


当 GPT-4o 流畅解析量子力学、Gemini 2.0 精准推导热力学公式、o3 以接近人类的准确率攻克 ARC-AGI 挑战、DeepSeek 在数学推理中展现惊人效率时,一个根本问题始终悬而未决:这些大模型究竟是真正能够“理解”自己所产生的内容的意义(meanings),还是在“拼贴词语概率”?
这正是学界争议多年的「随机鹦鹉」(Stochastic Parrot)命题——大语言模型是否只是统计学意义上的「复读机」?
随着大模型能力的迭代演进,過往评测基准的局限性逐渐显现。以 O3 系列模型为例,其在 ARC-AGI 基准的准确率已突破 80% 阈值,这种演化将 AGI 评测推向新的维度。
新一代评估框架需满足双重挑战:既要阻断大模型通过记忆库检索或策略性搜索获取解题捷径,更需构建具备认知复杂度的任务体系——抽象概念具象化的複雜性、输入输出对的不唯一性等。
为此,腾讯、香港科技大学及约翰霍普金斯大学组成联合团队,设计了一套基于物理概念理解的评测框架 PhysiCo。该框架采用了一种总结性评估策略来评估智能体对物理概念(如抛物线运动、能量守恒)的理解程度。
具体地,它设计了两种概念理解的子任务:
第一种是基于自然格式的概念理解子任务,主要用来评估智能体的记忆能力(低层次理解);
第二种是基于网格化抽象表示的概念理解子任务,由于网格化的表示可以有效剥离语言模型的记忆优势,因此它可以用来评估智能体对概念的高层次理解能力比如抽象和联想能力(高层次理解)。
关键研究发现包括:
-
SoTA 大模型(包括 o3-mini-high、DeepSeek-R1、GPT-4o、o1、Gemini 2.0)在高层次的物理概念理解任务中落后人类约 40%;
-
大模型在基于自然语言的低层次理解子任务中表现完美,但在同一概念的抽象网格子任务中完全失败,印证“随机鹦鹉”假说;
-
大模型的短板源于深层理解缺失,而非对网格格式的陌生,传统优化方法(如微调)收效甚微。

论文题目:
The Stochastic Parrot on LLM’s Shoulder: A Summative Assessment of Physical Concept Understanding
收录会议:
NAACL 2025
论文链接:
https://arxiv.org/pdf/2502.08946
项目主页:
https://physico-benchmark.github.io

通过总结性评估衡量概念理解程度
衡量大语言模型(LLM)对句子或概念的理解程度本身具有内在挑战性。尽管 Bender 和 Koller(2020)从语言学视角对“理解”给出了定义,但这一定义依赖于另一个抽象且不可量化的术语——“意义”。因此,即使有此定义,精确测量“理解”仍难以实现。
研究者借鉴教育学和认知科学的视角,采用总结性评估来探究 LLM 是否理解特定概念。在教育与认知心理学中,总结性评估被教育工作者广泛用于评估学生的概念掌握与知识习得。
研究者将这一评估思路扩展至大模型对概念的理解评估。具体而言,假设存在一个智能系统 S 与特定概念 C,为评估 S 对 C 的理解程度,总结性评估包含以下步骤:
-
针对 C 的任务设计:设计若干概念理解任务,每个任务包含若干围绕概念 C 人工构建的问题。
-
评估 S 的表现:要求 S 解答任务中的问题,并计算其回答准确率。
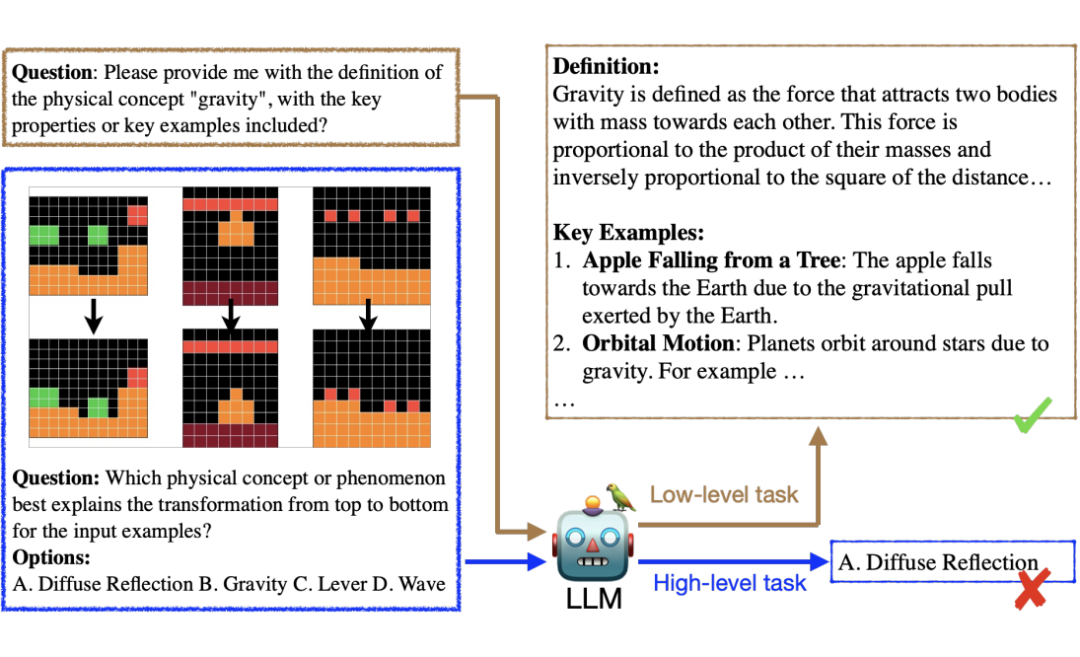

任务设计
PhysiCo 的设计考虑了以下两个层次的理解:
-
低阶理解:涵盖布鲁姆分类法中两个最基础的技能层级:从长期记忆中检索相关知识以及用自己的语言进行转述表达。
-
高阶理解:涵盖单纯记忆以外对知识的理解程度。任务的设计对应布鲁姆分类法中从“应用”到’分析’的理解层次,例如应用知识解释物理现象及以概括化和抽象化的方式分析概念的具体属性。
2.1 低阶任务
对应低阶理解任务,研究者设计了两类模态物理概念选择任务及一个物理概念生成任务。
2.1.1 物理概念选择(文本)
为了评估大模型是否掌握目标物理概念的知识,研究者设计了一项任务:要求模型根据维基百科的定义识别对应概念。
首先人工将概念的同义词替换为占位符 [PHENOMENON],同时将与概念高度相关的实体替换为 [MASK] 以避免模型通过捷径推理。随后,模型需从四个可能的物理概念中选出正确答案,这些选项与后续高阶任务的设计保持一致。
2.1.2 物理概念选择(图像)
为了评估大模型能否通过现实图片识别物理概念,研究者在谷歌图片搜索中选取反映目标概念核心属性及示例的图片(共 100 张),并构建与文本任务相同的四选一选择题。
2.1.3 物理概念生成
为评估大型语言模型在自然语言知识掌握方面的充分性重,研究者要求大模型生成物理概念的描述,包括其核心属性和示例。最后让标注员对生成的描述质量进行人工评估。评估采用二元评分制:若描述存在对概念本身的事实性错误或示例不真实的情况,则得分为 0;否则得分为 1。
2.2 高阶任务
而在高阶高阶理解任务上,研究团队构分别通过原创图对构建核心属性测试集(Core),同时基于 ARC 数据集的原数据图片进行关联物理概念延伸(Associative)。
2.2.1 PhysiCo-Core
该子任务聚焦物理概念的核心属性或最具代表性的示例/应用。为确保任务符合人类认知水平,研究者选取了 52 个高中课程范围内的常见物理概念,并由五名标注者标注每个概念的多维核心属性。每个属性对应若干抽象网格图对(共 1200 对),通过输入-输出的图形变换直观展示概念内涵。
2.2.2 PhysiCo-Associative
原始 ARC 数据集中许多实例可通过关联物理概念解决。因此,研究者要求标注者从 ARC 中手动筛选能引发特定物理概念联想的输入-输出网格图,并将对应概念作为真实标签。与 Core 不同,该任务采用开放式註解,允许标注过程中纳入新概念。
该基准测试涵盖了 50 多个物理概念。每个概念包含多种物理现象(例如,引力相关现象包括物体下落、抛物线运动及行星轨道等),总计复盖 600 个具体案例。

2.3 任务挑战性
OpenAI 的 o3 系列模型之所以能够攻克 ARC-AGI 任務,主要基于两大重点:1)大模型在代码生成方面具有卓越能力;2)其奖励机制(如准确率指标)易于设计和量化。
相比之下,PhysiCo 则面临显着下列挑战:
1. 相较于常规代码生成,创建符合物理规律的彷真引擎复杂度更高
2. 采用网格化数据格式,有效规避了视觉语言模型(VLMs)通过模式记忆解决问题的方式
3. 输入输出对不具唯一性,难以靠搜索方法找到 shortcut、绕过理解问题
4. 抽象概念(例如核聚变、光电效应等)增加了任务複杂性

实验结果及发现
通过系统性设计的 6 个研究问题(RQ),实验揭示了人机认知的深层差异:
RQ1:模型是否具备自然语言层面的知识储备以解决低阶任务?
结果:大语言模型能流畅描述物理概念并回忆属性,但仅展现自然语言层面的表面理解能力。
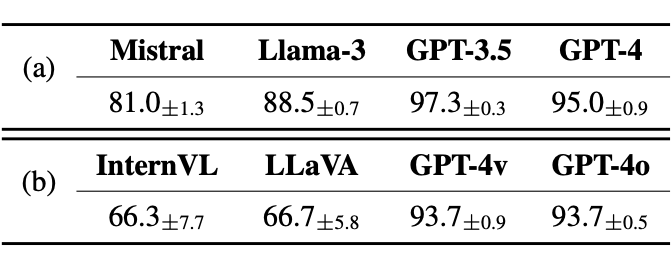
▲ 表1.(a)基于文本和(b)基于图像的物理概念选择任务准确

▲ 表2. 物理概念生成的人类评估结果
RQ2:人类在高阶任务中的表现如何?
结果:人类平均准确率达 90%。
RQ3:大模型能否处理网格表徵的高阶任务?
结果:SoTA 大模型仅在准确率上达到约 40%。
RQ4:视觉化输入能否提升高阶任务表现?
结果:视觉输入仅将 dev 准确率提升至 50%,仍然与人类有 40% 的差距。
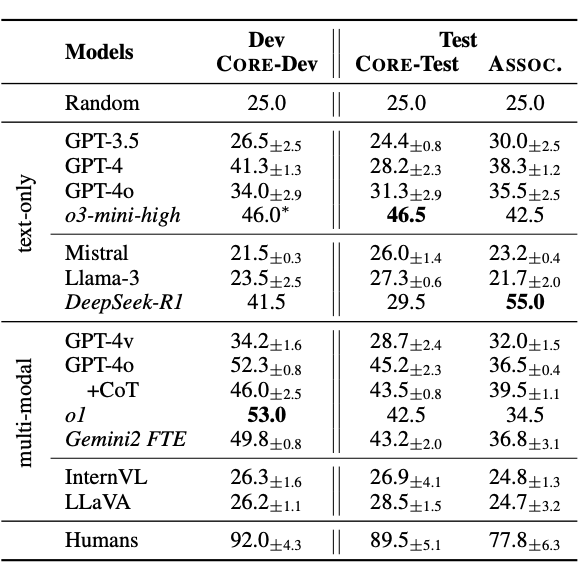
▲ 表3. 高阶任务实验结果
RQ5:大模型在 PhysiCo 上表现的不理想是否基于大模型对网格格式的陌生?
结果:实验选取 60 对网格数据,要求模型识别物体形状、颜色、位置及其变化。结果显示,GPT-4o在物体属性全对(形状、颜色、位置)条件下的准确率为 86.7%,证明 GPT-4o 熟悉网格格式。而进一步在网格格式数据上训练无法改善大模型在 PhysiCo 的表现。
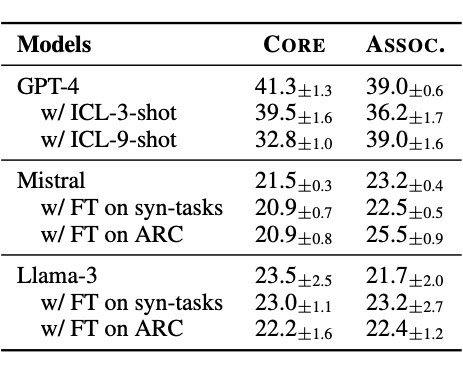
▲ 表4.在网格格式数据上的上下文及微调结果
RQ6:监督训练能否突破性能瓶颈?
结果:微调仅带来边际改善,显示模型存在「本质性理解缺陷」。

▲ 表5.在与和 Core 有重迭的概念的 Associative 子集上的实验结果
基于上述实验结果,研究团队提出三个理论:
-
40% 以上的准确率差距揭示当前模型与人类理解机制存很大的差异(RQ2, RQ4)
-
SoTA 大模型表现出「随机鹦鹉」现象(RQ1, RQ3, RQ4)
-
PhysiCo 的主要挑战在于大模型深度理解的内在困难,而非形式上的陌生。(RQ5, RQ6)
当前最先进的大语言模型对物理概念的定义具备精准掌握能力,对网格输入的理解也达到了较高水平。然而,约 40% 的认知差距揭示了人类与大语言模型在抽象模式理解层面存在本质性差异。此项研究为理解大语言模型的深度理解定义提供了新范式,被 NAACL 2025 接收。完整实验数据已在 HuggingFace(https://huggingface.co/datasets/ShunchiZhang/PhysiCo)平台开源,更多讨论可参阅该平台 Daily Paper(https://huggingface.co/papers/2502.08946)专栏。
(文:PaperWeekly)