

极市导读
北航与小红书联合发布大模型翻译研究成果 RedTrans,通过双模型回译采样和强化学习偏好优化等创新方法,解决了社交生活化场景中翻译数据稀缺、风格偏好对齐等难题,显著提升了翻译准确性和风格适配性,并构建了高质量社交翻译评测基准,为社交翻译领域树立了新标杆。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文标题:Redefining Machine Translation on Social Network Services with Large Language Models
研究团队:北航、小红书NLP团队
论文链接:https://arxiv.org/abs/2504.07901
GitHub:https://github.com/HC-Guo/RedTrans
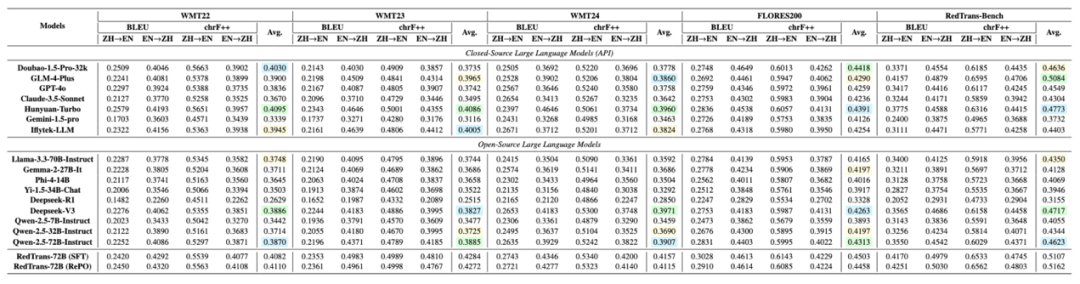
从评测结果可以看出:在公开翻译评测基准WMT 22-24,以及社交生活化翻译评测基准,本文提出的RedTrans翻译大模型均取得行业领先效果,不但优于开源大模型,也超越了商用闭源大模型,如GPT-4o和Claude-3.5-Sonnet等,在翻译任务中展示出不错的效果。
01社交生活化场景翻译挑战
在真实社交生活化场景中,实现高质量机器翻译主要面临以下三重难题:
(1)缺乏大规模高质量标注数据——难以全面优化模型。 社交生活化语言包罗万象、更新迅速,然而人工标注代价高昂,导致现有训练集多聚焦于新闻、书籍、网页等文本。因此,缺乏贴近社交领域的高质量平行数据,使得模型往往只能“迁移”而难以“适配”,在流行语、表情符号语义和文化梗等高语境依赖内容上出现理解偏差。
(2)跨文化表达与风格偏好——需解决“意思对了、味儿不对”。 社交场景语言不仅传递字面信息,更承载情绪语气与群体文化。例如 “破防”、“狗头”、“笑死” 等词汇背后暗含独特情感映射,若翻译只关注语义等价而忽视风格和情境,就会造成文化维度缺失、幽默感丧失,进而影响用户体验。此外,不同用户群体对译文语气、口吻的偏好也存在一定差异,这就要求模型具备细粒度的风格调控能力。
(3)评测基准缺口——缺乏针对生活化内容的统一度量。 现有评测基准大多服务于通用或正式场合的翻译,难以覆盖“多语混杂、弹幕式口语、emoji 语义”等社交平台特有现象,更难衡量译文在幽默、俚语、情绪传递等方面的质量。因此,亟需构建涵盖真实社交交互数据、聚焦文化细节与表达多样性的专用评测基准,为模型改进和方法比较提供统一、可靠的量化环境。
综上,数据稀缺、风格/文化偏好对齐,以及评测基准的缺失,共同构成了影响社交生活化翻译的效果瓶颈。

02社交场景翻译创新方案设计
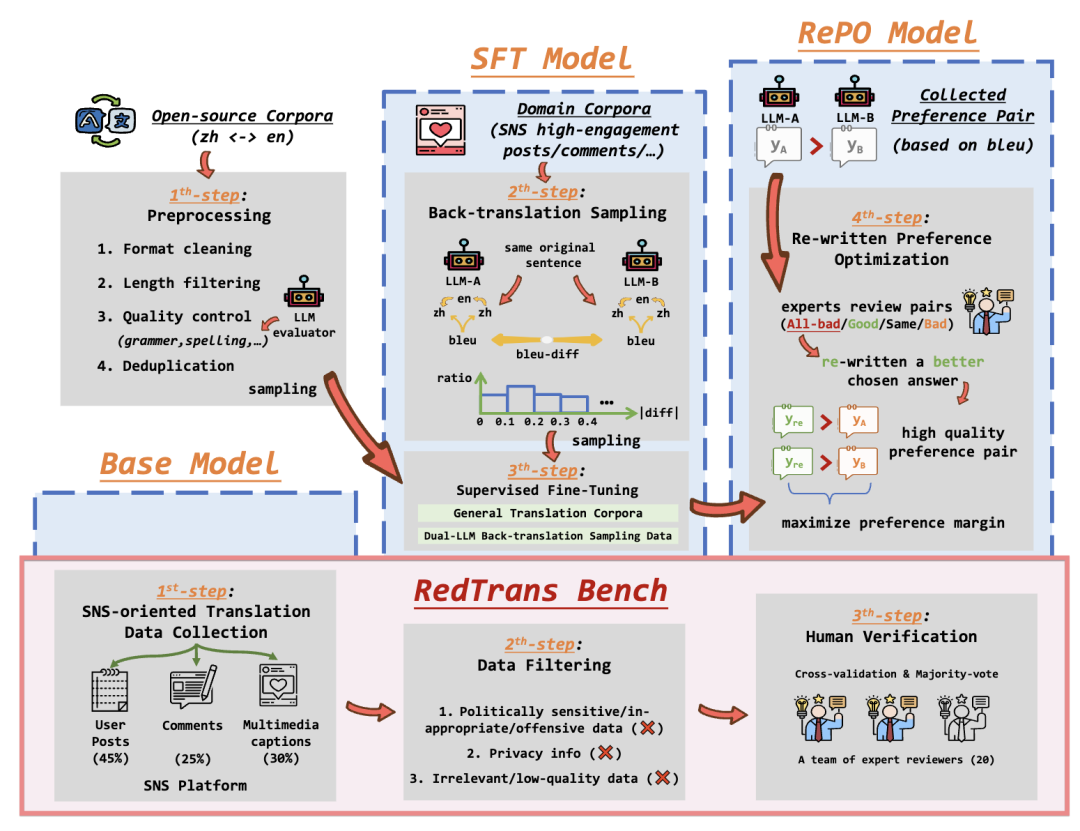
我们经过反复研究和实验验证,设计了社交生活化场景下的翻译技术方案(如图2所示):
2.1 无需标注数据,提高翻译准度:基于双模型回译采样的蒸馏微调。
采用蒸馏微调的方式对大语言模型进行训练,以提高其对社交网络特有内容的翻译准确性。为了克服传统平行语料在社交领域的稀缺性,通过不依赖人工标注的方式,提出了双模型回译采样方法:首先使用两个不同的大语言模型,对同一批数据分别进行翻译,接着再翻译回源语言,然后,通过BLEU等指标度量差异大小,将差异较大的回译结果分层抽样,保证数据多样性。通过这一过程,能够从大规模无标注语料中筛选出高价值的平行数据,极大提升模型的翻译能力。
2.2 翻译风格偏好对齐:强化学习方法 RePO。
常规的偏好对比方法DPO(Direct Preference Optimization)遇到社交类翻译问题时,可能因翻译风格而产生不尽人意的效果。为此,我们提出了重写偏好优化(RePO)算法,利用RLHF技术对齐译文的社交生活类语言风格。其中,当偏好样本对中皆无法达到翻译质量要求时,会由翻译专家人工介入,给出一个优于二者的“最佳翻译答案”,将其与原样本配对,构造出偏好数据并进行模型训练。通过充分利用少量人工偏好标注,模型能够更好地修正翻译过程中的风格问题。
2.3 社交生活化领域翻译评估破局:提供高质量Benchmark。
在社交生活化场景翻译中,为获取高质量、高可信度的评估数据,我们提供了一个高质量的中英翻译评测基准,该基准包含了大约3000条经过严格筛选的人类标注测试集,涵盖幽默、表情语义、俚语、流行文化等多元场景。数据来自真实社交平台的高互动帖子、评论及多媒体字幕,并且特别关注了文化迁移、表情包翻译和梗文化传递等较难情景。
03实验结果与分析
3.1 评估数据分析
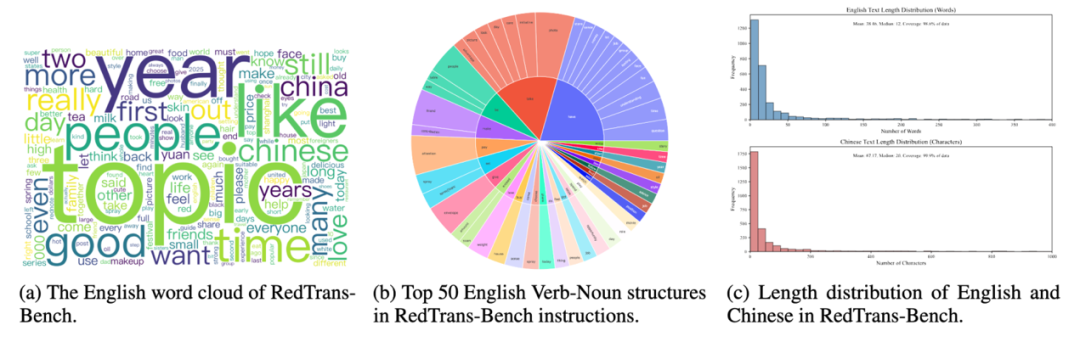
为确保模型真正理解社交语言的“风格”,我们对翻译数据进行了深入分析。从高频词(如“topic”、“people”、“year”)到动词结构(如“take photo”、“make time”),再到中短文本为主的长度分布,充分覆盖了社交场景真实语言的口语化特点。
3.2 RePO(Rewritten Preference Optimization)消融分析
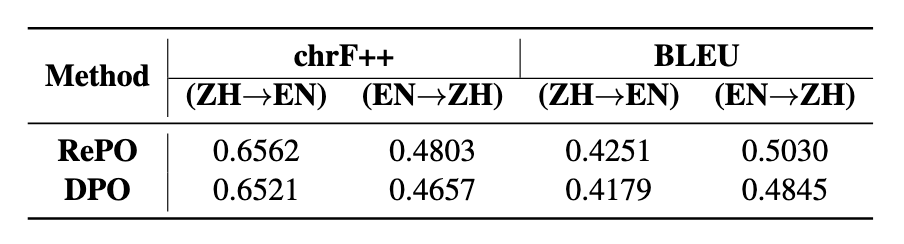
如图4所示,RePO相比DPO显著性能提升。在中英互译的 BLEU 和 chrF++ 指标上,RePO 均优于DPO(Direct Preference Optimization)。改写机制强化训练信号质量:RePO 引入了“重写一个更优答案”的机制,将低质量或模糊的偏好对改写为可信样本,从而提高训练集的一致性与鲁棒性,这对于社交场景这种偏好分歧大的语境尤其有效。同时,翻译风格表达的适应更强:相比DPO仅基于大模型生成的偏好对排序优化,RePO 更能体现社交风格,例如,“you are not my type”翻译为“你不是我的菜”和“你不是我喜欢的类型”这类表达选择上,RePO的表现更贴合用户认知,提升了模型处理俚语、网络用语和文化特定表达的准确性,使翻译结果更贴合社交场景的使用习惯。
3.3 双模型回译采样分析
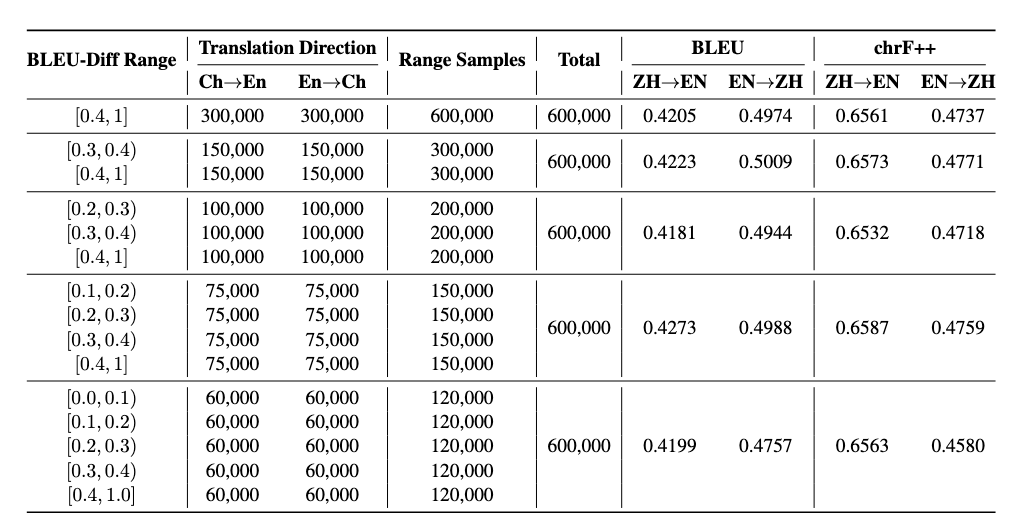
从图5可以看出:
-
分段采样提升数据多样性:通过将回译样本按 BLEU 差值进行分段采样,提高了训练集的多样性;
-
中等差值采样效果最佳:在 BLEU 差值 0.3–0.4 区间采样的数据,在 BLEU 和 chrF++ 两项指标上表现最平衡,说明中等程度的语义变化能带来更强的泛化能力;
-
低差值样本略拉低BLEU:进一步扩展到 BLEU 差值 0–0.1 时,指标略有下降,说明较低的采样差异会导致训练噪声;
-
避免高偏差和低多样性共存:单独使用高差值样本(>0.4)或低差值样本(<0.1)都会导致模型训练不稳定,混合分布采样是更优解。
3.4 自动化评测指标分析
最后,在社交生活化产生,我们对自动化评测指标有了全新的思考:在大模型翻译时代,我们需要重新审视XCOMET。最初,诸如XCOMET等语义相似性指标,主要是为了弥补BLEU等基于N-Gram计算指标在语义理解层面的欠缺;然而,大模型翻译恰恰擅长的是语义理解和生成,如果太依赖于语义相似性来评估,那么在社交生活化场景反而无法精准评估模型的翻译精准度和风格。因此,我们发现BLEU指标反而更加贴合社交场景的翻译效果评测。
04总结
通过引入双模型回译采样,以及强化学习偏好优化,有效解决了传统翻译在社交生活化场景中遇到的诸多问题,不但提升了翻译准确性,还改善了翻译风格。同时,72B模型的性能超越了闭源商用大模型,证实了“无标注数据蒸馏+少量偏好数据优化”可以打破模型参数规模的限制。此外,提出的社交化场景的评测基准与自动化指标的探索,也为推动社交化翻译发展带来了源动力。
作者简介
郭宏成: 北京航空航天大学计算机系博士,小红书NLP团队实习生,主要研究方向:大模型在智能运维、视频生成、智能代码、社交媒体、智能医疗等多领域技术研究和应用。获得华为天才少年等互联网人才称号,DolphinAI联合创始人,受到雅克·苏凯院士等多方单位的共同支持,累计发表CCF A/B类论文三十余篇,担任Neurips、ICLR、ICML、ACL、EMNLP、NAACL、AAAI等会议审稿人。
赵飞: 硕士毕业于上海交通大学,小红书NLP团队算法工程师,专注于大语言模型和多模态大模型的RL、SFT和评估,发表过多篇SCI期刊和顶会论文,同时也是知乎/B站技术账号“大家好我是爱因”的作者。
曹绍升: 小红书NLP团队负责人,发表论文30余篇,授权专利100余项,引用近4000次,获得ICDE 2023年最佳工业论文奖、CIKM 2015-2020年最高引用论文、AAAI 2016最具影响力论文。此外,他荣获了中国发明协会创新成果一等奖(排名1)、中国人工智能学会吴文俊科技进步二等奖(排名1),连续4年入选世界人工智能学者榜单AI-2000新星榜前100名、Elsevier中国区高被引学者,CCTV-13《新闻直播间》采访报道。
吕欣泽: 硕士毕业于南京大学,现小红书NLP团队算法工程师,从事机器翻译在小红书业务中应用。主要研究方向:大模型应用、机器翻译和Agent等。
刘子岩: 现就读于北京邮电大学电子工程学院,2023级硕士生,小红书NLP团队算法实习生,在ACL、EMNLP等国际顶会发表过多篇学术论文,主要研究方向:多模态大模型、大模型推理、多智能体系统等。
王岳: 现就读于南京大学计算机学院,2023级硕士生,小红书NLP团队算法实习生,在KDD等国际顶会发表过学术论文,主要研究方向:大模型微调应用、LLM评测等。
鲁重钢: 硕士毕业于北京航空航天大学,小红书NLP团队算法工程师,在SIGIR、EMNLP等国际顶级会议发表多篇学术论文,研究兴趣主要为大模型后训练,Agent系统,大模型检索增强等。
李舟军, 北京航空航天大学计算机学院教授、博士生导师。长期从事数据挖掘、自然语言处理、人工智能与深度学习、智能问答等相关领域研究。在TKDE、AAAI、ACL、IJCAI、KDD等国际顶会和顶刊上发表论文400余篇,获得部委级科技成果二、三等奖,获中创软件人才奖、全国优秀博士学位论文提名、ECIR 2010最佳论文奖、国际知名AI公司Adept Mind终身成就奖、2019年吴文俊人工智能科技进步一等奖,连续入选2023年、2024年全球前2%顶尖科学家榜单。

(文:极市干货)