


极市导读
一种新型的实时交互式 3D 场景生成方法WonderTurbo,能够在 0.72 秒内生成高质量的 3D 场景,建模速度相比传统方法提升了 15 倍。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

文章链接:https://arxiv.org/pdf/2504.02261
项目链接:https://wonderturbo.github.io/

亮点直击
提出了 WonderTurbo,首个实时(推理耗时:0.72 秒)的 3D 场景生成方法,支持用户交互式创建多样化且连贯连接的场景。 在几何效率优化方面,提出的 StepSplat 将前馈范式(feed-forward paradigm)扩展至交互式 3D 几何表示,可在 0.26 秒 内加速 3D 场景扩展。此外,引入 QuickDepth 以确保视角变化时的深度一致性。在外观建模效率方面,提出 FastPaint,仅需 2 步推理 即可完成图像修复。 通过全面实验验证,WonderTurbo 在实现 15 倍加速 的同时,在几何与外观方面均优于其他方法,可生成高质量的 3D 场景。
总结速览
解决的问题
-
实时交互性不足:现有3D生成技术(如WonderWorld)更新单视角需近10秒,无法满足实时交互需求。 -
几何建模效率低:传统3D Gaussian Splattings(3DGS)等方法依赖迭代训练更新几何表示,耗时较长。 -
外观建模速度慢:基于扩散模型的图像修复方法需要大量推理步骤,计算开销大。 -
小视角局限性:现有单图像新视角生成方法仅支持小幅视角变化,难以适应动态交互需求。
提出的方案
-
StepSplat:动态更新高效3D几何表示,单次更新仅需0.26秒,支持交互式几何建模。 -
QuickDepth:轻量级深度补全模块,为StepSplat提供一致深度先验,提升几何准确性。 -
FastPaint:两步扩散模型,专为实时外观修复设计,保持空间一致性,显著减少推理步骤。
应用的技术
-
几何建模:
-
基于前馈式推理(feed-forward)的3D Gaussian Splattings(3DGS)加速,避免迭代训练。 -
特征记忆模块动态构建cost volume,适应视角变化。 -
深度优化:轻量级深度补全网络(QuickDepth)提供稳定深度输入。
-
外观建模:高效扩散模型(FastPaint)仅需2步推理完成修复,兼顾质量与速度。
达到的效果
-
速度突破:
-
单视角生成仅需0.72秒,较基线方法(如WonderWorld)加速15倍。 -
StepSplat几何更新仅0.26秒,FastPaint外观修复仅需2步推理。 -
质量与一致性:
-
在CLIP指标和用户评测中领先,保持高空间一致性和输出质量。 -
支持大幅视角变化(如全景相机路径和行走路径)。 -
应用场景:适用于实时3D内容创作、虚拟现实(VR)和交互式设计等场景。
效果展示
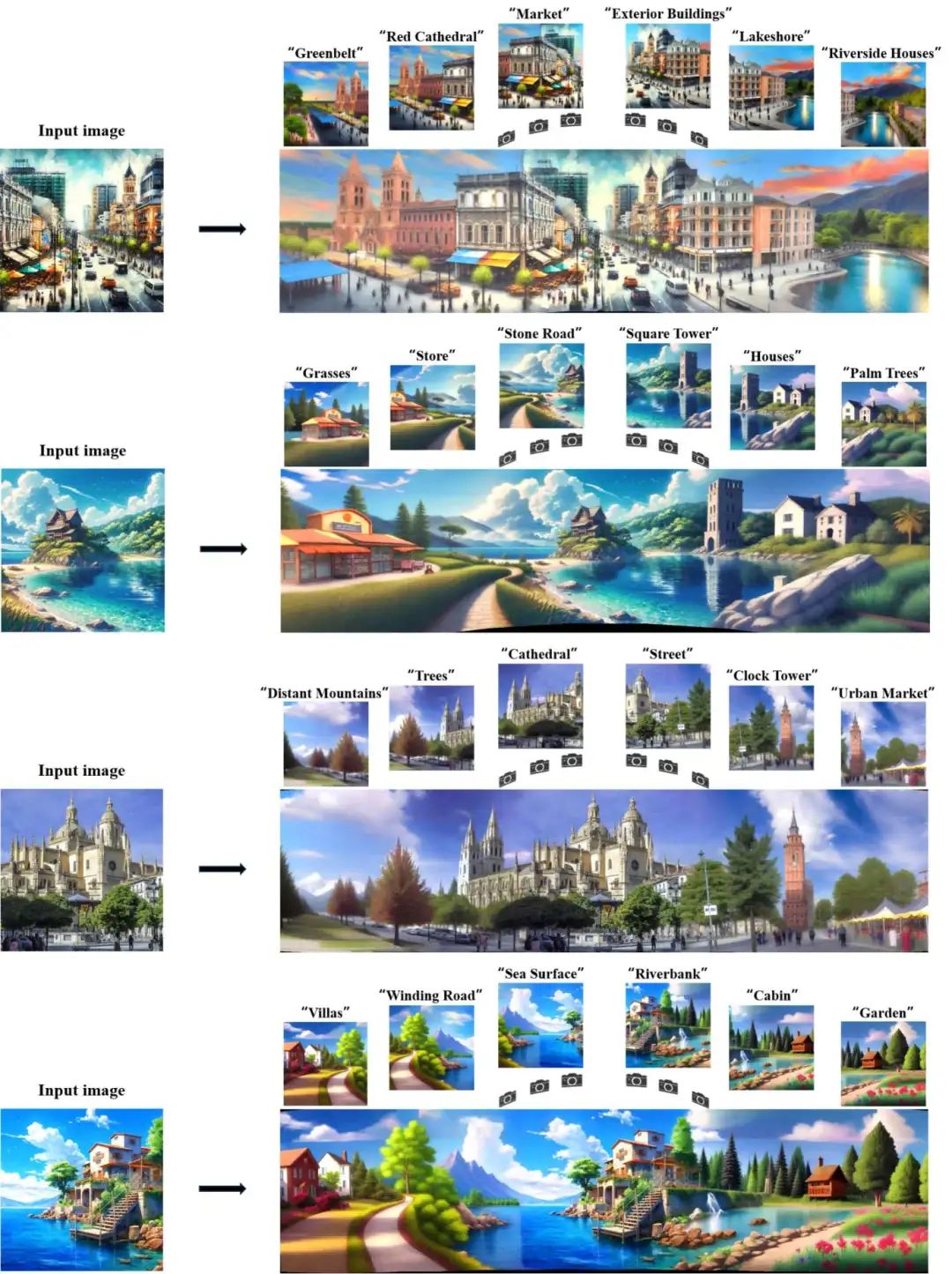

方法
WonderTurbo 的整体框架
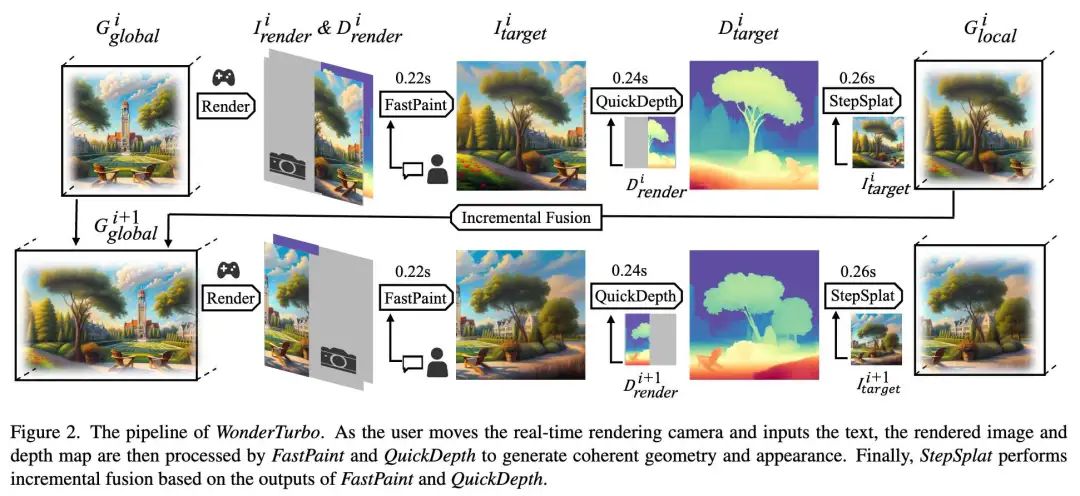
交互式 3D 场景生成受限于计算效率,主要由于几何与外观建模的耗时问题。WonderWorld 提出了 FLAGS 以加速几何建模,但仍需数百次迭代优化几何表示,且其外观建模依赖预训练扩散模型,需数十步推理完成修复。相比之下,WonderTurbo 通过同时加速几何与外观建模,实现实时交互式 3D 场景生成。具体而言,提出 StepSplat 加速几何建模,可在 0.26 秒 内直接推断 3DGS;在此框架下,QuickDepth 在 0.24 秒 内补全缺失深度信息;针对外观建模加速,引入 FastPaint,仅需 0.22 秒 完成图像修复。
下图 2 展示了 WonderTurbo 的流程。在第 次迭代时,给定用户指定位置,FastPaint 基于当前 3D 场景的渲染图像 和用户提供的文本描述,生成新场景外观 度图 和新生成的外观 生成深度图 ,确保新生成场景的几何结构与现有 3D 场景对齐。最后,StepSplat 以深度图 和新场景外观 为输入,将局部几何 增量融合至全局表示 。下文将详细阐述 StepSplat,QuickDepth 和 FastPaint。
StepSplat
为加速几何建模,本文提出 StepSplat。如下图 3 所示,StepSplat 以位姿 ,图像 及 QuickDepth 提供的对应深度 为输入,首先通过主干网络提取匹配特征 和图像特征 ;随后查询特征记忆模块中邻近视角的匹配特征以构建成本体积(cost volume)。成本体积与 拼接后预测高斯参数。同时,利用 QuickDepth 提供的稳定深度作为几何先验构建成本体积,确保高斯中心点的准确性。最终,通过增量融合策略将当前视角生成的局部几何 合并至全局几何 ,实现连续一致的 3D 表示。
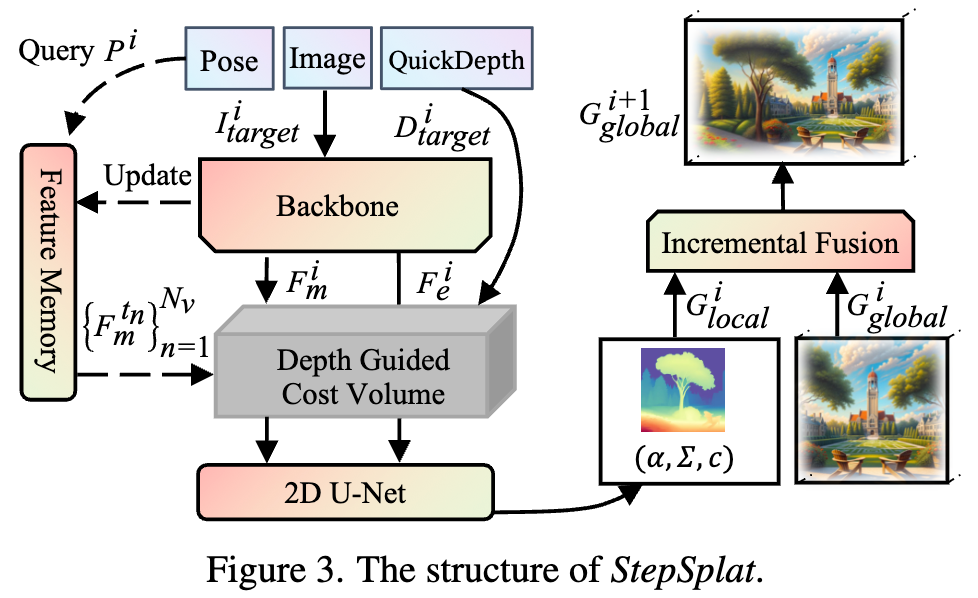
特征记忆模块
本文引入特征记忆模块存储历史视角的匹配特征,用于构建后续成本体积。给定输入图像 和位姿 ,首先通过主干网络提取图像特征 和匹配特征 ,随后将元组 更新至特征记忆模块。为加速推理,采用 RepVGG 作为主干网络。
深度引导的成本体积构建
针对当前视角的成本体积构建,自适应地从特征记忆模块中选择 个邻近视角,并利用 QuickDepth提供的输入深度作为成本体积的深度候选。具体实现时,首先计算当前位姿 与特征记忆模块中所有历史位姿 的距离。
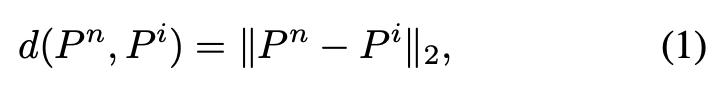
其中 表示 L2 范数。根据这些距离,选择 个最接近当前位姿的位姿,并从记忆模块中提取其对应的匹配特征 ,其中每个 对应 个最近位姿之一。
为确保 3D 表示的一致性,受多视图立体匹配(Multi-View Stereo)的启发,本文利用 指导成本体积的构建。从范围 中均匀采样 个深度候选 ,其计算公式为:
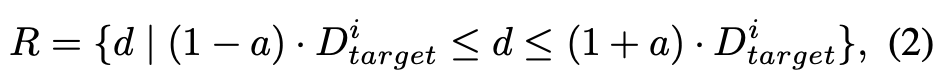
其中 是用于调整深度候选范围的偏移值。然后,使用平面扫描立体算法(plane-sweep stereo)将每个邻近视图的匹配特征 变换到当前视图的候选深度平面 上,特征变换公式表示为:
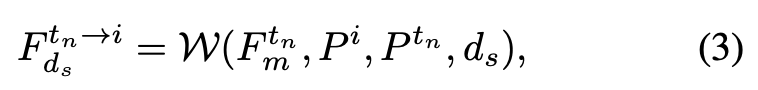
其中 表示可微分的warping操作。随后计算当前视角特征 与每个warped邻近特征 的归一化点积相关性,并对所有邻近视图的相关性图取平均:
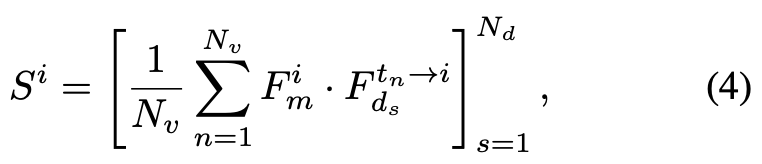
其中 表示候选深度数量,各深度的相关性图被堆叠形成成本体积 。同时,采用额外的2D U-Net进一步精炼和上采样成本体积。对成本体积 进行归一化后,通过对所有深度候选进行加权平均得到预测深度图 :

在获得深度预测后,深度值被反投影作为3D高斯分布(3DGS)的中心点。随后对成本体积和图像特征进行解码以获取其他高斯参数,方法与MVSplat类似。
增量融合
为减少高斯分布的冗余,通过深度约束将局部几何 更新至全局几何 。具体而言,给定具有二维坐标 和深度 的 ,我们使用相机投影矩阵 将全局几何 中的所有高斯分布 投影至当前像素坐标系:
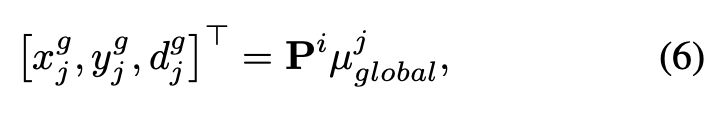
然后通过以下方式构建投影到相同离散像素位置的全局高斯候选集:
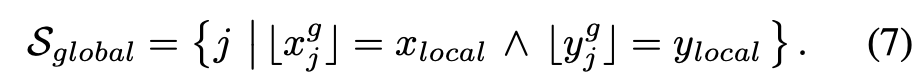
为保持几何连续性,从 中剔除违反深度一致性约束的冲突高斯分布。待剪枝的高斯分布定义为集合 中的元素:
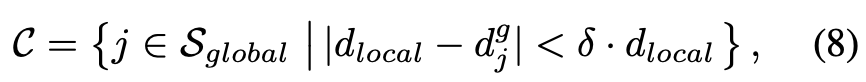
其中 控制深度容差。随后通过选择性地将有效局部高斯(即未包含在 中的高斯)合并到现有全局模型中来完成全局模型更新,如以下公式所示:
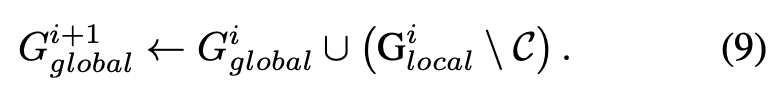
StepSplat的训练
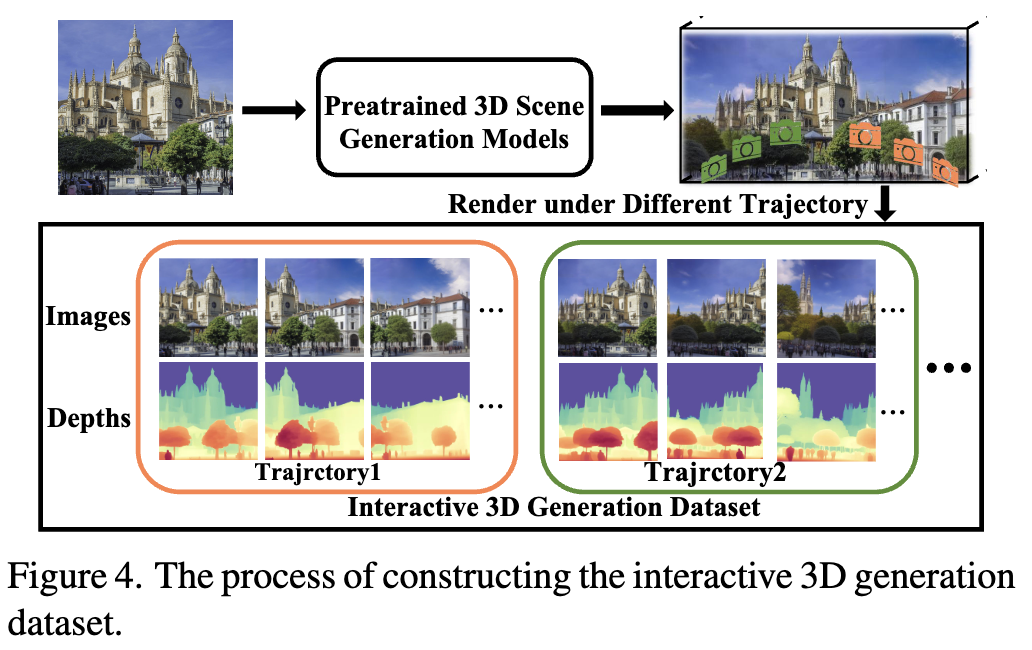
传统前馈式3DGS方法难以满足交互式3D场景生成的需求,部分原因是数据集的多样性有限(主要集中在自动驾驶或室内环境等特定场景),且这些数据集的视角变化与交互式3D场景生成的要求存在显著差距。本文利用3D生成模型创建包含模拟视角变化的数据集来训练StepSplat。训练时随机选取图像序列逐帧输入模型,生成全局高斯表示,并基于该表示渲染新视角图像,以RGB图像作为监督信号。
QuickDepth
现有深度补全方法虽取得显著进展,但主要针对稀疏深度补全任务,难以处理完全缺失深度信息的区域(交互式3D场景生成的关键需求)。WonderWorld提出免训练的引导深度扩散方法,但单张深度图需3秒以上;Invisible Stitch因缺乏真实数据而采用教师蒸馏与自训练策略,但训练数据有限导致部分场景性能下降。本文提出QuickDepth——基于自建数据集训练的轻量级深度补全模型,具有强泛化能力,可适应多样化场景。
为适配交互式3D场景生成,本文构建包含室内外环境、漫画与艺术作品等多样化场景的数据集。不同于使用随机掩码或投影模拟交互场景的掩码,本文设计了更符合交互需求的相机轨迹:
1.设计相机位姿 ,从数据集获取帧序列 及其对应深度图
2.利用相邻帧几何关系:将前一帧深度图 通过相对位姿 投影至当前帧 坐标系,生成不完整深度图 与二值有效掩码 (无效像素标识需补全区域)
训练时,输入构造方式为:
-
完全掩码目标帧真实深度 -
或选择经变换的深度-掩码对
QuickDepth以轻量预训练深度估计模型初始化,输入目标帧RGB图像、不完整深度图与二值掩码,通过损失监督预测深度与真实深度的差异。
FastPaint
在3D场景生成中,图像修复技术对3D外观建模至关重要。现有方法存在以下局限:
-
空间定位不足:如Pano2Room可从单输入生成全景图像,但难以在用户指定位置生成内容
-
效率瓶颈:WonderJourney和WonderWorld采用基于Stable Diffusion的微调修复模型,但存在:
-
微调时的修复区域与3D场景生成需求不匹配,需额外模型验证生成内容 -
扩散模型需多步推理(通常20+步)
本文提出FastPaint解决方案:
-
推理加速:通过知识蒸馏结合ODE轨迹保持与重构技术,将推理步骤压缩至2步
-
领域适配:构建专用训练数据集,其特点包括:
-
相机位姿模拟交互式3D生成过程 -
通过深度图投影获取掩码(与StepSplat/QuickDepth共享轨迹生成逻辑) -
确保修复区域与实际应用场景对齐
交互式3D生成数据集
单张图像的交互式3D生成支持多样化风格图像作为输入,但现实数据往往局限于自动驾驶或室内环境等特定场景。这种局限性导致当前3D生成方法泛化能力不足。同时,部分方法直接采用预训练模型构建流程,这些模型可能并非专为交互式3D场景生成设计,因此需要借助视觉语言模型(VLM)来验证生成内容是否符合场景风格或文本要求。
为突破这一限制,本文基于现有3D场景生成方法构建数据集,并利用该数据集训练所有模块。采用多种3D场景生成方法来创建各方法擅长的3D场景,同时使用VLM模型验证生成数据是否符合预设场景。最终数据集包含通过模拟交互轨迹渲染的600多万帧画面,涵盖旋转路径、线性移动和混合轨迹三种运动模式,主要包含四大类场景:室内环境(32%)、城市景观(28%)、自然地形(25%)和风格化艺术场景(15%)。
训练StepSplat时,对相邻输入帧的间距施加约束,避免使用间隔过近的帧,从而更好地契合3D交互生成的实际应用需求。对于FastPaint和QuickDepth模块,则利用相邻帧的深度信息通过投影获取对应掩膜。
实验
本节将介绍实验设置(包括实现细节和评估指标),随后通过定量与定性结果证明WonderTurbo在性能和效率上的优越性,最后通过消融实验验证各模块的有效性。
实验设置
基线方法:在对比分析中,本文选取了具有代表性的离线与在线3D生成方法。离线方法包括通过多视角图像生成3D场景的LucidDreamer和Text2Room,以及直接生成全景图再提升至3D的Pano2Room和DreamScene360。在线方法则评估了WonderJourney和WonderWorld。所有对比均采用各方法的官方代码实现。
评估指标:遵循WonderWorld的设定,本文采用CLIP分数(CS)、CLIP一致性(CC)、CLIP-IQA+(CIQA)、Q-Align和CLIP美学分数(CA)作为评估指标,并辅以用户研究收集视觉质量的主观反馈(详见补充材料)。
实现细节:为确保全面评估,本文使用LucidDreamer、WonderJourney和WonderWorld的输入图像,针对4组测试案例各生成8个场景(总计32个场景)。评估采用固定全景相机视角,并以相同视域内场景生成时间作为效率对比指标。
主要结果
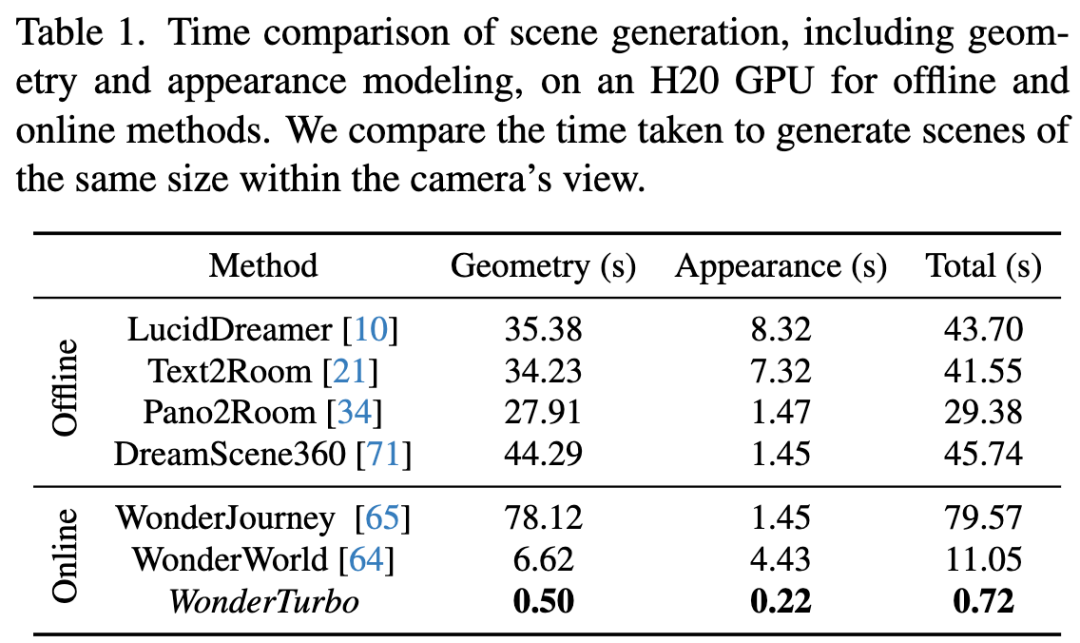
生成速度:交互式3D生成的时间成本至关重要。如下表1所示,即便采用FLAGS加速,对比方法中最快的WonderWorld仍需超过10秒生成场景。LucidDreamer和Text2Room需为每个新场景生成多视角,显著增加了外观建模时间;而Pano2Room和DreamScene360虽无需多视角生成,但全景图生成延迟和逐场景优化需求严重制约效率。值得注意的是,WonderTurbo在几何与外观建模上均表现优异,总体加速达15倍。
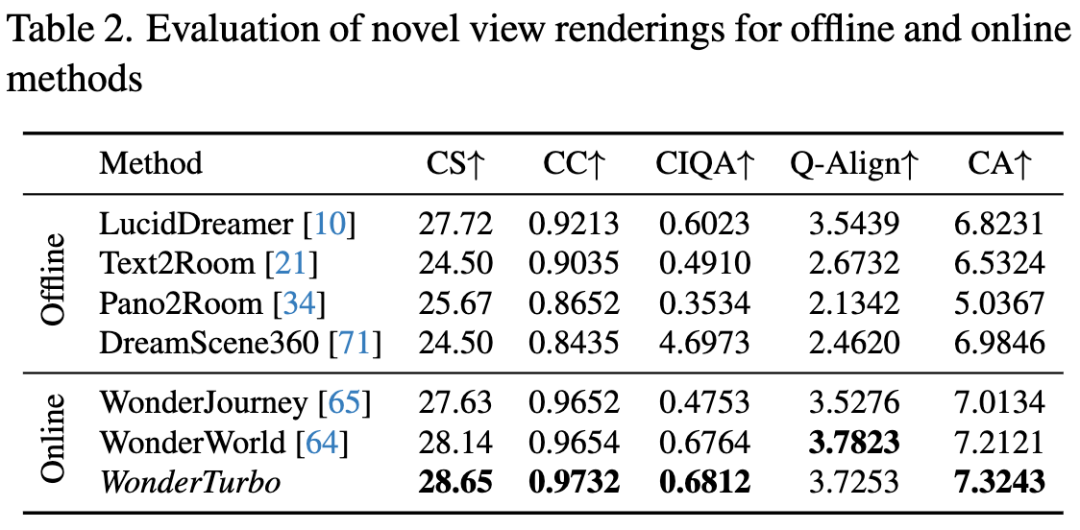
定量结果:下表2对比了WonderTurbo与多种3D生成方法。实验表明,在线生成方法因更贴合用户文本需求,其CLIP分数和一致性优于离线方法。WonderWorld在所有基线中领先,而WonderTurbo在加速15倍的同时仍保持与之相当的指标性能。此外,由于针对交互任务微调,WonderTurbo在CLIP分数、一致性、CLIP-IQA+和美学分数上均有提升。
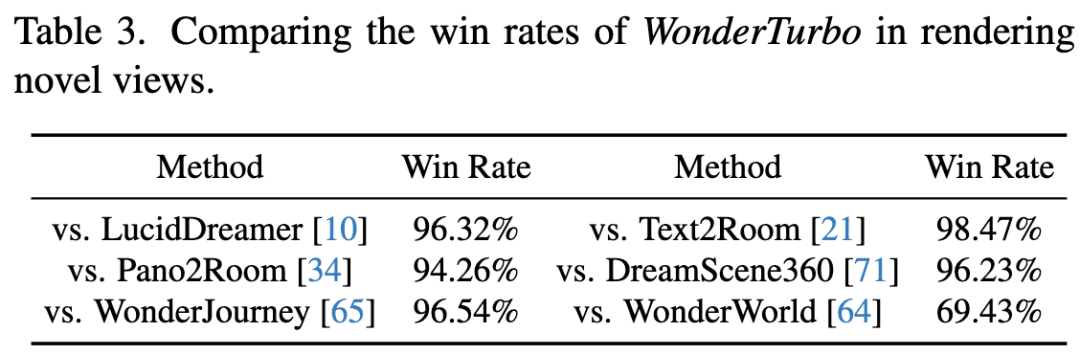
用户研究:下表3,用户研究表明WonderTurbo在生成时间更低的情况下达到与WonderWorld相当的生成质量,并在用户偏好度上显著优于其他方法。
定性结果:下图5展示了相同设置下WonderTurbo与基线方法的生成效果对比。可见WonderTurbo在显著缩短生成时间的同时保持了竞争力:DreamScene360和Pano2Room因泛化能力有限出现几何失真且美学表现不足;LucidDreamer和Text2Room则存在内容错位与提示细节缺失问题;而WonderTurbo与WonderWorld的结果质量接近,均展现出优异性能。

消融实验
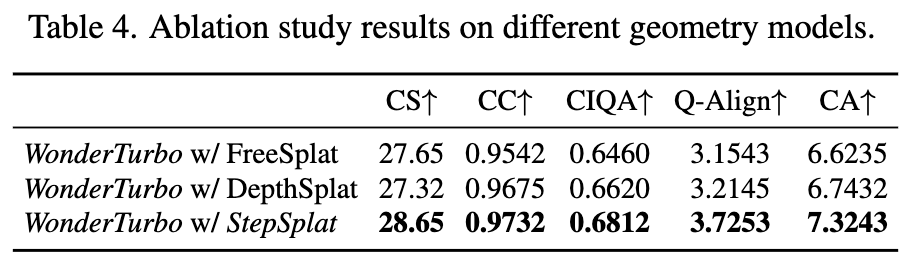
几何建模:本文对比了FreeSplat、DepthSplat等几何建模方法(均采用相同微调设置以确保公平)。如下表4所示,依赖无监督深度估计的FreeSplat和DepthSplat在Q-Align和CLIP美学分数上显著劣于StepSplat。而StepSplat通过一致性深度图指导代价体积构建,实现了自适应交互式3D场景生成。
StepSplat分析:针对深度引导代价体积(depth guided cost volume)与渐进融合(incremental infusion)的消融实验如下表5所示。结果表明:深度引导代价体积是精确几何建模与图像质量的关键;渐进融合则通过减少冗余高斯分布和避免浮点问题提升性能。
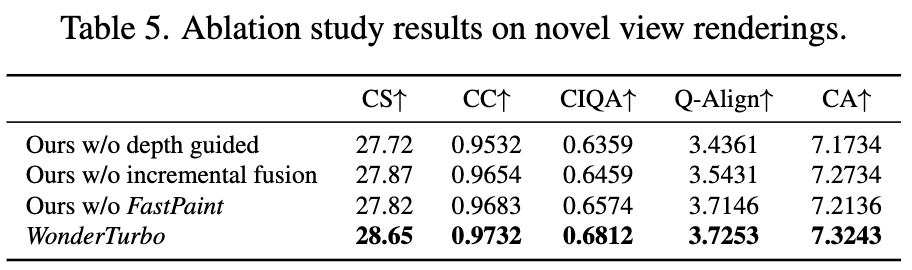
FastPaint验证:与预训练修复模型的对比显示,FastPaint显著增强了3D外观建模能力,各项指标均有提升。
讨论与结论
尽管单图像3D场景生成取得进展,但耗时的几何优化与视角细化仍制约效率。为此,提出实时交互框架WonderTurbo:
-
几何加速:StepSplat可在0.26秒内扩展3D场景并保持高视觉质量,QuickDepth为代价体积构建提供一致性深度先验 -
外观建模:FastPaint仅需2步推理即可完成空间一致的外观建模
实验表明,WonderTurbo能精准实现文本到3D的生成,在CLIP指标和用户偏好率上均优于基线方法,同时获得15倍加速。
参考文献
[1] WonderTurbo: Generating Interactive 3D World in 0.72 Seconds

(文:极市干货)