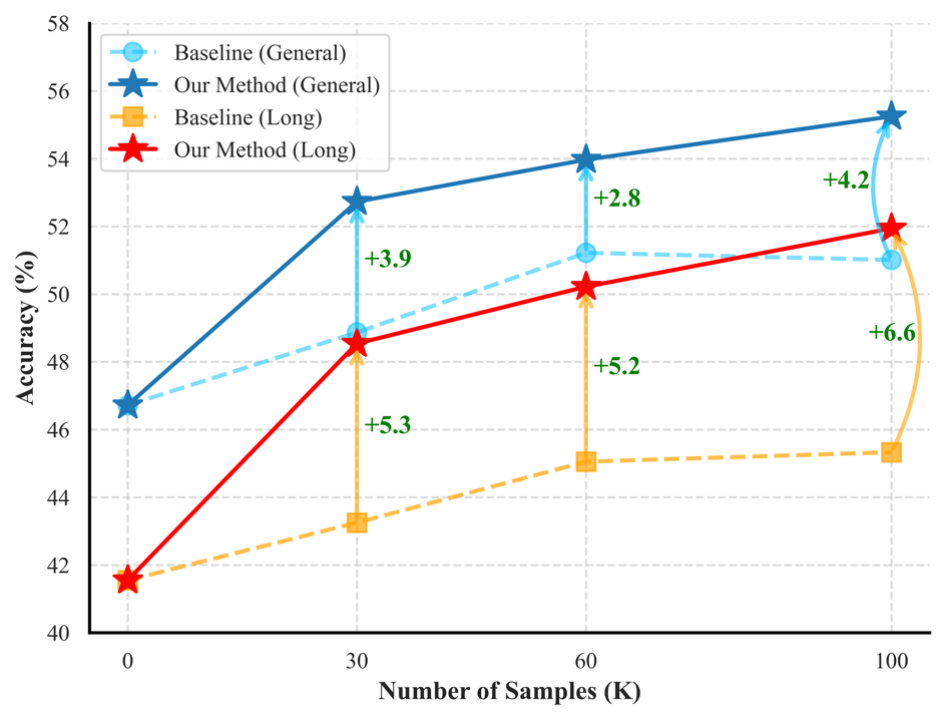
Sparrow 仅使用 30K 混合数据,性能超越 100K 视频数据达 1.7%;同时,Sparrow 在数据规模 scaling 上去后这一差距更加明显,在同样达到 100K 数据量时领先达到了 4.2%。主要原因是基线方法在数据 scaling 时迅速达到了饱和,而 Sparrow 能更稳定地 scale up。
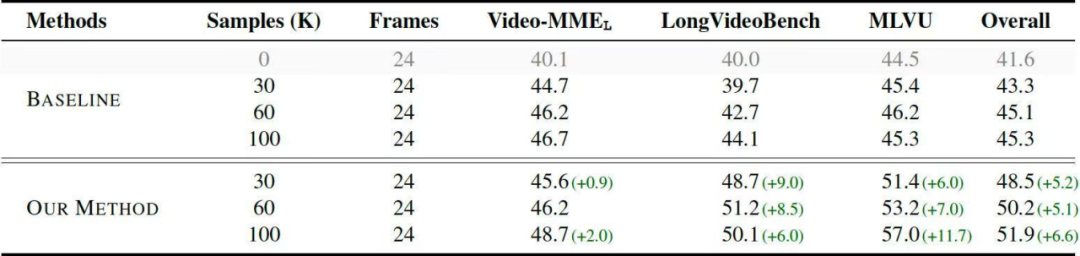
这一性能提升在长视频评测集上更为明显,在同样使用 100K 数据量时,Sparrow 领先基线达到 6.6%,即使未使用任何长视频训练数据。
本文介绍视频多模态大语言模型领域的新工作《Sparrow: Data-Efficient Video-LLM with Text-to-Image Augmentation》,相关代码和数据已开源。
论文链接:
https://arxiv.org/abs/2411.19951
数据链接:
https://huggingface.co/datasets/xjtupanda/Sparrow-Synthetic
GitHub链接:
https://github.com/VITA-MLLM/Sparrow
来自中国科学技术大学和南京大学等机构的学者合作提出了新的数据增强方法和视频 LLM 训练范式 Sparrow:利用长文本 QA 数据合成“视频”样本,提高视频数据集的指令多样性,从而提高视频 LLM 的微调效率。
该研究发现,总数据样本量相同的前提下,在视频数据中混合合成数据,可以在一般视频理解以及长视频理解 benchmark 上取得显著更优的结果。
▲ 图1. 使用不同的训练数据配置 scale up 后视频理解的性能对比。在训练数据样本量相同的前提下,使用 Sparrow 的数据增强方案后,一般视频理解与长视频理解的性能相较于基线(视频 caption 和指令数据 1:1 混合)显著提升。
大模型的成功很大程度上归功于 scaling law,即更大的训练数据量和更大的模型尺寸可以带来更好的模型性能。而近年来,多模态数据的 scale up 主要靠搭建数据 pipeline 大批量合成数据,而核心就是依赖 self-instruction(即“蒸馏”)调用商用大模型(如 GPT、Gemini)生成数据。
然而,使用这些合成数据的 scaling 特性一直缺乏探究。因此,该工作首先在这方面做了简单的探究实验。
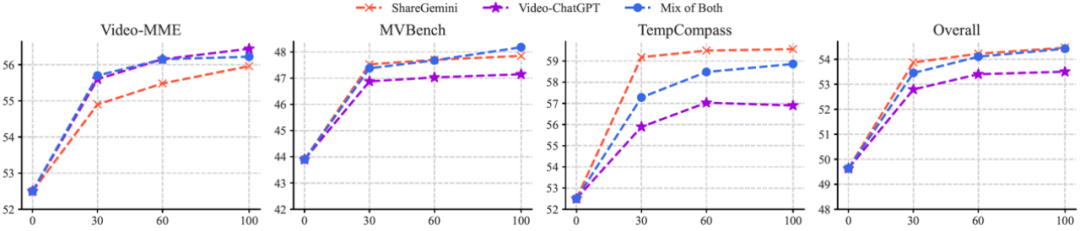
基于预训练的图片大模型(InternVL-4B),使用不同数据量与类型进行微调与评测,训练数据集包括合成的视频 caption 数据(ShareGemini-100K)以及合成的指令数据(Video-ChatGPT-100K),评测集包括 Video-MME、MVBench 以及 TempCompass,得到的结果如下:
▲ 图2. 使用不同数据量和数据类型训练后,模型在通用视频评测集上的性能
1. 使用 caption 数据、指令数据或者两者等量混合均可以提升视频理解性能。
2. 随着数据量增大,模型的性能提升迅速达到饱和。事实上,在 60K 以上增加数据量提升已经比较微小 (绝对提升小于 0.3 个百分点)。
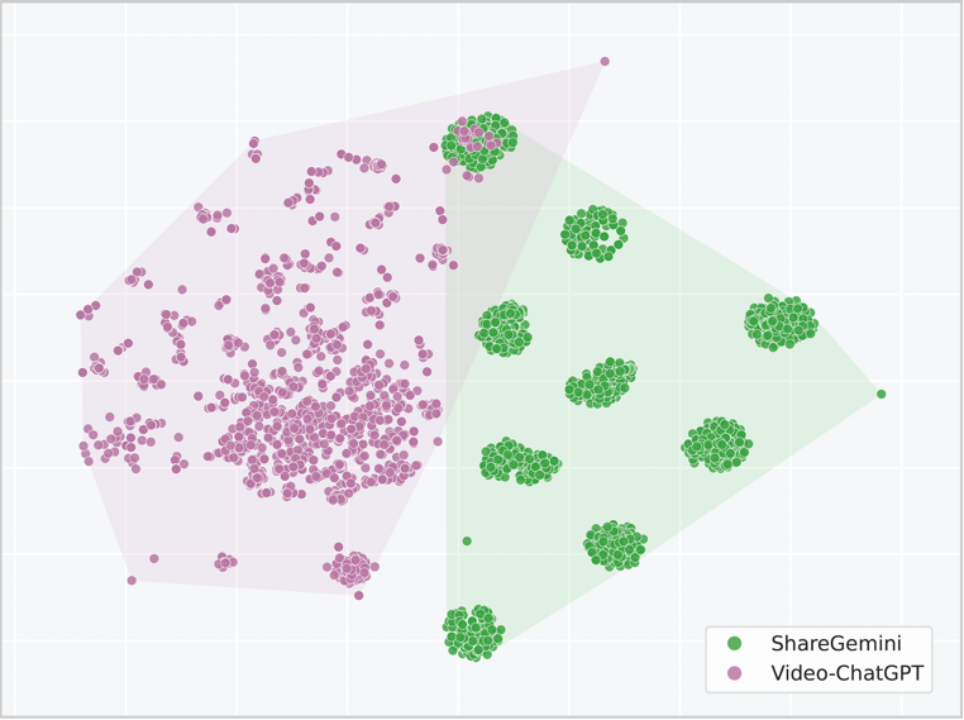
观察到这一数据 scaling 迅速饱和的现象后,该工作随后探究训练集的数据特性。具体方法是观察数据指令的 t-SNE 分布,如下图所示。
▲ 图3. ShareGemini与Video-ChatGPT数据集的指令分布t-SNE可视化
可以观察到数据的整体分布较缺乏多样性,呈现出比较明显的聚类现象。结合主流的合成数据构造范式,可以作出以下分析:
1. Caption 数据中明显的聚类簇。其中最明显的是 9 个绿色的簇。这实际上对应了以往针对单一任务(比如 OCR、Grounding。此处是 caption)时的常用做法,即事先定义一个 prompt 池,对于每个数据样本,从 prompt 池中随机抽取一个 prompt 作为该条数据的指令。
2. 指令数据的多样性不足。以往普遍做法是调用商业模型的 API 批量合成数据,调用 API 时输入:固定的 prompt 模版、数据的要求(格式、长度等)、任务范围、数据示范样例。
这种做法的缺陷在于:任务较为单一(一般受限于预先划定的任务范围和相应的数据示范样例),以 Video-ChatGPT 为例,该数据集划定了三大类任务并制定了固定模版。
文中根据这些观察判断指令多样性的不足导致了数据 scaling 的低效。
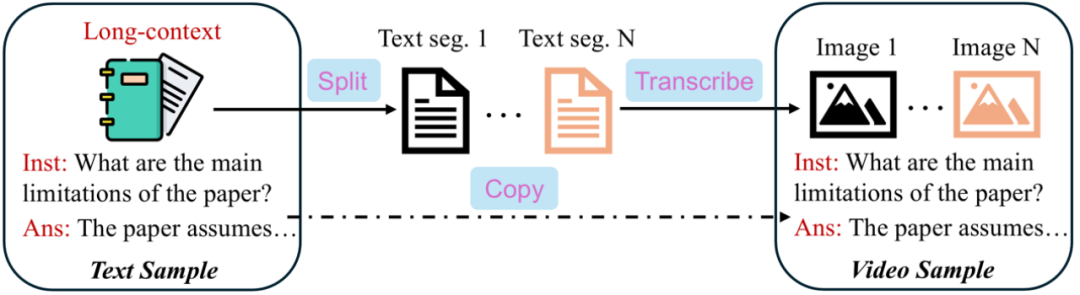
针对训练数据指令多样性不足的问题,直接标注更多样的视频数据开销很大。该工作提出一种经济的数据增强方法 Sparrow,即利用已有的开源长文本 QA 数据合成“伪视频指令数据”,提高训练集的多样性。
该做法基于两个出发点:1)文本数据的指令分布多样且不同于视觉领域,可以形成互补;2)长文本的上下文关联结构与视频帧之间的一维时序结构类似,在形式上适合模拟视频。
如图所示,该方法将长文本 QA 数据样本的(长上下文,问题,答案)三元组中的长上下文分块并分别嵌入图片中,从而为每个文本样本合成一串图片,而问题和答案保持不变。合成得到的数据格式类似于一般的视频指令数据。
文中对这种基于简单合成的数据增强方法进行了实验验证,此处主要介绍最主要的两点,更好的 scaling 表现和无长视频数据训练前提下实现长视频理解性能提升。
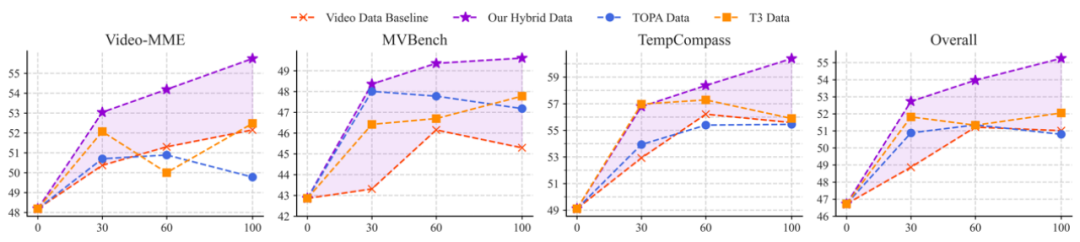
▲ 图5. 使用不同数据量和数据类型训练后,模型在通用视频评测集上的性能。紫色阴影区域表示Sparrow(视频数据:新合成数据=2:1)相较于基线的增益
如上图所示,在使用等量数据训练时,相比于其它方法,Sparrow 方法在各个 benchmark 的性能都更优。
在总体性能上,Sparrow 使用 30K 数据总量训练得到的模型就已超越 100K 数据量训练的基线 1.7 个百分点;而 Sparrow 在数据 scaling 上去后这一差距更加明显,在同样达到 100K 数据量时差距达到了 4.2 个百分点。主要原因是基线在数据 scaling 时迅速达到了饱和,而 Sparrow 能更稳定地 scale up。
▲ 图6. 使用不同数据量和数据类型训练后,模型在长视频评测集上的性能
有趣的是,虽然没有使用真正的长视频训练,而只是加入了多模态上下文更长的合成数据训练,模型在长视频理解 benchmark 上相比于基线方法显著提升 6.6%。这可能说明模型处理长文本的能力在一定程度上迁移到了长视频理解上。
该工作主要重新审视了合成数据的特点以及 scaling 特性,并探索了如何利用数据增强的方法优化数据分布,从而达到更好的数据 scaling 表现。
另一方面,从构造视频训练数据集的角度看,合成数据是并将长期是 scale up 多模态大模型训练的主要推动力。如何更高效地利用合成数据、如何构造更高质量的合成数据值得更多的思考和探索。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
(文:PaperWeekly)