


论文:Parallel Scaling Law for Language Models
链接:https://arxiv.org/pdf/2505.10475
LLM 的进化一直依赖「堆参数」,但模型越大,问题越明显:
-
训练成本爆炸:千亿参数模型训练需耗费千万度电 -
推理速度慢:生成一句话要等几十秒 -
手机跑不动:显存要求动辄上百G,普通设备无法部署

最近提出的「Test Time Scaling」虽能提升性能,但需要生成数百个中间步骤,反而更慢。学者们不禁思考:有没有既高效又省资源的扩展方式?
ParScale的突破思路:用「并行计算」代替「堆参数」
这篇论文的核心创新点在于——让同一个模型「分头思考」。
-
传统方法:一个模型「单线程」计算 -
ParScale:复制输入并添加不同「思考前缀」,同时跑P个计算流 -
动态融合:用LLM自动给不同思考结果打分,加权合成最终答案

举个通俗例子:就像让10个专家同时解同一道题,再根据他们的解题过程动态选最优解,而不是只问一个超级专家。
核心:动态加权融合
关键公式藏在论文的Proposition 1中:
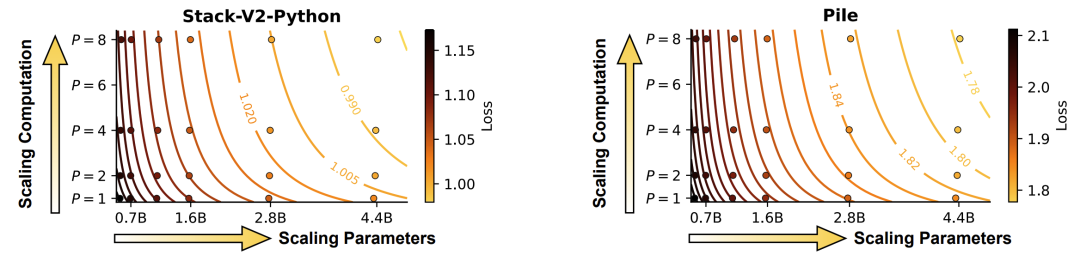
模型损失与并行流数量P呈对数关系
(N为参数量,P为并行流数)
这意味着:
-
并行计算的效果≈参数量的对数级增长 -
开8个并行流 ≈ 参数翻3倍的效果 -
但实际增加的硬件成本微乎其微

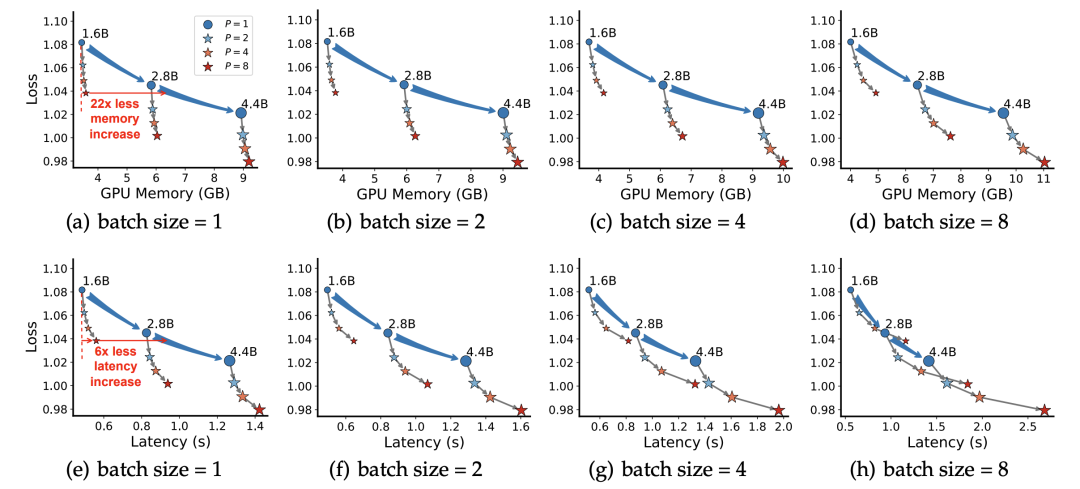
实验结果:推理效率提升22倍
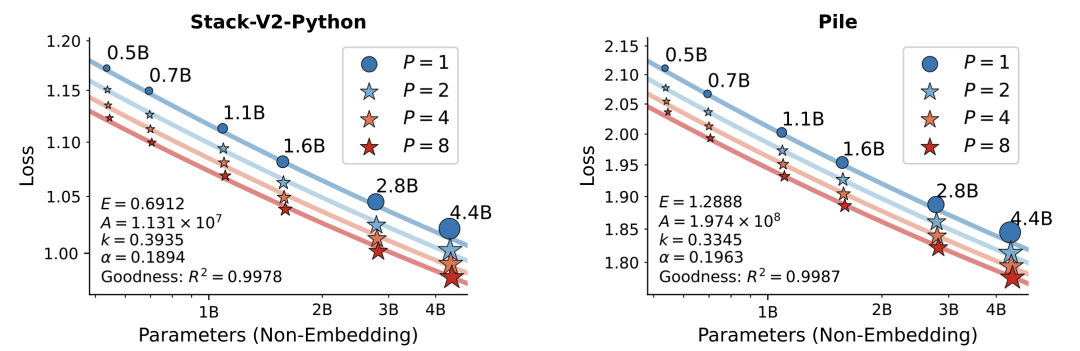
论文在42B token数据上训练了67个模型,结论炸裂:
-
性能比肩参数扩展:1.6B参数+8并行流 ≈ 4.4B参数模型 -
推理成本暴降: -
内存占用减少22倍 -
延迟降低6倍 -
**数学推理暴涨34%**:GSM8K等复杂任务提升最明显
更绝的是,旧模型也能改造!用少量数据微调即可让已有模型支持并行计算,堪称「老模型返老还童术」。
落地价值巨大:手机都能跑「LLM」
这项技术最颠覆的应用场景是边缘设备:
-
手机/汽车只需加载一个小模型,开多个并行流就能获得大模型性能 -
动态调节并行数:聊天时开2个流,解数学题时开8个流 -
成本优势碾压:显示其综合成本仅为传统方法的1/6 
未来咱们的手机助手可能既是「生活管家」又是「数学老师」,却完全不卡!
畅想下未来:模型的「算力永动机」
ParScale揭示了一个深层规律:模型能力不只取决于参数,更取决于计算方式。这打开了新世界的大门:
-
动态扩展:根据任务难度实时调整并行数 -
混合架构:MoE+ParScale双剑合璧 -
跨领域应用:图像生成、蛋白质预测均可借鉴
或许未来AI进化的关键不再是「造更大的模型」,而是「更聪明地使用算力」。
这篇真的是个巨作!划时代!好样的,Qwen~
(文:机器学习算法与自然语言处理)