


新智元报道
新智元报道
【新智元导读】谷歌最新发布的76页AI智能体白皮书,深入剖析了智能体的应用前景。智能体通过感知环境、调用工具和自主规划,能够完成复杂任务并做出高级决策。从智能体运维(AgentOps)到多智能体协作,这份白皮书为AI智能体指明了方向。
近日,谷歌发表了76页的AI智能体白皮书!
智能体通过感知环境,并利用工具策略性地采取行动,实现特定目标。
其核心原理,是将推理能力、逻辑思维以及获取外部信息的能力融合,完成一些基础模型难以实现的任务,做出更复杂的决策。
这些智能体具备自主运行的能力,它们可以追寻目标,主动规划后续行动,无需明确指令就能行动。
参考链接:https://www.kaggle.com/whitepaper-agent-companion
白皮书深入探讨了智能体的评估方法,介绍了谷歌智能体产品在实际应用中的情况。
参与过生成式AI开发的人都知道,从一个创意发展到概念验证阶段并不难,但想保证最终成果的高质量,并将其投入实际生产,就没那么简单了。
在将智能体部署到生产环境时,质量和可靠性是最大的问题,智能体运维(AgentOps)流程是优化智能体构建过程的有效方案。

过去两年,生成式AI(GenAI)发生了巨大变革,企业客户越来越关注如何将解决方案真正应用到实际业务中。
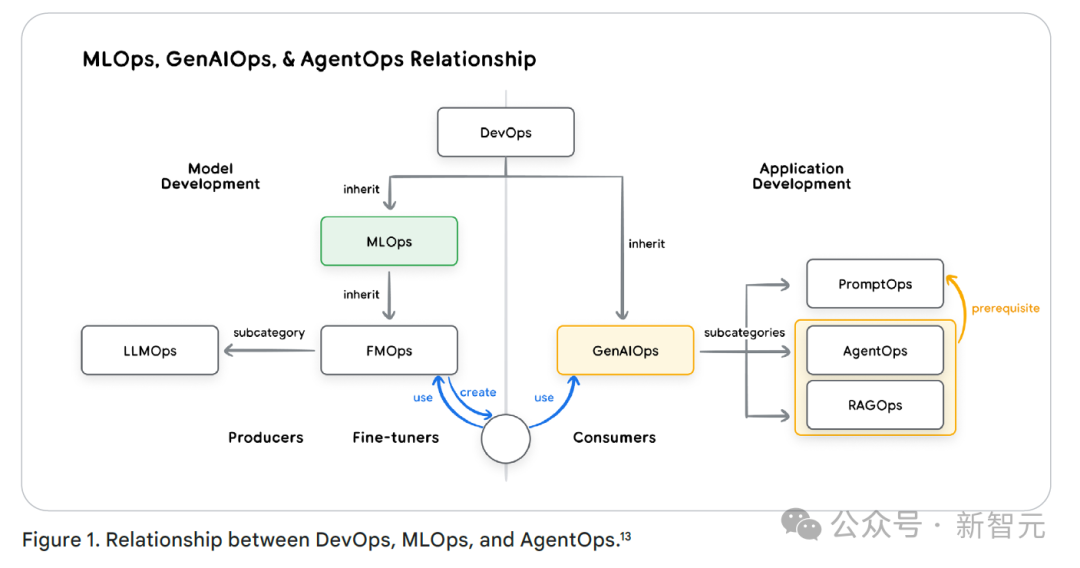
智能体与运维(AgentOps)属于生成式AI运维的一个分支,重点关注如何让智能体更高效地运行。
AgentOps新增了一些关键组件,包括对内部和外部工具的管理、智能体核心提示(像目标、配置文件、操作指令)的设置与编排、记忆功能的实现,任务分解等。
开发运维(DevOps)是整个技术运营体系的基石。
模型应用开发在一定程度上继承了DevOps的理念和方法,机器学习运维(MLOps)则是在DevOps的基础上,针对模型的特点发展而来的。
运维离不开版本控制、通过持续集成 / 持续交付(CI/CD)实现的自动化部署、测试、日志记录、安全保障,以及指标衡量等能力。
每个系统通常会根据指标进行优化,衡量系统的工作情况、评估结果和业务指标,然后通过自动化流程获取更全面的指标,一步步提升系统性能。
不管叫「A/B测试」「机器学习运维」,还是「指标驱动开发」,本质上都基于相同的理念,AgentOps中也会遵循这些原则。
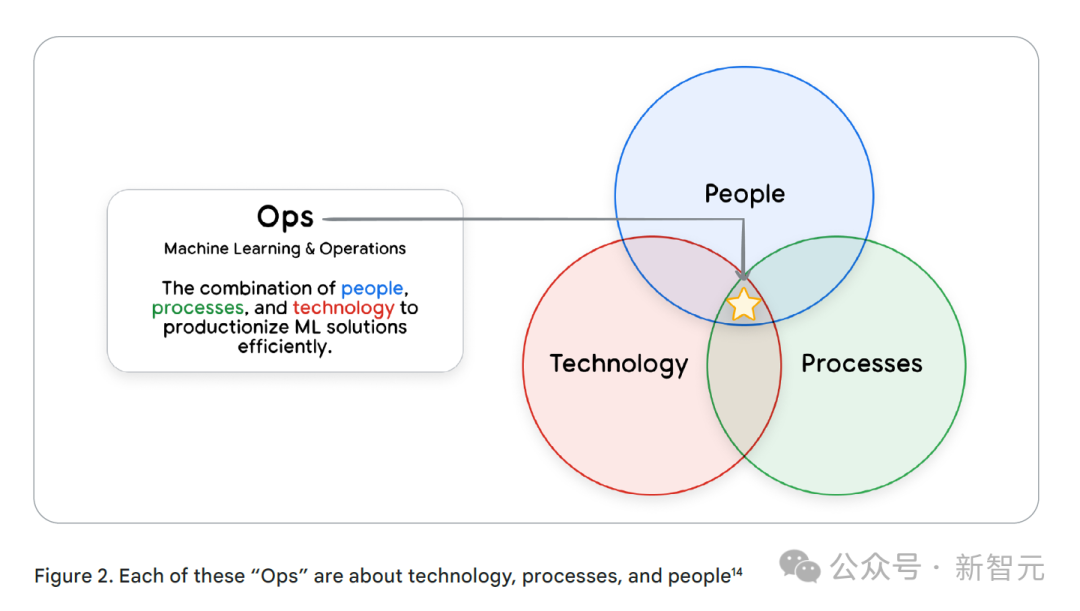
需要注意的是,新的技术实践并不会完全取代旧的。
DevOps和MLOps中的优秀实践经验,对于AgentOps来说依然不可或缺,它们是AgentOps顺利运行的基础。
比如,智能体调用工具时会涉及API,而这个过程中用到的API,和非智能体软件使用的API是一样的。
大多数智能体都是围绕完成特定目标设计的,目标完成率是一个关键指标。
一个大目标往往可以细分成几个关键任务,或者涉及一些关键的用户交互环节。这些关键任务和交互都应单独监测和评估。
每个业务指标、目标,或者关键交互数据,都会按照常见的方式进行汇总统计,比如计算尝试次数、成功次数、成功率等。
另外,从应用程序遥测系统获取的指标,像延迟、错误率等,对智能体也非常重要。
监测这些高级指标,是了解智能体运行状况的重要手段。

用户反馈也是一个不可忽视的指标。
在智能体或任务执行的过程中,一个简单的反馈表,就能帮助了解智能体哪些地方表现得好,哪些地方还需要改进。
这些反馈可能来自普通用户,也可能是企业员工、质量检测人员,或者是相关领域的专家。
想把概念验证阶段的智能体,变成可以真正投入生产使用的产品,一个强大的自动化评估框架必不可少。

在评估特定的智能体应用场景之前,可以先参考一些公开的基准测试和技术报告。
对很多基本能力,像模型性能、是否会产生幻觉、工具调用和规划能力等,都有公开的基准测试。
例如,伯克利函数调用排行榜(BFCL)和τ-bench等基准测试,就能展示智能体的工具调用能力。
PlanBench基准测试,则专注于评估多个领域的规划和推理能力。
工具调用和规划只是智能体能力的一部分。智能体行为,会受到它所使用的LLM和其他组件的影响。
智能体和用户的交互方式,在传统的对话设计系统和工作流系统中也有迹可循,可以借鉴这些系统的评估指标和方法,来衡量智能体的表现。
AgentBench这样的综合智能体基准测试,会在多种场景下对智能体进行全面评估,测试从输入到输出的整体性能。
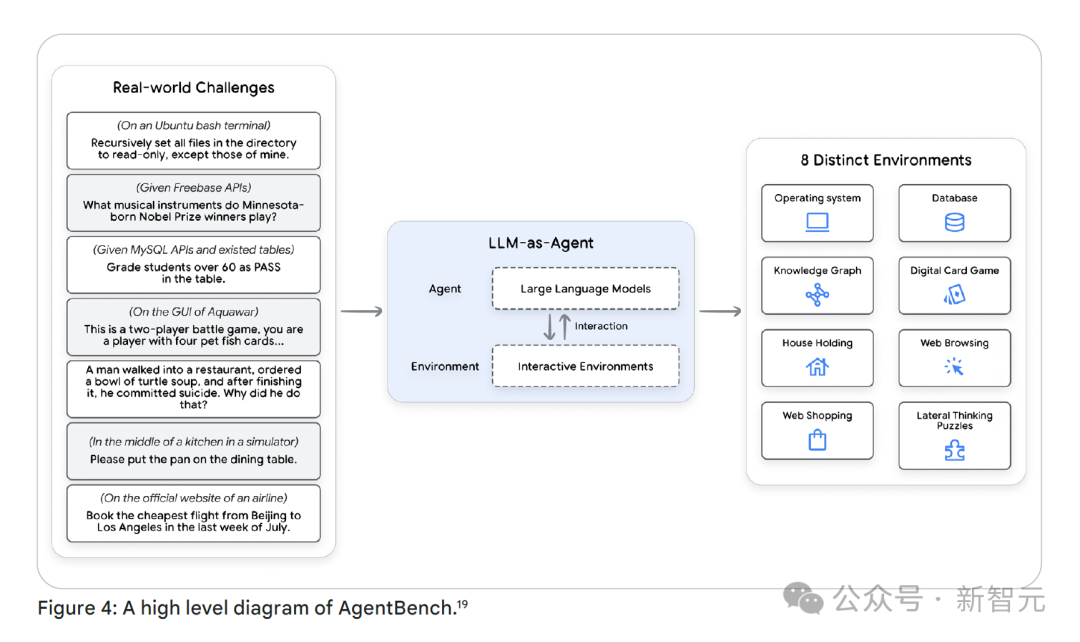
现在,很多公司和组织针对特定的应用场景,设立了专门的公开基准测试,如Adyen的数据分析排行榜DBAStep。
大多数基准测试报告中,都会讨论智能体常见的失败模式,这能为建立适合应用场景的评估框架提供思路。
除了参考公开评估,还要在各种不同的场景中测试智能体的行为。
可以模拟用户和智能体的交互过程,观察它的回应,不仅要评估最终给出的答案,还要关注它得出答案的过程,也就是行动轨迹。
软件工程师可以把智能体评估和代码的自动化测试联系起来。在代码测试中,自动化测试能节省时间,还能让开发者对软件质量更有信心。
对于智能体来说,自动化评估同样如此。
精心准备评估数据集非常重要,它要能准确反映智能体在实际应用中会遇到的情况,这点甚至比软件测试中的数据集准备还要关键。
智能体在回复用户之前,通常会执行一系列操作。
比如,它可能会对比用户输入和会话历史,消除某个术语的歧义;也可能查找政策文档、搜索知识库,或者调用API来保存票据。
这些操作中的每一个,都是其达成目标路径上的一个步骤,也被称为行动轨迹。
每次智能体执行任务时,都存在这样一条行动轨迹。
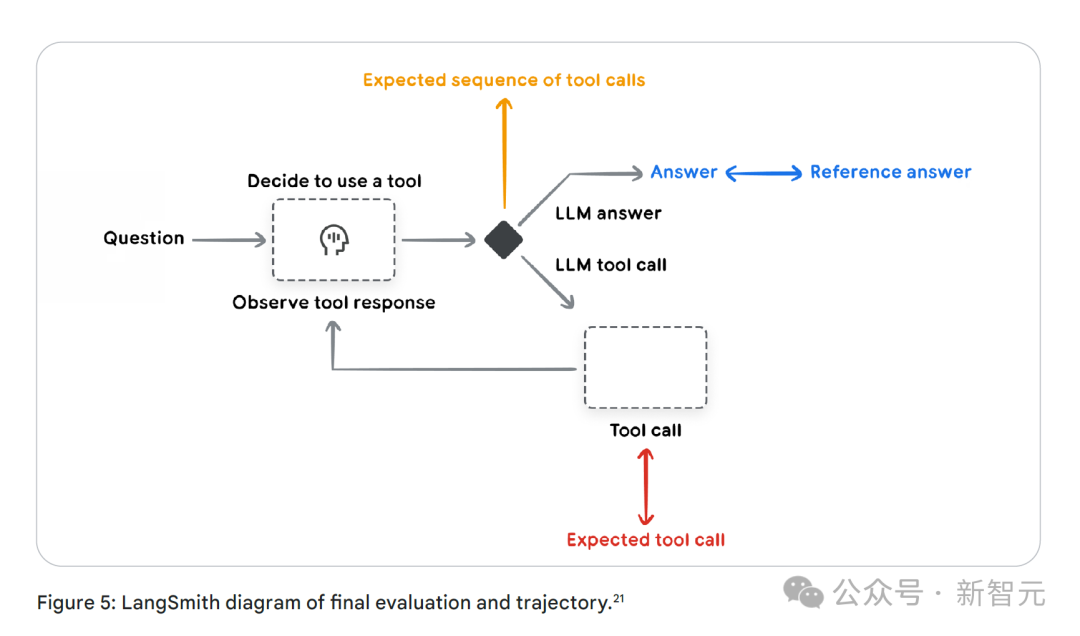
对开发者来说,对比智能体实际采取的行动轨迹和预期的行动轨迹,非常有助于发现问题。
通过对比,能够找出错误或效率低下的环节,提升智能体的性能。
不过,并非所有指标都适用于每种情况。
有些应用场景要求智能体必须严格按理想的行动轨迹执行,而有些场景则允许一定的灵活性和偏差。
这种评估方法也存在明显的局限性,那就是需要有一个参考行动轨迹作为对比依据。
最终响应评估,其实核心是:智能体有没有实现既定目标?
可以根据自身的需求,制定自定义的成功标准来衡量这一点。
比如,评估一个零售聊天机器人能否准确回答产品相关问题;或者判断一个研究智能体,能不能用恰当的语气和风格,有效地总结研究成果。
为了实现评估过程的自动化,可以使用自动评分器。自动评分器本质上是一个LLM,它扮演着评判者的角色。
给定输入提示和智能体生成的响应后,自动评分器会依据用户预先设定的一组标准,对响应进行评估,以此模拟人类的评估过程。
不过要注意,由于这种评估可能没有绝对的事实依据作为参照,精确地定义评估标准就显得尤为关键。
人机协同评估在一些需要主观判断、创造性解决问题的任务中,有很大的价值。
同时,它还能用来校准和检验自动化评估方法,看其是否真的有效,是否符合预期。
人机协同评估主要有以下优点:
-
主观性:人类能够评估一些难以量化的特质,像创造力、常识以及一些细微的差别,这些是机器较难把握的。
-
情境理解:人类评估者可以从更广泛的角度,考虑智能体行动的背景以及产生的影响,做出更全面的判断。
-
迭代改进:人类给出的反馈,能为优化智能体的行为和学习过程,提供非常有价值的见解,助力智能体不断优化。
-
评估评估者:人类反馈还能为校准和优化自动评分器提供参考,让自动评分器的评估更加准确。
多模态生成(如图像、音频、视频)的评估,则更为复杂,需要专门的评估方法和指标。
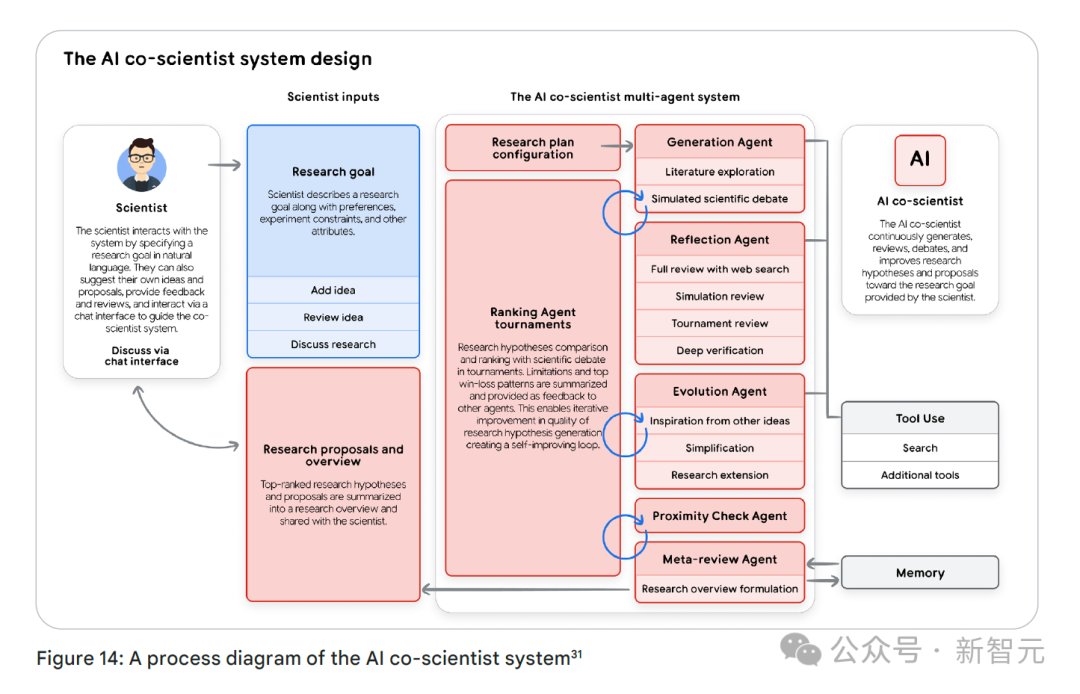
如今,AI系统正朝着多智能体架构方向发生变革。
在这种架构中,多个具有专业能力的智能体相互协作,共同完成复杂的目标。
多智能体系统就好比是一个由专家组成的团队,各自在擅长的领域发挥专长。
每个智能体都是一个独立的个体,它们可能使用不同的LLM,承担独特的角色,并且有着不同的任务背景。
这些智能体通过相互沟通、协作,来实现共同的目标。
这和传统的单智能体系统有很大区别,在单智能体系统中,所有任务都由一个LLM来处理。
多智能体架构会把一个复杂问题拆解成不同的任务,交给专门的智能体去处理。
每个智能体都有明确的角色,它们之间动态互动,以此优化决策过程、提升知识检索效率、确保任务顺利执行。
这种架构实现了更有条理的推理方式、去中心化的问题解决模式,以及可扩展的任务自动化处理。
多智能体系统运用了模块化、协作和分层的设计原则,构建出一个强大的AI生态系统。
智能体可以根据功能分为不同类型,例如:
-
规划智能体:负责将高层次的目标拆解成一个个结构化的子任务,为后续工作制定详细计划。
-
检索智能体:通过动态地从外部获取相关数据,优化知识获取过程,为其他智能体提供信息支持。
-
执行智能体:承担具体的计算工作,生成响应内容,或者与 API 进行交互,实现各种实际操作。
-
评估智能体:对其他智能体生成的响应进行监控和验证,确保符合任务目标,并且逻辑连贯、准确无误。
通过这些组件的协同工作,多智能体架构不再局限于简单的基于提示的交互方式,实现了自适应、可解释且高效的AI驱动工作流程。
多智能体系统评估是在单智能体系统评估的基础上发展而来的。
智能体的成功指标在本质上并没有改变,业务指标依然是核心关注点,其中包括目标和关键任务的完成情况,以及应用程序遥测指标,如延迟和错误率等。
通过对多智能体系统运行过程的跟踪记录,有助于在复杂的交互过程中发现问题、调试系统。
评估行动轨迹和评估最终响应这两种方法,同样适用于多智能体系统。
在多智能体系统中,一个完整的行动轨迹可能涉及多个甚至所有智能体的参与。
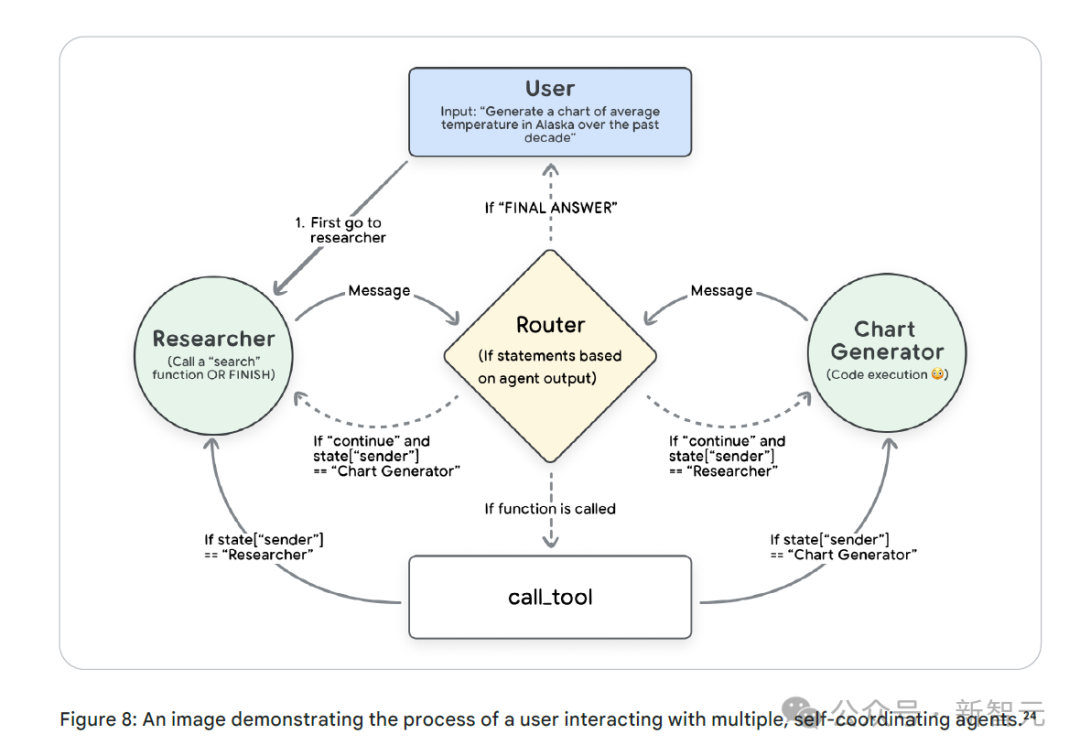
即便多个智能体共同协作完成一个任务,最终呈现给用户的是一个单一的答案,这个答案可以单独进行评估。
由于多智能体系统的任务流程通常更为复杂,步骤更多,所以可以深入到每个步骤进行细致评估。行动轨迹评估是一种可行的、可扩展的评估方法。
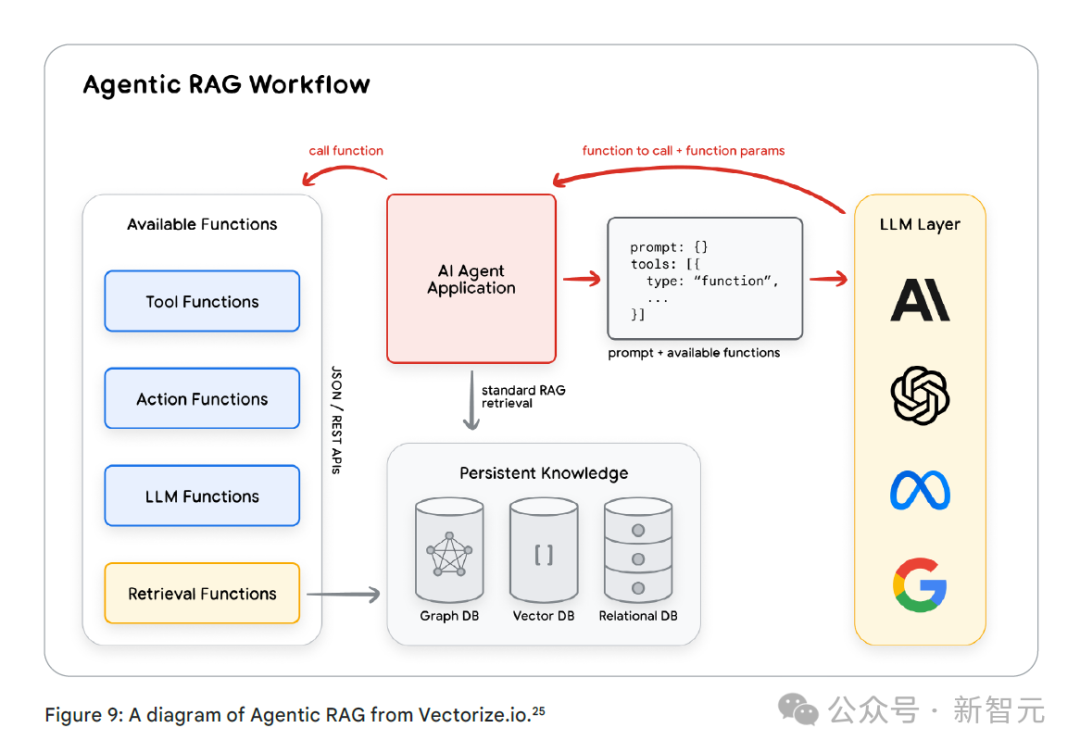
在智能体增强检索生成(Agentic RAG)中,智能体会通过多次搜索来获取所需信息。
在医疗保健领域,智能体增强检索生成可以帮助医生浏览复杂的医学数据库、研究论文和患者记录,为他们提供全面、准确的信息。
Vertex AI Search是一个完全托管的、具有谷歌品质的搜索与检索增强生成(RAG)服务提供商。涵盖数据收集、处理、嵌入、索引 / 排序、生成、验证和服务等流程。
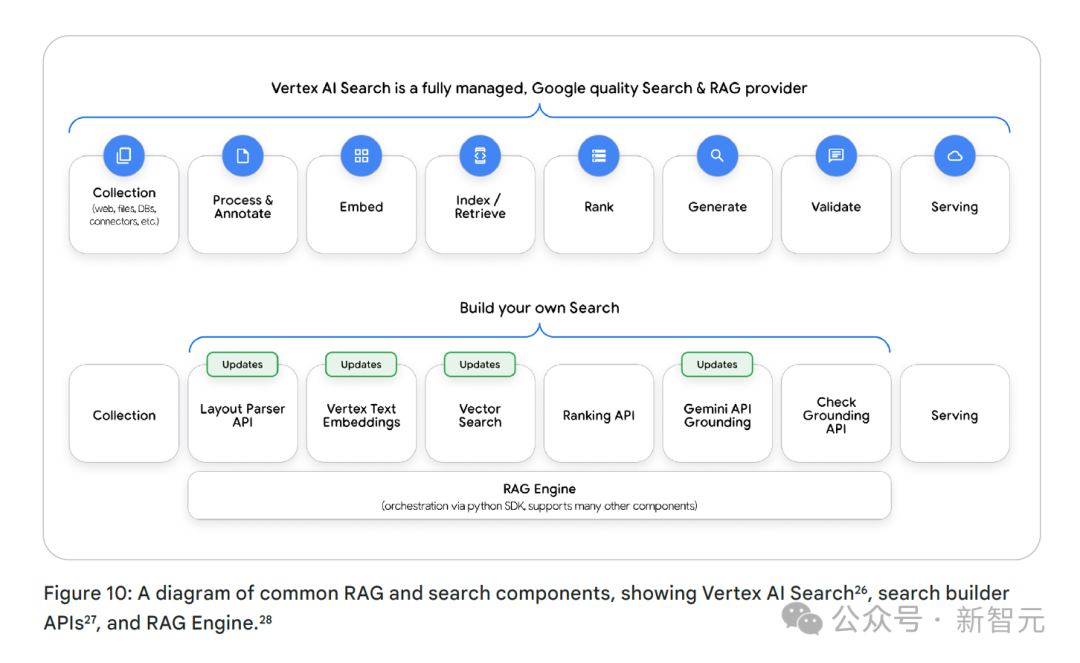
Vertex AI Search拥有布局解析器、向量排序API等组件,还提供RAG引擎,通过Python SDK进行编排,支持众多其他组件。
对于希望构建自己搜索引擎的开发者,上述每个组件都作为独立的API开放,RAG引擎能借助类似LlamaIndex的Python接口轻松编排整个流程。
企业开发并使用智能体,协助员工执行特定任务,或在后台自动化运行。
商业分析师借助AI生成的见解,能轻松挖掘行业趋势,制作极具说服力的数据驱动型演示文稿;人力资源团队可利用智能体优化员工入职流程。
软件工程师依靠智能体,能主动发现并修复漏洞,更高效地进行开发迭代,加快部署进程。
营销人员利用智能体,能深入分析营销效果,优化内容推荐,灵活调整营销活动以提升业绩。
目前,有两类智能体崭露头角:
助手型智能体:这类智能体与用户进行交互,接收任务并执行,然后将结果反馈给用户。
助手型智能体既可以是通用的,也可以专门针对特定领域或任务。
例如,帮助安排会议、分析数据、编写代码、撰写营销文稿、协助销售人员把握销售机会的智能体,甚至还有根据用户要求对特定主题进行深入研究的智能体。
它们响应方式不同,有些能快速同步返回信息或完成任务,有些则需要较长时间运行(比如深度研究型智能体)。
自动化智能体:这类智能体在后台运行,监听事件,监测系统或数据的变化,然后做出合理决策并采取行动。
这些行动包括操作后端系统、进行测试验证、解决问题、通知相关员工等。
如今,知识工作者不再只是简单地调用智能体执行任务并等待结果,他们正逐渐转型为智能体的管理者。
为了便于管理,未来会出现新型用户界面,实现对多智能体系统的编排、监控和管理,这些智能体既能执行任务,还能调用甚至创建其他智能体。
NotebookLM是一款研究和学习工具,旨在简化复杂信息的理解与整合流程。
用户可以上传各种源材料,如文档、笔记和其他相关文件,NotebookLM借助AI技术,助力用户更深入地理解这些内容。
想象一下,在研究复杂主题时,NotebookLM能把零散的资料整合到一个有序的工作空间。
本质上,NotebookLM就像一个专属研究助手,加速研究进程,帮助用户从单纯的信息收集迈向深度理解。
NotebookLM企业版将这些功能引入企业环境,简化员工的数据交互方式,帮他们从中获取有价值的见解。
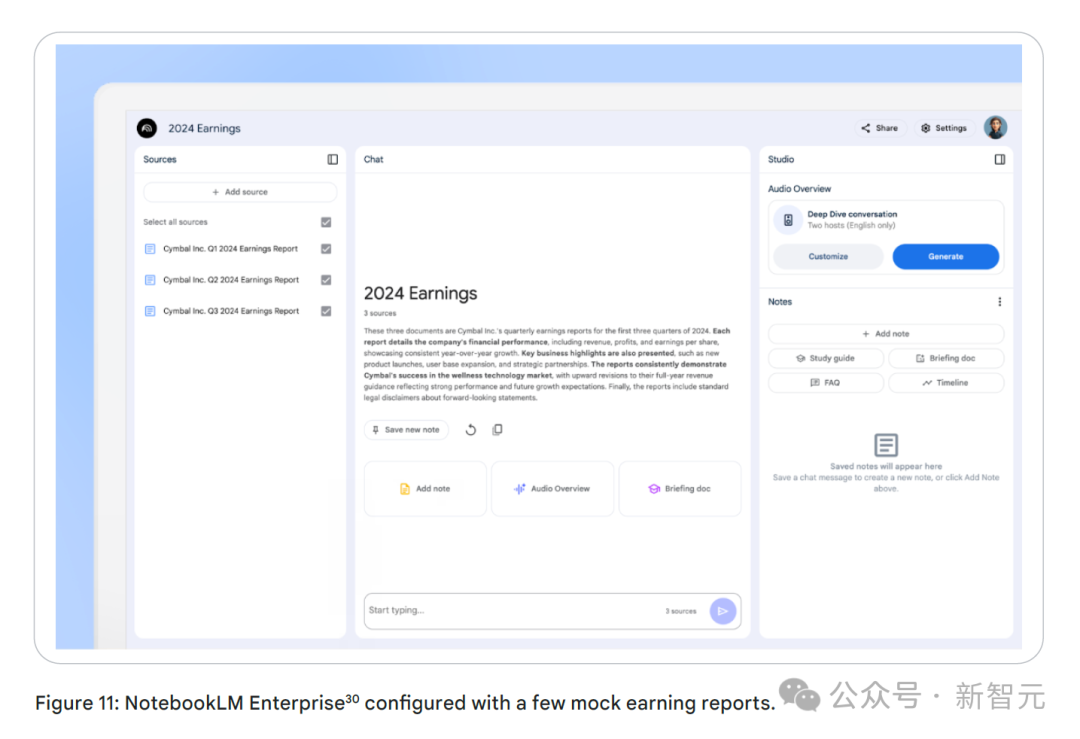
例如,AI生成的音频摘要功能,用户可以通过「听」研究内容来提升理解效率,促进知识吸收。
NotebookLM企业版融入了企业级的安全和隐私功能,严格保护敏感的公司数据,符合相关政策要求。
Google Agentspace提供了一套由AI驱动的工具,旨在通过方便员工获取信息,自动化复杂的智能体工作流程,提升企业生产力。
Agentspace有效解决了传统知识管理系统的固有缺陷,通过整合分散的内容源,生成有依据且个性化的回复、简化业务流程,帮助员工高效获取信息。
Agentspace企业版的架构基于多个核心原则构建。
安全性始终是Google Agentspace的首要关注点。
员工可以通过它获取复杂问题的答案,还能统一访问各类信息源,无论是文档、邮件等非结构化数据,还是表格等结构化数据。
企业可根据自身需求配置一系列智能体,用于深度研究、创意生成与优化、数据分析等工作。
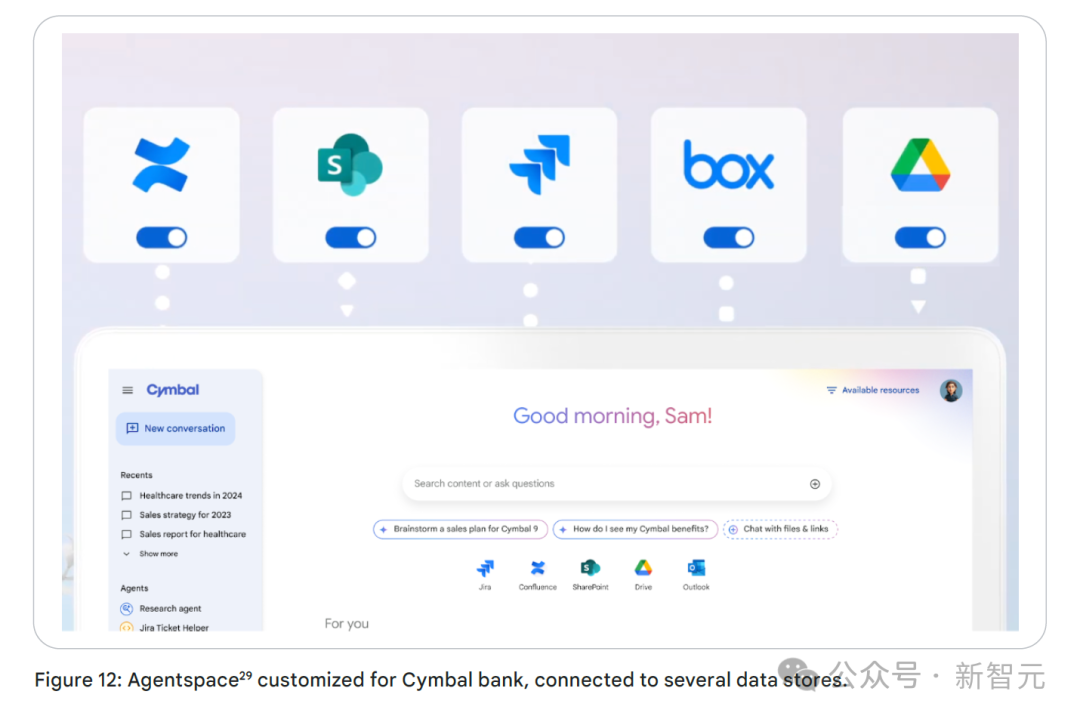
智能体空间企业版还支持创建定制化的AI智能体,满足特定业务需求。
该平台能够开发和部署具有上下文感知能力的智能体,帮助营销、财务、法律、工程等各部门员工高效开展研究、快速生成内容,并实现重复性任务(包括多步骤工作流程)的自动化。
定制智能体可连接内外部系统和数据,贴合公司业务领域和政策要求,甚至能基于专有业务数据训练模型。
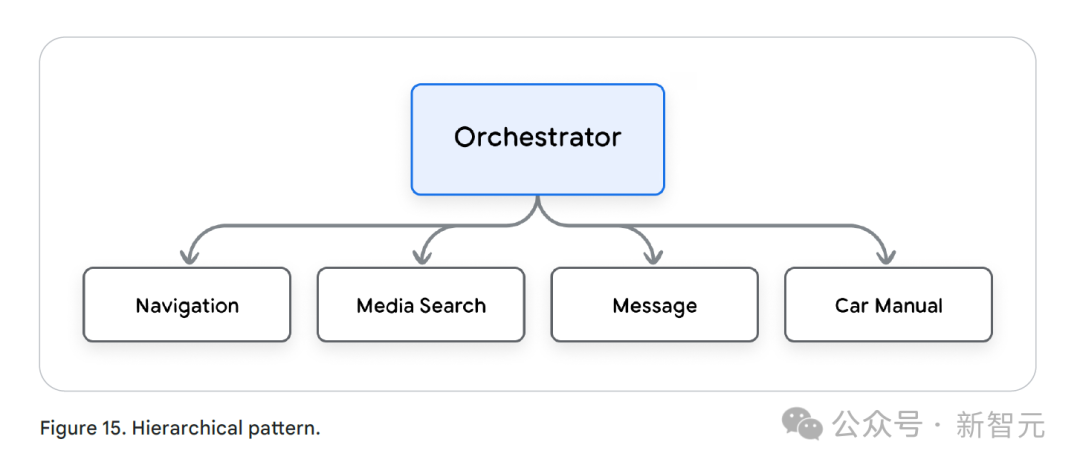
为了说明多智能体概念在实际中的应用,来看一个专为汽车设计的综合多智能体系统。
在这个系统中,多个专用智能体协同工作,为用户带来便捷、流畅的车内体验。
-
对话式导航智能体:专门用于帮助用户查找位置、推荐地点,并借助Google Places和Maps等API进行导航。
-
对话式媒体搜索智能体:专注于帮用户查找和播放音乐、有声读物和播客。
-
消息撰写智能体:帮助用户在驾驶时起草、总结和发送消息或电子邮件。
-
汽车手册智能体:借助检索增强生成(RAG)系统,专门解答与汽车相关的问题。
-
通用知识智能体:解答关于世界、历史、科学、文化及其他通用主题的事实性问题。
多智能体系统将复杂任务拆解为多个专业子任务。
在这种架构下,每个智能体专注于特定领域。这种专业化使整个系统更加高效。
导航智能体专注于定位和路线规划;媒体搜索智能体精通音乐和播客资源查找;汽车手册智能体擅长解决车辆相关问题。
系统会根据任务难度分配资源,简单任务用低配置资源,复杂任务再调用高性能资源。
关键功能(如调节温度、开窗等)由设备端智能体快速响应,而像餐厅推荐这类非紧急任务则交给云端智能体。
这种设计还具备天然的容错能力。网络连接中断时,设备端智能体仍能保证基本功能正常运行,比如温度控制和基本媒体播放不受影响,只是暂时无法获取餐厅推荐。
(文:新智元)