

随着语音助手、有声交互、AI 角色配音等场景的普及,语音大模型也正在面临一个核心瓶颈:响应速度太慢,难以实时交互。
今天为大家介绍一款由 VITA 团队开源的端到端语音模型:VITA-Audio,可以带来前所未有的超低延迟体验,让语音生成进入毫秒级响应时代!

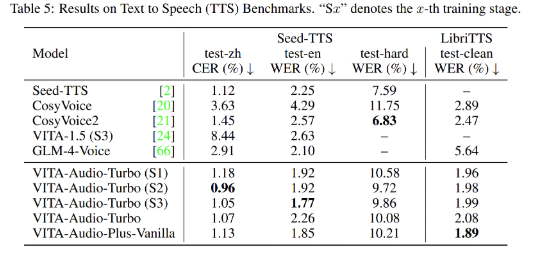
一个7B参数的端到端语音模型,首次生成音频仅需53毫秒,速度比同级别模型快3-5倍!
它完全开源,代码、数据、权重全公开,简直是给开发者和研究者送福利。

核心优势
-
• 超低延迟:首次生成延迟仅 53ms,比同类 7B 语音模型快 3–5 倍。 -
• 首次前向传播生成:Audio Token Chunk不再自回归迭代,直接生成可解码音频 token。 -
• 多模态语音能力:支持语音识别(ASR)、语音合成(TTS)、语音问答(AQA)等任务。 -
• 端到端架构:无需多阶段预处理,直接“一条龙”,既快又稳。
技术解析
传统语音模型如 Whisper、XTTS、NaturalSpeech 2 等,多采用:
-
• 自回归机制 → 每个音频 token 逐步生成 -
• 嵌套编码器+解码器结构 → 多阶段运算
VITA-Audio 创新之处:
-
• Chunk-wise 预测架构 → 第一次推理就生成一整块 audio token,可解码为首段语音 -
• Token 预填充机制 → 模型预热处理部分历史 token,快速推理当前 chunk -
• 解码优化 → 减少音频合成过程的重建步骤
这使得整个模型能够在输入响应后毫秒级输出第一帧语音,真正实现对话场景“边听边说”。
安装与部署
先把项目代码拉取下来,并安装好依赖
git clone https://github.com/VITA-MLLM/VITA-Audio.git
cd VITA-Audio
pip install -r requirements_ds_gpu.txt
pip install -e .建议用NVIDIA GPU(A100或V100最佳)。懒得折腾环境的,直接用官方Docker镜像:
docker pull shenyunhang/pytorch:24.11-py3_2024-1224模型权重,需要下载三个文件:VITA-Audio模型权重、音频编码器和解码器权重。去Hugging Face或官方链接搞定,配置好路径就行。
启动WEB界面:
python web_demo.py
写在最后
VITA-Audio 就像一个突然闯进语音领域的“新秀”,用53毫秒的“魔法”让所有人眼前一亮。
它不仅给小企业提供了无限可能,也让普通开发者也提供了一种新思路。
更让我感慨的是,VITA-Audio背后折射出的开源社区力量。VITA-MLLM团队把代码、数据、权重全盘托出,这种开放态度让每个开发者都能站在巨人的肩膀上,创造属于自己的“语音魔法”。
GitHub 开源地址:https://github.com/VITA-MLLM/VITA-Audio

● 一款改变你视频下载体验的神器:MediaGo
● 字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
● 英伟达开源语音识别模型!0.6B 参数登顶 ASR 榜单,1 秒转录 60 分钟音频!
● 开发者的文档收割机来了!这个开源工具让你一小时干完一周的活!
● PDF文档解剖术!OCR神器+1,这个开源工具把复杂排版秒变结构化数据!

(文:开源星探)