

在AI技术迅猛发展的今天,大语言模型(LLM)和检索增强生成(RAG)系统已成为开发者构建智能应用的核心工具。
然而,许多团队在落地过程中发现了一个关键痛点:AI模型的性能高度依赖于输入数据的质量。尤其是当处理非结构化文档(如PDF、扫描件、图文混排报告)时,传统OCR工具往往只能提取“文字碎片”,却无法理解文档的逻辑结构、表格关系或跨页内容。
这种 “只见树木不见森林” 的解析方式,直接导致RAG系统检索效率低下、答案准确性不足,甚至因上下文缺失而生成错误信息。
之前也为大家分享了好几款识别效果较不错的开源文档解析工具,但有些小伙伴觉得在部署使用上比较复杂繁琐。
今天为大家推荐一款效果与功能都比较优异的闭源的文档解析引擎:EasyDoc,一个专为LLM预处理设计的智能文档解析引擎,为解决文档解析难题带来了一片曙光。

与传统OCR不同,它通过AI驱动的多模态解析技术,将文档转化为层次化、结构化的JSON数据,包含以下关键信息:
-
• 逻辑结构:标题层级、段落归属、列表项关联。 -
• 复杂元素:表格的行列结构、合并单元格识别、跨页表格自动拼接。 -
• 多模态内容:图表类型识别、图标题提取、图片位置与上下文关联。
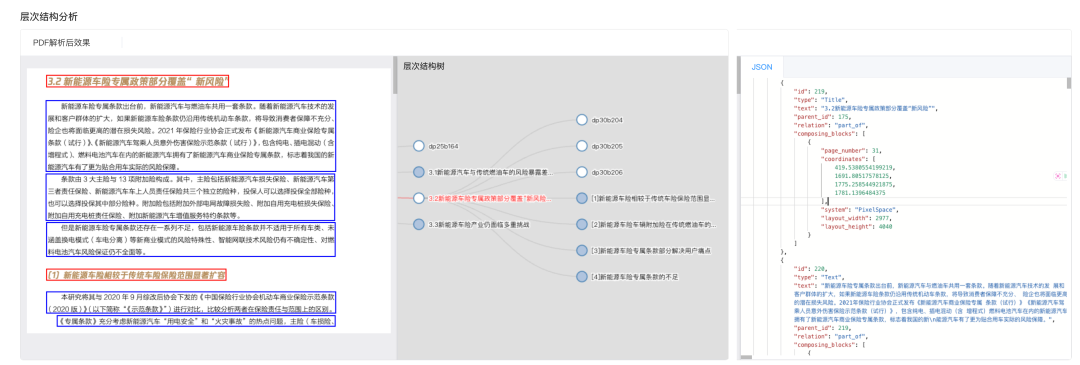
这种结构化输出可直接服务于RAG系统的分块、检索和增强生成环节,成为提升AI应用效果的关键预处理工具。
即使普通用户拿来做文档解析识别也是个不错的选择。
接下来,我将从实战案例、功能特性,全面解析EasyDoc如何重塑文档处理流程。
核心功能案例演示
场景一:跨页表格解析识别
EasyDoc 无论是对简单的单行列数据表格,还是包含合并单元格、跨页的复杂表格,都能准确提取单元格中的文本内容,并正确还原表格的行、列、表头以及合并单元格等结构信息。
在 JSON 解析结果中,表格数据以清晰的层级关系呈现,便于开发者用于数据分析或导入数据库。

这种自动合并数据并跨页表格,可以确保数据完整性。还有表头信息,还有单元格原始坐标信息。
它的一个数据层级中它会有纯文本的展示,也会有基于原数据的Table表格展示,适应多方面的数据要求。
下面是一个官方提供例子,更能展现出来跨页表格解析的强大能力。

场景二:图表与上下文关联
EasyDoc 还有一个强大的功能:多模态视觉思考推理,也是当下主流的AI应用都在做的技术。
它可以精准解析图片、图表的信息,并以文字信息传达出来。
比如当下解析文档有一个教室活动墙图片,采用Premium解析模式,它就会为我们精准解析出这个活动墙所要表达的主旨内容。

并且可以通过父ID关联上下文,保障信息内容间的关联结构。(可能识别的层级嵌套过多,对应会麻烦)

还有就是对柱状图、饼图等图表数据解析也非常清晰且到位,就拿下面的柱状图来说,首先原PDF中的柱状图我已经放大显示了,人眼都还是有点模糊,但EasyDoc还是能够准确地将数值解析出来,而且也会分析当前柱状图数据状态。

当然EasyDoc还有许多细致的功能,比如:明确段落与标题的归属关系,避免RAG检索时出现“断章取义”。

EasyDoc 介绍
EasyDoc 是一款强大的多模态文档处理 API,能够精准解读文本和图表中的层次结构与逻辑关系,将非结构化文档转化为 JSON 格式数据。
为大语言模型(LLM)应用提供全面而丰富的上下文信息,同时为 LLM 的推理与训练提供高质量数据支持。

核心功能
-
• 主流文档格式支持:包括 .doc、.docx、.ppt、.pptx、.txt、.pdf 等。 -
• 提供三种解析模式:提供有Lite、Pro、Premium 三种解析模式,以适配不同复杂度的文档解析需求。 -
• 文档信息智能抽取:支持多模态信息统一提取、跨页信息关联分析、图表数据自动提取、关键信息智能摘要等。 -
• 内容块智能识别:超越传统行文分割,将零散文本转化为LLM可理解的语义知识块。 -
• 层次结构分析:智能识别文档结构,构建文档结构树,为LLM注入结构化的上下文认知。 -
• 图表深度解读:将复杂的表格与图片进行深层次的语义解读,全面提升多模态AI应用效果。
解析模式详解
EasyDoc提供有三种 API 解析模式,适应不同场景需求:
1、Lite模式
可快速提取原始文本,适合简单内容预览或原型验证。
curl --location --request POST 'https://api.easydoc.sh/api/v1/parse' \
--header 'api-key: <your-api-key>' \
--form 'file=@"<your-file-path>"' \
--form 'mode="lite"'2、Pro模式
可保留完整文档层次结构(标题、段落、列表),是构建知识库的性价比之选。
curl --location --request POST 'https://api.easydoc.sh/api/v1/parse' \
--header 'api-key: <your-api-key>' \
--form 'file=@"<your-file-path>"' \
--form 'mode="pro"'3、Premium模式(核心优势)
支持多模态深度解析表格、图表、图片,支持跨页内容合并,专为复杂文档设计。
curl --location --request POST 'https://api.easydoc.sh/api/v1/parse' \
--header 'api-key: <your-api-key>' \
--form 'file=@"<your-file-path>"' \
--form 'mode="premium"'开发者(会API调用的编程小白也可上手)可通过REST API一键调用不同模式,且新用户注册可免费获得10美元额度(相当于5000页Lite解析或2000页Pro解析)及500页Premium体验,大幅降低试错成本。
使用方法
访问EasyDoc官网主页点击“立即体验”进行注册。
官网地址:https://easydoc.sh/zh/
注册完成后会登录到 EasyDoc 后台,然后点击左侧“API Keys”,创建个人API Key,后面接口请求会用到。

方式一:直接使用API请求工具
借助 Postman、ApiPost 等接口请求工具,也可以使用在线的接口请求工具。
文档解析接口:
https://api.easydoc.sh/api/v1/parse
参数:
-
• api-key: EasyDoc的认证参数 -
• file: 上传需要解析的文件(File类型) -
• mode:解析模式(lite/pro/Premium)

接口请求响应会收到一个 task_id,接下来可以使用它来跟踪解析任务的详情。

任务查询接口:
https://api.easydoc.sh/api/v1/parse/{task_id}/result

当你用解析接口请求成功后,也可以直接在 EasyDoc 后台查看解析结果。

方式二:Python调用
使用 Python 封装一个接口调用代码,最后用命令行执行即可。我已经封装好了,希望用此方式的小伙伴可自取。
import requests
import argparse
import time
import sys
def parse_document(api_key, file_path, mode='lite'):
"""调用文档解析接口"""
url = 'https://api.easydoc.sh/api/v1/parse'
headers = {'api-key': api_key}
try:
withopen(file_path, 'rb') as f:
files = {'file': (file_path, f), 'mode': (None, mode)}
response = requests.post(url, headers=headers, files=files)
if response.status_code != 200:
returnNone, f'请求失败,状态码:{response.status_code}'
result = response.json()
ifnot result.get('success'):
returnNone, result.get('error', '未知错误')
task_id = result['data'].get('task_id')
ifnot task_id:
returnNone, '响应中缺少task_id'
return task_id, None
except Exception as e:
returnNone, f'解析失败:{str(e)}'
def get_parse_result(api_key, task_id):
"""轮询获取解析结果"""
url = f'https://api.easydoc.sh/api/v1/parse/{task_id}/result'
headers = {'api-key': api_key}
try:
response = requests.get(url, headers=headers)
if response.status_code != 200:
print(f'结果查询失败,状态码:{response.status_code}')
returnNone
result = response.json()
return result
except Exception as e:
print(f'查询异常:{str(e)}')
returnNone
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='EasyDoc 文档解析工具')
parser.add_argument('--api_key', required=True, help='API访问密钥')
parser.add_argument('--file', required=True, help='待解析文档路径')
parser.add_argument('--mode', default='lite', help='解析模式(默认:lite)')
args = parser.parse_args()
# 第一步:提交解析任务
task_id, error = parse_document(args.api_key, args.file, args.mode)
if error:
print({'error': error})
sys.exit(1)
# 第二步:获取结果
result = get_parse_result(args.api_key, task_id)
if result isNone:
sys.exit(1)
print({'result': result})
# 使用示例:
# python doc_parser.py \
# --api_key your-api-key \
# --file ./demo.pdf \
# --mode lite \写在最后
EasyDoc 的核心价值在于将非结构化文档转化为AI就绪的结构化数据,解决了RAG系统的“数据供给瓶颈”。
虽然它是一个闭源工具,但其能力及其效率是一些同类型开源工具所不具备的。
通过本次体验也可以看到:
-
• 提升检索精度:结构化JSON允许基于语义分块,避免无效文本干扰。 -
• 多模态理解能力:对于图表内容的解析也比较精准明确。 -
• 降低开发成本:开箱即用的API与免费额度,加速原型开发与迭代。
当然,它的使用方式上仅限API调用,对新手小白可能不大友好。可能当数据过量时也会存在内容摘取困难的问题。
但它是一个新型的智能文档解析工具,相信未来也会有更多优化升级的地方,也期待未来会有Web界面版,新增些多样化导出方式(json/md/csv/db等)。
EasyDoc 支持本地私有化部署,可满足企业级文档解析的严苛数据安全需求。若您的企业有相关需求,欢迎扫码加入EasyDoc官方交流群,
EasyDoc团队将与您联系开展商务洽谈,共同探索高效、安全的文档处理解决方案。

参考链接:
-
• 官方主页:https://easydoc.sh/zh -
• API文档:https://github.com/easydoc-ai/easydoc
(文:开源星探)