

今天,我们学习如何构建一个 Agentic 工作流,根据 3-5 个单词的书名编写一本 20k 单词的书。
技术栈:
-
Bright Data 用于大规模抓取网页。
-
crewAIInc 用于编排。
-
GoogleDeepMind 的 Gemma 3 作为 LLM。
-
ollama 在本地为 Gemma 3 提供服务。
以下是我们的工作流程:
-
使用 Bright Data,Outline Crew 抓取与书名相关的数据并确定章节数和标题。
-
并行调用多个 Writer Crew,每个 Writer Crew 编写一章。
-
合并所有章节以获得整本书。

准备好了吗?开始撸代码!
1️⃣ 抓取工具 – SERP API
书籍需要研究。因此,我们将使用 Bright Data 的 SERP API 大规模抓取数据。
工具使用:
-
大纲团队 → 研究书名并准备大纲。
-
作家团队 → 研究章节标题并撰写。

2️⃣ 在本地设置 Gemma 3
我们将通过 Ollama 在本地提供 Gemma 3。
具体操作如下:
-
首先,我们把它下载到本地。
-
接下来,我们使用 CrewAI 的 LLM 类对其进行定义。

3️⃣ 大纲团队
这个团队有两个智能体:
-
研究智能体 → 使用 Bright Data 抓取工具抓取与书名相关的数据并准备提取信息。
-
大纲智能体 → 使用见解将总章节和标题输出为 Pydantic 输出。

4️⃣ 写作团队
这个团队有两个智能体:
-
研究智能体 → 使用 Bright Data Scraping 工具抓取与章节标题相关的数据并准备提取信息。
-
写作智能体 → 使用见解撰写章节。

5️⃣ 创建工作流程
我们使用 CrewAI Flows 来协调工作流程。
首先,大纲方法调用大纲团队,其:
-
使用抓取工具研究主题。
-
返回章节总数和相应的标题。
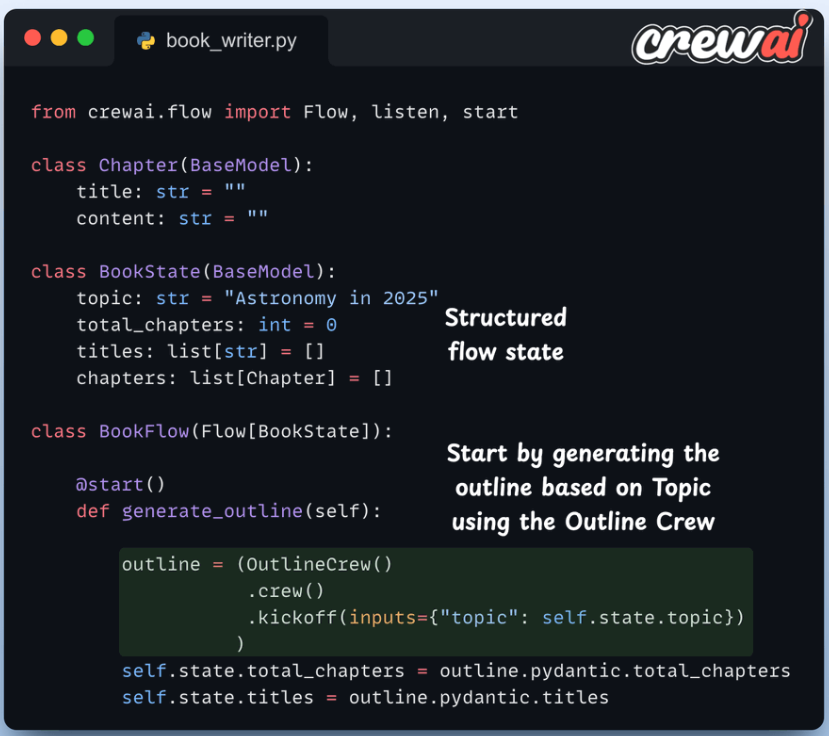
接下来,我们定义一个编写章节的方法。在这里,我们每章调用一个 Writer Crew,每个 Crew 并行运行。
我们还将所有章节的列表传递给每个 Crew,以便他们了解这本书的整体大纲。

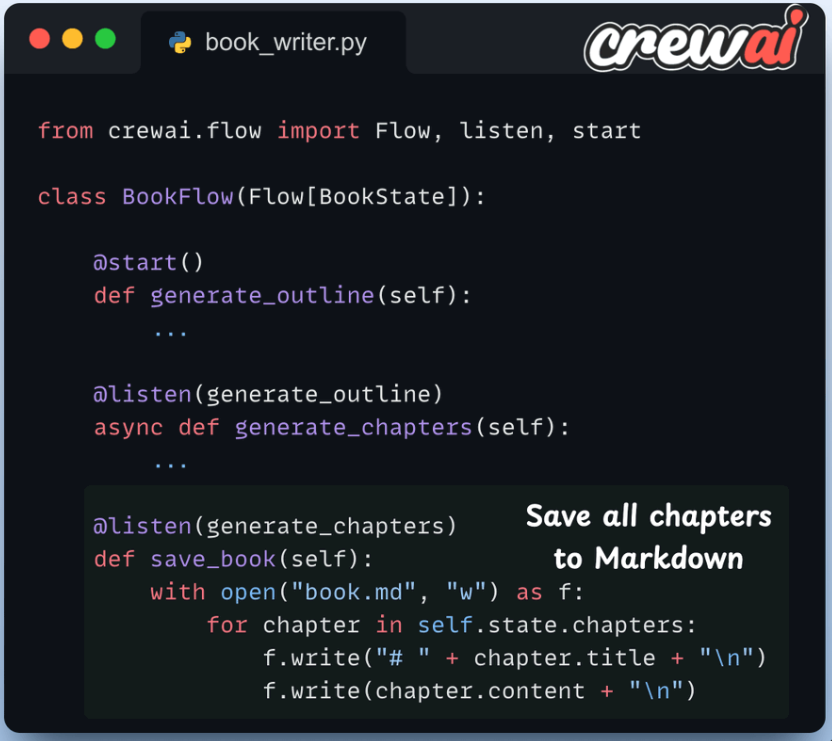
6️⃣ 保存书籍
一旦所有 Writer Crew 都完成执行,我们就会将书籍保存为 Markdown 文件。
7️⃣ 启动工作流程
最后,我们运行流程。
-
首先,调用大纲组。它利用 Bright Data 抓取工具来准备大纲。
-
接下来,并行调用许多作家组,每人编写一章。
https://x.com/_avichawla/status/1903490706393436197
(文:PyTorch研习社)
收藏了