

Magi-1,开源于北京,五道口
于是,很多朋友发现了:
在视频圈子,Magi-1 映入了大家眼帘不到两天,在 GitHub 上拿到了 1.7k Star
这全球首个高质量自回归视频模型
着实的,给中国开源,涨了波脸
国产 Magi-1,在物理真实性上,断层第一
在物理真实性测试中,比谷歌的 VideoPoet,还高出 3 个 Sora
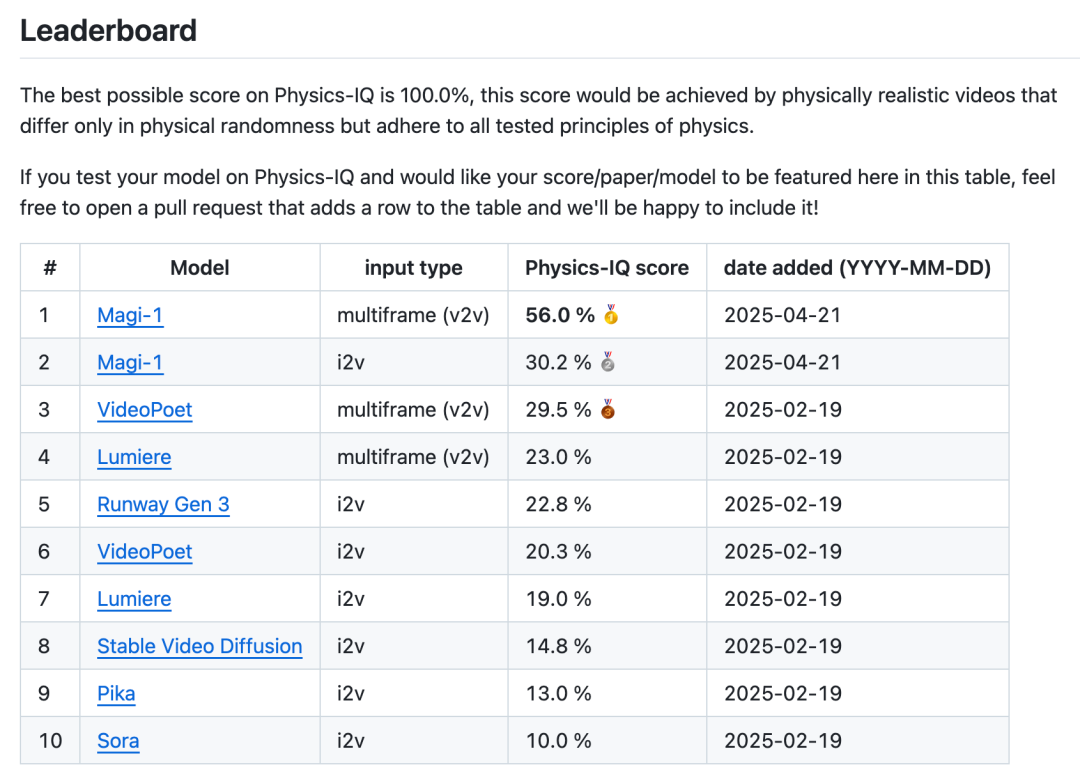
Twitter 上的讨论
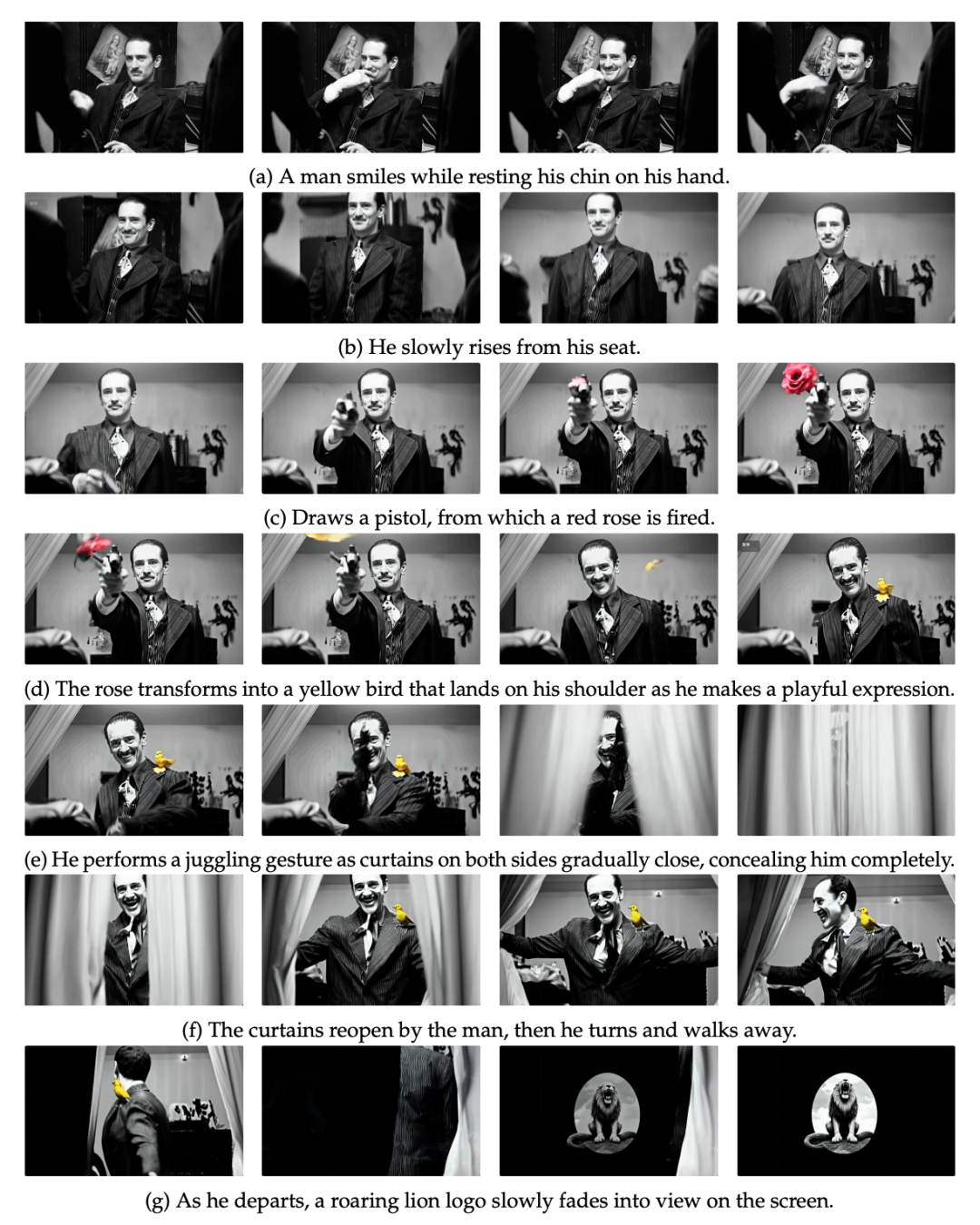
来看看效果
相信我,这是一个划时代的发布
干得漂亮
务实一点说,Magi-1 在画面稳定性上,还有所欠缺。
但在常见场景中,开源的 Magi,已经能跟可灵们掰掰手腕了。
令人敬佩的是,他们验证了自回归视频模型 这条路线,使模型可以遵循现实的因果律,在相关推理任务中,遥遥领先。
你没看错,包括 Sora 在内的各类视频生成 AI,是把整个片段同时画出来,不区分“先发生什么,后发生什么”,不存在时间,更无法遵从相关因果律。
而 Magi-1 大胆革新,做到了,而且做的很不错。
益于自回归架构的天然优势,Magi 在预测物理行为方面,远超现有模型的精度

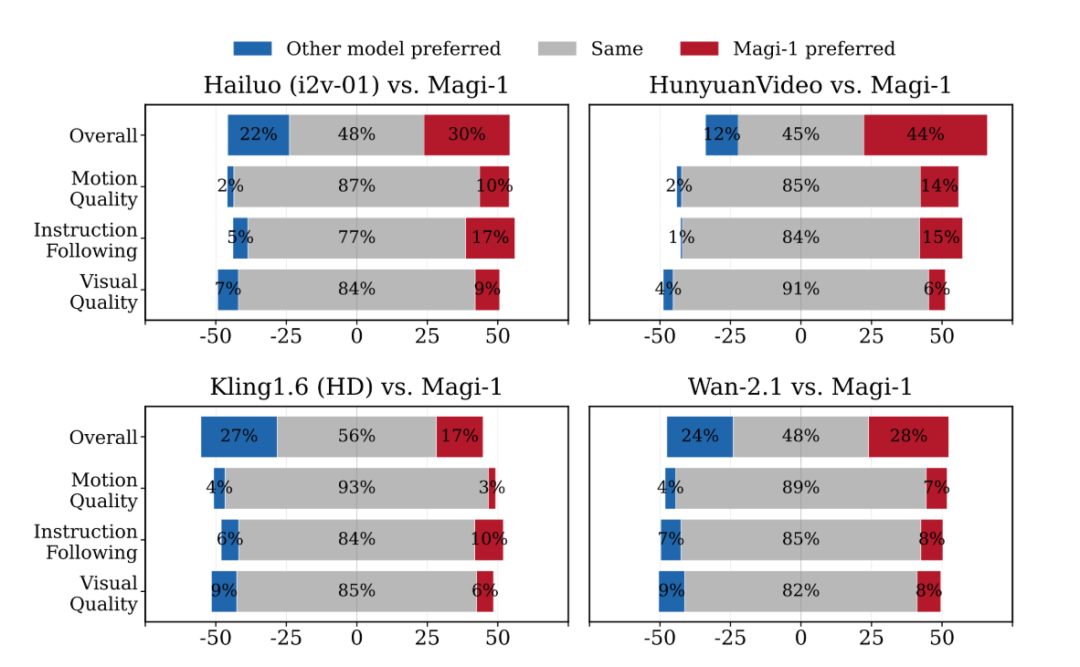
在指令遵循和运动质量方面,Magi 表现不错
然后,这个 Magi 开源了,从4.5B到24B:
https://huggingface.co/sand-ai/MAGI-1

再然后,他们还上线了一个可以开箱即用的产品:
https://sand.ai/magi
Magi-1 背后的团队,是 Sand.ai
创始人是曹越,「光年之外」联合创始人。
之前,在他办公室里聊了半个下午,问了大量私货,有了这篇文章
本篇,应是对 Sand.ai 最全面的介绍了

是谁做的?
创始人是曹越。
清华特等奖学金,ICCV 马尔奖(Marr Prize),Swin Transformer 共同一作,博士毕业后加入微软亚洲研究院,后任智源研究院视觉中心负责人。

2023 年年初,他和王慧文、袁进辉共同创立了大模型公司「光年之外」,担任算法联创。
之后,光年之外被收购。
袁进辉成立了「硅基流动」,而曹越则继续深耕视频生成方向,并2024 年正式创立 Sand.ai(三呆科技…这名字太抽象了),Magi-1 便是团队推出的首个模型产品。
我眼中的曹越
曹越非常敏锐,思维极为清晰,不讲玄虚,会把一个个概念拆成因果讲清楚。
有一天,在 Sand.ai 的办公室,我们就视频生成的未来,聊了整个下午。
主题很直接
视频能不能被真正「生成」?
如果能,路径应该是怎样的?
我们聊了视频生成的各类方法,比如 DiT。看起来高效、效果也不错,但它本质上是把几秒钟的视频,一次性生成。
生成视频的时候,过去和未来是同时出现,不存在时间。
因此,在视频生成的 AI 中:控制“场景”容易,控制“发生”很难。
问题很直白
如果视频是时间的表达,那生成它的方式,就必须能处理时间。
这也是 Magi-1 的起点:如果想让视频更符合人的认知,就要有时间因果性,就不能假装时间是静态的。
于是,Magi-1 便开始了此路径上的探索:秒内 Dit,秒外自回归,每一段视频都是基于前面的内容,往下推进。
这也便有了后面会看到的 chunk-by-chunk 结构,也是为什么它可以精确到每一秒发生什么、能接着拍下去,而不是只是“画出一段动图”。
团队不大,出身很硬
Sand.ai 的团队不大,三十人的团队,几乎都是技术人员,其中不乏科研出身的算法专家。
联合创始人张拯,也是 Swin Transformer 的作者之一,ACM 亚洲金牌,MSRA 老同事。他和曹越在微软合作了五年,一起打磨过不少视觉模型。 Google Scholar 引用接近 5 万,算是这条路线里默默干活、极少抛头露面的那种人。
还有几位核心算法,背景都差不多——MSRA、智源、清华、华中科大。工程团队亦人才济济,清华、北大、南大、厦大。
这也决定了他们在技术选型上的很多不寻常。比如:
-
• 不做并发采样; -
• 不用标准扩散路径,而是自回归扩散; -
• 自写推理系统,从 attention 到 chunk cache 都是自己改的。
把整个结构从头写一遍。
三轮融资,一路没断
Sand.ai 自打创立,便在 VC 圈里到了很多关注:目前已经完成三轮、总计约六千万美金。
几轮融资的主领投方分别是:源码资本、今日资本、经纬中国。
跟投方也很强大:创新工场、IDG、襄禾、商汤、华业天成,再加上一些业内的个人投资者。
可见,Sand.ai 很早就被人看懂了方向、认了出来、下了重注:
-
• 这是新的路线探索; -
• 能打穿结构 +基础设施; -
• 能 scale 的训练、推理体系。
不在追随谁,而在走自己的路
技术原理
上面浅提了过,比如 OpenAI 的 Sora 这样 DiT 模型的工作方式:一口气生成几秒视频,然后拼接起来播放。
这听上去没什么问题,甚至很高效。但本质上,它们是并发生成,没有时间顺序。你写一个 prompt,模型一次性把整个片段画出来,未来和过去是同时想象出来的:不区分先发生什么,后发生什么。
这就会带来一个问题:生成的视频,未必遵循现实的因果律,缺乏真正的时间感
Magi-1 的解决思路
它采用的是一种叫做 chunk-by-chunk 的自回归生成 方法。
视频被划分为一个个时间片段(chunk),每段比如 24 帧,相当于 1 秒的视频。 每生成一段,才会进入下一段。下一段的内容,要基于上一段的内容来生成。
这个结构天然地保留了因果性,时间在模型里是顺序展开的,而不是拼装进来的。

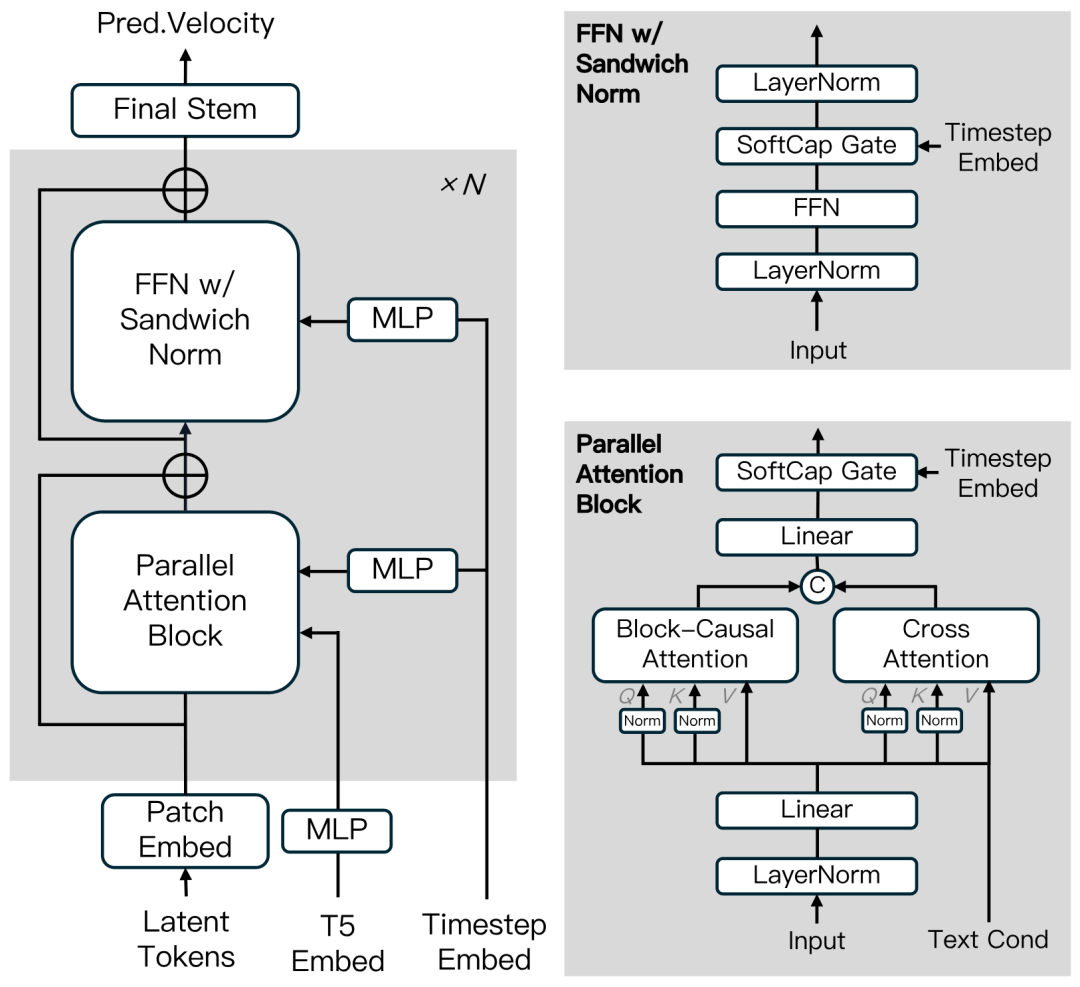
具体来说,它使用一种叫做 block-causal attention 的机制:
-
• 块内是全连接,保留短时段的一致性; -
• 块与块之间是单向连接,只能“看前不看后”。
这种方式,保证了每一段的生成都带着“记忆”,并且不会被未来的信息干扰。
Magi-1 的训练方法
训练时,模型不是一次性还原整个视频,而是逐段对每个 chunk 进行去噪。每个 chunk 会被注入不同程度的噪声(前面的噪声少,后面的噪声多),模型的任务是学习如何根据时间顺序去还原这些 noisy chunk。
论文中这一机制叫作:时间上单调递增的噪声注入(temporally progressive noise levels)。
生成时,Magi-1 会在 chunk 被“去噪到一定程度”时提前进入下一个 chunk 的生成。所以模型可以流式生成、边播边推,同时还能保持时间上的逻辑闭环。
通过这些,Magi-1 有了几个非常实际的能力:
-
• 无限时长生成:可以不断续写,一直“接着生成”,没有固定长度限制; -
• 每秒控制粒度:可以对每个 chunk 加不同的 prompt,精确指定什么时候发生什么; -
• 推理成本固定:每个 chunk 的计算开销是定值,长视频不爆显存;
全新的算法范式,带来了业界从未解决过的工程挑战。
在之前,业界没有解决方案可以同时满足:
-
视频的超长序列
-
自回归与 Chunk 结合带来的复杂 attention
-
千卡集群训练
为了解决这个问题,Sand.ai 从底层通信元语到上层调度算法,都做了全栈创新,并把全套解决方案开源给技术社区。
能做视频续写
有意思的是,Magi-1 不止支持 T2V(文本生视频)和 I2V(图生视频),它的结构天然也能做 V2V(视频续写),而且效果远好于 I2V 模拟续写。
论文第16页的实验对比非常直接:
-
• 笔旋转的例子里,I2V 模型完全预测不了旋转的速度; -
• Magi-1 的 V2V 模式则能把动作延续得很自然,因为它确实“看到了前面”。

推理效率下了功夫
它的推理过程是“并行去噪 + pipeline 式推进”,最多可以同时生成 4 个 chunk,每段都带有历史记忆,但不会因为长度变长而爆显存。得益于它的自回归结构和 KV 缓存机制,哪怕是分钟级视频,系统推理的峰值资源也不会变。
在论文第2页有一句话说得很清楚:
“Magi-1 的推理峰值资源使用量,与视频长度无关。”
这一点对于部署来说意义非常大:它真的可以跑长内容、实时生成,不靠截断、不靠分段预处理。
再补充点细节
Magi-1 的结构不是从 Diffusion Transformer 拿过来直接用,而是在 attention、FFN、条件编码、位置编码上都做了大量改进。
包括:
-
• 3D 可学习 RoPE 位置编码; -
• 平行 attention 结构(合并 self-attn 和 cross-attn); -
• SwiGLU 激活 + sandwich norm 稳定训练; -
• QK-Norm + GQA 以节省内存并提升收敛稳定性;
这些都藏在结构实现里,没有在首页图表里体现,但在训练大模型时非常关键。
回顾一下
Magi-1 做的是这样一件事:
它让视频生成这件事,从“像画图一样生成结果”, 变成了“像连续剧一样,一集一集生成”。
这或许是一个新的范式。而这一切,现在已经开源了。
开源了,而且是全套交付
是真的,全放了。
模型权重,从 4.5B 到 24B 的全尺寸都开了。推理脚本和训练代码也都在,支持文本生成视频、图像生成视频,以及视频续写。用的是标准 HuggingFace 接口,也有 CLI 和 Gradio 的完整推理链路。

部署也比较轻,不是那种只能跑在高性能集群里的模型。最小版本一张 4090 就能跑,开箱即用,推理成本也不会随着视频长度线性增长。
伴随代码开源的同时,也有一份完整技术报告(61页):从机制设计到训练策略、推理流程、基础设施都讲清楚了,把一整个系统的内部文档摊给你看,就像 DeepSeek 那种风格。

还有个产品
除了开源,它还有个产品,已经能用了。
官网在这:
你开源上传一张图,写一句话,它就能生成视频。每次生成的时长由你控制,也可以开启“增强理解”“高质量”等选项。

最妙的是,它支持从任意时间点续写。你可以先生成一小段,然后从中间某一秒接着写下去,或者换个 prompt 接续新镜头。不是“生一个开头”,而是一个可以不断拓展、不断演化的生成工具。
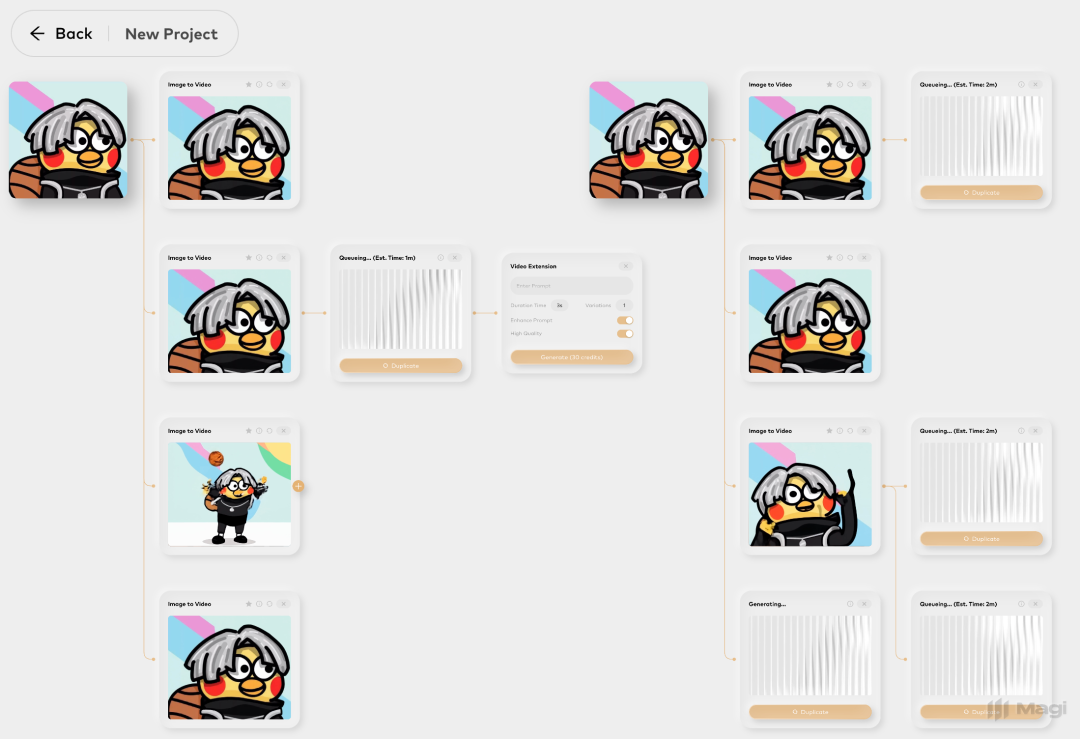
开源和产品一起推出来,这在视频模型里并不常见。
最后
Magi-1 想做的事其实挺朴素的:让视频这件事,能被生成,符合规律。
它没有走当下最主流的路线,也没有追求最炸的效果,而是选了一条更难但更扎实的路径:从时间出发,构建更真实的物理世界模拟器。
这件事的意义,在于它跑通了一个原本只有想象的可能
最后,用曹越的话来结尾
语言模型,偏向于虚拟世界;
视频模型,更偏向于现实世界。
目前的视频模型,还在一个比较早期的阶段,但长期所谓的“世界模型”,会在这个方向上。
(文:赛博禅心)