

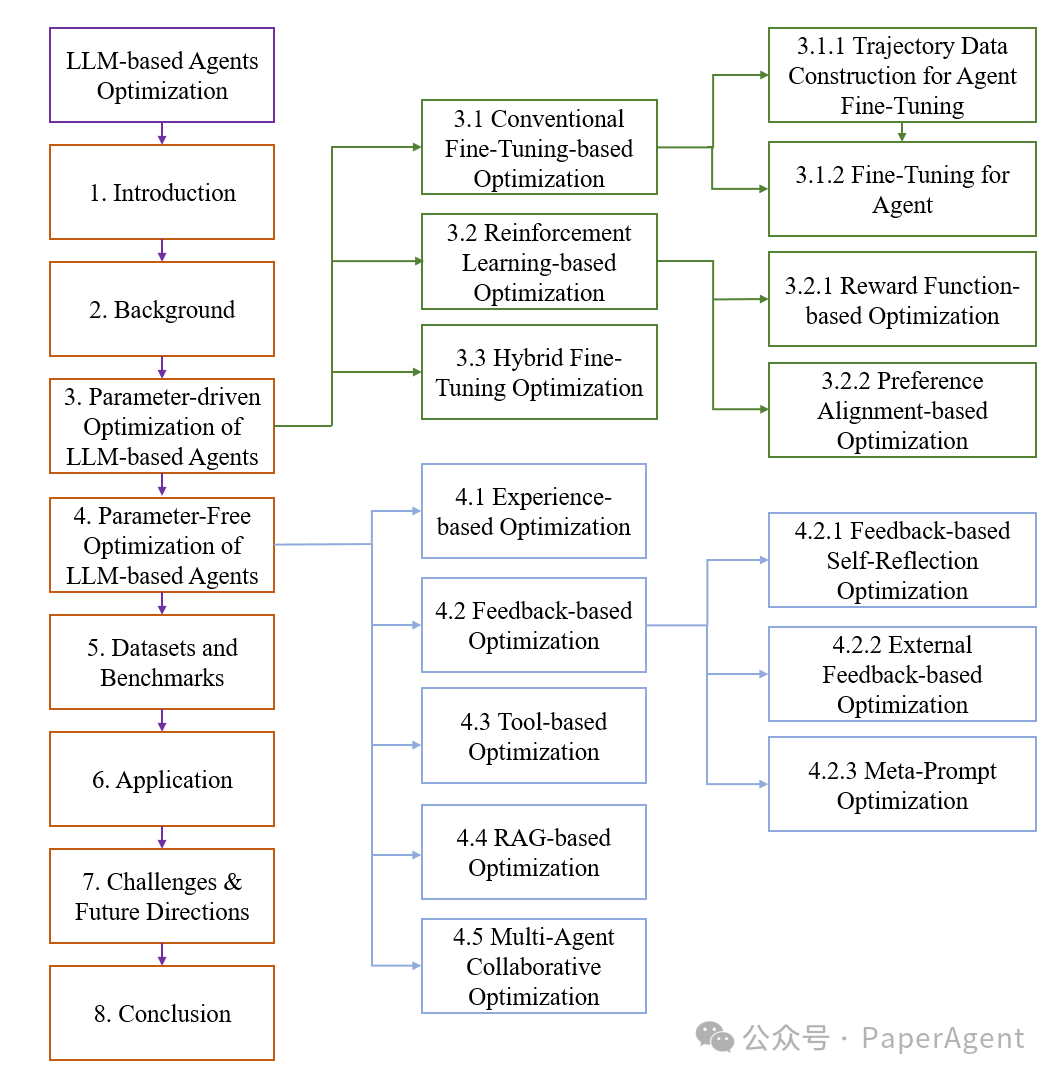
详细探讨了基于参数驱动的优化方法,这些方法通过调整大型语言模型(LLM)的参数来提升其作为智能体(agent)的性能。参数驱动的优化方法主要分为三类:传统的基于微调(fine-tuning)的优化、基于强化学习(reinforcement learning, RL)的优化,以及混合优化策略:
-
传统微调优化
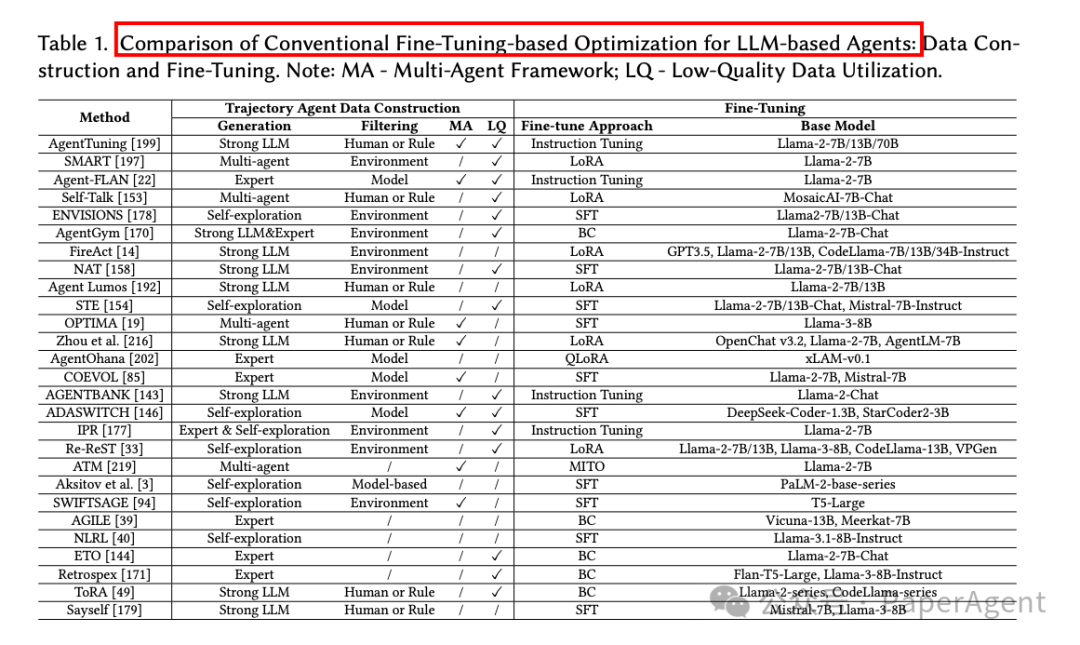
传统的微调方法通过调整预训练的LLM参数来适应特定任务,主要涉及以下步骤:
-
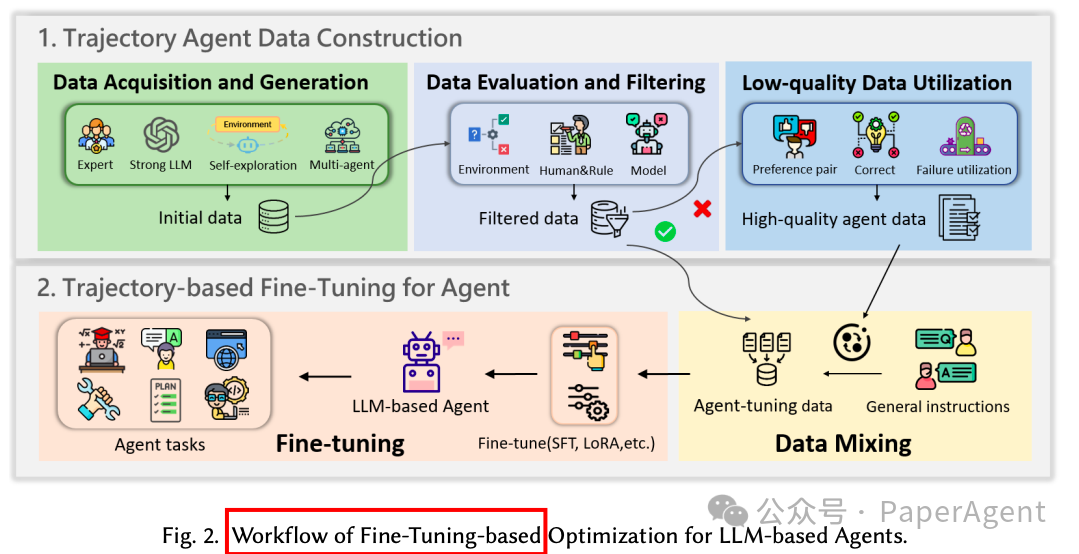
轨迹数据构建(Trajectory Data Construction):这是微调前的关键步骤,目的是生成与目标任务对齐的高质量轨迹数据。数据获取和生成方法包括专家标注数据、强大的LLM生成轨迹、自我探索环境交互轨迹和多智能体协作构建。每种方法都有其优势和局限性,例如专家标注数据质量高但成本高,而自我探索方法成本低但可能产生低质量轨迹。
-
基于轨迹的微调(Trajectory-based Fine-Tuning):微调过程通常结合一般指令数据和特定任务的轨迹数据,以确保模型在保留基础语言能力的同时,优化特定任务的性能。微调技术包括标准的监督式微调(SFT)、参数高效微调(如LoRA)和针对特定任务定制的微调策略。
-
基于强化学习的优化
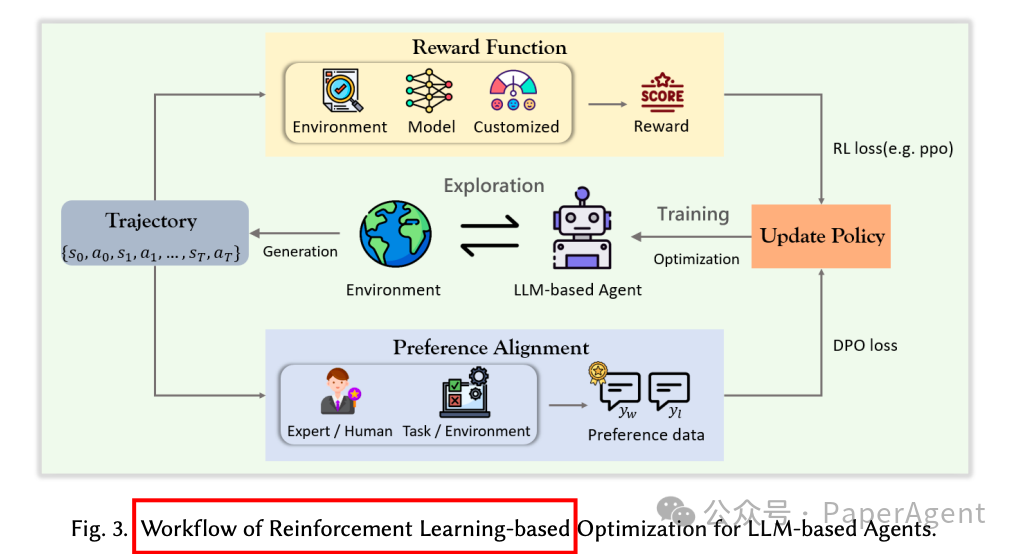
强化学习方法通过与环境的交互来优化LLM智能体的行为,主要分为基于奖励函数的优化和基于偏好对齐的优化:
-
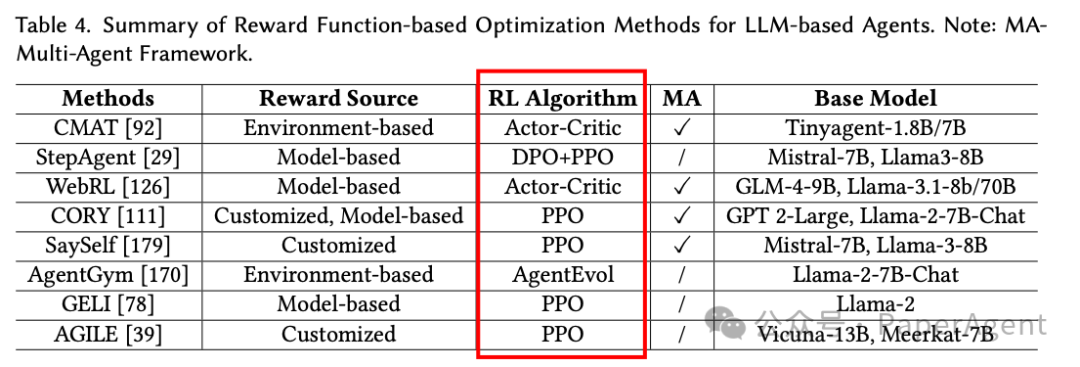
基于奖励函数的优化(Reward Function-based Optimization):利用明确的奖励信号来指导LLM智能体的行为优化。这些方法通常使用传统的强化学习算法,如PPO或Actor-Critic,通过环境反馈、模型生成的信号或自定义奖励函数来调整LLM的参数。例如,CMAT使用多智能体协作和Actor-Critic框架,而StepAgent结合了逆强化学习(IRL)和DPO+PPO来优化智能体行为。
-
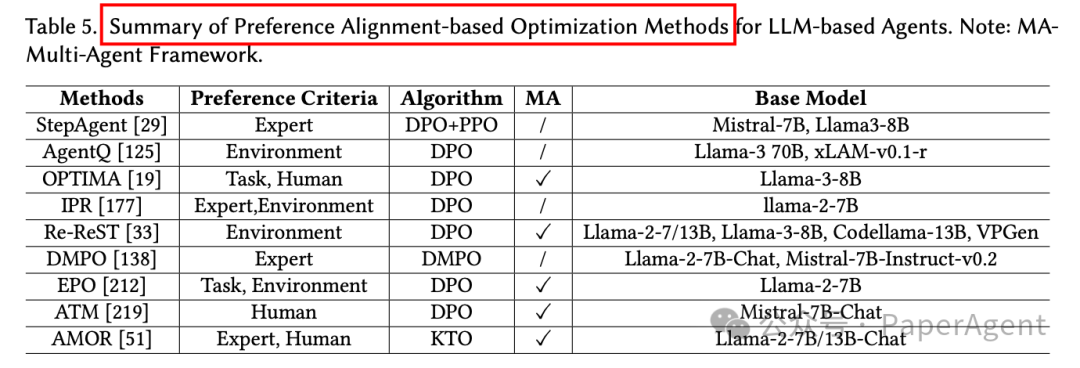
基于偏好对齐的优化(Preference Alignment-based Optimization):这种方法不依赖于明确的奖励信号,而是通过偏好数据来优化智能体的行为,使其更符合人类偏好或特定任务目标。DPO是一种常用的技术,它通过比较偏好对来直接优化策略,而无需建模奖励函数。例如,DMPO通过替换策略约束为状态-动作占用度量(SAOM)约束来优化RL目标,而IPR使用DPO来优化智能体在每一步的行为。
-
混合微调优化
混合微调策略结合了监督式微调和强化学习的优势,以克服单一方法的局限性。这些方法通常先通过监督式微调初始化智能体,然后使用强化学习进一步优化其策略。例如,ReFT、AgentGym和ETO等方法在监督式微调阶段使用高质量的专家轨迹数据进行初始化,然后在强化学习阶段使用PPO或DPO来优化智能体的行为。此外,一些方法采用迭代方法,交替进行监督式微调和强化学习阶段,以持续优化智能体的性能。
探讨了参数无关优化方法,通过调整输入、上下文或任务交互,而不是修改模型参数,来优化基于LLM的智能体行为。

-
基于经验的优化
基于经验的优化方法利用历史数据、轨迹或累积知识来改进LLM智能体。通过存储和分析成功与失败的经验,智能体能够提炼出有用的见解,从而优化策略、增强长期决策能力,并适应不断变化的任务。例如:
-
Optimus-1:利用多模态记忆模块,将探索轨迹转换为层次化的知识图谱,辅助智能体的任务规划和提示生成。
-
Agent Hospital:整合医疗记录库和经验库,根据成功和失败案例优化决策。
-
ExpeL:自动收集训练任务中的知识,并在推理时回忆这些知识。
-
基于反馈的优化
基于反馈的优化方法通过利用反馈进行自我反思、纠正和迭代改进来增强LLM智能体。这些方法分为三类:
-
自我反思优化(Self-Reflection Optimization):智能体利用环境或自身评估的反馈来识别改进领域,并通过自我纠正和进化来调整行为。例如:
-
Reflexion:将任务结果或启发式评估转换为文本修正,集成到决策中。
-
SAGE:检查器代理提供迭代反馈,助手代理生成自我反思。
-
外部反馈优化(External Feedback Optimization):利用外部模型、代理或框架的评估信号来优化行为。例如:
-
Retroformer:使用回顾模型分析失败并提供改进反馈。
-
COPPER:使用共享反思模块生成反事实反馈。
-
元提示优化(Meta-Prompt Optimization):通过迭代调整全局指令或元提示来增强智能体的泛化能力。例如:
-
MetaReflection:从失败试验中提取信息,创建优化的提示。
-
OPRO:通过分析任务准确性生成改进的指令。
-
基于工具的优化
LLM智能体能够利用外部工具(如计算器、搜索引擎、代码解释器等)来增强其解决问题的能力。优化工具使用和选择策略是提升智能体性能的关键。例如:
-
TPTU:优化任务分解和工具调用。
-
AVATAR:通过比较样本对的性能差异,分析工具使用问题。
-
Middleware:引入错误反馈机制,对齐工具输入输出。
-
基于RAG的优化
检索增强生成(RAG)通过动态整合外部知识,克服了预训练知识的局限性,提升了智能体在知识密集型任务中的表现。例如:
-
AutoRAG:自动化选择RAG模块,评估不同的检索技术和重排策略。
-
Self-RAG:结合检索与自我反思,智能体通过迭代反馈自适应地优化内容。
-
RaDA:利用过去的经验和动态检索分解任务,生成情境化的行动。
-
多智能体协作优化
多智能体框架通过分配角色和迭代互动来处理复杂任务,提升决策能力。例如:
-
MetaGPT:通过多智能体协作模拟软件开发流程。
-
ChatDev:分解任务为模块化阶段,通过角色协作优化软件开发。
-
DyLAN:动态构建智能体网络,优化团队协作。
-
Agentverse:提供多智能体协作和探索新兴行为的平台。
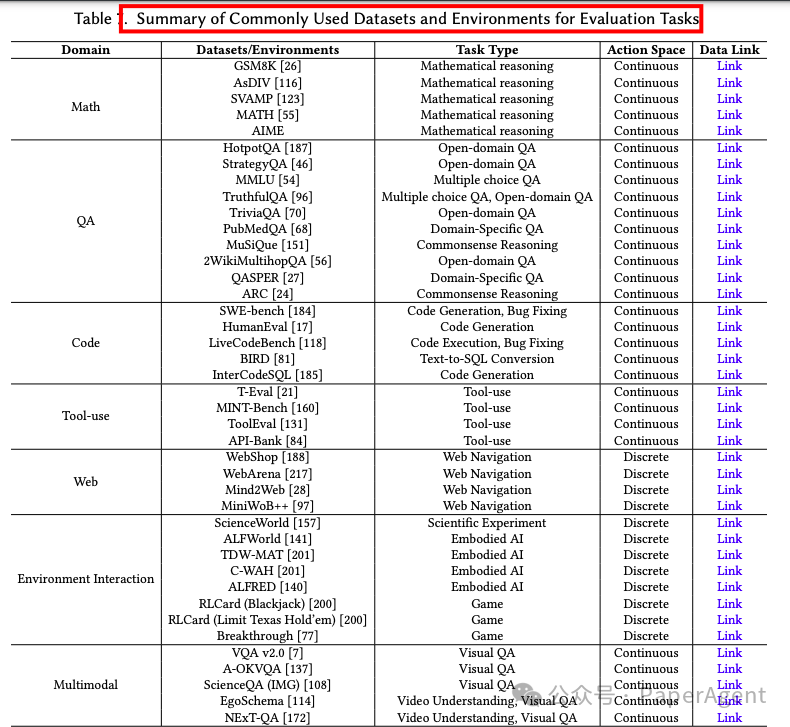
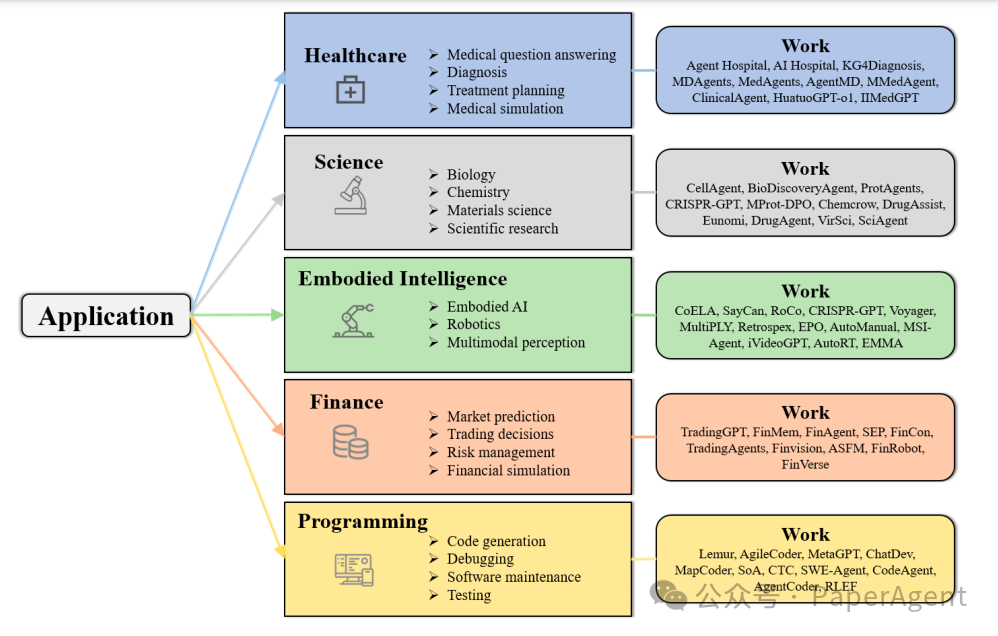

https://arxiv.org/pdf/2503.12434A Survey on the Optimization of Large Language Model-based Agentshttps://github.com/YoungDubbyDu/LLM-Agent-Optimization.
(文:PaperAgent)