
目前为止分析DeepSeek最全面的文章了:专家混合(MoE),多头潜在注意力(MLA),多标记预测(MTP),群体相对策略优化(GRPO),推理行为等。
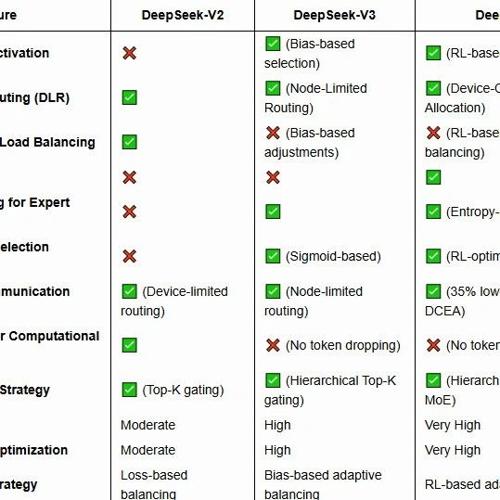
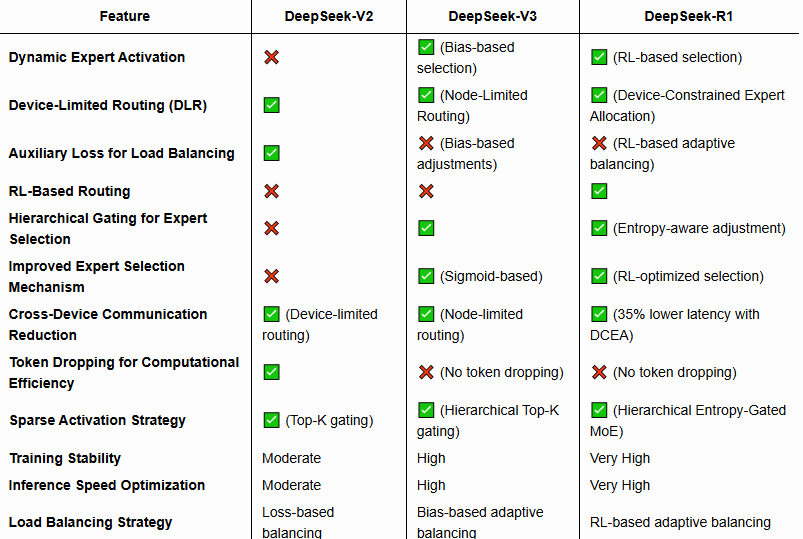
DeepSeek-V2 采用 DeepSeekMoE 架构,旨在优化训练成本和推理效率,同时保持强大的模型性能。与传统的稠密 Transformer 架构不同,DeepSeekMoE 引入了稀疏激活的专家网络,大幅降低了每个 token 的计算开销,同时允许模型拥有更高的总参数量。
DeepSeekMoE 遵循 Mixture of Experts(MoE,专家混合)范式,每个 token 会被动态分配到一部分专门的前馈网络(FFN)专家,而不是通过一个统一的稠密 FFN 进行计算。
参考文献:
[1] https://aman.ai/primers/ai/deepseek-R1/
(文:NLP工程化)
这不就是个MoE模型吗?专家混合+稀疏激活,我滴天!
Wow! 这些技术细节属实太强了!稀疏激活搭配专家网络,算得上是硬核操作。相比传统的密集架构,效率和性能都直线上升!