


随着人工智能技术的飞速发展,自然人机交互的需求日益增长。语音作为人类日常交流中最自然、最便捷的方式之一,成为人机交互的重要研究方向。然而,现有的语音模型在流式处理中生成首个音频标记时仍面临高延迟问题,这成为部署过程中的一个重大瓶颈。为了解决这一问题,VITA-Audio应运而生。它是一种能够快速生成音频–文本标记的端到端大型语音模型,通过创新的技术架构和训练策略,显著降低了延迟,为实时语音交互提供了新的解决方案。

一、项目概述
VITA-Audio是一个面向高效大规模语音语言模型的端到端大语言模型,能够快速生成音频–文本标记。它通过引入轻量级的多模态交叉标记预测(MCTP)模块,在单次模型前向传播中高效生成多个音频标记,不仅加速了推理过程,还显著降低了流式场景下生成首个音频的延迟。VITA-Audio完全可复现,仅使用开源数据进行训练,并在自动语音识别(ASR)、文本转语音(TTS)及口语问答(SQA)任务的多项基准测试中,显著优于相似模型规模的开源模型。
二、技术原理
(一)架构设计
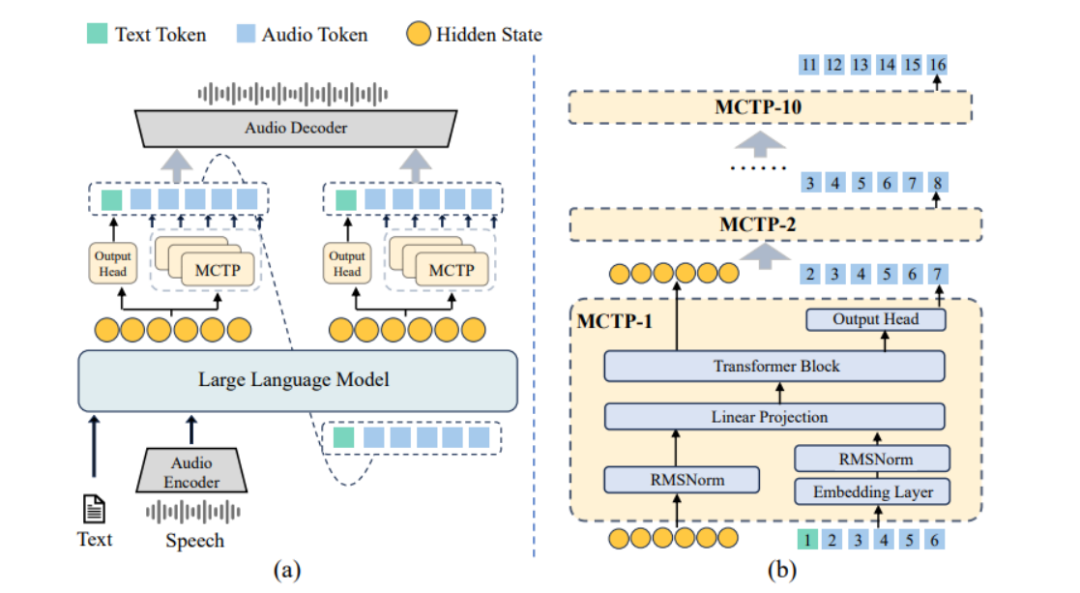
VITA-Audio由四个主要组件构成:音频编码器、音频解码器、大型语言模型主干,以及一组跨模态标记预测(MCTP)模块。音频编码器和解码器负责处理音频输入和输出,大型语言模型主干则用于处理文本和语音的语义信息。MCTP模块是VITA-Audio的核心创新点,它能够从LLM隐藏状态和文本嵌入中生成音频标记,从而实现极低延迟的语音生成。
(二)MCTP模块
MCTP模块具有轻量级架构,能够在0.0024秒内完成一次前向传递。它能够从LLM隐藏状态和文本嵌入生成多个音频标记,并且生成的音频标记可以直接由音频解码器解码。这种设计使得VITA-Audio能够在一次LLM前向传递中生成音频响应,从而实现极快的生成速度。
(三)训练策略
VITA-Audio采用了四阶段渐进式训练策略:
1. 音频–文本对齐:通过大规模语音预训练扩展LLM的音频建模能力。
2. 单MCTP模块训练:将一个MCTP模块与LLM连接,根据输入标记和LLM的隐藏状态预测后续标记。
3. 多MCTP模块训练:增加MCTP模块数量,以便在每次模型前向运算中预测更多标记。
4. 监督微调:使用语音问答数据集进行微调,优化模型的语音到语音对话能力。
三、主要功能
(一)低延迟音频生成
VITA-Audio能够在首次前向传播中生成多个音频标记,显著减少了生成首个音频标记的延迟。实验结果表明,VITA-Audio在70亿参数规模下实现了3至5倍的推理加速。
(二)多模态交互
VITA-Audio支持文本到语音(TTS)、自动语音识别(ASR)和口语问答(SQA)等多种任务。它能够处理混合的语音–文本序列,实现自然流畅的人机对话。
(三)高效推理
VITA-Audio提供了多种推理范式,以适应不同的应用场景。例如,VITA-Audio-Turbo在每次前向传递中生成多个音频标记,适用于需要高效推理的场景;而VITA-Audio-Balance则在保持语音质量的同时,实现较高的推理效率。
四、应用场景
(一)智能语音助手
VITA-Audio的低延迟特性使其非常适合用于智能语音助手,能够快速响应用户的语音指令,生成自然流畅的语音回答。无论是查询信息、设置提醒,还是进行日常对话,VITA-Audio都能提供即时的反馈,提升用户体验。
(二)语音客服
在语音客服领域,VITA-Audio能够快速理解用户的问题,并生成准确、自然的语音回答。其高效的推理速度可以显著缩短客户等待时间,提高客服效率。
(三)语音教育
VITA-Audio可以用于语言学习软件,帮助用户学习和练习发音。通过生成标准的语音发音和实时反馈用户的发音错误,VITA-Audio能够有效提升用户的语言能力。
(四)智能车载系统
在智能车载系统中,VITA-Audio可以作为语音交互的核心模块,支持语音导航、车辆控制等功能。用户可以通过语音指令查询路线、调整车内设备设置,而VITA-Audio能够快速响应并执行相应的操作。
五、快速使用
(一)环境准备
1. 硬件要求
推荐使用具有高性能GPU的计算设备,例如NVIDIA RTX 30系列或更高。如果使用CPU,推理速度可能会较慢。
2. 软件依赖
安装以下软件环境:
docker pull shenyunhang/pytorch:24.11-py3_2024-1224或者直接在本地环境中安装Python 3.8及以上版本,并安装必要的依赖:
pip install -r requirements_ds_gpu.txt(二)代码获取
1. 克隆代码仓库
从GitHub克隆VITA-Audio的代码仓库:
git clone https://github.com/VITA-MLLM/VITA-Audio.gitcd VITA-Audio
2. 安装依赖
安装项目所需的Python依赖:
pip install -r requirements_ds_gpu.txtpip install -e .
(三)预训练权重准备
1. 下载LLM权重
从Hugging Face下载LLM权重:
wget https://huggingface.co/Qwen/Qwen2.5-7B-Instruct/resolve/main/pytorch_model.binmkdir -p ../models/Qwen/Qwen2.5-7B-Instruct/mv pytorch_model.bin ../models/Qwen/Qwen2.5-7B-Instruct/
2. 下载音频编码器和解码器权重
下载音频编码器:
wget https://huggingface.co/THUDM/glm-4-voice-tokenizer/resolve/main/pytorch_model.binmkdir -p ../models/THUDM/glm-4-voice-tokenizermv pytorch_model.bin ../models/THUDM/glm-4-voice-tokenizer
下载音频解码器:
wget https://huggingface.co/THUDM/glm-4-voice-decoder/resolve/main/pytorch_model.binmkdir -p ../models/THUDM/glm-4-voice-decodermv pytorch_model.bin ../models/THUDM/glm-4-voice-decoder
(四)推理示例
1. 运行推理脚本
使用以下命令运行推理脚本:
python tools/inference_sts.py在运行脚本之前,请确保设置以下参数:
– `model_name_or_path`:指向VITA-Audio模型权重的路径。
– `audio_tokenizer_path`:指向音频编码器权重的路径。
– `flow_path`:指向音频解码器权重的路径。
2. 示例输入与输出
推理脚本支持多种任务,例如语音到语音(Speech-to-Speech)、自动语音识别(ASR)和文本到语音(TTS)。以下是一个简单的TTS示例:
# 设置输入文本input_text = "Hello, how are you?"# 运行推理output_audio = model.generate(input_text)# 保存生成的音频output_audio.save("output_audio.wav")
运行后,您将在当前目录下找到生成的音频文件`output_audio.wav`。
(五)微调实践
1. 准备微调数据
准备用于微调的数据集,数据集应包含文本和对应的音频文件。数据格式需符合项目要求。
2. 运行微调脚本
以`VITA-Audio-Boost`为例,运行以下微调脚本:
bash scripts/deepspeed/sts_qwen25/finetune_glm4voice_stage1.sh 8192 `date +'%Y%m%d_%H%M%S'`根据需要调整脚本中的参数,例如`ROOT_PATH`和`LOCAL_ROOT_PATH`。
3. 多阶段微调
VITA-Audio的微调分为多个阶段,包括音频–文本对齐、单MCTP模块训练、多MCTP模块训练和监督微调。每个阶段的脚本和参数配置请参考GitHub仓库中的说明。
六、结语
VITA-Audio作为一种高效、低延迟的开源多模态大语言模型,在语音交互领域展现了巨大的潜力。它通过创新的MCTP模块和渐进式训练策略,显著提升了语音生成的速度和质量,同时支持多种模态的交互任务。无论是智能语音助手、语音客服还是语音教育,VITA-Audio都能提供强大的技术支持。希望本文的介绍能够帮助您更好地了解和使用VITA-Audio,推动语音交互技术的发展。
项目地址:https://github.com/VITA-MLLM/VITA-Audio
论文链接:https://arxiv.org/pdf/2505.03739
(文:小兵的AI视界)