


新智元报道
新智元报道
【新智元导读】NYU机器学习教授痛心表示,如今很多大学的ML课程,已经抛弃了基础概念和经典。他晒出的课程大纲,引起了哈佛CS教授的赞同:很高兴我们并不孤单,想在大纲中保留基础概念可太难了。甚至,印度和美国的大学生都在抱怨,学校的机器学习课太垃圾了,全靠自己自学!
就在刚刚,NYU教授Kyunghyun Cho呼吁:如今大学的机器学习课程,已经抛弃了经典!
在他看来,很多课程都抛弃了关于ML和深度学习的基础概念,这很危险。

他提出了一个深刻的议题:在LLM和大规模计算力普及的今天,机器学习一年级研究生课程该教些什么呢?
对此,教授给出了一种独辟蹊径的方式——
教授所有能用随机梯度下降(SGD)解决,但又不是LLM的内容,并且让学生去阅读一些早期的经典论文。

上下滑动查看
在看完他晒出的讲座笔记和教学大纲后,不少网友表示赞叹。
有人评论说:2025年的机器学习课程里竟然还教RBM(受限玻尔兹曼机)?这绝对是独一无二的课程,太特别了。
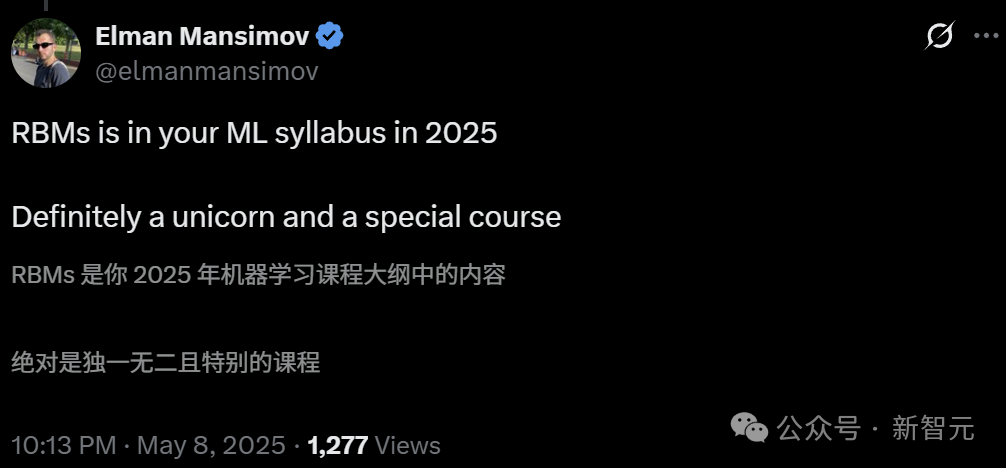
一位哈佛的助理教授说,自己非常喜欢这个教学大纲,和哈佛的CS1810课程大纲基本类似,只是少了一些进阶主题和生成模型的类型。
要知道,想把深度学习前期的基础概念保留在课程大纲中,时常会受到阻力,他表示,很高兴看到自己并不孤单。

NYU教授晒出的讲座笔记如下。
可以看到,在这门课程中他首先引入了机器学习的基本概念,比如感知机与间隔损失函数、Softmax与交叉熵损失函数,反向传播,随机梯度下降(SGD),泛化与模型选择,超参数调优与模型选择等。
随后,课程的第3章开始教授神经网络的基本构建模块,如归一化、卷积模块、循环模块、注意力机制等。
第4章教授的是概率机器学习与无监督学习,包括能量函数的概率解释,变分推断与高斯混合模型,连续潜变量模型,VAE等。
在第5章,学生们会学到受限玻尔兹曼机(RBM)、基于能量的生成对抗网络(EB-GAN)、自回归模型等无向生成模型。
在打好这些基础后,学生们才会学习强化学习、元学习、因果推断这些内容。



左右滑动查看
在这门机器学习课程的教学大纲中,教授也强调——
如今,机器学习系统已经在飞速发展。我们经常使用随机梯度下降(或其变体),在包含数百万乃至数十亿训练样本的大型数据集上,训练拥有数百万乃至数十亿参数的大规模模型。
这些令人惊叹的成果,都离不开数学、概率、统计和计算机科学中那些简单而基础的理念。
而这门课,强调的就是这些基础概念,从而让学生们能更系统、更严谨地理解现代的大规模机器学习算法。

教学大纲中推荐的论文,也并不是近几年的爆款时兴论文,反而是从上世纪90年年代至2022年的一些经典论文。
比如神经网络先驱之一的Ronald Williams,靠一篇关于反向传播算法的论文,引发了神经网络研究的热潮。
教授推荐列表的第一篇文章,就是他发表于1992年的「Simple Statistical Gradient-following Algorithms for Connectionist Reinforcement Learning」。
第二篇年代久远的论文,就是现任微软人工智能研究院主任、英国计算机科学家Christopher Bishop的发表于1994年的「Mixture density networks」。
图灵三巨头的不少经典论文也入选了,比如LeCun的「Efficient BackProp」,Hinton的「Training Products of Experts by Minimizing Contrastive Divergence」等。
总之,不追逐潮流,只读经典。

上下滑动查看

哈佛的CS 1810课程,此前在网上就曾引起热议。

教材:https://github.com/harvard-ml-courses/cs181-textbook/blob/master/Textbook.pdf
从课程大纲中可以看出,这门课非常全面严谨地介绍了机器学习、概率推理等基础知识。
内容涵盖了监督学习、集成方法与提升方法、神经网络、支持向量机、核方法、聚类与无监督学习、最大似然估计、图模型、隐马尔可夫模型、推断方法、强化学习等。
而且这门课因为是面向高年级本科生,所以需要学生能用Python写比较复杂的程序,还需要具备概率论、微积分、线代的基础知识。
正如此前提到的助理教授所说,这份课程大纲中保留了很多深度学习前期的基础概念,这在当今竟然已经不多见了。







左右滑动查看
另一传统牛校MIT 2024年的机器学习讲义,是下面这样的。

教材:https://introml.mit.edu/_static/spring24/LectureNotes/6_390_lecture_notes_spring24.pdf
这门机器学习的入门课,是为本科生和研究生设计。
内容包括监督学习(如线性回归、逻辑回归、神经网络)、无监督学习(如聚类、主成分分析)、概率模型以及强化学习的基础。
跟哈佛的CS 1810相同,这门课除了理论,也非常强调实践。
学生需要完成多项编程项目,使用Python和相关库(如NumPy、PyTorch)实现模型,并通过考试和项目展示对理论的理解,因此必须具备基础数学和编程背景。





左右滑动查看
除了AI领域之外,有些学科本身就倾向于学习经典内容,比如数学。
有网友表示,在许多本科和研究生的数学课程中,5、60年代的教学大纲仍然被认为是黄金标准。

对此,reddit上的网友Cheezees表示赞同,他说他的父亲——一名兼职教授,就认为《Elementary Analysis》是最好的数学教科书。这本书首版于1980年,但至今仍在使用。
还有像是《Principles of Mathematical Analysis》(数学分析原理)这种出版于1953年的教材,现在仍在全美超过80%的荣誉本科分析课程中使用。
对于有些学科教材过时的问题,也不是没有解决的办法。
比如,这位网名Rain-Stop的生物材料教授称,虽然他喜欢的一本教材自从2013年就没有更新了,但是他使用过去3-4年内发表的期刊论文来涵盖领域内的进展。
经典教材配合上最新论文,这也不失为一个好办法。

接下来,我们看看国内高校AI专业的培养方案。
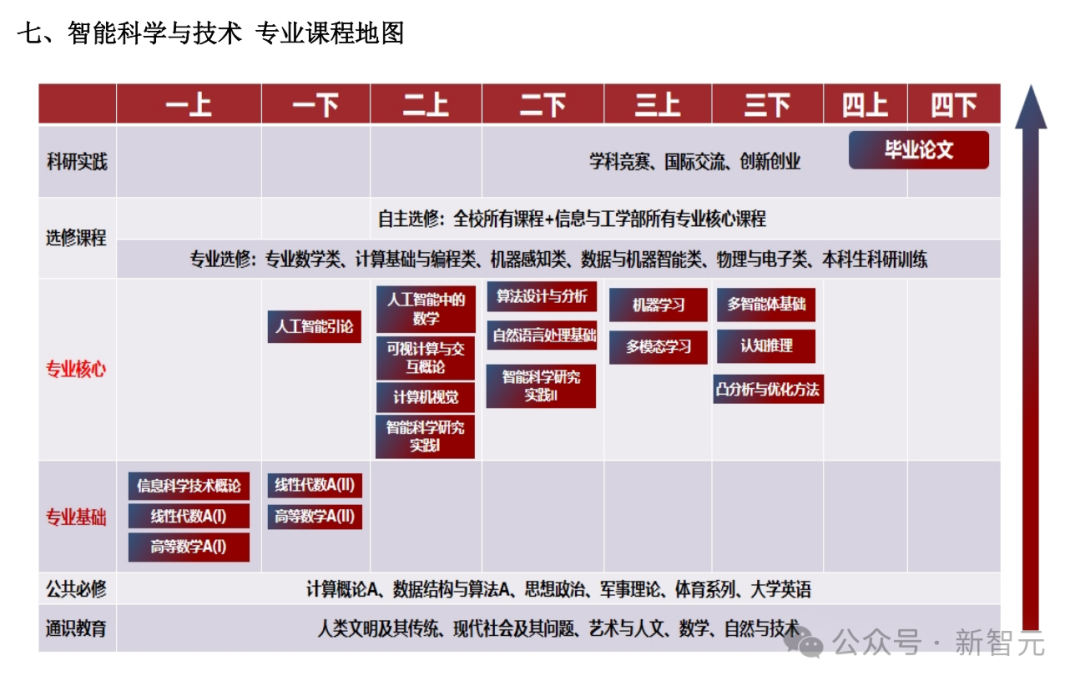
比如北大信科智能科学与技术专业(智班)的24年本科生培养方案,是这样的。
两门公共必修课,是计算概论和数据结构与算法。

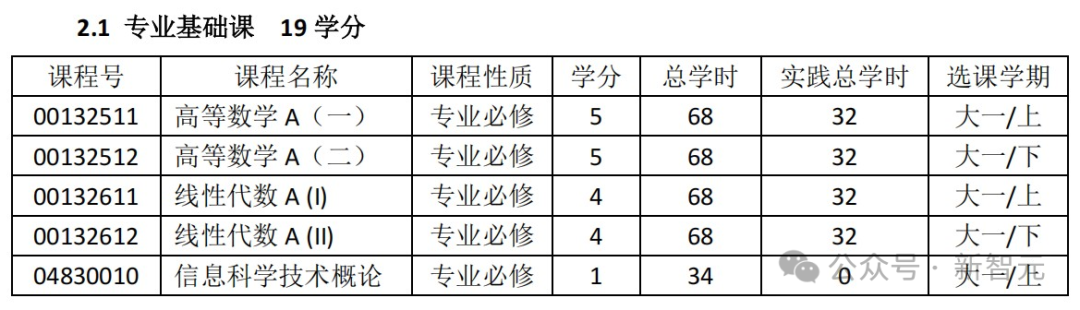
专业基础课,是高数、线代和信科技术概论。
专业核心课中,包括人工智能引论、算法设计与分析、机器学习、多模态学习等。
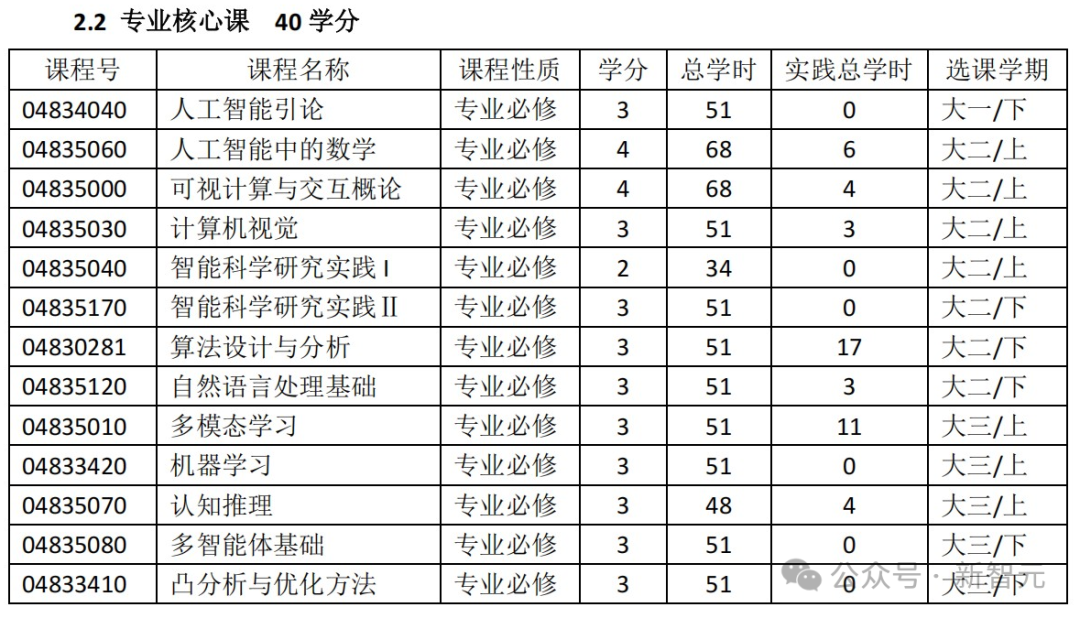
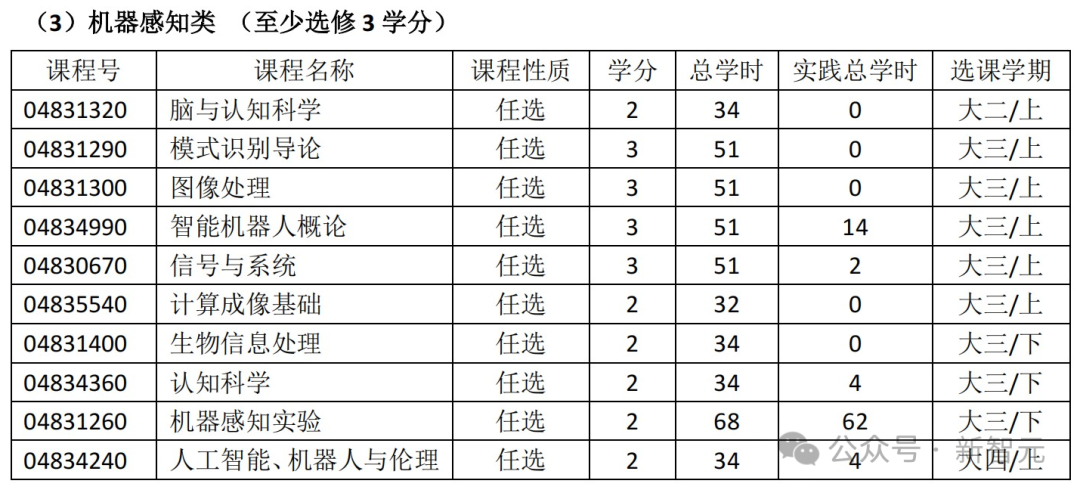
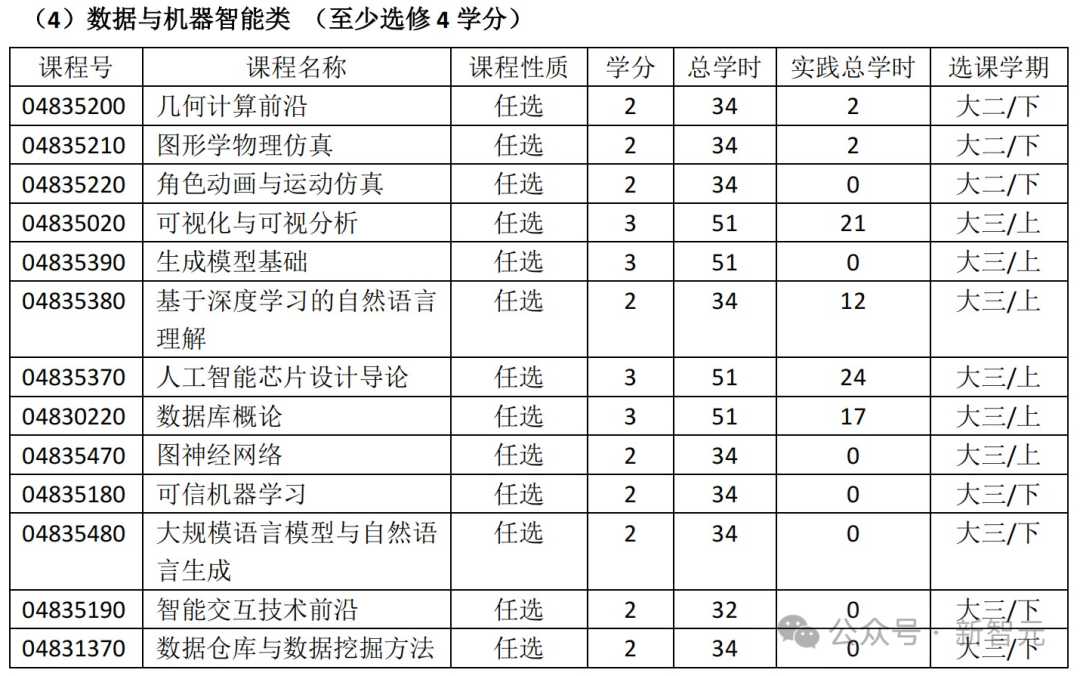
专业选修课中,还包括不少计算基础与编程类、机器感知类、数据与机器智能类的课程。


下面是一份专业课程地图全览。
再比如,23年清华叉院的计算机科学与技术(人工智能班)专业本科培养方案。

这个培养方案涵盖了数学、物理、计算机科学基础(如数据结构、算法设计)、人工智能(如机器学习、深度学习)以及工程实践。


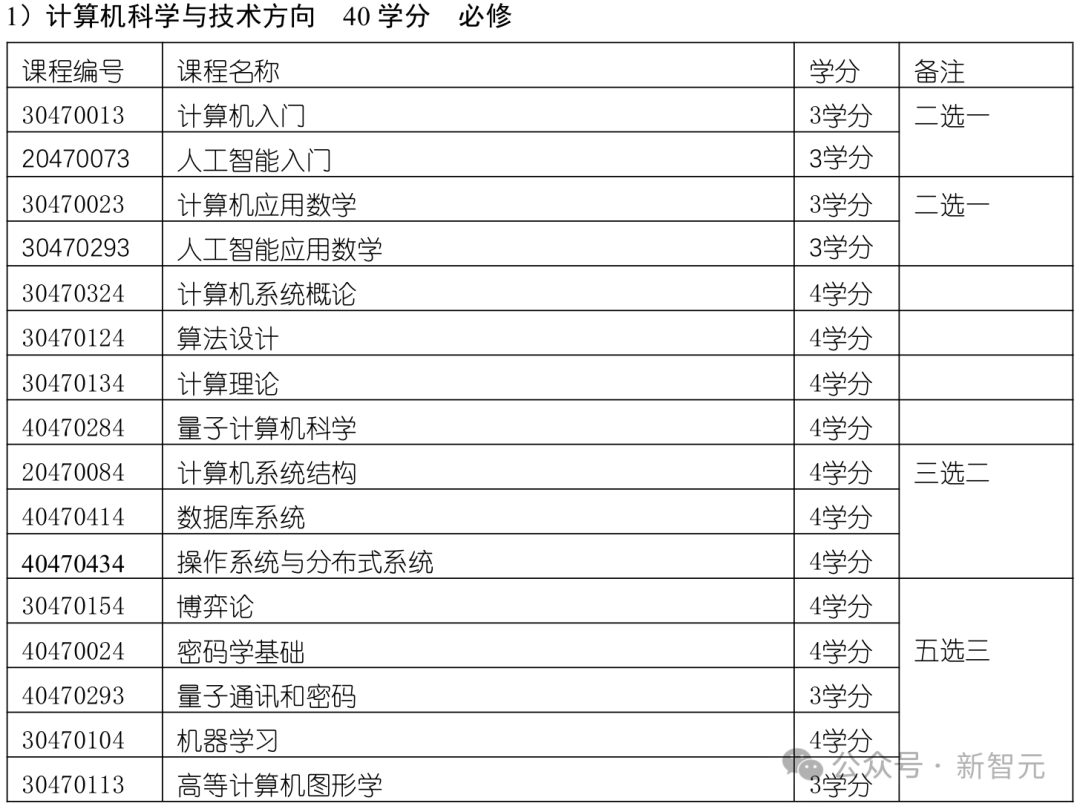
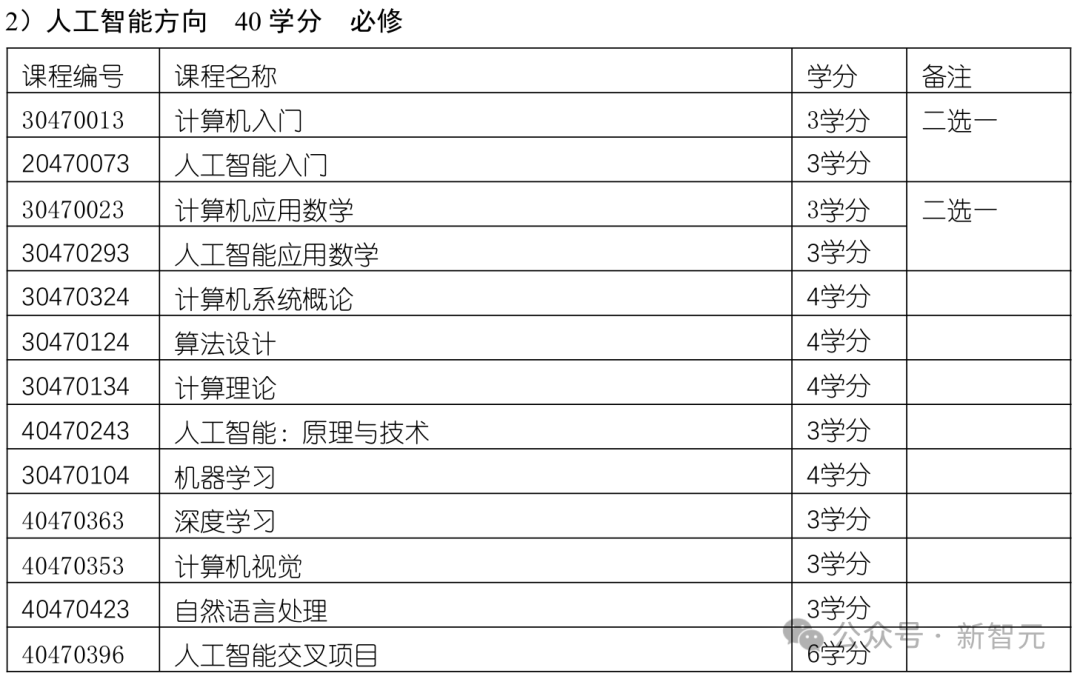
对数学和基础理论课程的重视,为学生深入理解算法和系统设计奠定了坚实基础。
另外,方案中还安排了丰富的实践环节,体现了清华对培养学生动手能力和创新能力的重视。例如,学生需完成多个编程项目和跨学科综合设计,将理论应用于实际场景。
课程中还有如量子计算和人工智能交叉项目(AI+X)这些前沿领域。


有趣的是,就在去年,一位印度学生曾在reddit上发帖,抱怨学校的机器学习课程太垃圾。
他来自印度一所四级地方学院,觉得学校的机器学习课程问题很大。
具体来说就是,课程使用了太多技术术语,却没有真正解释深入的工作原理。
比如他们的其中一部分教学大纲是这样的。
1. 人工智能/机器学习简介,线性回归,逻辑回归,贝叶斯分类,决策树
2. 正则化,支持向量机
3. 集成学习,自助聚集(bagging),提升法(boosting)
4. 神经网络,卷积神经网络
5. Seq2Seq模型,注意力机制,Transformer
这位学生表示,课程大纲只有第一章和神经网络导论涉及数学,其余部分都是一堆废话。
他认为,这门课作为一门工程课程,实在太抽象了:使用了一些华丽的术语,却并未深入解释任何内容。
虽然只要记住这些花哨的单词就能通过考试,但一遇到项目,他就傻眼了。这些项目至少需要博士学位才能理解,需要采用GAN、可解释AI、神经架构搜索、视觉Transformer、优化等技术。
所以,绝大多数学生都只能在GitHub上找到一些现成的项目,复制粘贴论文,然后用Humanize AI降低查重率。
然而发帖人表示,自己并不喜欢抄袭别人的作品,但「AI正被强塞进自己的喉咙」。本来如果按照自己的节奏慢慢学习,应该会喜欢ML/AI的。
但是现在,自己可能要花好几年才能理解这些论文,更不用说想到一个新的项目点子了。
有人指出,这个现象反映出印度教育体系的一个典型问题:把流行术语和技术灌给学生,概念却极其空洞,如果缺乏必要的数学和统计学背景,就不会理解这些算法的「why」和「how」。

只有对线代、概率论、微积分有扎实理解,才能理解向量机或神经网络等算法的内部原理。如果没打好基础就跳到Transformer和GAN等高级概念,就像造摩天大楼却不打地基一样。
因此,他建议这位迷茫的学生回去学好基础数学,比如Marc Peter Deisenroth 的 《机器学习的数学》,然后在Coursera和edX平台学好AI课程。其中吴恩达在Coursera上的机器学习和深度学习课就堪称典范。
甚至在这个帖子下,有个来自美国的学生抱怨说,美国大学也同样存在这个问题。
他来自自己所在州最好的大学,正在读七年级。系里会在五年级教学生网络技术,六年级教人工智能,七年级教机器学习。
但课程结构非常混乱,甚至教授们根本不讲算法原理,只会读PPT,甚至懒得教数学。
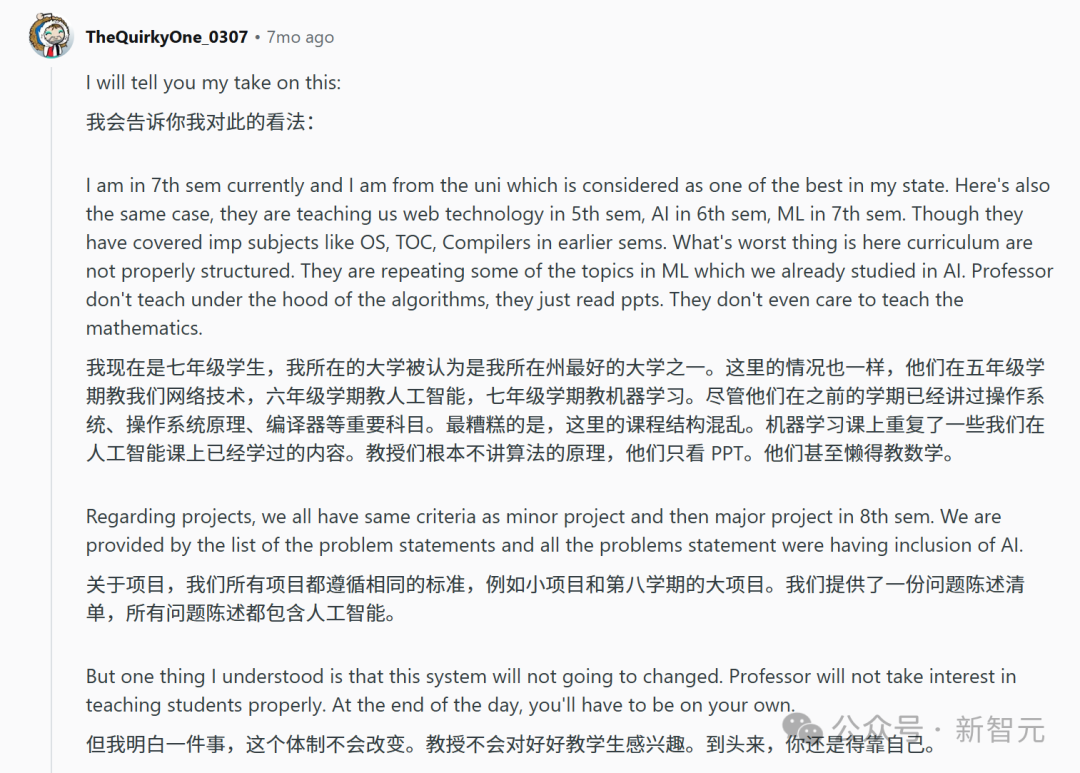
这位学生意识到:如果想学好机器学习,只能靠自己,去找网课和教材自学。
比如他推荐了一本不错的教材「Hands on Machine Learning with Scikitlearn, Keras and Tensorflow」,还订阅了一些不错的YouTube频道。
其实无论是在印度还是美国大学中,问题的核心就在于,如今AI/ML的发展速度实在太快了,任何大学都无法跟上,甚至一些机构也举步维艰。
所以,如果真的只靠学校课程,学生是不太可能学好AI/ML的,只能选择靠自己。
大学的教材和课程可能会过时,但不会阻碍一个人的学习。
今年早些时候,剑桥大学的学生们向诺贝尔奖得主、Google DeepMind首席执行官Demis Hassabis提交了问题,他们中的许多人想知道在AI时代应该如何安排他们的时间。
Hassabis的建议是——把时间花在「学习如何学习」上。

「我认为最重要的是真正理解自己——利用本科阶段的时间更好地了解自己,以及自己最有效的学习方式。」
在这之中,适应能力至关重要,也就是「如何快速掌握新知识并运用自如」。
由于技术不断发展,如今的大学生们将进入一个充满「颠覆和变革」的世界,而这是唯一可以预见的。
在他看来「AI,以及VR、AR和量子计算等领域,在未来五到十年内都极具潜力」,每一次变革都蕴藏着巨大的机遇。
Hassabis建议学生们专注于基础知识。虽然新潮流层出不穷,但最好避免被那些「今天风靡一时,明天就无人问津」的事物所干扰。
「我最喜欢的科目是计算理论和信息论,还有研究像图灵机这样的东西。这些知识贯穿了我的整个职业生涯。我喜欢数学的底层逻辑,以及许多传统的、基础性的研究」。他补充说,学生们也不应该忽略自己的兴趣。
Hassabis认为,毕业生们应该能够将对自身兴趣的深入理解与他们所掌握的核心技能「结合」起来。
Hassabis建议道:「在课余时间,你应该积极探索自己热爱的领域。对我来说,那就是AI。现在涌现出了大量的工具——其中许多都非常容易上手,而且是开源的——这样你才能在毕业时真正掌握最前沿的知识。」
Hassabis同时建议研究生们培养跨领域的专业知识。例如,如果他们学习的是AI,那么他们也应该了解如何将其应用到最佳的领域。
因为在未来十年左右,多学科研究将会成为主流。
在AI和STEM领域交叉的地方,可能会有很多「唾手可得的成果」,因此重要的是要对这两个领域都有足够的了解,才能明白什么是「正确的问题」——因为提出这些问题可能会带来突破性的进展。
Hassabis说:「选择问题就像拥有某种品味或嗅觉,或者说是一种直觉,知道『什么是正确的问题?』以及『现在是否是解决这个问题的最佳时机?』因为时机非常重要,你肯定不想超前时代50年。」
尽管Hassabis认为人们无法真正培养出那种第六感,但他建议大家保持开放的心态,随时准备抓住机遇。
「机遇可能来自任何地方,所以要成为一个多学科的人,让自己接触到各种各样的想法」。
(文:新智元)