

本文由 @Simon V(https://github.com/simveit) 授权转载和翻译并发表到本公众号。原始地址为:https://veitner.bearblog.dev/how-to-use-reasoning-models-with-sglang/
在SGLang中使用reasoning模型
2025年5月11日
在本文档中,我们将为希望快速上手SGLang的人提供一个实用资源。SGLang是一个高性能的LLM推理引擎,可以很好地扩展到大量GPU(https://lmsys.org/blog/2025-05-05-large-scale-ep/)。我们将使用新的Qwen3(https://github.com/QwenLM/Qwen3)模型系列,它在SGLang上获得了首日支持。在这篇博文中,我们将使用8B模型。如果你使用较小的GPU,请查看一些较小的Qwen模型,它们同样出色。
设置开发环境
使用以下命令运行一个已设置好SGLang并可以使用的docker容器
docker run -it --name h100_simon --gpus device=7 \
--shm-size 32g \
-v /.cache:/root/.cache \
--ipc=host \
lmsysorg/sglang:dev \
/bin/zsh
从现在开始,我们将在这个docker容器内工作。注意:我在上面选择了device = 7,你当然可以选择任何设备或全部使用所有可用的GPU。
基本推理
使用
python3 -m sglang.launch_server --model-path Qwen/Qwen3-8B
来启动服务器。最初这将花费一些时间,因为需要下载模型权重,之后服务器启动会快得多。有关其他服务器参数,请参阅相应的文档(https://docs.sglang.ai/backend/server_arguments.html)。
服务器启动后,你将在终端中看到:
The server is fired up and ready to roll!
现在我们已准备好执行推理。
要使用Qwen3,请执行以下程序:
from openai import OpenAI
# Set OpenAI's API key and API base to use SGLang's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:30000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen/Qwen3-8B",
messages=[
{"role": "user", "content": "Give me a short introduction to large language models."},
],
max_tokens=32768,
temperature=0.6,
top_p=0.95,
extra_body={
"top_k": 20,
},
)
print("Chat response:", chat_response)
你将收到如下响应
Chat response: ChatCompletion(id='f5f49f3ca0034271b847d960df16563e', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content="<think>\nOkay, the user wants a short introduction to large language models. Let me start by defining what they are. They're AI systems trained on massive amounts of text data. I should mention their ability to understand and generate human-like text. Maybe include some examples like GPT or BERT. Also, highlight their applications in tasks like answering questions, writing, coding, and more. Keep it concise but cover the key points. Avoid technical jargon so it's accessible. Make sure to note that they're part of the broader field of NLP. Check if there's anything else important, like their training process or significance. Alright, that should cover it.\n</think>\n\nLarge language models (LLMs) are advanced artificial intelligence systems trained on vast amounts of text data to understand and generate human-like language. They can perform tasks such as answering questions, writing stories, coding, and translating languages by recognizing patterns in text. These models, like GPT or BERT, leverage deep learning to process and produce coherent responses, making them powerful tools in natural language processing (NLP) and a cornerstone of modern AI applications.", refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None, reasoning_content=None), matched_stop=151645)], created=1746716570, model='Qwen/Qwen3-8B', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=227, prompt_tokens=18, total_tokens=245, completion_tokens_details=None, prompt_tokens_details=None))
获取响应的另一种等效方式是使用curl
curl http://localhost:30000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "Qwen/Qwen3-8B",
"messages": [
{"role": "user", "content": "Give me a short introduction to large language models."}
],
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20,
"max_tokens": 32768
}'
然后你将收到以下格式的响应:
{"id":"25f606ceada843eb8d980114b0475d87","object":"chat.completion","created":1746716675,"model":"Qwen/Qwen3-8B","choices":[{"index":0,"message":{"role":"assistant","content":"<think>\nOkay, the user wants a short introduction to large language models. Let me start by defining what they are. I should mention that they are AI systems trained on vast amounts of text data. Then, maybe explain how they work, like using deep learning and neural networks. It's important to highlight their ability to understand and generate human-like text. I should also touch on their applications, such as answering questions, creating content, coding, etc. Oh, and maybe mention some examples like GPT or BERT. Wait, the user might not know specific models, so I should keep it general. Also, I need to keep it concise since they asked for a short intro. Let me make sure not to get too technical. Maybe include something about their scale, like the number of parameters. But don't go into too much detail. Alright, let me put that together in a clear, straightforward way.\n</think>\n\nLarge language models (LLMs) are advanced AI systems trained on vast amounts of text data to understand and generate human-like language. They use deep learning techniques, such as transformer architectures, to process and analyze patterns in text, enabling tasks like answering questions, creating content, coding, and even reasoning. These models, often with billions of parameters, excel at tasks requiring contextual understanding and can adapt to diverse applications, from customer service to research. Notable examples include models like GPT, BERT, and others developed by companies like OpenAI and Google. Their ability to mimic human language makes them powerful tools for automation, creativity, and problem-solving.","reasoning_content":null,"tool_calls":null},"logprobs":null,"finish_reason":"stop","matched_stop":151645}],"usage":{"prompt_tokens":18,"total_tokens":335,"completion_tokens":317,"prompt_tokens_details":null}}
解析推理内容
我们可能想将推理内容与响应的其余部分分开。SGLang通过提供额外的服务器参数--reasoning-parser提供了这种能力。
要启动带有推理解析器的模型,请执行:
python3 -m sglang.launch_server --model-path Qwen/Qwen3-8B --reasoning-parser qwen3
然后我们可以按如下方式将推理与内容的其余部分分开:
from openai import OpenAI
# Set OpenAI's API key and API base to use SGLang's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:30000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen/Qwen3-8B",
messages=[
{"role": "user", "content": "Give me a short introduction to large language models."},
],
max_tokens=32768,
temperature=0.6,
top_p=0.95,
extra_body={
"top_k": 20,
"separate_reasoning": True
},
)
print("==== Reasoning ====")
print(chat_response.choices[0].message.reasoning_content)
print("==== Text ====")
print(chat_response.choices[0].message.content)
这将给我们
==== Reasoning ====
Okay, the user wants a short introduction to large language models. Let me start by defining what they are. They are AI systems trained on massive amounts of text data. I should mention their ability to understand and generate human-like text. Maybe include examples like GPT or BERT. Also, highlight their applications in various fields. Need to keep it concise but informative. Let me check if I'm missing any key points. Oh, maybe mention the training process and the scale of data. Avoid technical jargon to keep it accessible. Alright, that should cover the basics without being too lengthy.
==== Text ====
Large language models (LLMs) are advanced artificial intelligence systems trained on vast amounts of text data to understand and generate human-like language. These models, such as GPT or BERT, use deep learning techniques to recognize patterns, answer questions, and create coherent text across diverse topics. Their ability to process and generate natural language makes them valuable for tasks like translation, summarization, chatbots, and content creation. LLMs continue to evolve, driving innovations in fields like education, healthcare, and customer service.
更多详细信息,请参阅推理解析器的文档(https://docs.sglang.ai/backend/separate_reasoning.html)。
结构化输出
结构化输出是LLM的一个有趣应用。我们可以使用它们来结构化以前非结构化的数据,并将其转换为可以进一步处理的格式。
以下脚本可以生成结构化输出,在使用reasoning-parser启动服务器后:
from openai import OpenAI
from pydantic import BaseModel, Field
# Set OpenAI's API key and API base to use SGLang's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:30000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
# Define the schema using Pydantic
class CapitalInfo(BaseModel):
name: str = Field(..., pattern=r"^\w+$", description="Name of the capital city")
population: int = Field(..., description="Population of the capital city")
response = client.chat.completions.create(
model="Qwen/Qwen3-8B",
messages=[
{
"role": "system",
"content": "Please extract the name and population of the given country as JSON schema."
},
{
"role": "user",
"content": "Please extract name and population of the Capital of France.",
},
],
temperature=0,
max_tokens=2048,
response_format={
"type": "json_schema",
"json_schema": {
"name": "foo",
# convert the pydantic model to json schema
"schema": CapitalInfo.model_json_schema(),
},
},
)
print(
f"reasoning content: {response.choices[0].message.reasoning_content}\n\ncontent: {response.choices[0].message.content}"
)
这里我们使用Pydantic(https://docs.pydantic.dev/latest/)以一种方便的方式来制定我们的结构。
reasoning content: Okay, the user is asking for the name and population of the capital of France. Let me break this down.
First, I need to confirm which city is the capital of France. I know that France's capital is Paris. So the name part is straightforward.
Next, the population. I remember that Paris has a population of around 2.1 million people. But wait, I should check if that's the latest data. The most recent estimates might be a bit higher or lower. Let me think—maybe the 2023 estimate is about 2.16 million? Or is it 2.1 million? I think the commonly cited figure is approximately 2.1 million, but I should be precise.
Wait, the user might be expecting the exact number. Let me recall. The population of Paris is often cited as around 2.1 million, but the exact figure can vary. For example, the 2022 estimate was about 2.16 million. However, sometimes sources round it to 2.1 million for simplicity.
I need to make sure I'm not giving outdated information. If I can't recall the exact number, it's better to state the approximate figure. Also, the user might not need the most precise number, just a reasonable estimate.
So, putting it all together, the capital of France is Paris, and its population is approximately 2.1 million. I should present this as a JSON object with "name" and "population" keys. Let me double-check the structure to ensure it's correct. The JSON should have the name as a string and population as a number.
Wait, the user said "population of the Capital of France," so the capital is Paris, and the population is that of Paris. I need to make sure there's no confusion with the population of France as a country versus the capital city. The question specifically asks for the capital's population, so Paris is correct.
Alright, I think that's all. The JSON should be accurate and clear.
content: {
"name": "Paris",
"population": 2100000
}
更多信息请参阅相应的SGLang文档(https://docs.sglang.ai/backend/structured_outputs_for_reasoning_models.html)。
多GPU使用
我们想使用多个GPU的原因有多种。
-
模型无法放入单个GPU。 -
我们想利用多个GPU并行处理输入。
第一个问题可以通过张量并行解决,即我们以分片方式将模型权重分布到多个GPU上。请注意,这种技术主要用于解决内存限制问题,而不是为了获得更高的吞吐量。第二个问题可以通过数据并行解决,即我们在多个GPU上复制模型,并将请求并行发送到其中一个。
SGLang的router可以方便地利用多个GPU。
可以通过pip install sglang-router安装。
让我们修改上面的docker启动脚本以使用多个GPU,即
docker run -it --name h100_simon --gpus '"device=6,7"' \
--shm-size 32g \
-v /.cache:/root/.cache \
--ipc=host \
lmsysorg/sglang:dev \
/bin/zsh
张量并行和数据并行大小可以通过服务器参数dp-size和tp-size控制。使用router以数据并行模式启动非常简单:
python3 -m sglang_router.launch_server --model-path Qwen/Qwen3-8B --dp-size 2
我们会通过类似这样的消息得到进程成功完成的通知:
✅ Serving workers on ["http://127.0.0.1:31000", "http://127.0.0.1:31186"]
请注意,你需要满足dp_size * tp_size = #GPUs。
让我们模拟一个重负载工作。注意,我们在这里不调整最高性能。这只是为了显示router按预期工作并在两个GPU上处理请求。请观察启动router的终端以更好地理解。要了解命令行参数,请参考bench_serving.py(https://github.com/sgl-project/sglang/blob/main/python/sglang/bench_serving.py)。
python3 -m sglang.bench_serving --backend sglang --dataset-name random --num-prompts 1000 --random-input 4096 --random-output 4096 --random-range-ratio 0.5
你可以执行
watch nvidia-smi
看到两个GPU都被大量使用:
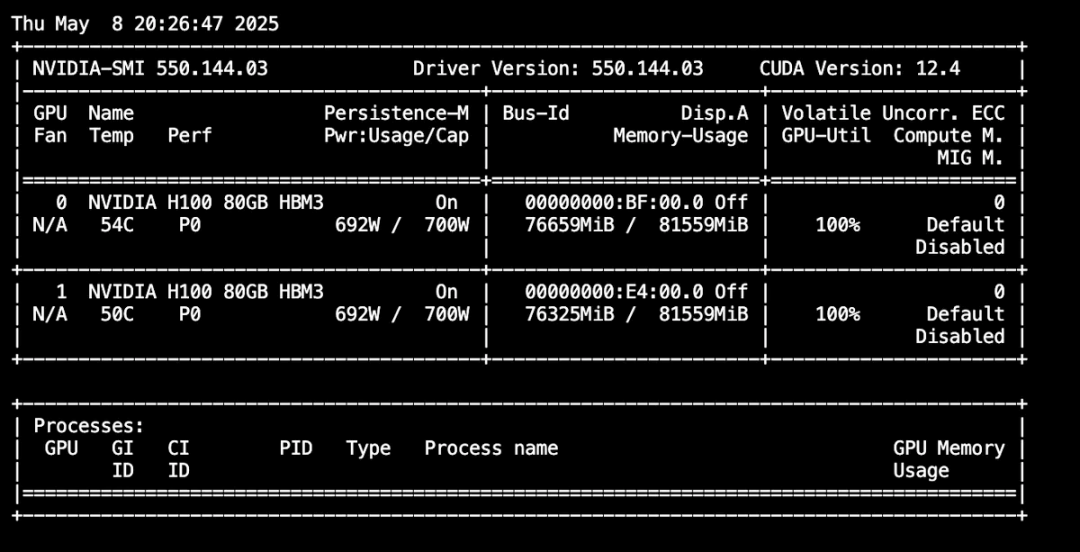
结论
我希望这篇博客使SGLang和SGLang中的推理模型更加易于理解。如果你有更多问题,请告诉我。你可以通过LinkedIn联系我。
关于SGLang有多个有价值的资源
-
SGLang是开源的,它的代码库(https://github.com/sgl-project/sglang)自然是一个很有价值的资源。 -
文档(https://docs.sglang.ai/index.html)包含许多例子(https://github.com/sgl-project/sglang/tree/main/examples)。还有例子文件夹。 -
SGLang仓库的benchmark(https://github.com/sgl-project/sglang/tree/main/benchmark)文件夹包含更多复杂的例子。 -
技术深入解析可以在Awesome-ML-Sys(https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/tree/main/sglang)教程仓库的代码走读(https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/tree/main/sglang/code-walk-through)中找到。 -
SGLang Slack频道是一个很有帮助的社区。
(文:GiantPandaCV)