

今天是2025年5月14日,星期三,北京,晴。
我们来看两件事:
一个是文档智能方向的一个应用,如何做一个arXiv论文翻译的工具?来看看一个研发历程,其中有些方案和坑点可供我们借鉴。
另一个是Qwen3技术报告的一些技术点,包括训练阶段的设计、混合思考模型的训练以及训练中的强化学习奖励函数。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、Qwen3技术报告的几点技术细节
Qwen3进展,技术报告发布,可以在github库里下载,https://github.com/QwenLM/Qwen3/,比技术博客细节更多一些,但依旧写的很含糊,我们来看看。
1、预训练阶段与后训练阶段
首先是,预训练,分为三个阶段:通用阶段(S1):在超过30万亿token的数据上进行训练,覆盖119种语言和方言;推理阶段(S2):增加STEM、编程、推理和合成数据的比例,进行约5T高质量token的训练;长上下文阶段:收集高质量的长上下文语料库,将上下文长度扩展到32,768 个token;
后训练阶段**包括四个阶段,
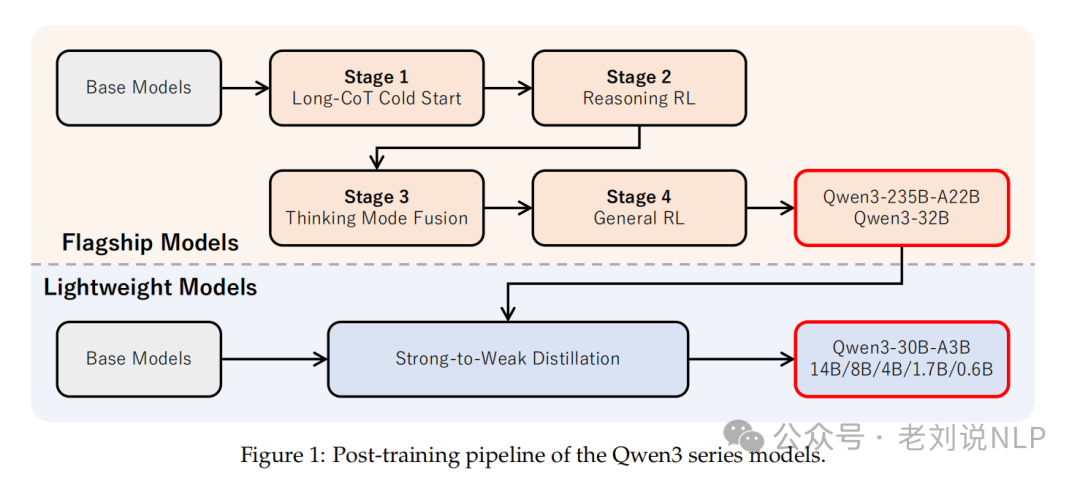
长链式思维冷启动阶段,构建包含数学、编程、逻辑推理和一般STEM问题的综合数据集;
推理强化学习阶段,使用GRPO算法更新模型参数,采用大规模批处理和高的每个查询展开次数;
思维模式融合阶段,设计聊天模板以融合思维和非思维模式,并引入思维预算机制。
通用强化学习阶段,涵盖超过20个不同任务,使用了几个奖励函数。
3、关于混合推理训练
这个可以展开来说,首先是数据:

SFT数据集结合了“思维”和“非思维”的数据。为确保第二阶段模型的绩效不受额外SFT的影响,“思维”数据是通过使用第二阶段模型本身对第一阶段查询进行拒绝采样生成的;
“非思维”数据则经过精心策划,以涵盖包括编程、数学、指令遵循、多语言任务、创意写作、问答以及角色扮演在内的多样化任务;
对于处于思考模式和非思考模式的样本,分别在用户查询或系统消息中引入/think和/no_think标志。这使得模型能够根据用户的输入相应地选择合适的思维模式。
对于非思考模式的样本,在助手的响应中保留一个空的思考块,以确保了模型内部的格式一致性,并允许开发者通过在聊天模板中拼接一个空的思考块来防止模型进行思考行为。
默认情况下,模型以思考模式运行,因此增加了一些用户查询不包含/think标志的思考模式训练样本。

另外一个就是预算控制,如下,说的其实很抽象。

上面的意思是,一旦模型学会了以非思考和思考两种模式进行回应,它自然而然地发展出处理中间情况的能力—基于不完整的思考生成响应,这项功能为实现对模型思维过程的预算控制奠定了基础。
具体来说,当模型的思维长度达到用户定义的阈值时,会手动停止思维过程,并插入停止思考指令:“考虑到用户时间有限,我现在必须基于直接思维给出解决方案。\n\n\n”,插入该指令后,模型会基于到那时为止积累的推理生成最终回应。这一能力并非经过明确训练,而是应用思维模式融合后自然产生的结果。
4、关于强化学习的奖励函数
这个值得看看,包括Rule-based Reward、Model-based Reward with Reference Answer以及Model-based Reward without Reference Answer。
基于规则的奖励Rule-based Reward,基于规则的奖励已在推理强化学习阶段广泛使用,也适用于一般任务,如指令遵循和格式遵守);
基于参考答案的模型奖励Model-based Reward with Reference Answer,为每个查询提供一个参考答案,并提示Qwen2.5-72B-Instruct基于此参考来评分模型的响应,该方法允许更灵活地处理多样化的任务,无需严格遵守格式要求,避免了仅基于规则奖励可能出现的假阴性;
无参考答案的基于模型的奖励Model-based Reward without Reference Answer,利用人类偏好数据,训练一个奖励模型来为模型响应分配标量分数。这种方法不依赖于参考答案,可以处理更广泛的查询,同时有效增强模型的参与度和有用性。
二、如何做一个arXiv论文翻译的工具?
arxiv论文翻译是现在读论文群体的一个重要工具,而怎么做到在准确翻译的同时,还保持布局信息,是个很有趣的技术点。
社区的成员在https://zhuanlan.zhihu.com/p/1905569596599169419?share_code=tyy3jxftlLdW&utm_psn=1905581193958761586中,介绍了在研发arxiv论文翻译时的一些经验,在这里分享出来,供大家一起看看。
1、翻译arXiv论文有以下几种方案
方案一:将PDF转成Markdown再翻译
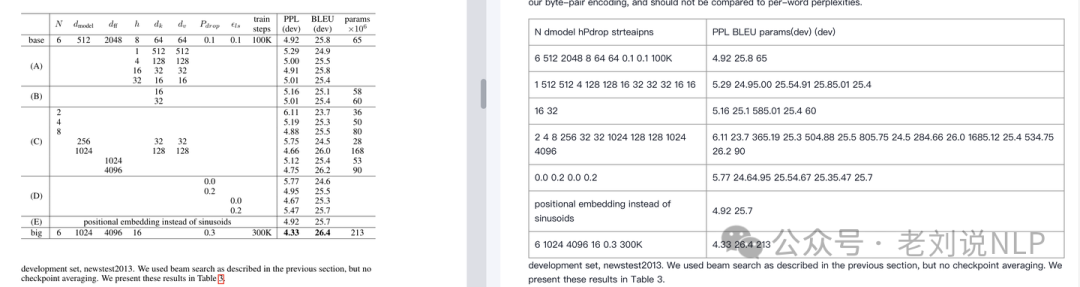
比如使用MinerU之类的工具,转Markdown的好处是可以方便二次编辑,但Markdown本身表现能力弱,导致丢失太多信息了,比如Markdown本身不支持复杂表格,大部分工具的转换效果都很差,比如下面是一个产品的效果,左侧是原先的表格,右侧是转换后的表格,转换后完全没法看。
最近比较火的方法是使用多模态大模型进行解析,大概是先转成图片然后使用大模型的OCR能力实现的,我也测试过了据说效果最好的Gemini,但它有个缺点是转换后的Markdown没有图片,所以只适合用来提取文本信息,而且我测试时发现经常无故丢失大段文本,因此这个方案不可行。
方案二:将PDF转成Word后翻译
相比Markdown,Word可以更好保留原先的布局,但由于PDF文件本身的复杂性,这些软件通常都会遇到排版和公式错乱问题,下图是某个国外知名的翻译软件效果
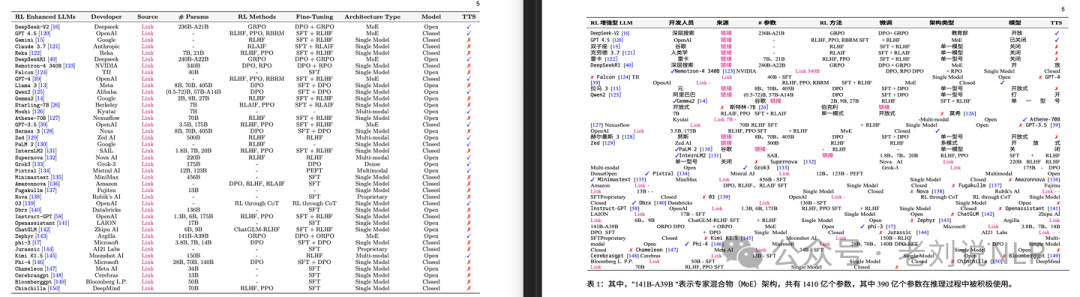
如果是复杂公式更没法看了,比如下面是某篇论文的翻译结果

虽然这个软件号称效果最好,但从我个人使用经验看,几乎没有一个PDF是能正常看的,必须忍受大量错乱的布局,而且价格很贵,28$的版本每月限制20个文件。
如果要自己实现的话,PDF转Word是很费时的功能,实现成本很高,而市面上唯一可用的第三方库是SolidConverter,它的价格很贵,据说每年百万,因此效果不好还贵,这个方案也不可行。
方案三:基于arXiv官网提供的HTML版本翻译
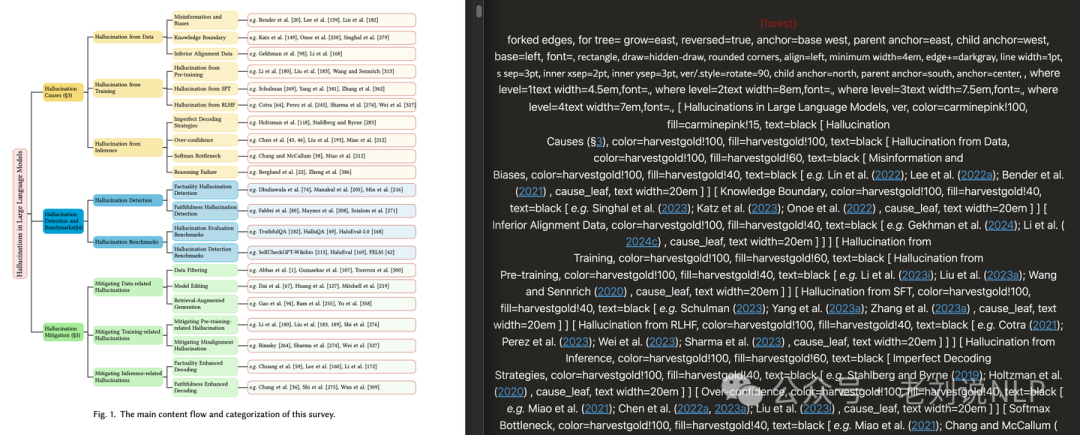
arXiv为大部分论文都提供了基于LaTeXML编译的网页版本,这样就能使用浏览器中的翻译软件翻译了,但LaTeXML很多模块不支持,比如forest宏不支持,下面使用forest的论文效果,左侧是原本的树形图,右侧是LaTeXML的显示效果,基本没法看。
方案四:基于arXiv的LaTex源码翻译
这种做法能最大程度保留论文格式,包括所有公式及引用,是目前唯一能满足我所有需求的方式,有极少数产品是这么做的,但它们有以下两个问题:
经常解析失败,成功率很低,即便是商业产品也失败率很高,我个人使用的经验看成功率可能不到60%:
贵或有数量限制,现有产品通常有两种收费模式:
月费,比如几十元但只能翻译20篇,这种产品用起来真让人纠结。
按字数收费,看起来更合理?然而这类产品往往贵得夸张,下面是某个产品翻译一篇论文的价格,在国内都够买本书了,而实际消耗的token数量大概不到10万,按GPT-4o-mini算其实只需$0.06。

因此在评估了现有方案之后我决定自己实现,接下来是实现过程。
2、自行实现的一路研发历程
第一次尝试:基于开源项目改
在自己实现前先参考开源项目,因为之前已经有人实现过类似功能了,然而尝试之后发现成功率很低,而且这些开源项目基本都是基于正则实现的,难以实现准确判断,大多是没有类型标注的Python代码,改造困难,所以放弃了。
第二次尝试:完全使用大模型来翻译
考虑到《苦涩的教训》,我尝试的第一个方案是直接使用大模型翻译,目前大部分大模型上下文都很长,至少也有128K,因此可以直接将LaTex文件进行简单分割,直接让大模型进行全文翻译。
然而这个方案效果很差,由于幻觉问题,大模型经常生成无法编译的LaTex文件,比如多出未知宏,或者少转义了特殊字符等,尝试了几篇论文发现没有一篇能正常编译,所以放弃了这个方案。
第三次尝试:使用开源LaTex解析
既然完整LaTex解析容易出错,那就通过解析来简化,让大模型只看到纯文本,这样就不会犯错了,但我实在不想写语法解析,因此先找开源的LaTex解析库,评估之后选择了看起来很成熟的unified-latex。
于是使用unified-latex实现解析,提取其中的纯文本让大模型进行翻译,这个方案看起来很完美,然而实现完后发现了两个致命问题,一是unified-latex的实现不完整,稍微奇怪点的LaTex就不支持了,导致解析后无法还原回去,二是这个方案的翻译效果太差,举个例子,比如下面这段简单的文本
Whereis 解析后会变成三个节点
[{
"type": "string",
"content": "Where "
}, {
"type": "inlineMath",
"content": [
{
"type": "string",
"content": "x"
}
]
}, {
"type": "string",
"content": " is"
}]
然后让大模型逐个翻译「Where」、「x」和「is」,但问题来了,大模型只看到「Where」,它肯定会翻译成「哪里」,而这里的意思是「其中」,因此要翻译效果好必须看到完整段落,所以解析成纯文本也是不可行的,这个方案也放弃了。
第四次尝试:自己实现LaTex解析
为了解决前面翻译效果差问题,我不得不自己实现LaTex解析,而且还实现了两种解析,一种是半解析,它只提取段落级别文本,忽略不需要翻译的部分,另一种是完整语法树解析,用于检查及修改。
LaTex解析的实现比我预想的要复杂,它和Markdown之类文档格式不同,LaTex本质上是一种「脚本语言」,有IF等控制语法,甚至不能像普通语言那样先做语法解析再执行,而是必须边解释边执行,因为可以随时定义新的命令,比如不少人会通过下面的语句来定义公式开始和结束,遇到这个命令时要当成对应的其它命令:
\newcommand{\be}{\begin{equation}}
\newcommand{\ee}{\end{equation}}
完整实现LaTex解析还需要解析第三方库,这实在太复杂了,因此具体实现时我做了很多取巧,只覆盖绝大多数人使用的语法。
通过检查来应对大模型幻觉问题
有了自己实现的解析就能让大模型进行段落级别翻译了,然而即便是一小段文本,用大模型翻译依旧容易出错,翻译后可编译的成功率还是很低。
怎么办呢?解决方法是加了大量的后检查机制,使用前面提到的完整解析模型,包括检查关键宏是否遗漏,以及大模型是否可能翻错了,对于一些容易出错的地方,还会直接做屏蔽,比如发现大模型经常擅自修改公式,于是干脆直接屏蔽,改成一个特殊标记,大模型看不到就不会犯错。
参考文献
1、https://zhuanlan.zhihu.com/p/1905569596599169419?share_code=tyy3jxftlLdW&utm_psn=1905581193958761586
2、https://github.com/QwenLM/Qwen3/
(文:老刘说NLP)