


极市导读
香港中文大学、快手可灵等团队联合提出的Flow-GRPO,首个将在线强化学习引入流匹配模型的工作。它通过ODE-SDE等价转换和去噪步数优化等策略,显著提升了图像生成模型在复杂场景理解、文本渲染等任务上的性能,将SD3.5 Medium在GenEval基准测试中的准确率从63%提升到95%,组合式生图能力超越GPT-4o,为流匹配模型的发展开辟了新范式。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文由香港中文大学与快手可灵等团队联合完成。第一作者为香港中文大学 MMLab 博士生刘杰,他的研究方向为强化学习和生成模型,曾获 ACL Outstanding Paper Award。
流匹配模型因其坚实的理论基础和在生成高质量图像方面的优异性能,已成为图像生成(Stable Diffusion, Flux)和视频生成(可灵,WanX,Hunyuan)领域最先进模型的训练方法。然而,这些最先进的模型在处理包含多个物体、属性与关系的复杂场景,以及文本渲染任务时仍存在较大困难。与此同时,在线强化学习因其高效探索与反馈机制,在语言模型领域取得显著进展,但在图像生成中的应用仍处于初步阶段。
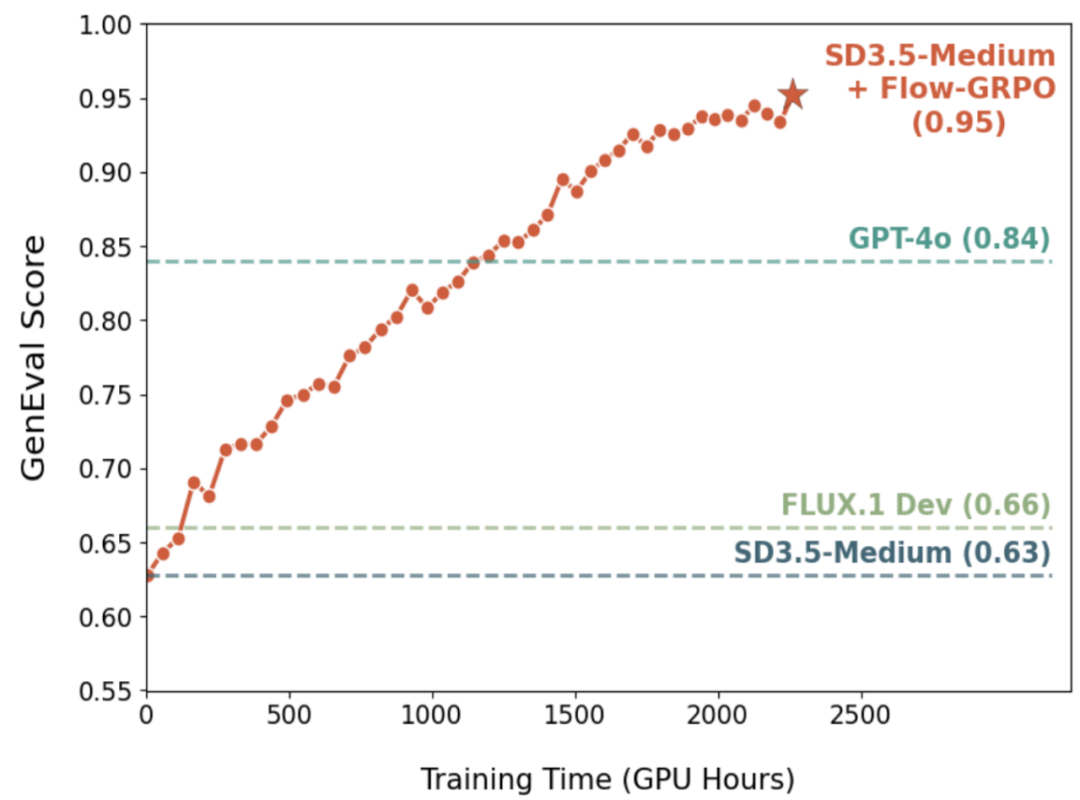
为此,港中文 MMLab、快手可灵、清华大学等团队联合提出 Flow-GRPO,首个将在线强化学习引入 Flow Matching 模型的工作。在 Flow-GRPO 加持下,SD3.5 Medium 在 GenEval 基准测试中的准确率从 63% 提升到 95%,组合式生图能力超越 GPT4o,这说明流匹配模型还有很大提升空间,Flow-GRPO 的成功实践,为未来利用 RL 进一步解锁和增强各类流匹配生成模型(包括但不限于图像、视频、3D 等)在可控性、组合性、推理能力方面的潜力,开辟了充满希望的新范式。

-
论文标题:Flow-GRPO: Training Flow Matching Models via Online RL
-
论文链接:https://www.arxiv.org/pdf/2505.05470
-
代码地址:https://github.com/yifan123/flow_grpo
-
模型地址:https://huggingface.co/jieliu/SD3.5M-FlowGRPO-GenEval
作者团队也会尽快提供 Gradio 在线 demo 和包含大量生成 case,强化学习训练过程中图片变化的网页,帮助读者更好地体会 RL 对于流匹配模型的极大提升。
一.核心思路与框架概览
Flow-GRPO 的核心在于两项关键策略,旨在克服在线 RL 与流匹配模型内在特性之间的矛盾,并提升训练效率:
-
ODE-SDE 等价转换: 流匹配模型本质上依赖确定性的常微分方程(ODE)进行生成。为了强化学习探索所需的随机性,作者采用了一种 ODE 到随机微分方程(SDE)的转换机制。该机制在理论上保证了转换后的 SDE 在所有时间步上均能匹配原始 ODE 模型的边缘分布,从而在不改变模型基础特性的前提下,为 RL 提供了有效的探索空间。
-
去噪步数「减负」提效: 在 RL 训练采样时,大胆减少生成步数(例如从 40 步减到 10 步),极大加速数据获取;而在最终推理生成时,仍然使用完整步数,保证高质量输出。在极大提升 online RL 训练效率的同时,保证性能不下降。
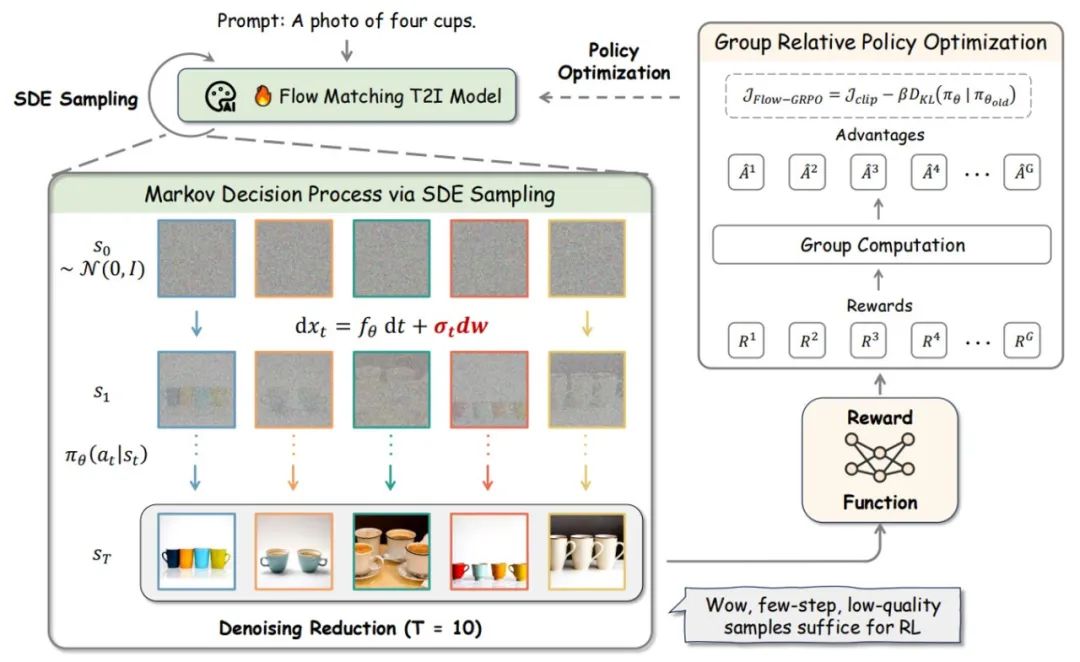
二. ODE to SDE
GRPO 的核心是依赖随机采样过程,以生成多样化的轨迹批次用于优势估计和策略探索。但对于流匹配模型,其确定性的采样过程不满足 GRPO 要求。为了解决这个局限性,作者将确定性的 Flow-ODE 转换为一个等效的 SDE,它匹配原始模型的边际概率密度函数,在论文附录 A 中作者提供了详细的证明过程。原始的 flow matching 模型 inference 的时候按照如下公式:
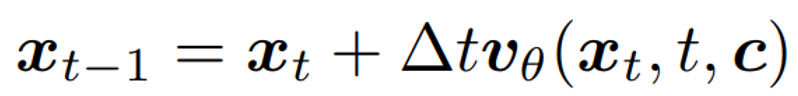
转变成 SDE 后,最终作者得到的采样形式如下:
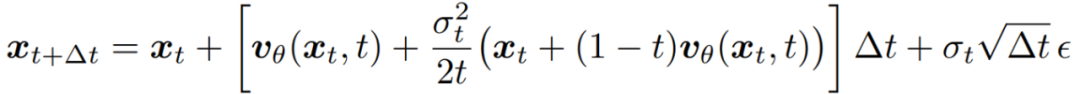
之后就可以通过控制噪声水平的参数很好地控制 RL 策略的探索性。
三.Denoising Reduction
为了生成高质量的图像,流模型通常需要大量的去噪步骤,这使得在线强化学习的训练数据收集成本较高。作者发现,对于在线强化学习训练,较大的时间步长在样本生成时是多余的,只需要在推理时保持原有的去噪步骤仍能获得高质量的样本。作者在训练时将时间步长设置为 10,而推理时的时间步长保持为原始的默认设置 40。通过这样的「训练时低配,测试时满配」的设置,达到了在不牺牲最终性能的情况下实现快速训练。
四.核心实验效果
Flow-GRPO 在多个 T2I(文本到图像)生成任务中表现卓越:
-
复杂组合生成能力大幅提升: 在 GenEval 基准上,将 SD3.5-M 的准确率从 63% 提升至 95%,在物体计数、空间关系理解、属性绑定上近乎完美,在该评测榜单上效果超越 GPT-4o!
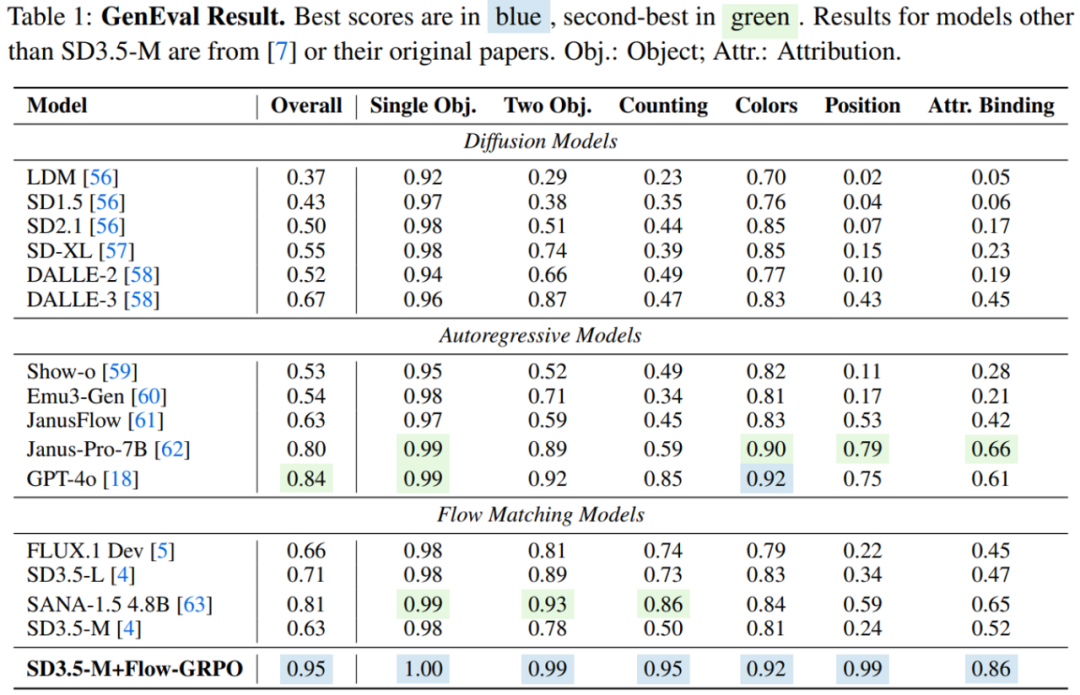

-
文字渲染精准无误: 视觉文本渲染准确率从 59% 大幅提升至 92%,可以较为准确地在图片中渲染文字。

-
更懂人类偏好: 在人类偏好对齐任务上也取得了显著进步。

-
奖励黑客行为显著减少: Flow-GRPO 在性能提升的同时,图像质量和多样性基本未受影响,有效缓解 reward hacking 问题。
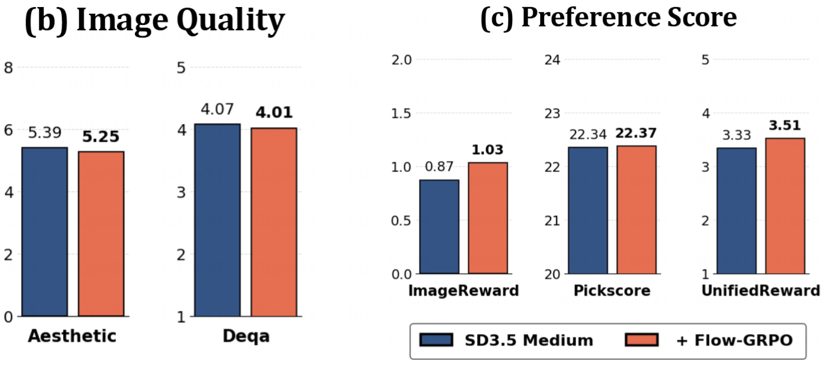
五.总结与展望
作为首个将在线强化学习引入流匹配模型的算法,Flow-GRPO 通过将流模型的确定性采样机制改为随机微分方程(SDE)采样,并引入 Denoising Reduction 技术,实现了在流匹配模型上的高效在线强化学习。实验结果显示,即便是当前最先进的 flow matching 模型,在引入强化学习后依然有显著的性能提升空间。Flow-GRPO 在组合式生成、文字渲染和人类偏好等任务上,相比基线模型均取得了大幅改进。
Flow-GRPO 的意义不仅体现在指标上的领先,更在于其揭示了一条利用在线强化学习持续提升流匹配生成模型性能的可行路径。其成功实践为未来进一步释放流匹配模型在可控性、组合性与推理能力方面的潜力,尤其在图像、视频、3D 等多模态生成任务中,提供了一个充满前景的新范式。
(文:极市干货)