


近日,阿里巴巴的研究人员在 Hugging Face 上发布了一种名为“ZeroSearch”的新技术,可以大大降低训练 AI 系统进行信息搜索的成本和复杂度,完全消除对昂贵商业搜索引擎 API 的需求。
研究人员表示,“强化学习(RL)训练需要频繁进行部署,可能会涉及到数十万次搜索请求,这会产生巨额的 API 费用,严重限制了可扩展性。”
据介绍,这项新技术是一种强化学习框架,允许大语言模型 (LLM) 通过模拟的方式开发高级搜索功能,而无需在训练过程中与真实的搜索引擎进行交互。并且,其表现优于基于真实搜索引擎的模型,同时产生的 API 成本为零。既能让企业更好地控制 AI 系统学习检索信息的方式,又可以为其节省大量的 API 费用。
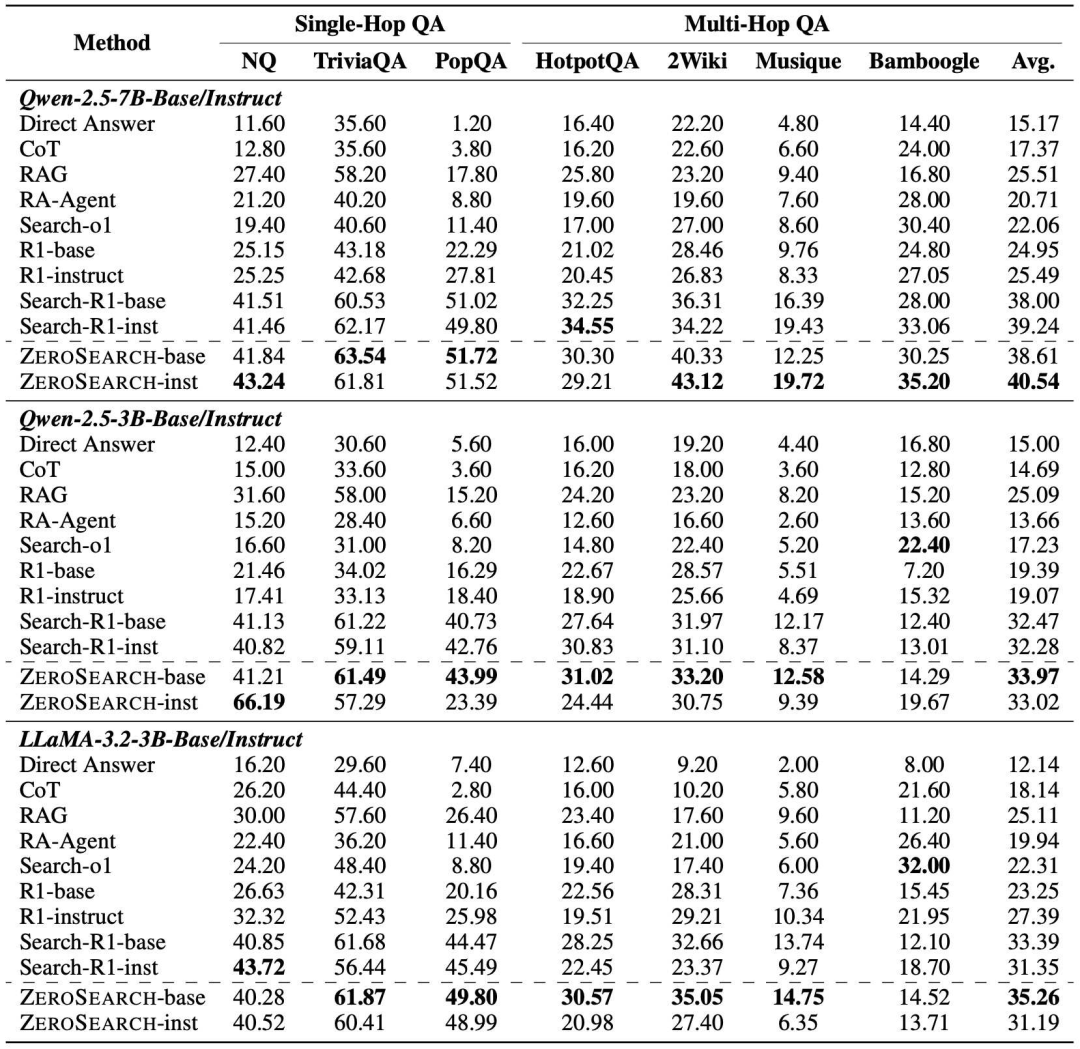
该技术适用于多个模型系列,包括 Qwen-2.5 和 LLaMA-3.2,且无论是基础模型还是经过指令调整的模型都能应用,无需单独的监督预热阶段,并与近端策略优化 (PPO)、组相对策略优化 (GRPO)等各种 RL 算法兼容。目前,研究人员已在 GitHub 和 Hugging Face 上提供了他们的代码、数据集和预训练模型,允许其他研究人员和公司能够应用这一方法。
项目链接:https://huggingface.co/collections/sunhaonlp/zerosearch-681b4ce012b9b6899832f4d0
有网友评价,“ZeroSearch 是 LLM 的游戏规则改变者。”还有人说,“这似乎是 RAG 应该发展的方向。”
要开发能够自主搜索信息的 AI 助手会面临两大挑战:一是在训练过程中,搜索引擎返回的文档质量不可预测;二是训练高级 AI 系统通常需要对大型科技公司控制的服务进行昂贵的 API 调用,尤其是向谷歌这样的商业搜索引擎进行数十万次 API 调用,成本高得令人望而却步。
在针对七个问答数据集所进行的全面实验中,ZeroSearch 的性能表现不仅与使用真实搜索引擎训练的模型相当,而且在很多情况下还超越了它们。结果表明,ZeroSearch 使用 3B LLM 作为模拟搜索引擎,就可以有效地提升策略模型的搜索能力;一个拥有 70 亿参数的检索模块能达到可与谷歌搜索相媲美的性能,而一个拥有 140 亿参数的模块甚至超过了谷歌搜索的表现。
更重要的是,ZeroSearch 表现出强大的可扩展性:增加 GPU 的数量可以显著加快模拟 LLM 的生成吞吐量,从而实现高效的大规模部署。
并且,ZeroSearch 在基础模型和指令优化模型中都能很好地泛化。在这两种模型类型下,ZeroSearch 都能稳步提高奖励性能,这突出了它的通用性。
“这证明了在强化学习的架构中,使用一个经过良好训练的 LLM 来替代真实搜索引擎是可行的。” 研究人员指出。
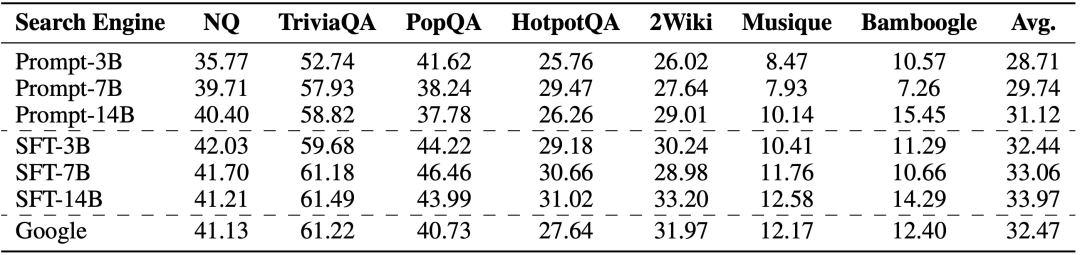
值得注意的是,ZeroSearch 在成本方面的节省也相当可观。根据研究人员的分析,通过 SerpAPI 使用 Google 搜索引擎对大约 64000 个搜索查询进行训练,成本约为 586.70 美元;而在四个 A100 GPU 上使用一个拥有 140 亿参数的模拟大型语言模型进行训练,成本仅为 70.80 美元,降低了 88%。
由此来看,ZeroSearch 所能解决的问题意义重大。不过,研究人员也指出,ZeroSearch 也有一定的局限性。部署模拟搜索 LLM 需要访问 GPU 服务器,虽然比商业 API 使用更具成本效益,但这会带来额外的基础设施成本。
据介绍,ZeroSearch 的方法始于一个轻量级的监督微调过程,将 LLM 转化为一个能够生成相关和不相关文档以响应查询的检索模块,可以作为模拟搜索引擎,生成相关和嘈杂的文档以响应查询。
研究人员解释道:“我们的关键认知是,LLM 在大规模预训练期间已经获得了广泛的世界知识,并且能够在给定搜索查询的情况下生成相关文档,真实搜索引擎和模拟 LLM 之间的主要区别在于返回内容的文本样式。但是,通过轻量级监督微调,即使是相对较小的 LLM 也可以有效地模拟真实搜索引擎的行为。”
除了消除 API 成本之外,使用 LLM 生成文档的一个重要优势是能够控制文档质量。具体来说,在监督微调过程中,通过提示设计区分导致正确或错误答案的文档,使模拟 LLM 只需调整提示中的几个单词即可学习生成相关或嘈杂的文档。
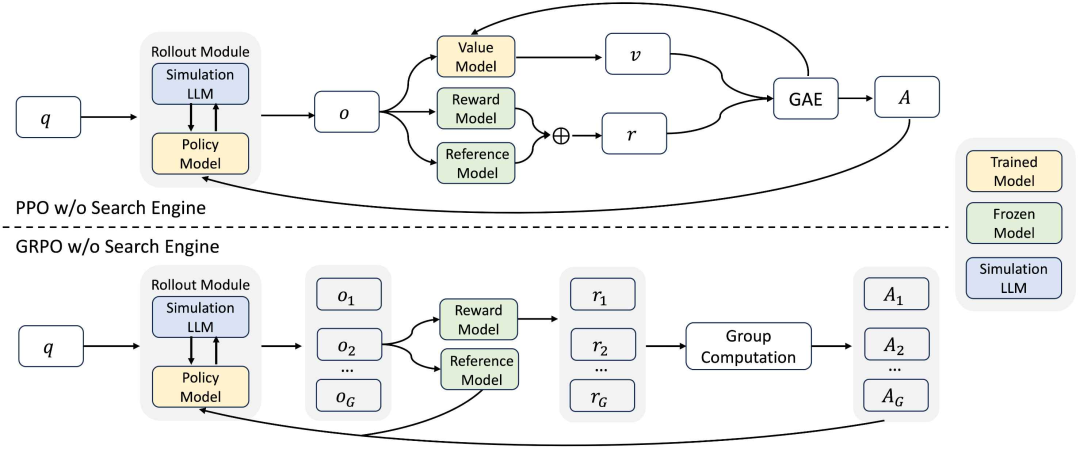
在强化学习训练期间,该系统采用了研究人员所说的“基于课程搜索模拟的推出策略”。在推出过程中,策略模型会执行交互式推理并生成搜索查询,然后将查询输入模拟 LLM 以生成相应的文档。为了逐步增加训练的难度,该系统在强化学习训练期间引入了一种基于课程学习的部署机制,这种机制下生成文档的质量会随着时间的推移而逐渐降低,以模拟越来越具有挑战性的检索场景。这允许策略模型首先学习基本的输出格式和任务要求,然后再逐步适应更具挑战性和嘈杂的检索场景。
奖励信号是强化学习过程中的主要监督。在这项工作中,ZeroSearch 采用了基于 F1 分数的奖励,该奖励只关注答案的准确性。
ZeroSearch 的这一突破标志着 AI 系统的训练方式发生了重大转变。其表明,AI 在不依赖搜索引擎等外部工具的情况下也能实现提升。
对于预算有限的小型 AI 公司和初创企业来说,这种方法可以创造公平的竞争环境。API 调用的高昂成本一直是开发复杂 AI 助手的一大进入壁垒,ZeroSearch 将这些成本降低了近 90%,使高级 AI 训练变得更加触手可及。除了节省成本之外,这项技术还让开发者能够更好地控制训练过程。在使用真正的搜索引擎时,返回文档的质量是不可预测的。而借助模拟搜索,开发者能够精确控制 AI 在训练过程中所接触到的信息。
随着大语言模型的不断发展,像 ZeroSearch 这样的技术意味着,未来 AI 系统可以通过自我模拟而不是依赖外部服务来发展日益复杂的能力,这有可能会改变 AI 开发的经济模式,并减少对大型技术平台的依赖。此外,传统搜索引擎对 AI 开发的必要性似乎在降低。
随着 AI 系统变得更加自给自足,未来几年的技术格局可能会大不相同。
(文:AI前线)