


©作者 | 孟繁青
单位 | 上海交通大学
研究方向 | 多模态大模型

论文标题:
MM-EUREKA: Exploring Visual Aha Moment with Rule-based Large-scale Reinforcement Learning
代码链接:
https://github.com/ModalMinds/MM-EUREKA
模型链接:
https://huggingface.co/FanqingM/MM-Eureka-Zero-38B
https://huggingface.co/FanqingM/MM-Eureka-8B
数据集链接:
https://huggingface.co/datasets/FanqingM/MM-Eureka-Dataset

Why We DO?
目前的研究大多未能在多模态环境中复现 DeepSeek-R1 的关键特性,如回答长度的稳定增长和准确率奖励。
例如,R1-V 仅在简单计数任务上有所改进,但未能复现回答长度增长和“顿悟时刻”;R1-Multimodal-Journey 探索了几何问题,但随着训练进行,回答长度反而下降;LMM-R1虽然在准确率奖励和回答长度方面取得了进步,但这种成功尚未在大规模图文数据训练中得到验证。
虽然 Kimi1.5 在多模态推理中取得了有竞争力的结果,但它并未向社区开源其模型或训练数据。

What We do?
开源框架:我们基于 OpenRLHF 构建了一个可扩展的多模态大规模强化学习框架,支持包括 InternVL 在内的多种模型和多种RL算法。与 R1-V 等框架相比,我们的框架具有更强的可扩展性,成功训练了 InternVL2.5-38B 等大型模型。
稳定的训练:MM-Eureka-8B 基于InternVL2.5-Instruct-8B 开发,MM-Eureka-Zero-38B 基于 InternVL2.5-Pretrained-38B 开发。两者均可以复现出稳定的 accuracy reward 以及 response length 增长,并且具备 visual aha-moment!
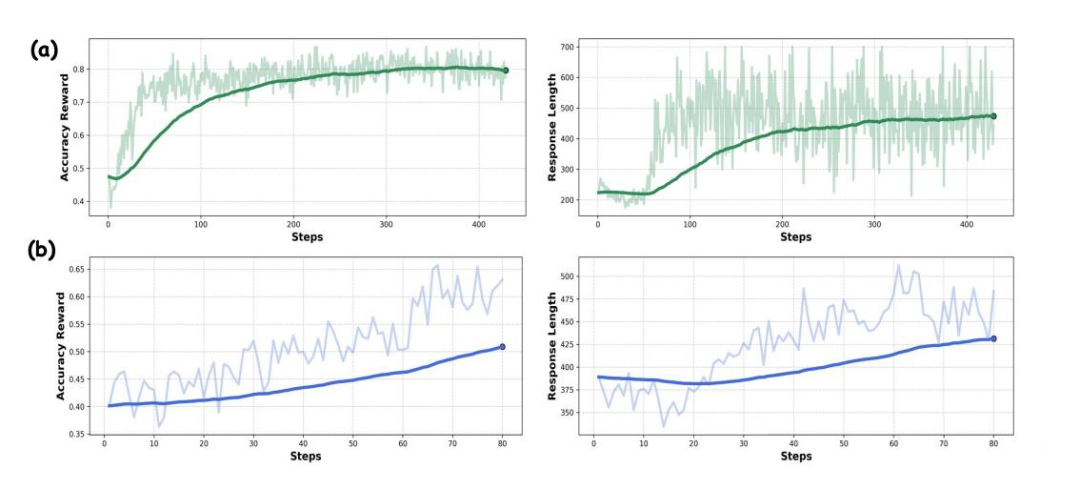
惊人的数据效率:仅使用 54K 图文数据进行规则型 RL 训练,平均性能超过使用 1M 数据的 MPO 模型;整体基准准确率与使用 12M 数据进行 CoT SFT 训练的模型相当!
MM-Eureka-Zero 仅使用 8K 图文数学推理数据(仅为指令模型的 0.05%),在我们自己构建的 K12 基准测试上比指令模型高出 8.2%,在 MathVerse 上表现相当。

What is Important?
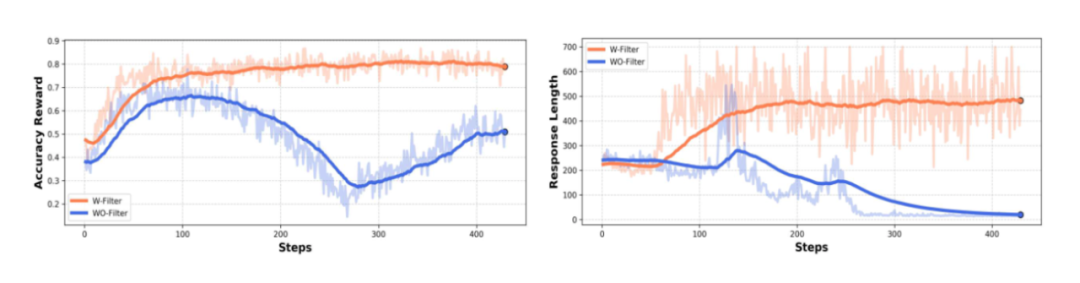
极简的 RL 设计足以获得很好的效果,如果是在 instruct model 上进行实验,添加 KL 散度往往会限制模型的探索,导致无法观测到 response length 的提高。

基于难度的数据过滤策略对于 RL 训练稳定性及其重要,我们发现在 8B-instruct 模型上训练,如果不进行数据过滤,RL 的训练将会非常不稳定。

What We Find?
模型在 RL 训练的过程中同样会展示出类似 DeepSeek-R1 的 aha-moment。特别得是:除了展示出反思和回溯操作,模型还学会了重新审视图像中的关键信息,我们认为这个是 visual aha moment 的关键特征。


What We Get?
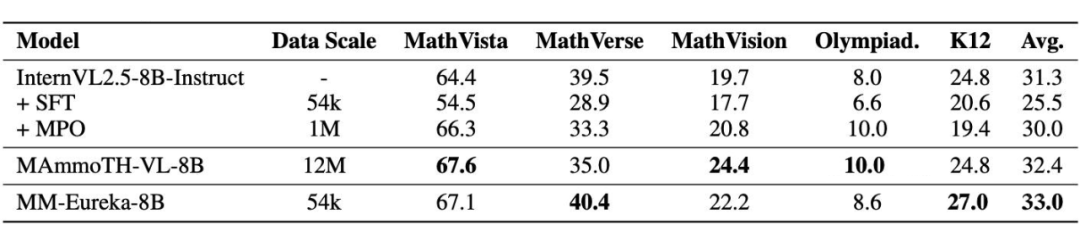
在 instructmodel 上,我们几乎使用全部开源数据(50k),便在所有的多模态数学推理 benchmark’ 上相比 instruct model 取得稳定提升,我们对比了使用 MPO,COT SFT 作为后训练的方法,我们发现简单的 rule-based RL 具备及其强大的数据高效性。
模型在所有 benchmark 的平均效果可以超过使用 1M 数据 MPO 的模型,与使用 12M COT SFT 的模型性能相似!
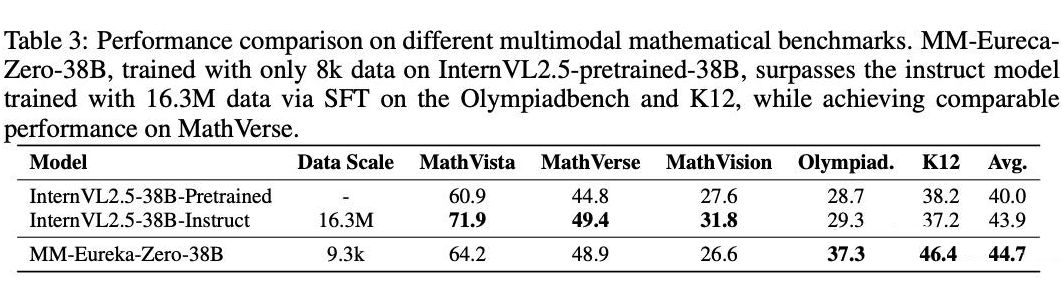
在 pretrained model 上,我们进一步挖掘了 RL 的潜力,这个事现在工作均有所缺失的。我们发现在 internvl2.5-38B 的 pretrained model上,仅仅需要 8k 的多模态数学推理数据,变可以在奥林匹克数学测试集(部分)以及 K12 数学推理测试集准上,超过使用 16.3M 数据 SFT 的 instruct model。
在 MathVerse 上,这两种模型也具有类似的表现!我们使用千分之 0.5 的数据达到了这一效果,凸显出 rl 强大的潜力!


What We Wanna Do?
我们在复现过程中进行了许多其他的尝试,再次我们分享一些我们认为有帮助,但是并没有 work 的操作,我们认为这并不代表这些有问题,而是需要进一步地探索。
Curriculum Learning:
得益于我们基于难度划分数据,每个数据都有难度标签,自然的我们把数据按难度从低到高进行 RL 训练,然而我们发现这并不能使得性能获得收益。我们认为这是因为模型在简单题目上的学习难以直接泛化到难题,如何进行 curriculum learning 的数据组织仍然重要。

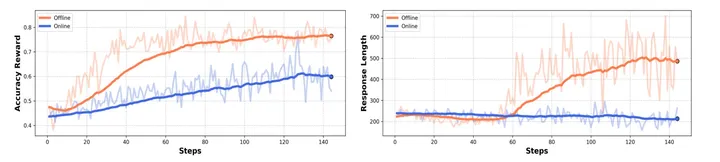
Online Data Filter:
我们将我们预先基于难度的数据筛选策略记为 Offline Data Filter。这种方案虽然可以帮助 RL 进行稳定训练,但是其数据利用率降低了,所以我们希望在模型训练的过程中动态进行基于难度的数据筛选(类似 PRIME)。
但是我们发现训练结果并不如 offline data filter 稳定,我们认为这是因为每次更新时候的数据量不同,导致梯度不稳定。
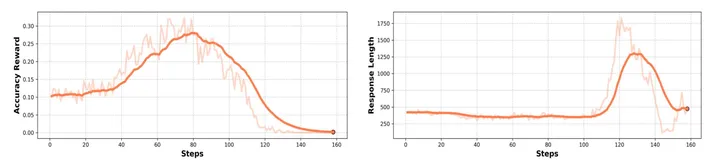
Model Size:
尽管目前一些工作比如 ORZ,SimpleRL 在 7B level 的 LLM 上也复现了 R1 的表现,但是我们在多模态推理场景下,难以通过 8B 的 internvl pretrained 进行成功复现。我们认为这受制于多模态推理数据质量以及多模态预训练数据中很少存在 long cot 数据。

What We Hope?
我们开源了全套数据(包括我们自助收集的多模态 K12 数据集),代码,以及模型等。除此之外我们推出一个详细的技术报告(在我们的 repo 中),包括我们所有的复现程序以及一些未成功的尝试。我们希望这可以帮助社区共同推理多模态推理发展。
(文:PaperWeekly)