的,多模态是大模型的一个发展趋势。
可以看出,百度对于多模态的技术投入将是长期而坚定的。
从慢思考到深度思考
长期追踪百度技术发展的朋友可能还记得,早在 2023 年 10 月,百度就发布过基于「系统 2」的慢思考技术,X1 和 X1 Turbo 便是以此为基础进化而来。此外,2018 年、2019 年左右,百度就在强化学习方向有所突破,构建了 PARL 强化学习框架等基础设施,这也推动了今天的深度思考模型的研发。
然而,早期的强化学习所解决的问题和今天有所不同,之前的模型主要聚焦于解决单一任务,而今天的模型是解决大量通用任务。
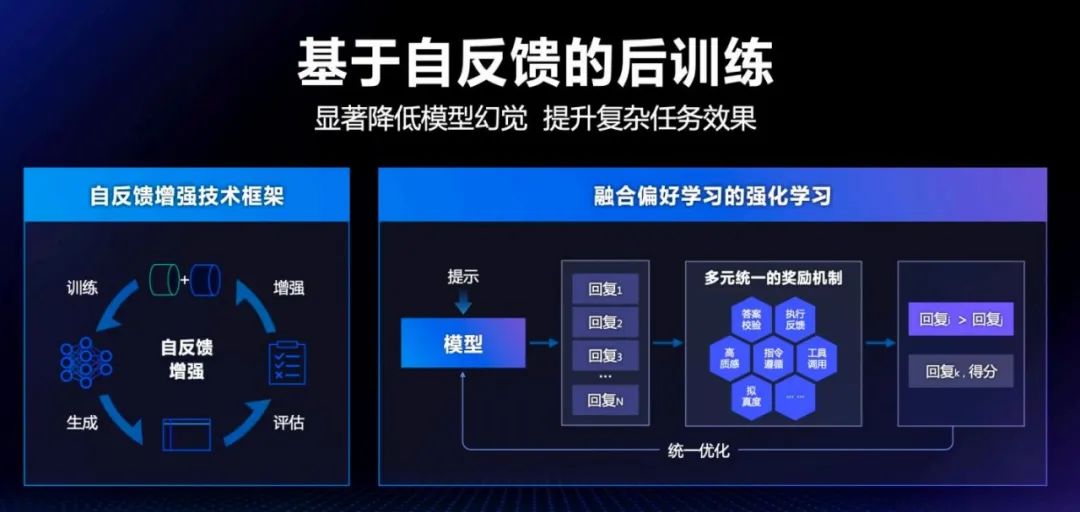
为了迎接新的挑战,百度进行了多项技术创新,包括:
-
自反馈增强技术框架:建立了「训练 – 生成 – 评估 – 增强」的闭环,让模型能够基于自身的生成和评估反馈能力不断自我迭代。
-
融合偏好学习的强化学习:结合用户偏好学习的强化学习,提升模型对高质量结果的感知能力和数据利用效率。
-
多元统一的奖励机制:融合多种评价标准(如结果正确性、执行反馈、思想深度、指令遵循等)对模型表现进行评判,引导模型向更优方向发展。
-
思考与行动融合的复合思维链:模拟人类不同的思维模式(边思考边行动、先思考后行动、先行动再反思等),通过强化学习让模型在不同任务上探索出适合的思维链和行动链组合,提高解决真实长程复杂任务的能力。

这些解决方案的出现也是技术演进的自然结果。吴甜解读到,当前基础模型的泛化能力很强,意味着模型自己可以在多任务上做探索,给模型输出结果的反馈,通过强化学习技术,让模型自行调试方向不断进化,这是让模型效果提升的重要方式。
复杂的数据建设
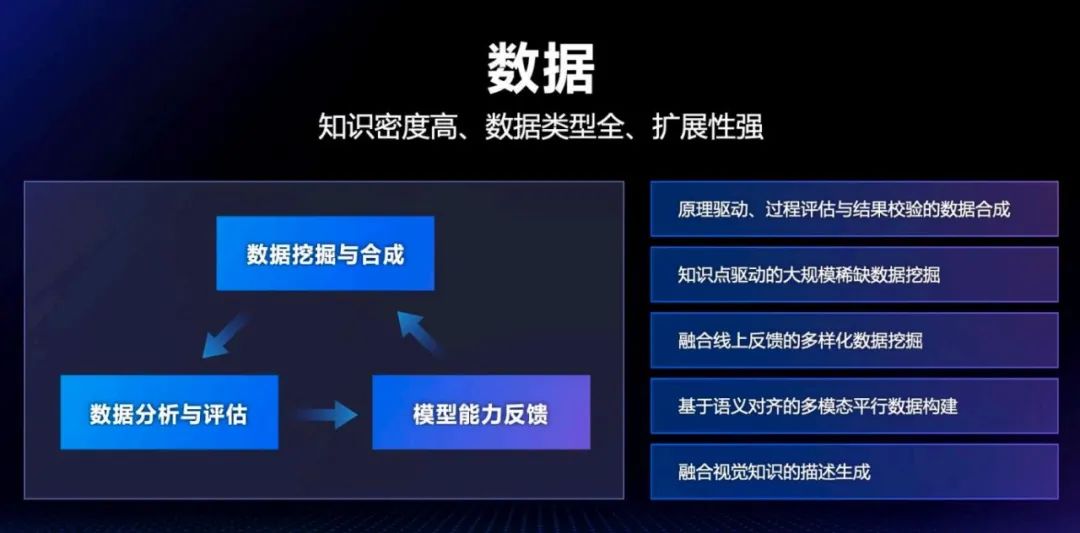
当模型进化到多模态、深度推理,数据建设的难度也在随之增大。吴甜提到,多模态数据的建设本身比纯文本数据的建设难度、复杂性都要高。另外是现在大量的多模态的任务所依赖的输入,是一种经过加工或中间处理的状态。 比如说图的生成要给模型一个 Prompt,现在让文生图模型去画图用的 Prompt,要想达到好的生图效果,并不是天然日常所用的文字表达方式,往往要增加一些比如「纸质纹理」、「丁达尔效应」、图片的比例等等这些设计用语。所以需要借助一些技术方法去挖掘、合成。
另外一个难点是稀缺数据的建设。天然的数据分布并不是像我们所希望的那样能够和知识体系匹配起来,这个时候对于一些稀缺数据要进行挖掘。
在解决这些问题的过程中,百度之前研究多年的知识图谱帮助他们构建了完备的知识体系,为稀缺数据的挖掘提供了理论支撑和实践指导。
此外,他们打造了「数据挖掘与合成 – 数据分析与评估 – 模型能力反馈」的数据建设闭环,为模型训练源源不断地生产知识密度高、类型多样、领域覆盖广的大规模数据。
从「飞桨」、「文心」到「飞桨文心」
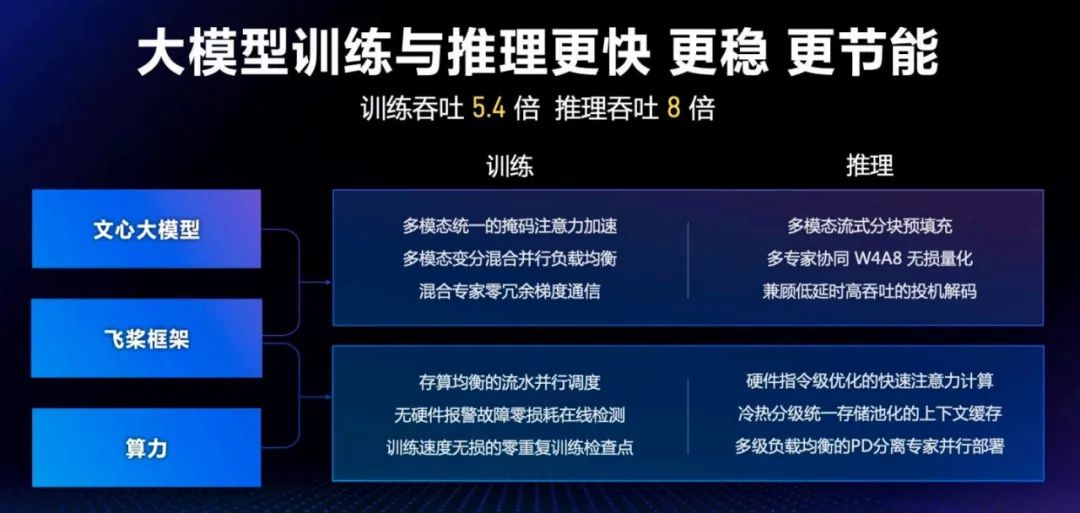
文心的每一次性能提升,都离不开与飞桨的深度协同和联合优化,这也是百度和其他 AI 公司非常不同的一点。
作为国内第一个功能完备的开源深度学习平台,飞桨从 2018 年起一直在不断进化,如今已经迭代到了飞桨框架 3.0 版本。
在百度 AI 的技术架构中,它扮演的是关键的「腰部」角色 —— 通过向上与模型层协同解决多模态统一和 MoE 专家均衡等问题,向下与算力层协同提升训练并行效率和推理性能,从而实现大模型的降本增效。
此外,吴甜还提到,飞桨和文心的持续进步,离不开百度在持续构建的 AI 生态系统的贡献。通过多年积累,百度在全国多地落地产业赋能中心、数据生态中心和教育创新中心,依托飞桨深度学习平台和文心大模型,借助广泛的伙伴体系连接千行百业,接触到更多元化的行业需求,也赋能当地的产业智能化升级。
更重要的是,这一生态形成了数据反哺的闭环机制。那些沉睡在各行业中的稀缺数据,无法通过纯技术手段获取,只能通过深度的生态合作逐步挖掘整合,为文心大模型的持续进化提供了源源不断的养分。
长期主义的赛道选择:AI 马拉松
站在 2025 年这个时间节点回望,百度在 AI 领域的布局体现出明显的长期主义特征。从昆仑芯片到飞桨框架,到文心大模型,再到最上层的应用,百度走的是一条「全栈布局、自主研发」的技术路线。在接下来的赛程中,这种全方位的准备将成为其在竞争中坐稳牌桌的关键所在。
展望未来,两个技术方向是更被百度看好的:多模态和智能体。智能体是建立在基础模型上的复合 AI 系统,它将大模型从单纯的理解和生成工具,升级为能够进行多步骤思考、自主规划并调用工具的行动系统。未来,智能体将成为在应用中解决大量问题的主要方式。而基础模型多模态、深度思考能力的提升可以更好地托举智能体能力。
在提升模型能力的同时,百度还在模型的技术普惠上发力,文心 X1 Turbo 的超低定价就是这一努力的代表。只有把模型的成本降得足够低,行业内的广大开发者才能在应用领域尽情施展,创造出一个蓬勃发展的大模型应用生态。
现阶段,整个 AI 生态仍在经历深刻变革,技术影响如涟漪般向外扩散。百度文心「变与不变」的平衡或许正是其在这轮科技革命中的制胜之道。
©
(文:机器之心)