
国内外14家机构的研究人员,用87页文章,对LLM的后训练方法(Post-training Language Models,PoLMs)进行了全面综述。该文章追溯了追踪从GPT-3(2020年)→ChatGPT(2022年)→DeepSeek-R1(2025年)的后训练进展,时间线如下:
2018-2021年(LLM基础时期)
• BERT和GPT确立了预训练和微调范式。
• 基于Transformer的模型提升了文本生成和理解能力。
2022-2023年(后训练方法的崛起)
• 引入了RLHF(人类反馈强化学习)来实现伦理对齐。 • 指令调优(InstructGPT)改善了用户互动。
• 自我精炼技术实现了逐步推理。
2024-2025年(大规模推理模型时代 – LRMs)
• DeepSeek-R1开创了冷启动强化学习,以提高推理能力。
• o1和o3模型强调了可扩展的、以对齐为驱动的训练。
• MoE(专家混合)模型通过参数选择,优化了效率。
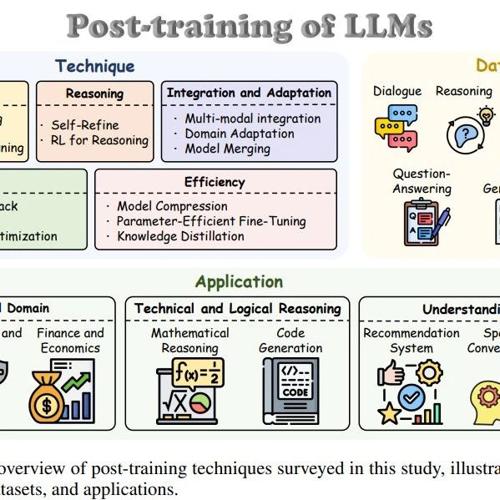
接下来是重点部分,文章综述了五种后训练范式,包括:
1. 微调(Fine-tuning) – 调整参数以提升任务特定的性能。
-
监督微调(SFT):使用标注数据集进行任务特定学习。 -
自适应微调:包括指令调优、前缀调优和提示调优,以提高适应性。 -
强化微调(ReFT):利用强化学习来优化复杂推理。
2. 对齐(Alignment) – 确保模型遵循伦理和与人类一致的行为。
-
人类反馈强化学习(RLHF):使用人类标注的奖励模型以更好地对齐偏好。 -
直接偏好优化(DPO):通过人类反馈直接优化模型。 -
AI反馈强化学习(RLAIF):使用AI生成的反馈扩展对齐训练。
3. 推理(Reasoning) – 提升多步骤推理和逻辑一致性。
-
思维链(CoT)提示:鼓励逐步推理。 -
自我精炼技术:模型迭代地优化自己的答案。 -
强化学习推理:将推理框架设为马尔可夫决策过程(MDP)。
4. 效率(Efficiency) – 优化计算资源并减少模型大小。
-
模型压缩:在不牺牲性能的情况下减小模型大小。 -
参数高效微调(PEFT):仅微调关键参数。 -
知识蒸馏:将知识从大模型转移到小模型。
5. 集成与适应(Integration & Adaptation) – 扩展模型以处理多模态和领域特定任务。
-
多模态集成:结合文本、图像和音频处理。 -
检索增强生成(RAG):获取外部数据以改善上下文响应。 -
模型合并:将多个模型结合以提高性能。
此外,文章还综述了后训练依赖的数据集,以及后训练LLM的应用场景。
数据集: 后训练离不开高质量的数据集,具体包括
-
人类标注数据集:用于微调的监督数据集。 -
蒸馏数据集:来自更大模型的派生数据(如Alpaca、Vicuna)。 -
合成数据集:由AI生成的数据,用于扩展模型能力。
应用:后训练LLMs已广泛应用于各个领域
-
医疗:协助医疗诊断和研究。 -
法律:法律文档分析和欺诈检测。 -
编程:改善代码生成效果。 -
聊天:增强聊天机器人的情感能力。
当然,文章最后,还提到了现如今LLM面临的风险,如伦理问题、公平性问题等;并提出了未来的研究方向,如自适应强化学习和公平优化。



参考文献:
[1] A Survey on Post-training of Large Language Models:https://arxiv.org/abs/2503.06072
(文:NLP工程化)