

今天是2025年4月16日,星期三,北京,晴。
本文先来看老刘关于RAG落地的十条建议,这是这两年来做RAG相关工作得到的一些启发,写出来供大家参考。
另外,RAG有一个发展方向,就是朝向个性化走,刚好也有一个技术总结,我们也来看看。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、真实场景下落地RAG的十条建议
RAG无处不在、无孔不入,却又缝缝补补,且出现了诸如GraphRAG、多模态RAG、Deepresearch等许多变体。RAG的方案人手一份,但是依旧在实际落地过程中出现各类问题。
昨晚,老刘在A2M人工智能创新峰会预热线上分享中进行《**RAG的花式变体及落地建议-GraphRAG or 多模态RAG or Deepresearch?**》主题报告,讲了一些有趣的事情,在结尾的时候,给出了这10条建议,供各位参考:
1、不要为了上RAG而上RAG,尤其是NL2SQL,KBQA这种类型,之前解决的很好的就不要再折腾了。
2、不要为了上变体而上变体,GraphRAG、多模态RAG、DeepResearch等能不上就不要上,把最基本的RAG做出来就好。
3、通用的RAG是一种标品,标品从来都解决不了优化问题,要放弃这种思路。
4、RAG本身就是破布,是面向具体业务问题而做的补丁,要有这种意识,面向业务做RAG,而不是面向RAG做业务,具体case 具体分析,评估先行,可用的RAG一定是有很多路由逻辑的。
5、目前开源的RAG框架有很多,其意义其实并不是为了生产,而是为了快速做场景验证,要做开源框架祛魅
6、能自己动手写就动手写,RAG没多少复杂的东西,开源框架同质化,黑盒化,不利于做问题定位,要适当抛弃;
7、RAG本身就是无处不在的,它是一种框架,而不是一种单独的技术,更多时候还是一种工程架构
8、决定RAG好不好用的,不是RAG技术本身,而在于用户的问题域是否建模清楚,以及业务实现逻辑的设计。
9、落地总是二八原则,很多优化方案都是解决20%的长尾问题而设计的,这个需要我们弄清楚,需要衡量ROI投入产出比;
10、RAG的文档解析要做,但并不需要文档解析做到100%还原,这是一条歧路。应该投入,但不要过度关注。文档解析是手段,不是目的;
二、RAG中如何提升个性化?
RAG有一个发展方向,就是朝向个性化,例如最近的工作《A Survey of Personalization: From RAG to Agent》(https://arxiv.org/pdf/2504.10147)这个技术总结可以看看,介绍了如何在RAG的不同阶段(预检索、检索和生成)以及基于代理的个性化系统中有效地集成个性化信息。
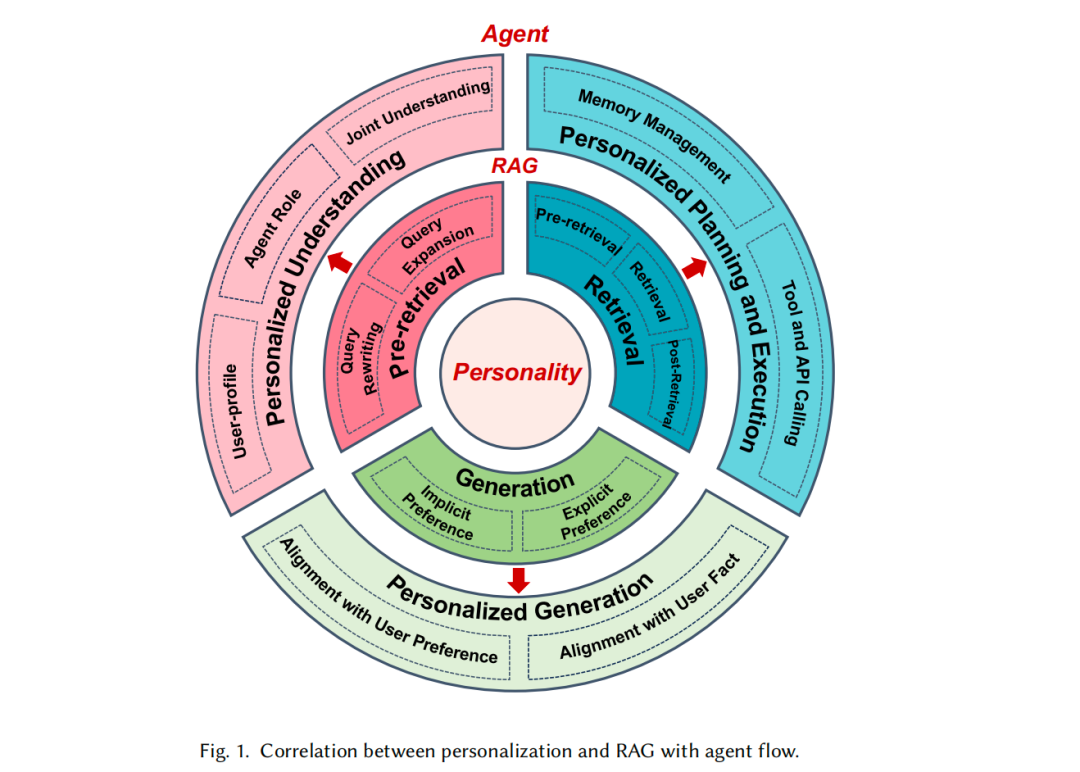
主要用到的技术点在这:
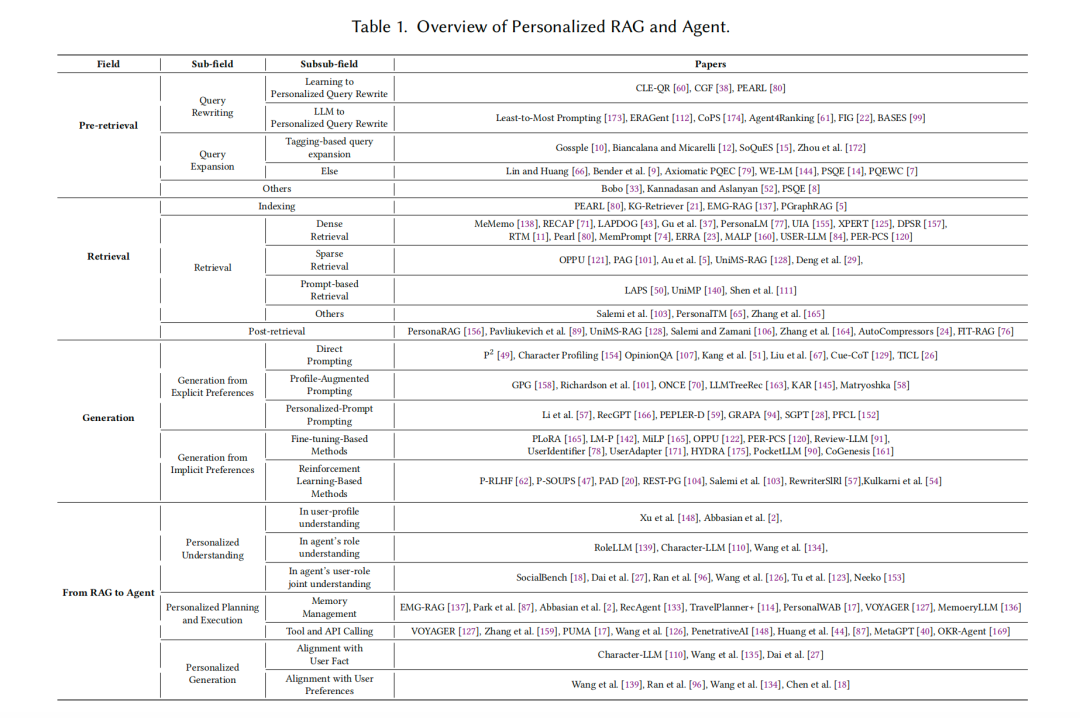
1、预检索阶段的个性化
在预检索阶段,查询处理(Q)使用个性化信息(如查询重写或扩展)来精炼原始查询。
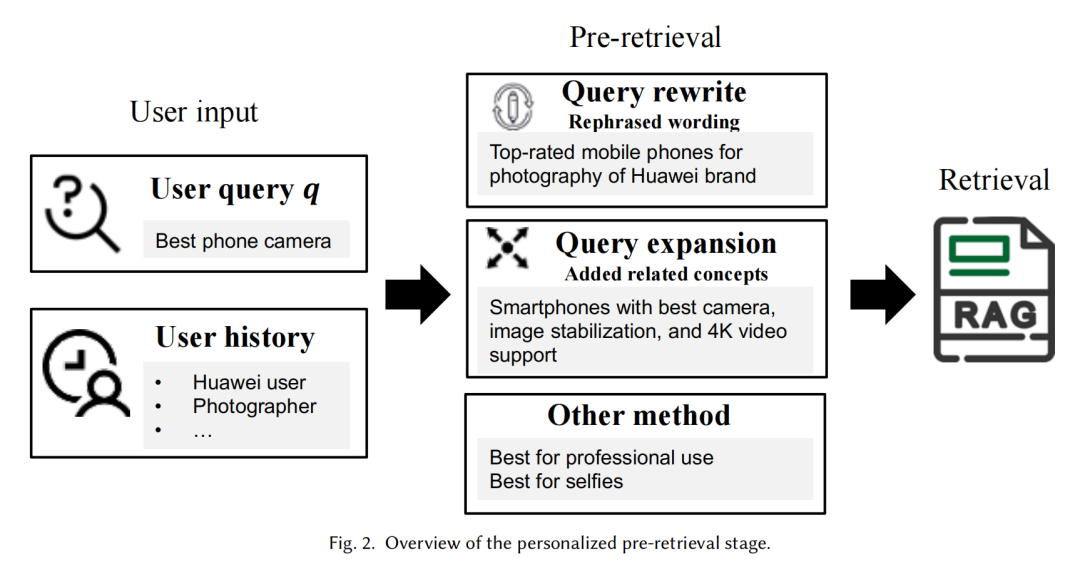
查询重写可以分为直接个性化查询重写和辅助个性化查询重写。直接个性化查询重写使用直接模型。辅助个性化查询重写则使用检索、推理策略和外部记忆。
2、检索阶段的个性化
在检索阶段,检索器(R)利用个性化信息(p)从语料库(C)中获取相关文档。检索过程可以引入索引、检索和后检索三个步骤。
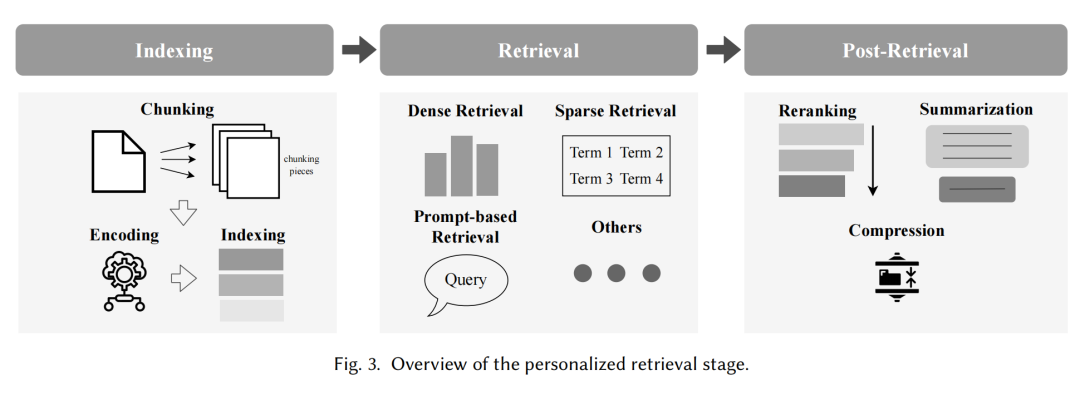
索引阶段可以通过生成用户嵌入来组织知识库数据。检索阶段可以分为密集检索、稀疏检索、提示检索和其他方法。后检索阶段主要通过重排、摘要和压缩来改进检索结果。
3、生成阶段的个性化
在生成阶段,生成器(G)结合检索到的文档、任务特定的提示和用户偏好信息(p)来生成定制化的内容。个性化生成可以通过显式和隐式偏好注入来实现。
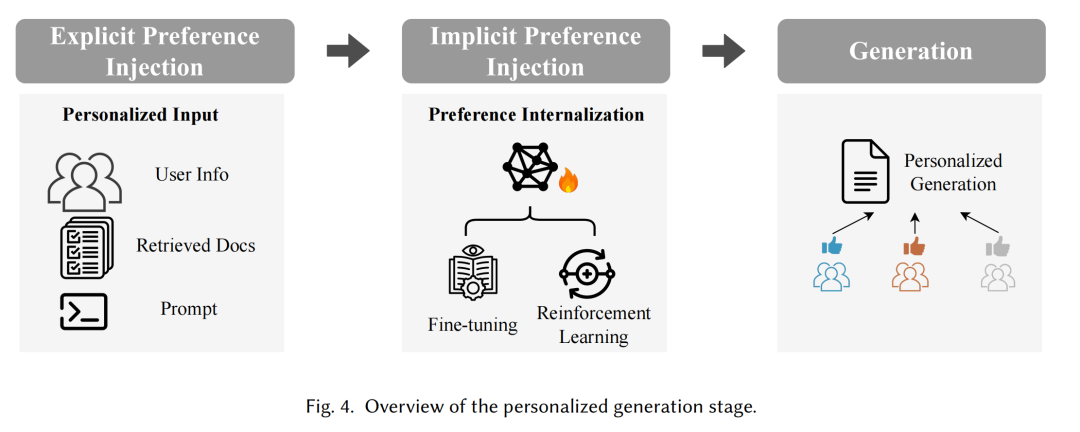
显式偏好注入包括直接集成提示、摘要增强提示和自适应提示。隐式偏好注入则通过参数高效微调和强化学习方法来实现。
4、从RAG到代理的个性化
个性化LLM代理系统动态地结合用户上下文、记忆和外部工具或API,以支持高度个性化和目标导向的交互。个性化理解、个性化规划和执行以及个性化生成是代理系统的关键组成部分。
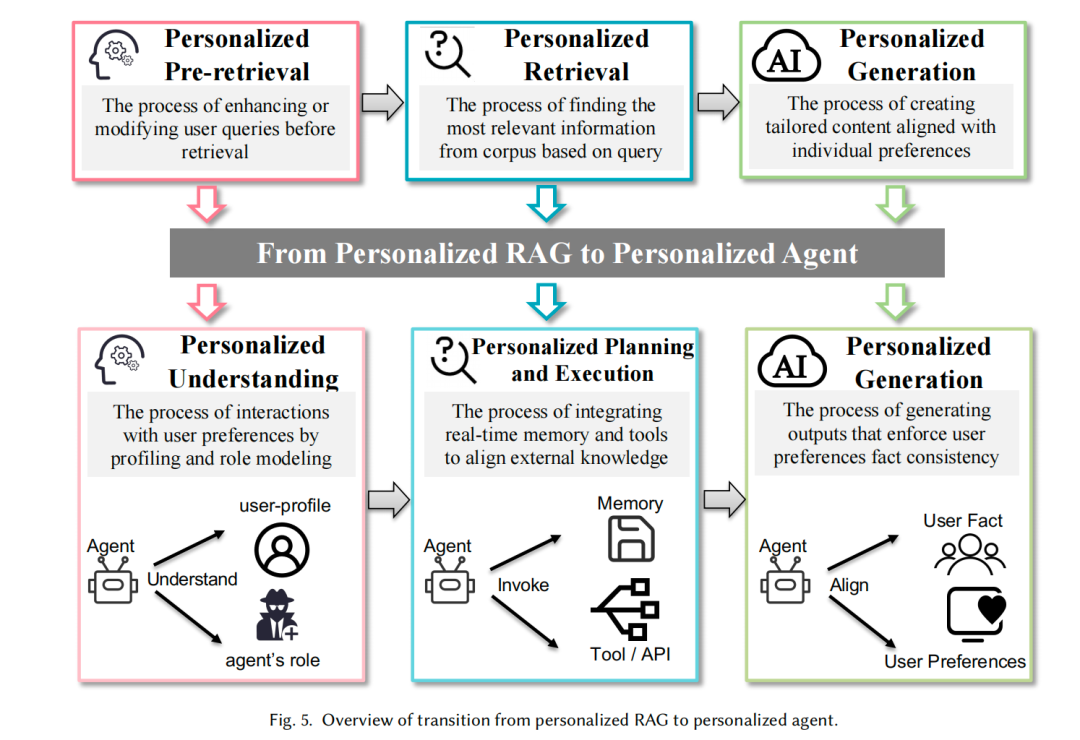
个性化理解包括用户档案理解、角色理解和用户-角色联合理解。个性化规划和执行包括记忆管理和工具和API调用。个性化生成则强调与用户事实和偏好的对齐。
参考文献
1、https://arxiv.org/pdf/2504.10147
(文:老刘说NLP)