

今天是2025年5月4日,星期日,北京,晴,假期已进入尾声。
我们今天来看看大模型部署的话题,之前也有介绍过,这次再温习一遍,讲的再细致些
计算LLM的显存需要考虑多个因素,了解核心组件(参数、优化器状态、梯度、激活值和开销)至关重要。根据任务(推理、全参数微调、PEFT)和操作设置(精度、批量大小、序列长度、多GPU配置),所需的显存差异很大。
如何进行估计其实是一个很有趣的问题,可以通过大致的计算公式计算出来,但是要记住,它们仅表示基本需求。实际显存消耗将受到框架内存管理、CUDA内核行为、内存碎片化以及未在主要公式中捕捉到的实现细节的影响。
因此,本文从原理进行介绍,参照https://apxml.com/posts/how-to-calculate-vram-requirements-for-an-llm,并且介绍一个大模型推理与微调计算器,可计算所需要的资源及预期速度。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、在线可用的大模型推理及微调资源计算器
最近发现一个大模型推理与微调计算器,可计算所需要的资源及预期速度。https://apxml.com/tools/vram-calculator,可以根据执行模型大小、模型上下文长度、batch_size长度,梯度累计等参数,来确定所需的推理、微调的显存要求。
例如,推理时的显存要求:
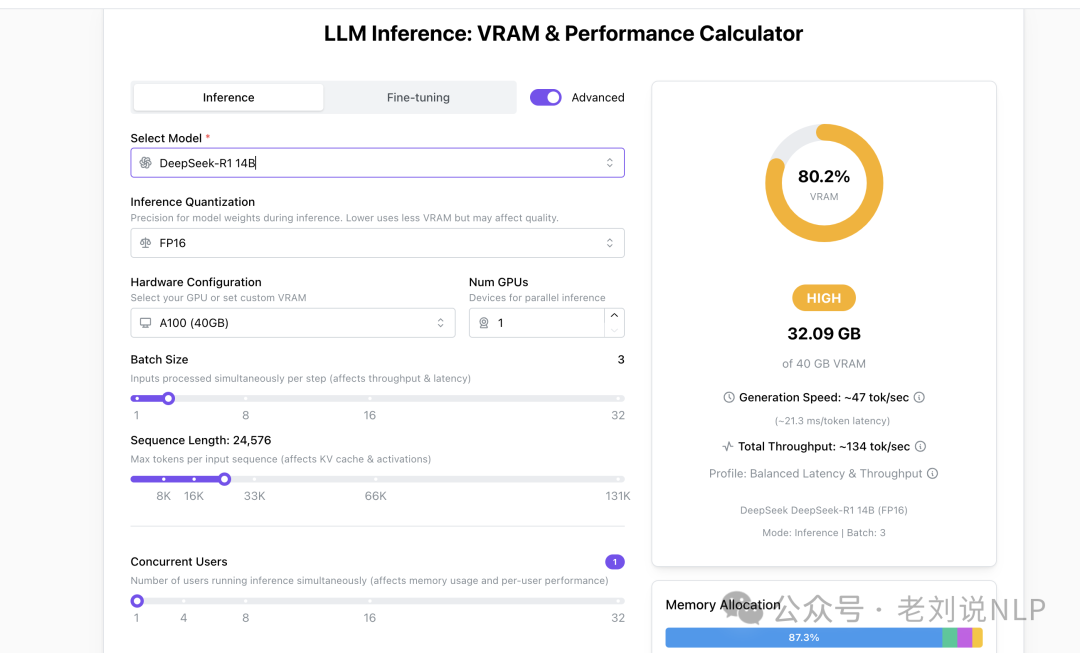
又如,微调的显存要求:
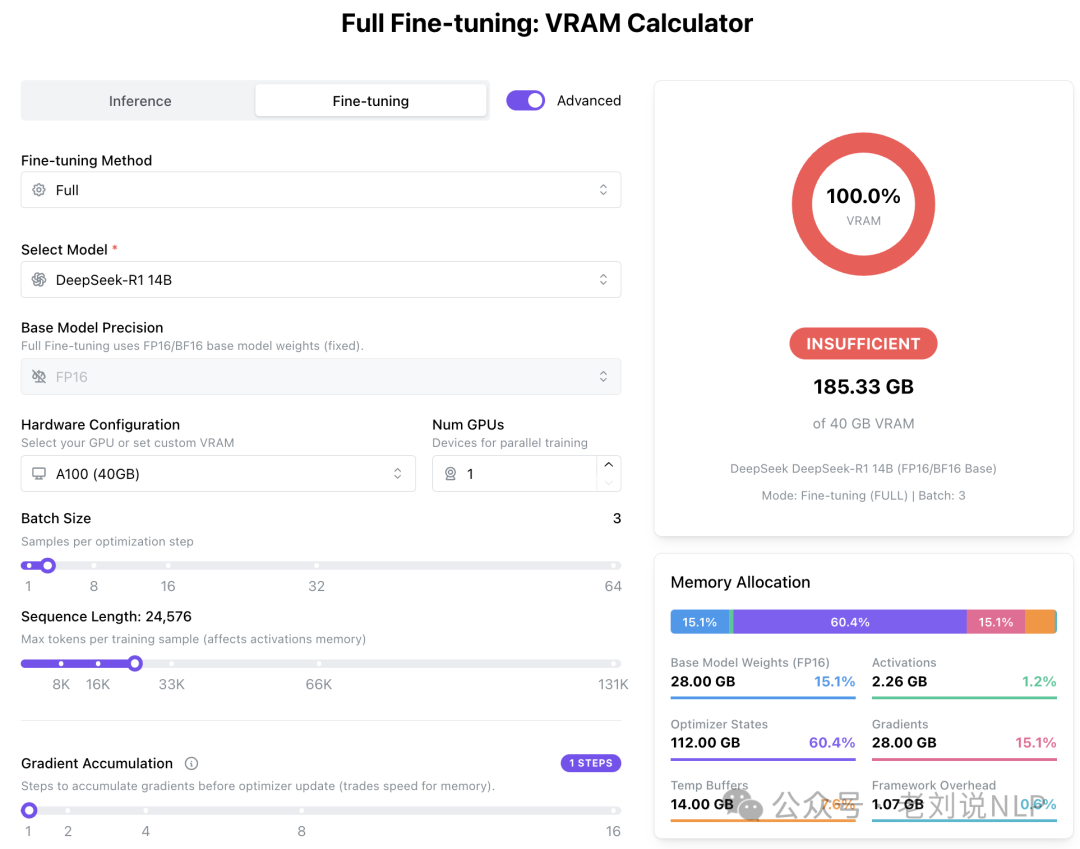
二、影响显存占用的几个因素
那么,具体是如何实现的?先看造成显存占用的组件,估算总显存需要将几个不同组件所占用的内存相加。每个组件的相关性取决于是进行推理还是训练/微调。
1、模型参数
模型参数通常是最大且最容易计算的组件。它取决于模型中的参数数量以及用于存储它们的数值精度。
参数数量:通常以十亿为单位表示(例如,7B、70B、180B)。这些信息通常可以在模型卡或存储库(如HuggingFaceHub)中找到。
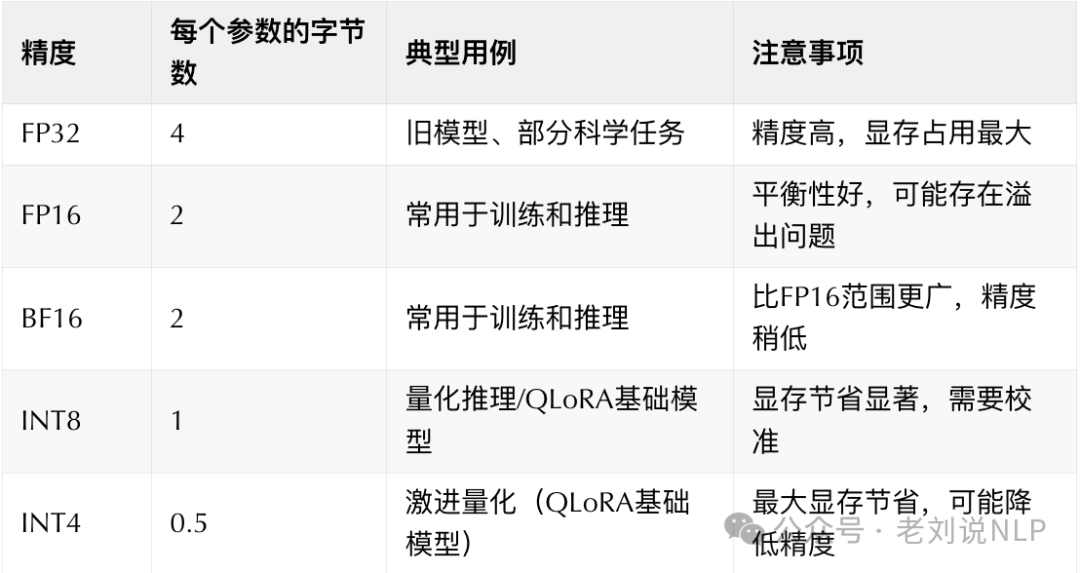
精度(数据类型):决定每个参数所需的字节数。FP32(单精度浮点)占据4字节;FP16(半精度浮点)占据2字节;BF16(Bfloat16浮点)占据2字节;INT8(8位整数)占据1字节;INT4(4位整数)占据0.5字节

2、优化器状态(仅限训练/微调)
在训练或微调期间,像Adam或AdamW这样的优化器会为每个正在训练的模型参数维护状态信息。Adam/AdamW通常为每个参数存储两个状态(动量和方差),通常无论模型的精度如何,都以FP32精度存储,尽管混合精度训练设置可能会改变这一点。
–Adam/AdamW:通常需要为每个参数存储2个值(动量、方差)。如果以FP32存储,这意味着每个参数需要8字节。这是一个常见的估计值。 –其他优化器:带有动量的SGD可能会为每个参数存储1个状态(如果以FP32存储,则为4字节/参数)。Adafactor使用的内存较少。

注意:DeepSpeed或bitsandbytes等库提供的8位优化器可以显著减少这一内存占用,从而改变每个参数所需的字节数。
3、梯度(仅限训练/微调)
反向传播会为每个可训练参数计算梯度。这些梯度通常在反向传播过程中与可训练参数具有相同的数值精度。

4、激活值(推理和训练)
激活值是模型层在前向传播过程中计算的中间输出。其大小的计算较为复杂,取决于:批量大小:同时处理的序列数量;序列长度:输入序列的长度;隐藏维度大小:内部向量表示的大小;层数:模型的深度。模型架构:具体细节,如注意力机制(尤其是在生成过程中的KV缓存)。
但是,由于不同层类型和可能的优化(如激活值检查点)的存在,精确计算激活值内存是具有挑战性的。实际使用情况高度依赖于特定框架的实现和模型细节。

其中K是一个与模型相关的常数(通常估计在10到30之间,用于考虑各种中间值,如注意力分数、层归一化输出等)。精确计算通常需要对模型进行详细分析或通过经验测量。
5、KV缓存(推理生成)
在自回归生成(推理中常见)过程中,模型会缓存来自注意力层的过去Key(K)和Value(V)状态,以加快后续标记的预测速度。这个缓存会随着生成序列长度的增加而增长,并且可能会占用大量的显存。

对于长序列或大批量,KV缓存很容易成为推理显存使用的主要因素。其大小估算也受到实现细节的影响。
6、临时缓冲区和工作区
深度学习框架(PyTorch、TensorFlow)和CUDA内核通常会为中间计算、融合操作或通信缓冲区(在多GPU设置中)分配临时内存。这部分很难精确预测,但通常占总显存的一小部分(例如,1-2GB,但可能会有所不同)。为这个不可预测的组件添加一个缓冲区是明智的。
7、输入数据
一批tokenizer的输入ID也会驻留在显存中,但其大小通常与参数、激活值或优化器状态相比可以忽略不计。
三、如何计算推理的显存?
对于推理,主要的贡献者是模型参数和激活值(包括KV缓存)。
总推理显存≈VRAM_params+VRAM_activations+VRAM_kv_cache+VRAM_overhead

注意:此总数是一个估算值。实际使用情况应在实际条件下进行监控。

以下是一种使用HuggingFacetransformers获取参数数量的方法:
fromtransformersimportAutoConfig,AutoModelForCausalLM
model_name="meta-llama/Meta-Llama-3-8B"
config=AutoConfig.from_pretrained(model_name)
#推荐:如果可用且准确,从配置中获取
num_params_config=getattr(config,"num_parameters",None)
#备选:加载模型并计数(需要CPU内存)
ifnum_params_configisNone:
print("配置中未找到参数数量,正在加载模型进行计数...")
#如果CPU内存有限,请考虑使用low_cpu_mem_usage=True加载
model=AutoModelForCausalLM.from_pretrained(model_name,low_cpu_mem_usage=True)
num_params=sum(p.numel()forpinmodel.parameters())
delmodel#释放内存
else:
num_params=num_params_config
bytes_per_param=2#对于FP16
vram_params_gb=(num_params*bytes_per_param)/(1024**3)
print(f"模型:{model_name}")
print(f"参数数量:{num_params/1e9:.1f}B")
print(f"估算参数显存(FP16):{vram_params_gb:.2f}GB")
四、如何计算微调所需显存?全参、PEFT?
微调所需的显存比推理多得多,因为它涉及存储梯度和优化器状态,以及参数和激活值。
总训练显存≈VRAM_params+VRAM_gradients+VRAM_optimizer+VRAM_activations+VRAM_overhead
1、全参数微调
在这里,所有模型参数都会更新。

注意:此计算突出了大型模型全参数微调的巨大内存需求,并且依赖于估算,尤其是对于激活值和开销。
这清楚地表明了为什么全参数微调大型模型需要多个高显存的GPU(如A100或H100)。
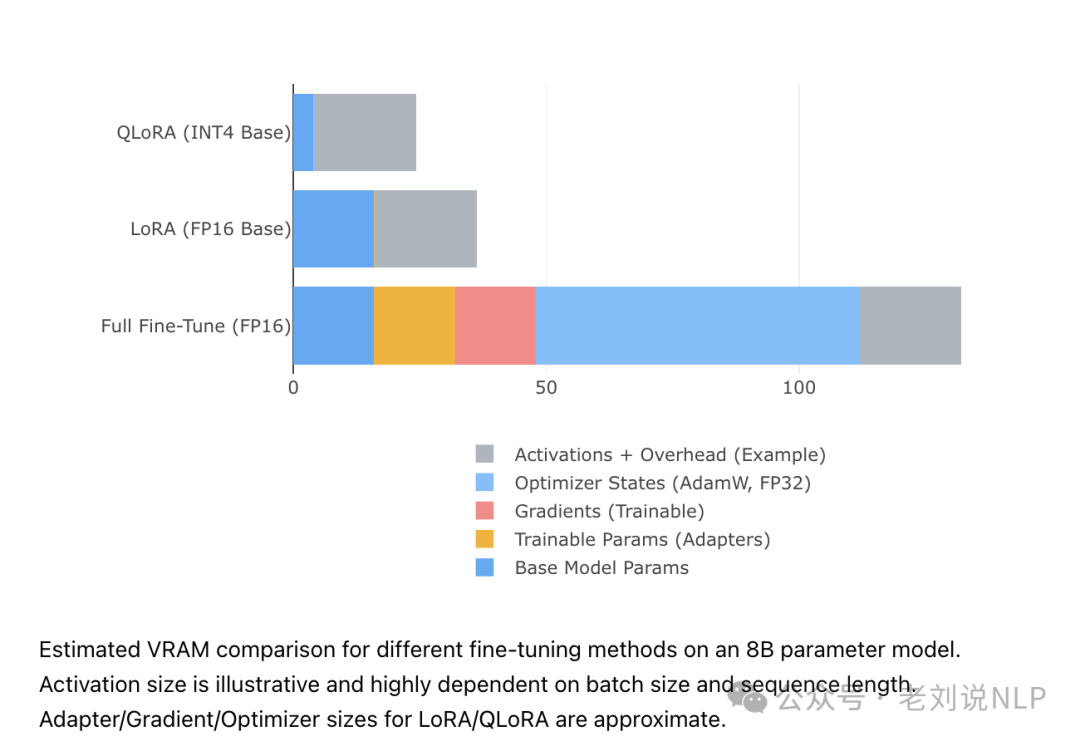
2、参数高效微调(PEFT)
像LoRA(低秩适配)这样的技术通过冻结基础模型参数并仅训练小型适配器层,显著减少了显存需求。
LoRA:只有LoRA适配器参数(通常是数百万,而不是数十亿)需要梯度和优化器状态。基础模型(冻结)只贡献其参数大小(通常以较低的精度加载,如FP16、BF16,甚至通过QLoRA使用INT8/INT4)。
QLoRA:通过以量化格式(例如,4位NF4)加载基础模型,同时以BF16训练LoRA适配器,进一步减少内存。

注意:再次强调,激活值和开销的数字是估算值。LoRA参数数量的估算也进行了简化。
这种巨大的减少使得在消费级或专业级GPU上进行微调成为可能。
#LoRA参数数量的粗略估算
defestimate_lora_params(model_config,rank=8,
target_modules=['q_proj','v_proj']):
hidden_size=getattr(model_config,'hidden_size',0)
num_layers=getattr(model_config,'num_hidden_layers',0)
intermediate_size=getattr(model_config,'intermediate_size',0)#如果目标是MLP层,则需要此值
#简化:假设每个目标模块在每一层中出现一次
#实际计算取决于目标层的维度(例如,注意力层与MLP层)
#此示例假设目标是注意力层的查询和值投影
params_per_layer=0
formodule_nameintarget_modules:
#假设为线性层,如注意力Q/V投影
#维度通常是[hidden_size,hidden_size]
#LoRA添加A[rank,in_features]和B[out_features,rank]
#对于q_proj和v_proj:in_features=hidden_size,out_features=hidden_size
params_per_layer+=2*rank*hidden_size#简化!
total_lora_params=num_layers*params_per_layer
returntotal_lora_params
#示例:使用Llama38B的配置值(使用假设值)
classMockConfig:#用实际加载的配置对象替换
hidden_size=4096
num_hidden_layers=32
intermediate_size=14336#示例值
config=MockConfig()
#示例:仅针对Q和V投影
l_params_qv=estimate_lora_params(config,rank=8,target_modules=['q_proj','v_proj'])
print(f"估算LoRA参数(r=8,仅Q/V):{l_params_qv/1e6:.2f}M")
#示例:如果针对更多层(注意:需要根据不同层形状调整函数)
#l_params_all=estimate_lora_params(config,rank=8,target_modules=['q_proj','k_proj','v_proj','o_proj','gate_proj','up_proj','down_proj'])
#print(f"估算LoRA参数(r=8,更多模块):{l_params_all/1e6:.2f}M")
注意:实际的LoRA参数数量高度依赖于目标的具体层及其维度。示例函数进行了简化,仅提供粗略估算。
五、精度和量化的影响及多GPU开销
这里来看看精度和量化的影响、多GPU开销及其原因、估算和监控的工具与技术以及其他提示和注意事项。
1、精度和量化的影响
选择合适的数值格式对于管理显存至关重要。
量化技术(如GPTQ、AWQ或bitsandbytes库,用于QLoRA)允许以INT8或INT4权重加载模型,显著减少参数内存占用。这主要用于推理或在PEFT(如QLoRA)中作为冻结的基础模型。
2、多GPU开销
使用多个GPU会引入额外的开销,与单GPU设置相比,性能和内存使用不会完全线性扩展。这主要是由于需要进行GPU之间的通信和同步。
内存开销:每个GPU需要额外的显存用于通信缓冲区、复制的非分片参数/状态(取决于策略,如DeepSpeedZeRO阶段),以及框架管理。确切的开销较为复杂,但有一个启发式模型表明它会随着GPU数量的增加而增加。通常由于以下因素导致的性能损失:
一个是通信成本:在GPU之间传输数据(数据并行中的梯度、张量/流水线并行中的激活值/权重)所花费的时间。受限于互连带宽(例如,NVLink、PCIe、InfiniBand)和网络拓扑结构;
一个是同步成本:GPU在某些点(例如,数据并行中的参数更新之前)需要等待其他GPU;
一个是工作负载不平衡:GPU之间处理时间的微小差异可能导致等待。
3、估算和监控的工具与技术
虽然公式可以提供估算值,但实际工具有助于完善和验证显存使用情况。例如:
HuggingFaceHub:模型卡通常会列出参数数量,有时还会列出特定硬件上的预期显存;
accelerate库:包含诸如infer_auto_device_map之类的实用工具,可以估算模型如何在设备之间分配,从而了解每个设备的内存需求。它还可以简化多GPU训练/推理的启动;
bitsandbytes库:用于实现4位/8位量化(QLoRA)和8位优化器;
nvidia-smi库:标准的命令行工具,用于实时监控GPU利用率,包括显存使用情况。
watch-n1nvidia-smi
nvtop/gpustat:更交互式或简洁的命令行GPU监控工具。
PyTorch内存工具:
importtorch
iftorch.cuda.is_available():
#打印每个设备的详细摘要(如果使用多个GPU)
foriinrange(torch.cuda.device_count()):
print(f"---设备{i}:{torch.cuda.get_device_name(i)}---")
print(torch.cuda.memory_summary(device=i))
#获取运行时所有设备上分配/保留的最大显存
#注意:必须在工作负载运行后调用
print(f"所有GPU上分配的最大显存:"
f"{torch.cuda.max_memory_allocated()/1024**3:.2f}GB")
print(f"所有GPU上保留的最大显存:"
f"{torch.cuda.max_memory_reserved()/1024**3:.2f}GB")
#如需重置峰值统计信息,以便进行分段分析
#torch.cuda.reset_peak_memory_stats()
4、其他提示和注意事项
1)添加缓冲区:始终在计算的显存估算值上增加一个安全裕度(例如,10-20%),以应对框架开销、内存碎片化以及简单公式无法捕捉到的意外峰值;
2)梯度累积:如果微调时显存紧张,可以在执行优化器步骤之前,将梯度累积到多个较小的“微批量”中。这可以模拟较大的有效批量大小(随微批量大小扩展),以计算时间换取内存节省;
3)激活值检查点(梯度检查点):避免在前向传播过程中存储所有激活值。相反,它会在反向传播过程中重新计算它们。这可以显著减少,代价是增加约20-30%的计算时间。对于训练长序列或大型模型非常有效,可以绕过激活值内存估算的一些限制;
4)模型并行化:对于即使是经过优化也无法放入单个GPU的模型:
一个是张量并行:将单个层(权重矩阵)拆分到多个GPU上。需要高GPU间带宽(例如,NVLink);
一个是流水线并行:将模型的不同顺序层分配到不同的GPU上。可能会受到“流水线气泡”(GPU空闲时间)的影响,但可能比张量并行需要的带宽少;
一个是ZeRO(零冗余优化器):在DeepSpeed和FSDP(PyTorch)等库中实现。将优化器状态、梯度以及可选的参数分区到多个GPU上(不同阶段提供不同级别的内存节省和通信开销);
一个是CPU卸载:像DeepSpeed中的ZeRO-Offload这样的技术会将优化器状态、梯度甚至参数暂时移动到CPU内存中,当GPU不立即需要时。这可以显著减少显存需求,但由于CPU-GPU数据传输较慢(通过PCIe总线),会带来显著的性能开销。当显存是绝对限制因素时非常有用。
参考文献
1、https://apxml.com/posts/how-to-calculate-vram-requirements-for-an-llm
2、https://apxml.com/tools/vram-calculator
(文:老刘说NLP)