


本文第一作者顾煜贤(https://t1101675.github.io/)为清华大学计算机系四年级直博生,师从黄民烈教授,研究方向为语言模型的高效训练与推理方法。他曾在 ACL,EMNLP,ICLR 等会议和期刊上发表近 20 篇论文,多次进行口头报告,Google Scholar 引用数 2600+,曾获 2025 年苹果学者奖学金。本篇论文为他在微软亚洲研究院实习期间所完成。
近年来,大语言模型(LLMs)在自然语言理解、代码生成与通用推理等任务上取得了显著进展,逐步成为通用人工智能的核心基石。然而,训练此类模型所需的计算资源和数据成本正以惊人的速度增长。面对高质量语料日益枯竭、训练预算持续上升的双重挑战,如何以更少的资源实现更高效的学习,成为当前语言模型发展的关键问题。
针对这一挑战,清华大学、北京大学联合微软亚洲研究院,提出了一种全新的预训练数据选择范式 ——PMP-based Data Selection(PDS)。该方法首次将数据选择建模为一个最优控制问题,并基于经典的庞特里亚金最大值原理(PMP)推导出一组理论上的必要条件,为预训练阶段中 “哪些数据更值得学” 提供了明确的数学刻画。
在理论基础之上,研究团队设计了可在大规模语料中高效运行的 PDS 算法框架,并在多个模型规模和任务设置中进行了系统验证。实验结果表明:
-
PDS 在不修改模型训练框架的前提下,通过一次离线选择,即可实现训练加速达 2 倍;
-
在多项下游任务中,PDS 显著优于现有数据选择方法,且对大模型训练具有良好的泛化能力;
-
在数据受限条件下,PDS 可减少约 1.8 倍的训练数据需求,提升数据利用效率。
PDS 不仅在实际效果上具备显著优势,更重要的是,它建立了一套以控制论为基础的数据选择理论框架,为理解预训练动态、提升模型可解释性与可控性提供了全新视角。目前,该成果已被机器学习顶级会议 ICLR 2025 正式接收,并入选口头报告(Oral, top 1.8%)。

-
论文标题:Data Selection via Optimal Control for Language Models
-
论文地址:https://openreview.net/forum?id=dhAL5fy8wS
-
开源代码:https://github.com/microsoft/LMOps/tree/main/data_selection
研究背景:训练大模型,不只是 “多喂数据” 这么简单
近年来,大语言模型(LLM)不断刷新下游任务性能的记录。但与此同时,一个关键问题也日益突出:训练这些模型所需的数据和计算资源呈指数级增长。面对海量的互联网文本,如何挑选 “更有价值” 的数据,成为提升模型效率与性能的关键一步。
现有的数据选择方法大多依赖启发式规则,如去重、n-gram 匹配、影响函数等,缺乏理论指导,效果难以稳健推广。而另一方面,部分方法尝试利用训练过程中的反馈动态进行在线数据筛选,却需修改训练流程、增加训练时的计算开销,实用性有限。
这项工作跳出常规视角,借助控制论中经典的庞特里亚金最大值原理(Pontryagin’s Maximum Principle, PMP),首次将数据选择建模为一个可解析的最优控制问题,为理解和实现最优数据选择提供了系统的数学框架,并基于此框架设计出了一套离线数据选择算法,在不增加训练开销的情况下提升性能。
理论创新:数据选择是一个 “控制” 问题
作者们提出,将训练过程看作一个动态系统,数据的选择权重作为控制变量,模型参数作为系统状态,而最终下游任务的表现则是目标函数。在这个框架下,预训练的每一步都对应状态的变化,而合理分配每条数据的 “重要性权重”γ,即是在有限预算下寻找最优控制策略。基于经典的庞特里亚金最大值原理(PMP),他们进一步推导出最优数据选择策略所需满足的必要条件(PMP 条件)。根据此条件来选择数据可以很大程度上保证选择结果的最优性。

图 1: PMP 条件的图形化解释
PMP 条件最关键的思想是:给出了最优的训练样本应该具有的梯度方向(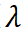 ,如上左图所示),并选择那些梯度方向与最优梯度高度一致的数据点,在数学上表现为梯度与 的内积最大(如上右图所示)。
,如上左图所示),并选择那些梯度方向与最优梯度高度一致的数据点,在数学上表现为梯度与 的内积最大(如上右图所示)。
该理论的核心价值在于:它不仅提供了选择高质量数据的明确准则,而且揭示了目标任务性能、模型训练动态与最优数据选择之间深层次的联系。
算法设计:构建高效实用的 PDS 框架
为了将理论应用于实际的大规模语言模型训练,作者设计了 PMP-Based Data Selection (PDS) 算法框架,如下图所示:
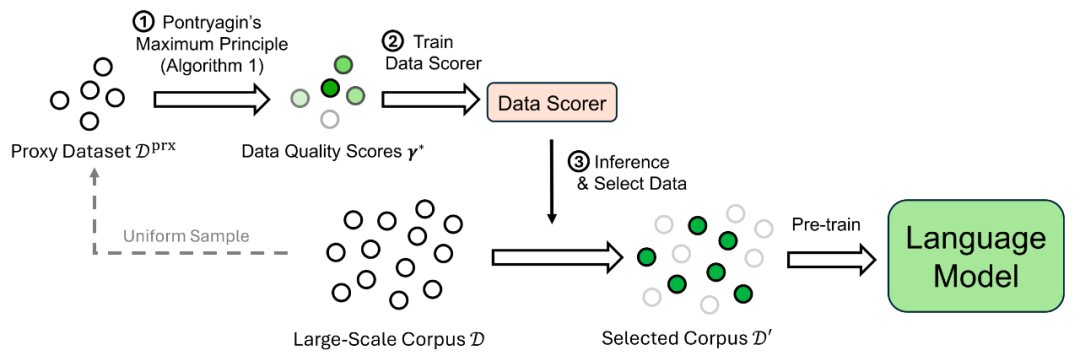
图 2: PDS 数据选择框架
该算法分三步进行:
1. 在代理环境中解 PMP 方程组:在一个小规模代理模型(如 160M 参数)和代理数据集(如 0.2B tokens)上迭代求解 PMP 方程组,得到代理数据集上的最优数据选择策略 γ*;
2. 训练数据打分器(data scorer):用一个小模型在代理数据集上拟合 γ*,根据输入样本输出其质量分数,然后为全量数据集打分;
3. 选择高质量数据用于大模型训练:根据打分结果,对于任意的数据阈值(如 50%),选择得分较高的样本,用于训练目标模型。
该方法完全离线进行,仅需运行一次,即可支持任意规模模型训练,且无需修改已有训练框架,对于高度优化的预训练代码来说,只用更换数据源,具有高度实用性与工程友好性。
实验效果
在实验中,作者基于 Redpajama CommonCrawl 中 125B token 的数据,使用 PDS 方法选出其中 50B tokens 用于训练 160M 至 1.7B 规模的语言模型。评估任务覆盖 9 个主流下游以及语言建模任务。
性能提升
在不同模型规模下,PDS 训练出的模型在 9 个下游任务上的整体性能优于随机选择(Conventional)、RHO-Loss、DSIR、影响函数(IF-Score)等方法,并且性能提升趋势随着模型规模的扩大依然可以保持:
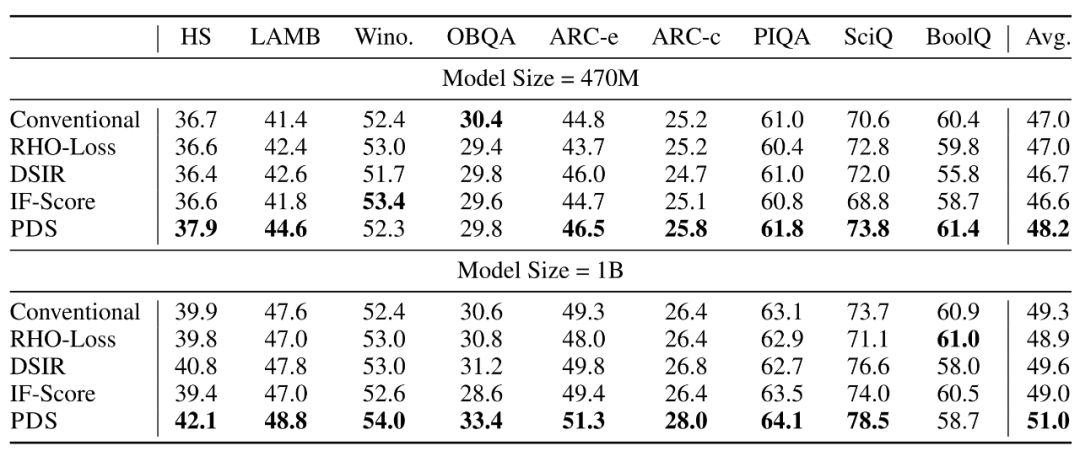
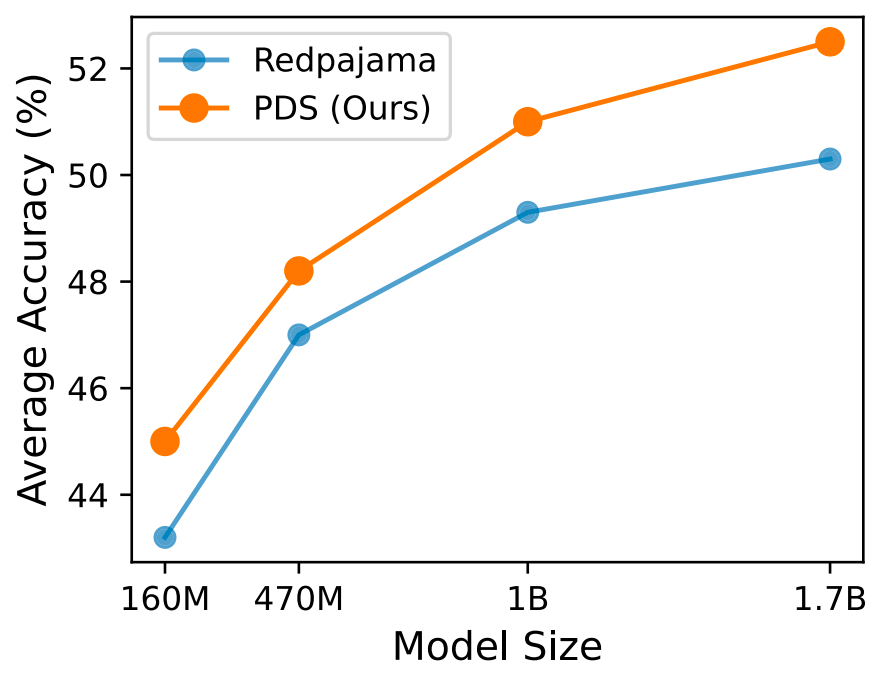
图 3: PDS 和其他数据选择方法的性能对比。
此外,如下左图,PDS 方法训练出来的模型在高质量语料(如 DCLM)上的语言建模性能也显著优于随机选择。如下表,使用语言模型的扩展定律外推到 GPT-3,Llama 系列模型的训练规模之后,PDS 的性能优势依然明显。
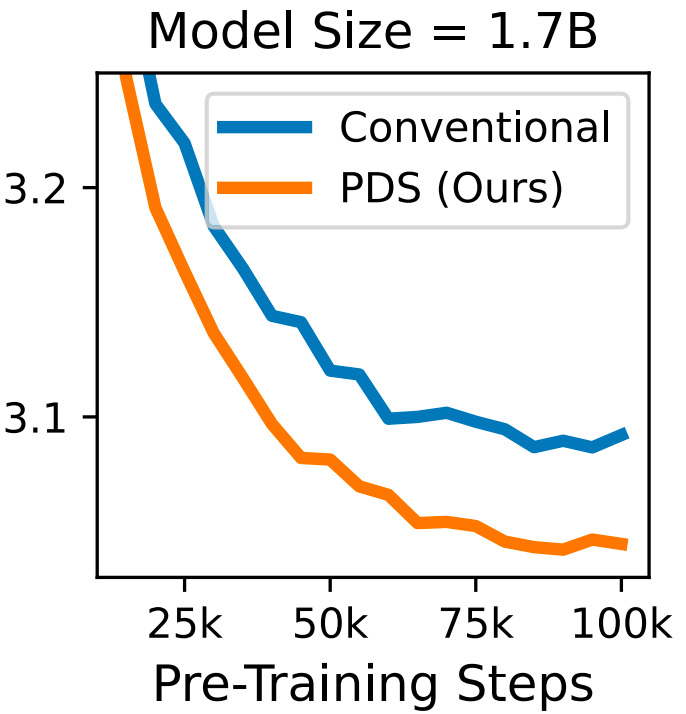
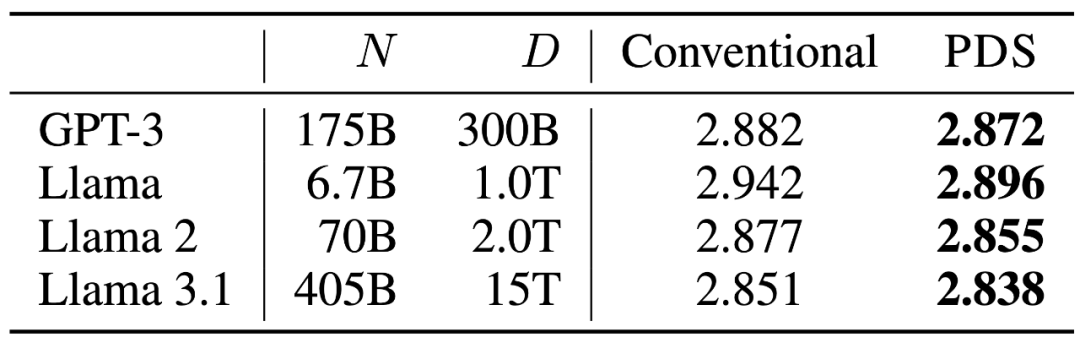
图 4: PDS 方法训练出的模型在语言建模任务上的性能
训练加速
如下图,在达到同等下游任务性能的情况下,PDS 能将 1.7B 模型的训练 FLOPs 减少约一半。值得注意的是,PDS 中对 PMP 条件的求解都是在预训练阶段离线完成的,从而避免了引入训练时开销。
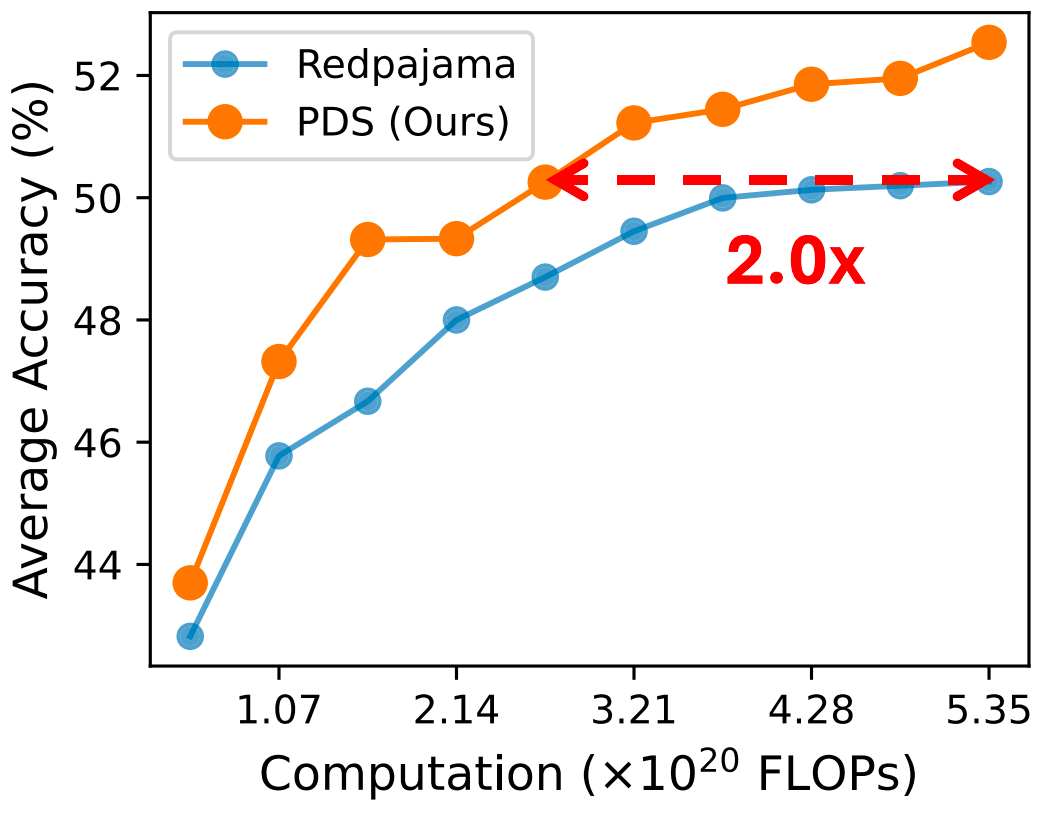
图 5: PDS 对于模型预训练的加速效果
数据利用率提升
作者们通过实验证明,在数据受限场景下,使用 PDS 选择一部分高质量数据并进行多轮训练,要好于使用原始数据进行一轮训练。如下图,图中蓝线表示使用原始数据进行 1 轮训练,而橙色线、绿色线、红色线分别表示使用 PDS 选择原始数据的 50%,25% 和 12.5%,并进行 2 轮,4 轮和 8 轮的训练,从而保证总体训练 token 数一致。可以看到,使用 PDS 选择质量较高的 25% 数据表现最好,由此说明 PDS 提升了数据有限情况下模型的性能,即提升了数据利用率,缓解了 “数据枯竭” 问题。
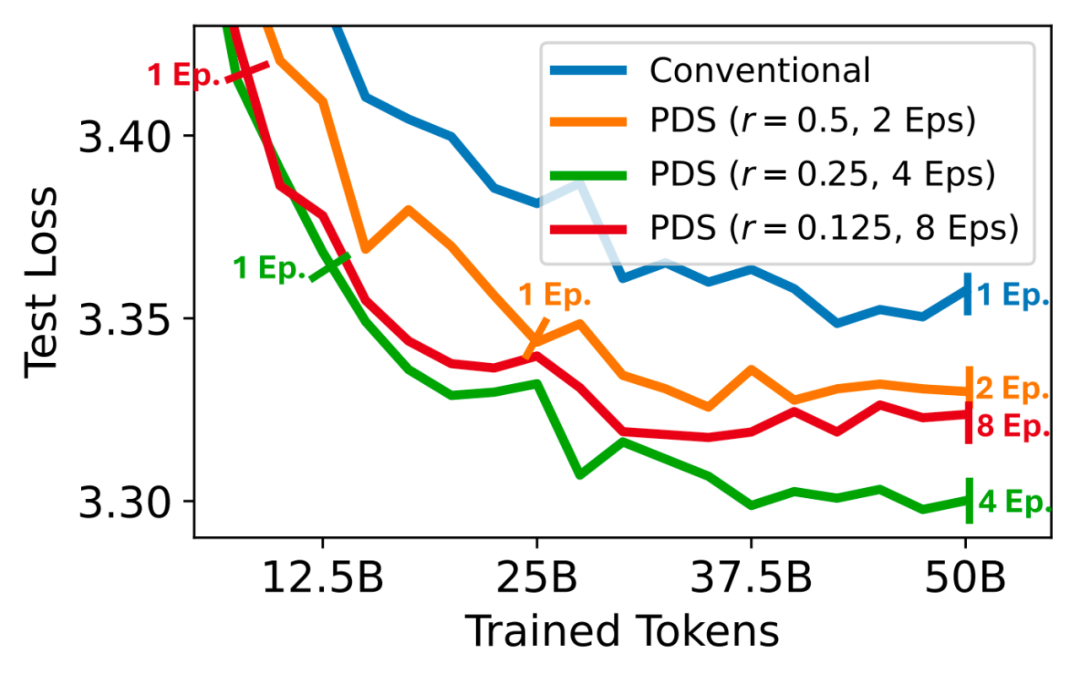
图 6: 数据有限情况下的数据选择
未来展望:为 “数据驱动的 AI” 构建理论框架
当前大模型的预训练过程仍高度依赖经验与启发式规则,模型如何学习、数据如何影响学习的机制长期处于 “黑箱” 之中。本工作通过最优控制理论建立起数据选择与训练动态之间的数学联系,为理解预训练数据的价值提供了理论抓手。
这一方向不仅有望替代传统依赖直觉与试验的数据筛选流程,也为未来自动化、可解释的大模型训练打开了新思路。作者们相信,围绕 “如何选择学什么” 这一核心问题建立理论体系,将成为推动 AI 从经验工程走向科学建模的关键一步。
©
(文:机器之心)