


【编者按】近日,中国人民大学 STILL 项目团队联合九章云极 DataCanvas 发布突破性论文《R1-Searcher: 通过强化学习激励大模型的检索能力》。该论文提出了一种全新框架 R1-Searcher,旨在通过强化学习(RL)显著增强大型语言模型(LLMs)的推理与搜索能力,解决了现有模型处理知识密集型问题时的不足,在多跳问答、实时信息处理等场景展现出颠覆性潜力。据论文公布,九章云极DataCanvas AIaya NeW智算操作系统支撑该R1-Searcher工程部署。
为保持原文的完整性,本文将以原文第一人称的形式进行发布!
原文链接:https://mp.weixin.qq.com/s/Cb_cfRwEsM1bOG8QwnQOcg
作者|宋华彤
机构|中国人民大学
研究方向|自然语言处理
现有的大型推理模型(LRMs)已经展示了强化学习(RL)在增强大型语言模型(LLMs)复杂推理能力方面的潜力。虽然它们在数学和编程等具有挑战性的任务上表现出色,但它们通常依赖于内部知识来解决问题,这在处理时效性强或知识密集型问题时可能显得不足,从而导致不准确性和幻觉现象。为了解决这一问题,我们提出了R1-Searcher,这是一种新颖的基于结果的两阶段强化学习方法,旨在增强LLMs的搜索能力。该方法允许LLMs在推理过程中自主调用外部搜索系统以获取额外知识。我们的框架完全依赖于强化学习,无需过程奖励或冷启动时的蒸馏。

-
代码仓库:https://github.com/SsmallSong/R1-Searcher -
模型: -
Qwen-2.5-7B-Base-RAG-RL: https://huggingface.co/XXsongLALA/Qwen-2.5-7B-base-RAG-RL -
Llama-3.1-8B-Instruct-RAG-RL: https://huggingface.co/XXsongLALA/Llama-3.1-8B-instruct-RAG-RL -
训练数据:https://huggingface.co/datasets/XXsongLALA/RAG-RL-Hotpotqa-with-2wiki


-
第一阶段,reward由retrieval-reward和format-reward组成,如果模型在推理过程中进行了检索,就会得到retrieval-reward,旨在让模型学会调用工具的格式; -
第二阶段,retrieval-reward被替换为answer-reward,让模型更自由地进行探索,answer-reward是标准答案和预测答案的F1-Score,旨在让模型学会正确调用工具解决问题。
-
RAG-based Rollout:我们使用标签<begin_of_query>…<end_of_query>来引导模型在生成过程中调用外部检索系统。捕捉到模型需要进行检索时,推理暂停并进行检索。检索到的文档被封装在<begin_of_documents>…<end_of_documents>标签中,并整合到模型的推理过程中。这种方法确保检索无缝融入推理过程,使模型能够基于检索到的文档继续推理,而不被打断。 -
Retrieval Mask-based Loss Calculation:当模型执行检索时,检索到的文档作为环境观察的一部分被整合到推理过程中。然而,模型并不需要自主生成这些文档。为了减少环境的影响,我们将<begin_of_documents>…<end_of_documents>指定为特殊标记,并在训练中对其进行掩码处理。这可以防止这些外部标记影响损失计算,确保检索到的文档不会干扰模型的内在推理和生成过程。


-
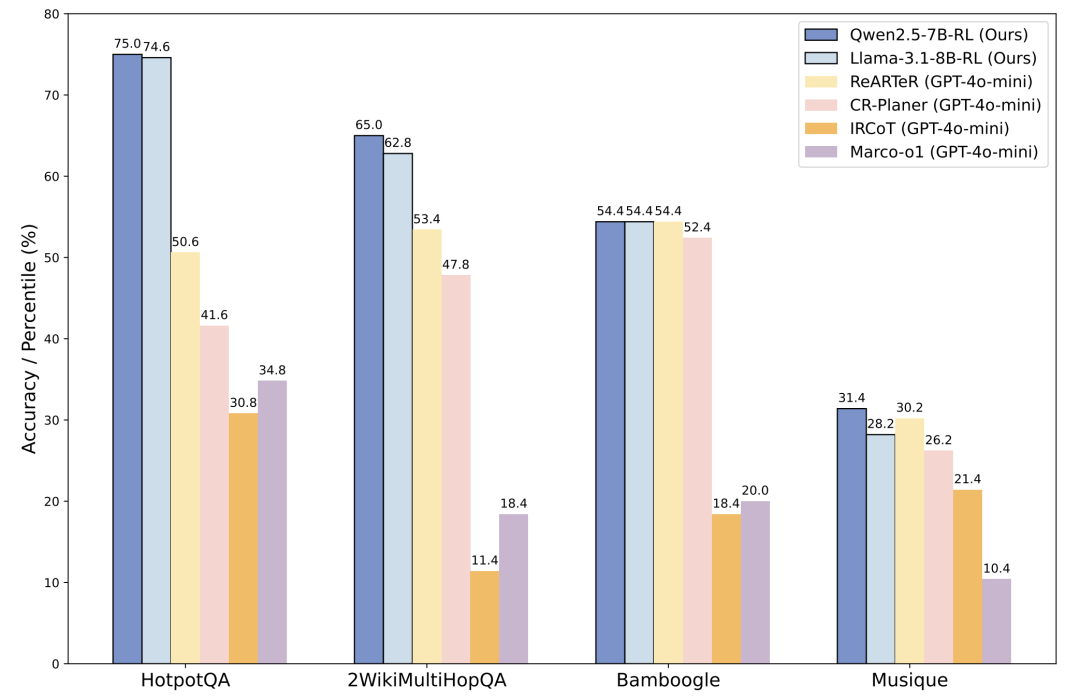
在多跳问答任务上实现显著的性能提升:相比于最好的基线ReARTeR,R1-Searcher,使用相同的LLaMA-3.1-8B-Instruct作为backbone,实现了显著的性能提升:在HotpotQA上提升了**48.2%,在2WikiMultiHopQA上提升了21.7%,在Bamboogle上提升了4.0%**(LLM-as-Judge)。这表明我们的方法可以有效地促进模型在推理过程中进行准确的检索调用。 -
从基础LLM开始进行RL学习,无需冷启动:我们从头开始使用强大的基础模型(如Qwen-2.5-7B-Base)进行RL学习。令人惊讶的是,我们能够取得更好的结果,并在大多数领域内和领域外的数据集上获得最佳性能,甚至超过了闭源的LLM,如GPT-4o-mini。这些结果展示了我们的两阶段RL方法在指导LLMs学习过程中的有效性。 -
保持泛化能力:我们仅使用HotpotQA和2WikiMultiHopQA训练集中的8148个样本进行RL训练。该模型不仅在这些领域内数据集上表现出色,还在领域外数据集(如Musique和Bamboogle)上展示了强大的泛化能力。这表明模型通过在RL训练期间的探索,有效地学习了检索并将其与推理相结合,从而在需要检索的新测试数据集上实现稳健的性能。



-
GRPO和Reinforce++算法的比较
-
结论:GRPO的生成solution更长和检索频率更高。GRPO在领域外测试数据集(如Bamboogle)上也展现出更好的性能;而Reinforce++在领域内测试集(如HotpotQA和2Wiki)上表现更优。
-
RL和SFT的比较
-
结论:RL在领域内和领域外的测试集上均优于SFT。SFT能够帮助模型生成检索查询,但这些查询的时机和相关性不如通过RL训练生成的查询。
-
Reward的设计对训练的影响
-
结论:基于F1的答案奖励能够产生更长的回答长度和更优的最终结果;基于EM的奖励在训练过程中导致回答长度较短,并且在测试时表现不如基于CEM或F1的奖励;基于CEM的奖励会生成带有不必要信息的偏长的answer。
-
数据难度分布和数据多样性对训练的影响
-
结论:使用混合数据集训练的模型在检索次数和生成回答长度上都有所增加,并且在测试集上取得了更高的分数;训练数据中混入较高难度的数据可以在领域内和领域外的测试集上均取得更好的效果。


案例展示

完成团队
-
Huatong Song*, Jinhao Jiang*, Yingqian Min, Jie Chen, Zhipeng Chen, Lei Fang, Wayne Xin Zhao, Ji-Rong Wen -
DataCanvas Alaya NeW

由 CSDN&Boolan 联合举办的「2025 全球机器学习技术大会」将于 4 月 18-19 日在上海隆重举行。大会云集院士、10 所高校科研工作者、近 30 家一线科技企业技术实战专家组成的超 50 位重磅嘉宾。他们将以独特的视角,解读智能体、联邦学习、多模态大模型、强化学习等前沿议题。无论你是科研学者、技术专家,还是行业从业者,都将在这里收获前沿洞见和实践经验,共同推动 AI 时代的技术变革与应用落地。

(文:AI科技大本营)