



论文题目:
A Survey on Image Quality Assessment: Insights, Analysis, and Future Outlook
作者单位:
北京大学、厦门大学
论文地址:
https://arxiv.org/abs/2502.08540
代码仓库:
https://github.com/11xiaoyi11/IQA-Survey


引言:图像质量评估是什么,为什么我们要关注它?
图像质量评估(Image Quality Assessment, IQA)是计算机视觉中的一项基础技术,核心任务是量化图像在某种标准下的表现,此处的标准由图像使用的场景决定。它不仅是算法优化的标尺(例如判断去雾、去模糊算法的效果),也是技术落地的安全保障(如避免自动驾驶因低质图像误判)。
目前的主流 IQA 方法分为如下几种:
主观评估(Subjective IQA):依赖人类观察者打分,结果符合人眼感知,但成本高、效率低,无法大规模应用。
客观评估(Objective IQA, OIQA):通过数学公式或AI模型自动评分,客观评估可以分为三类:
1. 全参考(Full-Reference IQA):需参考图像(reference image)对比;
2. 半参考(Reduce-Reference IQA):需要部分参考图像中的信息;
3. 无参考(No-Reference IQA):直接评估单张图像质量,因为无需参考图像,因此也叫盲图像质量检测(Blind IQA,BIQA)。
客观评估中的参考图像应该如何理解呢?图像在采集、传输、处理和存储过程中,可能会被噪声污染,出现失真现象。如果将对失真图像的 IQA 视作给一张试卷打分的过程,那么参考图像就是一张满分答卷,作为参考答案,帮助我们给试卷打分。
本文首先按照 IQA 方法所使用的场景进行分类,分为通用场景和专用场景下的 IQA 方法。随后以时间为线索,展示了 IQA 发展历史上,变革性技术引领的多个新时代,并梳理了具有代表性的方法。
同时以各种 IQA 方法至 2025 年 2 月 1 日在 google scholar 上的引用量为影响力的标准,展示了不同 IQA 方法的受关注程度。我们的分类方法如上图所示。

IQA方法
2.1 通用场景方法
许多 IQA 方法并不与特定的使用场景绑定,我们称这类方法为通用场景方法。
2.1.1 统计方法
2.1.1.1 基于人类视觉系统(Human Visual System,HVS)的方法
IQA 方法中,最基本的方法有均方误差(Mean Squared Error,MSE)、信噪比(signal-to-noise ratio,SNR)、峰值信噪比(peak signal-to-noise ratio,PSNR)和 universal image quality index(UQI)等。
这些方法虽然能根据统计特征评估图像噪声和保真度,但却只是从像素值的统计特征出发,并没有考虑人类视觉系统(HVS)的特性,和人类的感知有较大差异。
为了能够与 HVS 对齐,一些改进方法应运而生,比如视觉信噪比(VSNR)、基于 HVS 的 PSNR(PSNR-HVS)等,将 HVS 的因素考虑了进去。这类工作还有:
-
关注隐藏在像素之后的图像结构与色彩信息的 Visual Saliency-induced Index(VSI)、Visual Information Fidelity(VIF);
-
充分利用边缘信息的 Gradient Magnitude Similarity Deviation(GMSD)、perceptual similarity(PSIM)、gradient similarity(GSIM),feature similarity(FSIM);
-
从视野中提取结构信息的 SSIM、MS-SSIM、IW-SSIM;
-
以及综合考虑不同策略组合的 Most Apparent Distortion(MAD)等。
这些方法汇总在表 2 中。

2.1.1.2 基于域变换的方法
在评价图像质量时,许多基于域变换的方法可以派上用场,例如奇异值分解(SVD)、离散余弦变换(DCT)等,这些变换方法可以将图像从 A 域变换到 B 域内,许多在 A 域内不明显的特征,在 B 域内会变得易于识别和处理。这
部分的代表工作有使用 SVD 提取特征的 [Shnayderman et al.,2006];使用稀疏表示方法提取特征的 SFF 和 QASD;使用小波变换提取特征的 [Wang and Simoncelli,2005];使用离散余弦变换提取特征的 BLIINDS-II 等。本节方法的汇总在表 3 中。

2.1.1.3 基于自然场景统计的方法
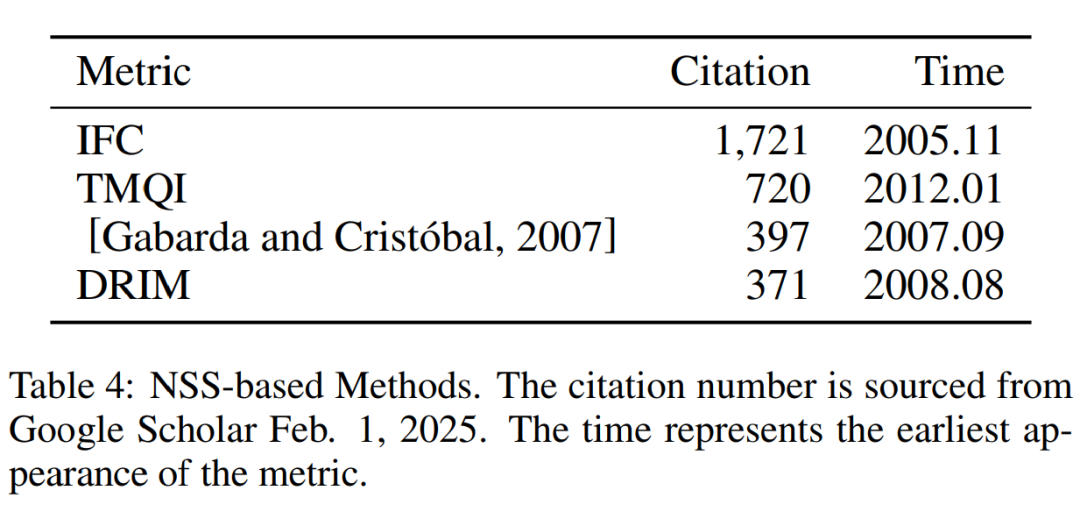
除了可以使用人类视觉系统的观察图像的习惯,和图像在变换域中的特征之外,自然图像本身的一些特点也可以用于 IQA。这类方法有分析自然图像统计特性的 IFC;利用图像各向异性的 [Gabarda and Cristobal, 2007];以及关注色调映射过程中,图像动态范围的 DRIM 和 TMQI。本节方法汇总在表 4 中。
2.1.2 机器学习方法
机器学习方法比起统计方法,可以更好地处理图像特征,因此迅速成为 IQA 研究领域的主流话题。我们在此将其分为基于模型的方法和基于框架的方法,前者指在模型架构方面有所创新的工作,后者指开创性地使用某种训练框架进行 IQA 的工作。
2.1.2.1 基于模型的方法
随着时间推移,机器学习方法中最受关注的话题一直发生着变化,从传统的经典机器学习模型,到黑盒卷积神经网络,再到力大砖飞的 Transformer 架构,机器学习领域的不同热点方法也催生了不同的 IQA 技术。这三类基于机器学习的 IQA 方法总结如下:
传统机器学习方法
随着机器学习技术的发展,许多机器学习方法被用于 IQA,例如使用支持向量回归(Support Vector Regression,SVR)的 MMF、ParaBoost 方法;机器学习方法也可以用来提取自然场景的统计特征,这方面的工作有 DIIVINE、IL-NIQE、BRISQUE 等。本节工作汇总在表 5 中。

基于卷积神经网络的方法
随着卷积神经网络(Convolutional Neural Network,CNN)所受的关注增加,从 2014 年使用 CNN 评估图像质量的 IQA-CNN 被提出后,越来越多人使用 CNN 来进行 IQA。
这一阶段值得关注的方法有:通过不同 patch 分别计算图像质量的 BIECON;使用 Siamese 网络提取特征的 [Bosse and et al.,2017];端到端的 IQA 方法 MEON;关注相对排名的 RankIQA;解决 CNN 对纹理相似性过于敏感问题的 DISTS 等。
许多从多个尺度对图像进行处理,以同时考虑全局和局部特征的方法在这一阶段被提出,例如 [Varga,2020]、Re-IQA 以及 NTIRE 2021 IQA 的冠军 IQMA Network 等。本节工作总结在表 6 中。

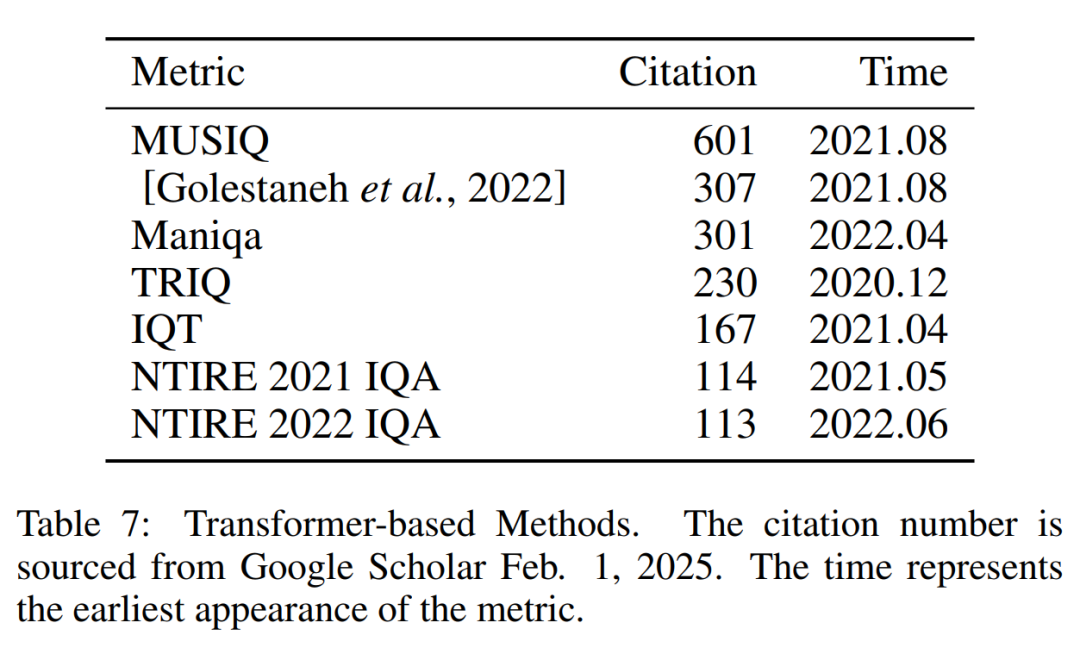
基于 Transformer 的方法
Transformer 的问世开启了人工智能领域的新时代,也给 IQA 注入了新的动力,在使用 CNN 进行图像质量评估时,往往需要固定输入图片的尺寸,无法处理不同分辨率的图像。
因此在处理实际图像时,要对初始图像进行缩放,这会导致原始信息丢失。而基于 Transformer 框架的 TRIQ、MUSIQ 等方法则可以处理不同大小和纵横比的图片,同时无需对其进行裁剪、强行调整大小,如此一来也就不会导致原始信息丢失。
除此之外,基于 Transformer 的 IQA 方法还有使用 Siamese 架构的 IQT;引入相对排名和自一致性 loss 的 [Golestaneh et al.,2022];使用跨通道、跨空间注意力机制的 Maniqa 等。
在 IQA 方向的专业赛事 NTIRE 2021 Challenge on Perceptual IQA 中,许多参赛队伍使用了 Transformer 框架,其中冠军队伍 LIPT team 首次将 Transformer 用于 FR-IQA;次年的 NTIRE 2022 Challenge on Perceptual IQA 中,FR-IQA 和 NR-IQA 两个赛道的冠军队伍都使用了 ViT 框架。
这充分说明基于 Transformer 的 IQA 方法效果受到了公众的肯定。本节工作总结在表 7 中。
2.1.2.2 基于框架的方法
除了模型结构的创新之外,机器学习中许多工作有着基于训练框架的创新,这些工作试图解决 IQA 领域一些至关重要的问题,所以同样值得关注。
在解决细分领域 IQA 的数据不足问题时,许多方法以训练框架的创新为切入点,设计了出色的方法,例如使用迁移学习的 Medical Ultrasound IQA;使用元学习的 MetaIQA;可以在多个数据集上同时训练的 UNIQUE;使用弱监督学习的 DeepFL-IQA;使用自监督学习的 CONTRIQUE、QAC;使用对抗学习的 Hallucinated-IQA 等。
NR-IQA 的研究存在一个致命的问题:使用 CNN 进行 NR-IQA 时,数据集的形式为一张图片对应一个分数。但 CNN 在处理图像时是逐像素处理的,却并不知道每个像素对应着的分数是多少——因为这个分数实际上并不存在。而在 FR-IQA 中,每个像素在参考图像都有着对应的像素作为参考。
因此我们应该想办法将 FR-IQA 中学到的知识用于 NR-IQA 中,以实现让每个 pixel 都有所参考。[Kim et al., 2018] 通过提出一个两阶段训练框架实现了将 FR-IQA 的知识用于 NR-IQA;CVRDK-IQA 通过知识蒸馏也做到了这一点。本节提到的方法总结在表 8 中。

2.2 专用场景方法
除了上述用于通用场景的 IQA 方法之外,还有许多 IQA 方法是针对特定应用场景的,这些方法为了满足特定场景的需求,做了特殊考虑。
例如医学场景下的[Rosen et al., 2018]、针对去雾算法(Dehazing Algorithm,DHA)的 [Min et al., 2019]、针对人像质量检测的 [Chahine et al., 2024]、NTIRE 2024 Challenge 人像质量评估赛道中的 PQE、SAR、针对特定失真的 [Liu et al., 2013]、BIBLE、[Ferzli and Karam, 2009]、[Gore and Gupta, 2015] 等。本节方法的汇总在表 9 中。


讨论与分析

▲ 图1:基于人类视觉系统、域变换、自然场景统计、传统机器学习的 IQA 方法中,经典方法的发表时间整理

▲ 图2:基于CNN、基于Transformer、基于训练框架、特定场景的 IQA 方法中,经典方法的发表时间整理
我们将前面提到的所有方法按照时间和分类,整理在上图中,以方便观察到各种方法出现的相对时间。
纵观 IQA 的发展,从简单的统计学指标,到传统机器学习方法和卷积神经网络,再到 Transformer 架构、元学习等各种训练框架,IQA 领域的主流技术在不断改变,但如今使用最广泛的 IQA 方法,却仍然是最传统的 PSNR, SSIM 等方法,原因在于传统方法具有使用简单和可解释性强的特点。
关于使用简单,使用目前效果最好的基于 ViT 的模型进行 IQA 时,配置环境、部署模型需要研究者们克服许多技术性难题,并且对计算资源要求很高;关于可解释性,因为神经网络是一个黑盒,这会导致以下情况的出现:假设基于 ViT 的 IQA 方法作为图像生成系统的一个模块,来评估生成的图像质量高低。
当图像质量在 IQA 模块中获得好的评估结果时,这可能只是由于图像符合基于 ViT 的 IQA 方法的评估偏好,而非图像本身质量高——也就是说在整个系统里,生成图像的模块在 IQA 方法给出的一次次评分中,学到的只是一种 IQA 方法的评估规律,而非图像质量本身。
与之形成鲜明对比的,SSIM、PSNR 只是一个公式,使用十分方便,可解释性也远高于种种神经网络。
同时,IQA 的发展还应该关注一点:IQA 技术在用于生产实践的过程中需要面临不同的使用场景,应该做到与使用者的需求一致,从使用者的角度出发,考虑图像质量应该如何评估。
例如当 IQA 技术评估图像的美学价值时,应当如从美学的观点出发,以构图,光线,聚焦,色彩为标准评估图像;当评价人像质量时,应像 NTIRE 2024 Portrait Quality Assessment Challenge 的参赛队伍一样,认识到面部区域的质量对整体人像质量的影响远大于其他区域。
总之,想要提出一种所有场景都适用的 IQA 方法是不现实的,很多场景对高质量的定义完全相反:举例来说,运动模糊可以增强图像的真实感,在一些情况下可以满足人像拍摄的要求,属于高质量图像,但对用于医学诊断的图像来说,则是低质量的图像。
总之,IQA 技术的发展需要在追求性能提升的同时,注重方法的针对性、可解释性和易用性。通过结合特定场景的需求和相关算法的特点,设计出更加易于理解和应用的 IQA 方法,才能更好地推动图像质量评估技术的发展和应用。
(文:PaperWeekly)