

你是否想过,LLM训练自己的数据,还能比人类筛选的更高效?传统code大模型依赖人工制定规则筛选数据,成本高、效率低,还容易带偏模型。
论文:Seed-Coder: Let the Code Model Curate Data for Itself
链接:https://github.com/ByteDance-Seed/Seed-Coder/blob/master/Seed-Coder.pdf
而Seed-Coder团队直接“让LLM自己当老师”,用模型筛选数据训练自己,打造出一系列8B参数的轻量级开源代码模型,性能甚至超越百亿级对手!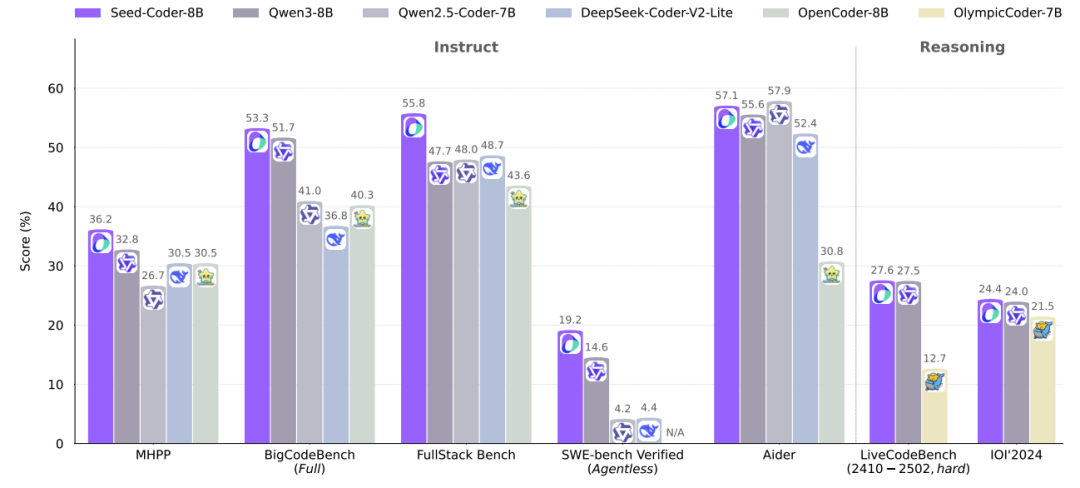
Seed-Coder
1. 自给自足的数据工厂
传统模型依赖人工规则过滤代码数据,比如“必须包含注释”“不能有语法错误”。但程序员审美各异,规则容易打架,扩展性差。
Seed-Coder的解决方案很“暴力”:让另一个LLM当裁判!团队训练了一个“代码质量评分器”,用LLM从可读性、模块化、清晰度、复用性四个维度给代码打分,自动过滤低质量数据。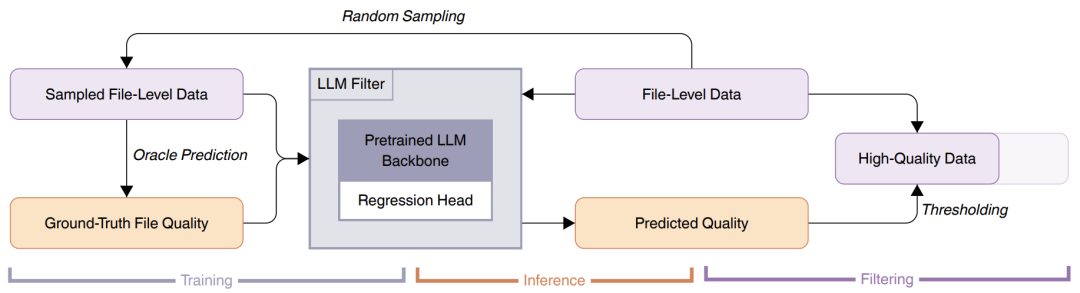 这种“LLM教LLM”的模式,让数据筛选效率提升百倍,最终构建了6万亿token的高质量代码训练库,支持89种编程语言!
这种“LLM教LLM”的模式,让数据筛选效率提升百倍,最终构建了6万亿token的高质量代码训练库,支持89种编程语言!
2. 小身材大智慧的模型架构
Seed-Coder基于Llama 3架构,8.2B参数:
-
长上下文支持:通过仓库级代码拼接,模型能处理32K超长代码文件,轻松应对复杂项目。 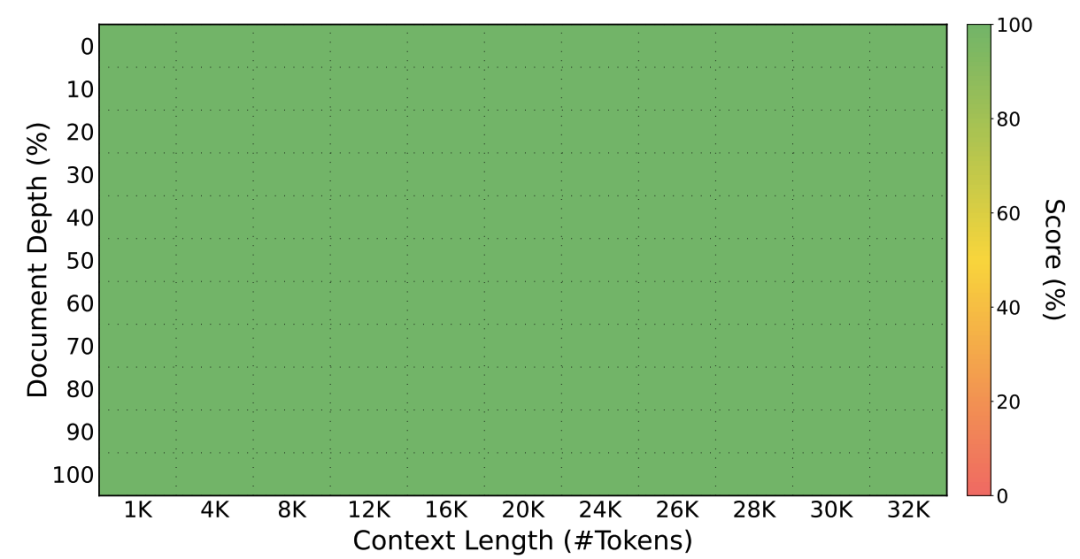
-
填空训练法(FIM):把代码随机拆成前缀、中缀、后缀,让模型学会“补全中间缺漏”,提升代码补全能力。公式如下: <[fim-suffix]> SUFFIX <[fim-prefix]> PREFIX <[fim-middle]> MIDDLE
这种训练让模型像玩拼图一样学习代码逻辑,效果远超传统单模式训练。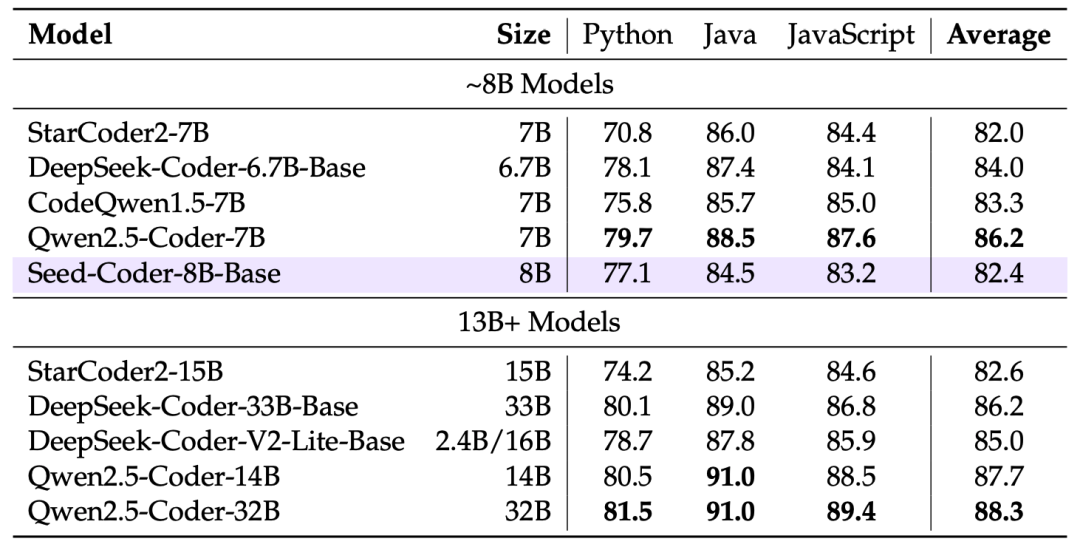
3. 推理能力的训练法
Seed-Coder的推理模型用长思维链强化学习(LongCoT),专攻多步骤复杂编码问题。简单说,就是让模型先写解题思路,再生成代码,并通过反复试错优化逻辑链。
比如解算法题时,模型会先拆分问题:“第一步读输入,第二步排序,第三步计算极差……”再一步步写代码。这种“先想后做”的策略,让它在竞赛级题库中表现惊艳。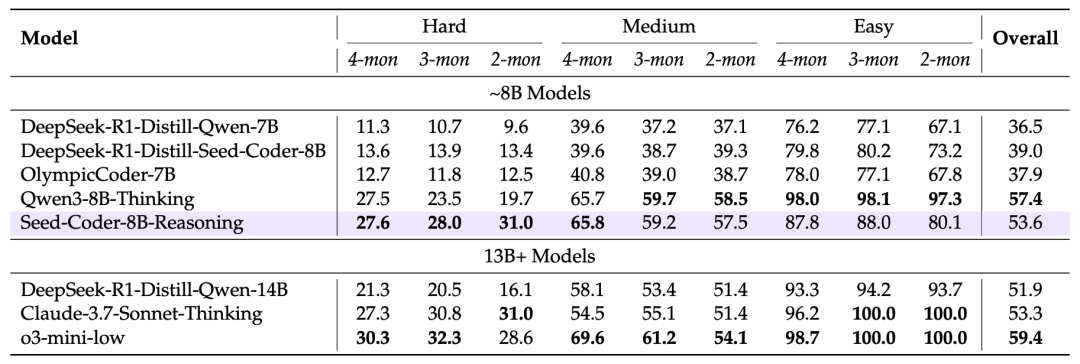
实际表现
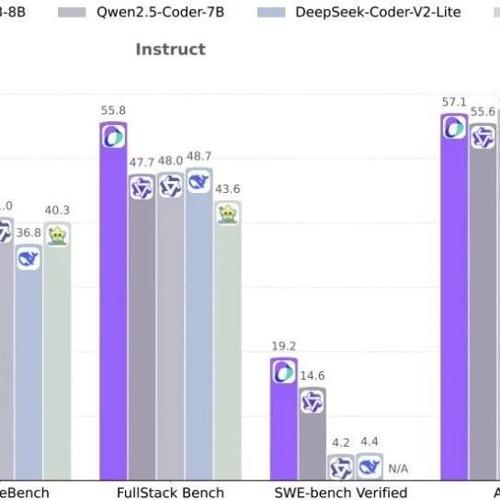
Seed-Coder在多个权威测试中碾压对手:
-
代码生成:在HumanEval+测试中,8B模型得分77.4,超过70B参数的CodeLlama! 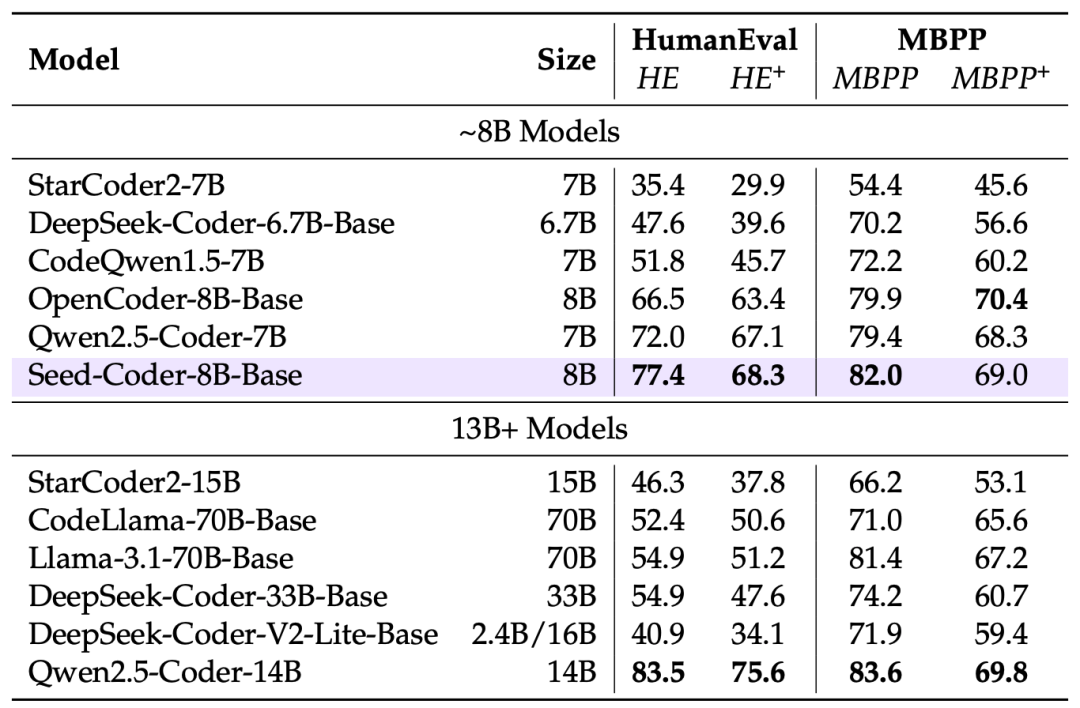
-
代码补全:面对跨文件补全任务,Seed-Coder的编辑相似度(ES)高达85.1%,吊打同规模模型。 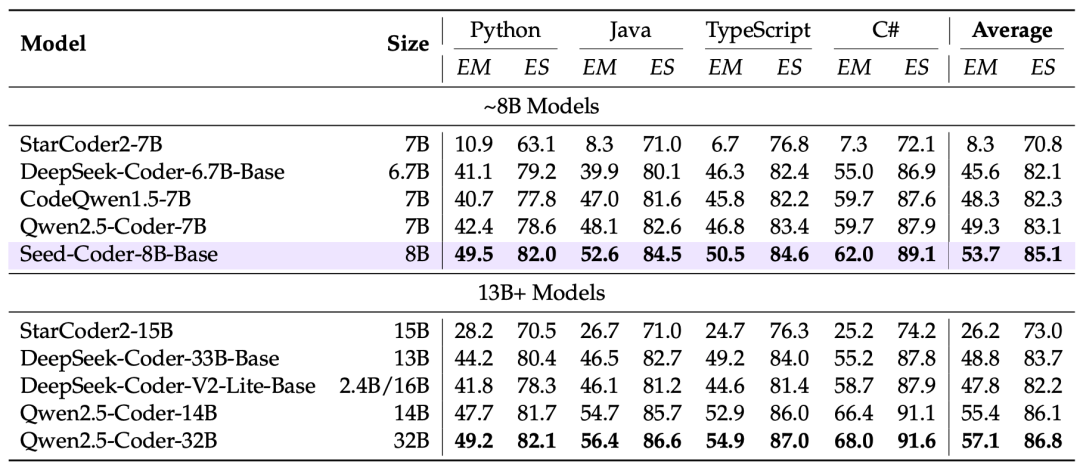
-
软件工程实战:在GitHub真实问题修复测试(SWE-bench)中,Seed-Coder解决率19.2%,比32B模型QwQ还高! 
更惊人的是,它甚至能在竞赛编程平台Codeforces上达到1553分,接近人类铜奖水平!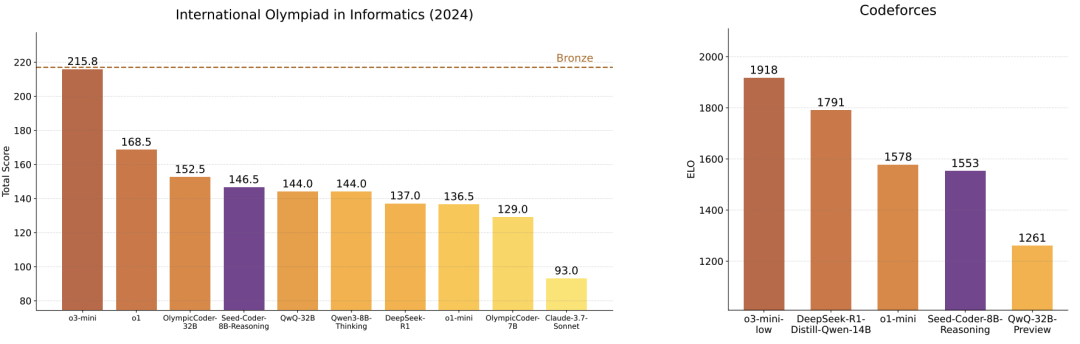
未来展望:AI程序员要抢饭碗了?
尽管Seed-Coder表现亮眼,仍有局限:
-
通用能力不足:专注代码导致常识理解较弱,比如无法回答“如何做番茄炒蛋”。 -
数学能力短板:训练数据中数学内容较少,解复杂数学题时容易翻车。
但团队已规划未来方向:
-
融合更多通用语料,打造“全能型”AI程序员 -
探索MoE架构,进一步压缩模型体积
可以预见,这类轻量高效的代码模型将加速渗透开发工具链,成为程序员24小时在线的“超级助手”已经不远了~(既感到欣慰,又感到危险有木有!
(文:机器学习算法与自然语言处理)