


新智元报道
新智元报道
【新智元导读】你以为GPT-4已经够强了?那只是AI的「预热阶段」。真正的革命,才刚刚开始——推理模型的时代,来了。这场范式革命,正深刻影响企业命运和个人前途。这不是一场模型参数的升级,而是一次认知逻辑的彻底重写。
AI推理模型改变了一切。
而OpenAI早有讨论。
最近,他们放出了过去关于推理模型重写未来的讨论。

OpenAI研究员Noam Brown强调了预训练和推理两种关键的AI范式,以及模型随着处理更多数据和计算能力的提升而不断改进的过程。
这些技术进步不仅加速了模型性能的提升,还在重塑人工智能基础设施的战略和经济动态。
与此同时,由OpenAI首席经济学家Ronnie Chatterji等讨论探讨了人工智能与国家安全和经济政策的交叉领域。
这些讨论共同强调了人工智能的双重轨迹:一方面加速技术进步,另一方面加深其在全球政策、基础设施和制度治理中的角色。

第一个出场的是Noam Brown。
他是OpenAI在多智能体推理领域的研究人员,以共同开发出首个超越人类水平的无限注德州扑克AI,以及首个达到人类水平的策略游戏《外交官》(Diplomacy)AI而闻名。

多年来AI已经取得了很多很酷、令人印象深刻的成果。
比如说,在1997年,IBM的「深蓝」战胜了国际象棋冠军Garry Kasparov。

在2011年在《危险边缘》节目中,IBM的「沃森」夺冠。

在某些特定领域,AI也早就有了不少令人惊艳的成果。
比如,很早以前,美国邮政就开始用光学字符识别技术来分拣邮件;Facebook的人脸识别功能,也已经存在很多年了。

那么问题来了,像ChatGPT这样的AI,以及现在所处的AI时代,到底特别在哪里?
答案其实就在于「通用性」。
最重要的区别在于:以前的AI系统都非常专注于单一任务。
比如在1997年,IBM的「深蓝」战胜Garry Kasparov,但背后可是花了两年甚至更久的时间,专门训练AI只为了下好国际象棋。

深蓝机组之一
同样的情况也发生在《危险边缘》节目上,他们花了好几年时间,只为了让AI在节目中表现出色——
但它只会做这一件事,其他什么都不会。
而现在ChatGPT和如今的AI特别之处就在于它们的「通用性」——
也就是说,它们可以完成很多完全不同的任务,哪怕这些任务并不是特意训练过的。
这就是我们所处AI新时代真正不同的地方。

Noam Brown接下来强调了两种关键的AI范式:预训练范式和推理范式。


「预训练范式」出现得更早,也是最初驱动ChatGPT的核心方式。
最早,这可以追溯到2019年的GPT-2。
它的基本思路其实很简单:
收集大量文本,包含了互联网的大部分内容;
然后训练AI模型来预测一句话中下一个可能出现的词。
听起来也许很基础,但这种方法却能带来令人惊讶的智能水平。
为什么会这样呢?
Brown认为原因在于,当把整个互联网的大量文本输入给模型,里面自然就包含多种多样的内容。
那么当模型要预测某个语句中的下一个词时,它必须理解很多上下文信息,才能做出最准确的判断。

Ilya Sutskever有个特别形象的说法:
想象一下网络上有一本推理小说,模型已经读完了整本小说的所有文字,来到结尾的部分。
故事最后,侦探说:「我知道凶手是谁了。凶手就是____。」
这个时候,如果模型要预测这句话中最后那个空白部分,它就必须真正「理解」整部小说的情节。
这就是为什么仅仅通过「预测下一个词」的训练方式,模型就能学到这么多看似复杂的知识。
这就是预训练范式的魅力所在。
而且另一个很关键的点在于,它具备很强的通用性——
因为它是基于整个互联网的海量文本进行训练的,所以自然能学到各种各样的知识和语言表达方式。
更令人印象深刻的是,大家已经持续观察到一个很稳定的趋势:当在预训练范式中投入更多的数据、更多的计算资源、以及更大的模型规模,模型在「预测下一个词」这项任务上的表现就会变得越来越好。
AI领域有2篇非常著名的论文。


这些研究表明:当扩大模型规模、延长训练时间、增加训练数据量之后,模型在完成预测任务时会提升。

这种稳定可控的增长趋势,正是促使OpenAI决定大规模投入资源、继续扩展模型规模的核心依据。
当然,光是让模型更会「预测下一个词」,并不一定就意味着它在用户真正关心的任务上,比如编程,真的变得更强了。
但在实践中发现:当模型在预测任务上表现越来越好时,它在各种「下游任务」上的表现也会随之变好,比如写代码、做数学题、回答问题等等。

这其实就是GPT范式不断演进的基础,从GPT-1到GPT-2,一直到现在,模型能力的持续提升。
但正是这种「简单粗暴」的扩大规模方式,带来了性能的巨大飞跃——
这就是令人惊喜的地方。
当GPT-3发布、而且提升的趋势依然继续延伸时,AI领域里很多人都开始认为:
好吧,这就是终点了。我们已经找到了通往超级智能的道路。我
们只需要不断扩大模型规模,就能获得越来越强的智能。
从理论上讲,这是对的。
但关键问题在于——这条路的成本非常高昂,而且会迅速飙升。
比如GPT-2的训练成本,大概在5,000到50,000美元之间,取决于具体怎么估算。而根据一些公开资料,GPT-4的训练成本可能高达5,000万美元左右。
如果还要继续按照这个方向再扩大几个数量级,那花费将是天文数字。
而且尽管模型确实变得更聪明了,但它离理想中的「通用智能」仍然还有一段路要走。

这也呼应了Ronnie曾经说过的一点:这个领域发展得非常快。
过去一年里听到的一些关于大语言模型(LLM)和「扩展范式」的批评,可能在当时确实是有道理的。
但到了2023年9月,情况发生了变化——
因为人类已经进入了「推理模型」时代。
这就引出了「扩展能力」的第二种范式:推理范式(reasoning paradigm)。
预训练的成本已经快速增长,动辄就是上千万美元,有些训练甚至花费了上亿美元。
虽然理论上还可以继续往上堆钱,比如投入十亿、甚至数十亿美元,但到某个点之后,经济回报就不再划算了。
不过,有一点非常关键:虽然训练的成本越来越高,但实际向模型提问,让它给你一个答案的花费的「推理成本」,其实仍然很低。
这就为「扩展」开辟了一个新的维度。
设想一下,如果大家不再单纯依赖扩大训练量,而是提升模型在「每次回答前进行更深层思考」的能力呢?
这正是o系列模型(比如o1)背后的核心思想。
举个例子:你向GPT-4提一个问题,它可能只花你一分钱左右。
但如果你问o1同样的问题,它会「认真思考」很久,也许会花上一分钟才回答,而成本可能是大约一美元——
具体来说是数量级上的估算,有上下浮动。
但这个一美元的回答,往往会比那一分钱的回答好得多。
这就是推理范式带来的全新可能。

右图展示了推理范式的实际效果。
美国数学竞赛(AIME),是美国数学奥林匹克国家队的选拔赛之一。

图中的纵轴表示准确率,也就是模型在「一次答对」的比例(叫做「pass@1」);横轴表示模型在回答问题时所消耗的推理计算量(也就是「思考」时间和资源的多少)。
在图的最左边,模型几乎是「秒回」——也就是基本没怎么思考;而在最右边,模型会花上几分钟去思考后再作答。
可以明显看出:随着模型「思考得越久」,答题准确率就越高,表现也就越好。
这说明推理时间确实能带来质量的提升。
这提供了全新的「扩展维度」——
大家不必再单靠堆大模型、加大训练成本来提升性能,而是可以通过增加推理时间、花更多资源在「每次思考」上,来获得更强的结果。
而且最美妙的是,这个维度几乎还没有被充分利用。
就像之前说的,GPT-4一次问答成本大约只有一分钱。
但实际上,对于很多人真正关心的问题,他们愿意支付远不止一分钱。
我们现在可以开始探索新的定价——
每次问答成本可以是几美元、几十美元,甚至更多,这样就可以支撑模型进行更深入、更高质量的推理。
目前来看,在竞赛数学方面,这是AIME 2024的测试数据。
GPT-4o得分大约是13%,o1 preview模型得分大约是57%,o1得分达到83%。
再来看博士级别的科学问题,也就是上图最右的GPQA基准测试。
这是一个多项选择题测试,设计目标是需要具备领域内博士水平才能作答。
人类平均正确率是70%。GPT-4o得分是56%,这个成绩已经很出色了。
而o1得分则是78%。
而且,自自从发布以来,这些成绩还在持续提升,而且进步非常迅速:
去年9月,发布o1 preview;
同年12月,发布了正式版的o1,并在同月宣布了还未发布的o3。
这是AI的重点所在。
关于编程竞赛的表现,以专业的编程竞赛平台Codeforces为例。
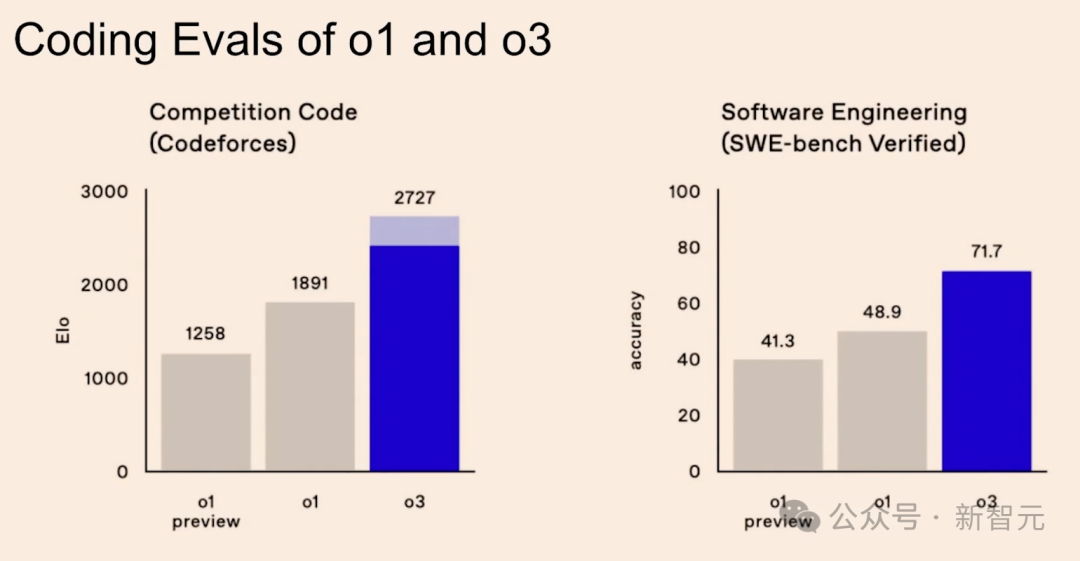
GPT-4o的得分只排在第11百分位,也就是说,它的表现只比约11%的顶尖人类程序员好。
o1模型的Elo分数是1891,相当于人类选手的第89百分位。
而o3模型的Elo分数超过了2700,已经进入了人类专业编程选手的前0.1%,相当于全球第175名的水平。
而且,OpenAI有个内部模型,它的水平已排进了全球前50名。
Brown预测:
到今年年底,OpenAI的模型在编程竞赛中将会达到超越人类的水平。
而「达到超人类水平」这件事本身并不新鲜,AI过去也做到过很多次。
但o3模型特别的地方在于:它不仅仅在编程竞赛中表现优秀,它在很多任务上都表现得非常出色。
而在编码任务基准测试Swebench Verifie,o3得分达到了72%。
这意味着这个模型即使不是专门为了编程训练的,也已经具备了强大的实际编码能力,对现实世界的经济活动会带来很大影响。
AI进步太快了:六个月前还存在的问题,但现在已经不成立了。
Aaron Ronnie Chatterji是OpenAI的多一位首席经济学家。
目前,他是杜克大学的Mark Burgess & Lisa Benson-Burgess杰出教授,专注于学术、政策与商业交汇的领域。
他曾在拜登政府任职,担任白宫CHIPS协调员以及国家经济委员会代理副主任。在此之前,他曾任美国商务部首席经济学家,以及白宫经济顾问委员会的高级经济学家。

他认为就像当前世界在多个维度上已经出现的分裂趋势一样,AI也不例外。
如果轻易接受这样分裂的世界,可能会带来两个风险:
一是OpenAI可能会在一些关键市场失去信誉,而这些市场正是它努力争取信任的地方;
二是OpenAI很可能会失去一些关键的人才。
因此,在坚持价值观的同时,如何在其中找到平衡,是这次讨论中的一个重要主题。
OpenAI非常国际化,因此,当不同地区开始采用不同类型的技术、而超级大国之间的技术竞争加剧时,这让很多人感到不安。
从总体上来看,OpenAI内部讨论的结论是:AI正在从根本上重塑企业格局。

但这种转型并不只是关于取代人类或企业本身的问题,而更像是一场「技术化竞赛」。
这种转型发生在各类企业中——包括《财富》500强、大中小型企业等各个层级。
他们的讨论主要从三个维度展开:
第一,AI取代人类。
这里的关键问题其实不是{AI会不会取代人类},而是「AI将如何增强或取代人类的角色」。这才是大家真正需要思考的方向。
第二,AI取代公司。
与其说是AI创业公司会取代传统企业,不如说是一场谁更能有效采纳和整合AI的竞赛。
比如在银行业,大家就可以看到这种分化趋势:一些银行拥有技术人才,正在积极投资AI;而另一些仍依赖传统主机系统(mainframes),开始借助AI推动现代化转型。
企业必须作出选择:要么走在AI转型的前列,要么就被甩在后面。
第三,从个人或企业的视角出发来看如何落地AI。
谁能真正理解并应用最新的AI技术,谁就能取得成功。AI的影响范围涵盖技术支持、运营效率、战略决策等多个方面。
所以,关键的问题是:企业的AI旅程是什么?
你现在处在什么阶段?
两年后你希望达到什么样的水平?
这正是许多企业在思考的问题。
这趟旅程并不是简单地购买AI工具、获取许可证那么简单,而是要把AI嵌入整个价值链中,实现深度融合。
(文:新智元)