
随着检索增强生成(RAG)的快速发展,单纯依赖文本的 RAG 已经难以满足日益复杂的需求,多模态 RAG 正在成为新的主流趋势。传统的文本嵌入模型,如 Word2Vec、M3E 和 BGE 等,在文本表示和语义检索方面表现出色,但在多模态领域面临诸多局限性。例如,它们无法有效处理图像、音频等其他数据类型,这使得跨模态信息的整合和理解变得困难。
为了解决这一问题,Meta 推出了ImageBind——一个统一多模态的嵌入模型,旨在打破单一模态的壁垒。ImageBind 的核心理念是将文本、图像、音频、视频甚至传感器数据等不同模态的数据映射到同一个嵌入空间中。这一创新不仅提升了多模态数据的检索效率,还显著拓宽了生成式 AI 的应用场景。

在本文中,我们将深入探讨 ImageBind 的设计原理、解决的问题以及其在实际场景中的广泛应用。从更智能的虚拟助手到更高效的内容推荐,ImageBind 为多模态 RAG 的未来打开了无限可能的大门。

可以在官网上体验Demo。https://imagebind.metademolab.com/demo?modality=A2GI
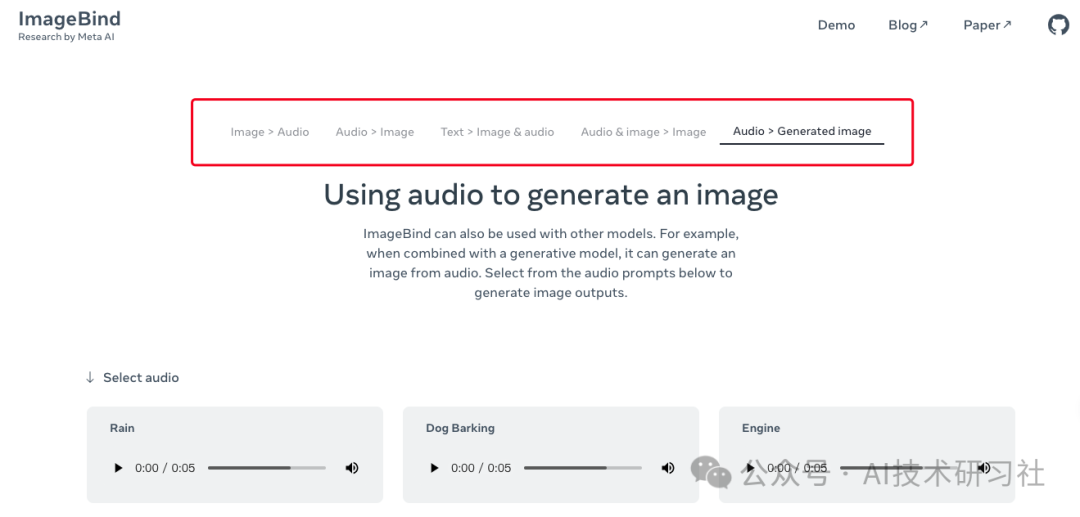
ImageBind 的核心设计在于提出了一种称为 IB(ImageBind)的模型,能够学习在六种不同模态(图像、文本、音频、深度、热成像和 IMU 数据)之间的联合嵌入方法。令人惊讶的是,这种联合嵌入的训练并不需要每种模态之间的所有配对数据,仅通过图像与其他模态的配对数据即可实现模态绑定。
这种方法充分利用了当前大规模视觉语言模型的强大性能,并通过与图像的自然配对,将模型的零样本能力扩展至新的模态。这使得 ImageBind 可以实现“开箱即用”的新型应用场景,包括:
- 跨模态检索:支持从一个模态查询数据并在其他模态中找到相关结果。
- 算术组合模态:能够以算术方式结合多个模态的特征,生成新的信息表示。
- 跨模态检测和生成:对输入数据进行分类或生成符合多模态上下文的输出。
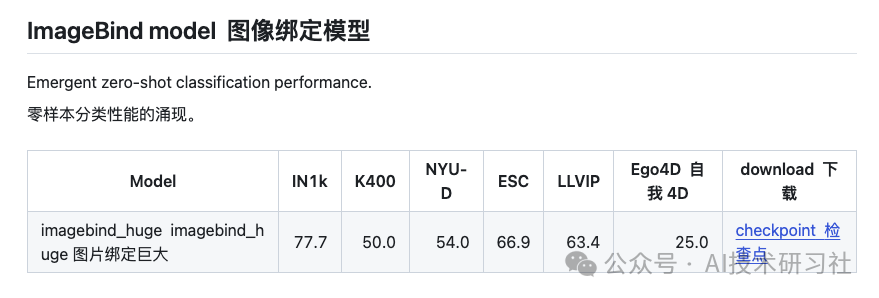
ImageBind 的新兴能力随着图像编码器的性能提升而变得更加强大。在多个跨模态零样本任务中,IB 展现出超越传统专业监督模型的性能,刷新了领域内的技术水平。此外,IB 在小样本识别任务中的表现同样优异,显著优于先前的方法。
更重要的是,ImageBind 提供了一种全新的途径,将视觉模型应用于视觉和非视觉任务的评估。这种灵活性不仅为多模态 AI 的研究提供了更强的工具,也为现实应用中复杂数据的整合和处理开辟了新方向。
使用之前,先进行安装 pytorch 1.13+ 及其他第三方依赖。
conda create --name imagebind python=3.10 -yconda activate imagebindpip install .
对于 Windows 用户,您可能需要安装 soundfile 来读取/写入音频文件。
pip install soundfile提取和比较不同模态(例如图像、文本和音频)的特征。
from imagebind import dataimport torchfrom imagebind.models import imagebind_modelfrom imagebind.models.imagebind_model import ModalityTypetext_list=["A dog.", "A car", "A bird"]image_paths=[".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"]audio_paths=[".assets/dog_audio.wav", ".assets/car_audio.wav", ".assets/bird_audio.wav"]device = "cuda:0" if torch.cuda.is_available() else "cpu"# Instantiate modelmodel = imagebind_model.imagebind_huge(pretrained=True)model.eval()model.to(device)# Load datainputs = {ModalityType.TEXT: data.load_and_transform_text(text_list, device),ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),}with torch.no_grad():embeddings = model(inputs)print("Vision x Text: ",torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, dim=-1),)print("Audio x Text: ",torch.softmax(embeddings[ModalityType.AUDIO] @ embeddings[ModalityType.TEXT].T, dim=-1),)print("Vision x Audio: ",torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.AUDIO].T, dim=-1),)# Expected output:## Vision x Text:# tensor([[9.9761e-01, 2.3694e-03, 1.8612e-05],# [3.3836e-05, 9.9994e-01, 2.4118e-05],# [4.7997e-05, 1.3496e-02, 9.8646e-01]])## Audio x Text:# tensor([[1., 0., 0.],# [0., 1., 0.],# [0., 0., 1.]])## Vision x Audio:# tensor([[0.8070, 0.1088, 0.0842],# [0.1036, 0.7884, 0.1079],# [0.0018, 0.0022, 0.9960]])
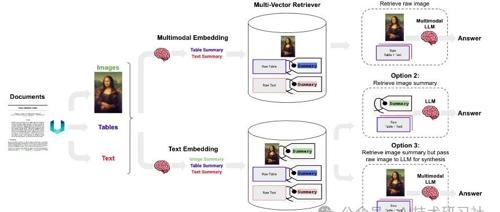
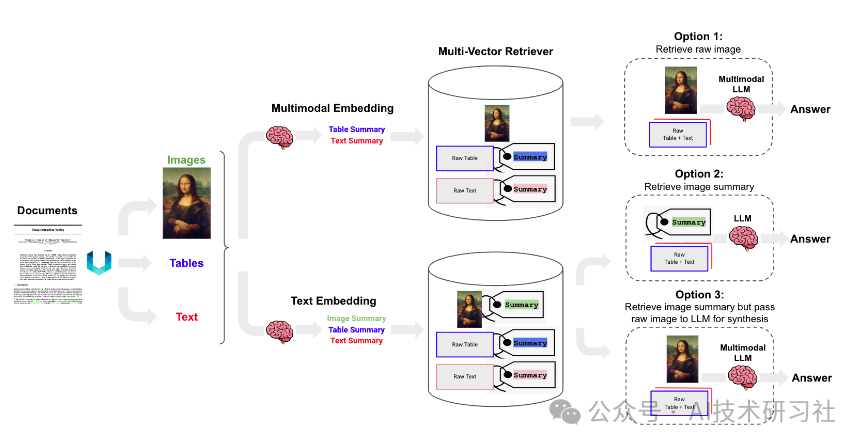
随着多模态大语言模型(LLMs)的出现(如 GPT-4V),在 RAG 应用中充分利用图像信息变得愈发重要。本文接下来,探讨了如何构建一个能够有效处理文本和图像内容的多模态 RAG 系统,重点介绍了方案三。
多模态 RAG 的三种实现方案
-
方案一:使用多模态嵌入
-
使用多模态嵌入模型(如 CLIP)嵌入图像和文本。 -
通过相似性搜索同时检索图像和文本。 -
将原始图像和文本块传递给多模态 LLM 进行答案合成。 -
方案二:使用多模态 LLM 生成图像摘要并检索文本
-
利用多模态 LLM(如 GPT-4V、LLaVA 或 FUYU-8b)从图像生成文本摘要。 -
嵌入和检索文本摘要。 -
将文本块传递给 LLM 进行答案合成。 -
方案三(本文重点):使用多模态 LLM 生成图像摘要并检索图像与文本
-
利用多模态 LLM 生成图像的文本摘要,同时保留原始图像引用。 -
嵌入和检索图像摘要及其参考的原始图像。 -
将原始图像和文本块传递给多模态 LLM 进行答案合成。
技术实现
-
数据解析
使用 Unstructured 工具解析文档(如 PDF)中的图像、文本和表格内容。 -
数据存储与检索
使用带有 Chroma 的多向量检索器,存储原始文本和图像及其摘要,便于高效检索。 -
模型应用
-
使用 GPT-4V 进行图像摘要生成,以支持检索阶段。 -
在答案生成阶段,联合分析检索到的图像和文本内容(包括表格)以生成最终答案。
通过这样的架构,系统能够充分挖掘多模态信息的潜力,实现更准确、更全面的问答能力。
除了以下 pip 软件包之外,您的系统中还需要poppler (安装说明)和tesseract (安装说明)。
pip install -U langchain openai langchain-chroma langchain-experimental # (newest versions required for multi-modal)pip install "unstructured[all-docs]" pillow pydantic lxml pillow matplotlib chromadb tiktoken对 PDF 表格、文本和图像进行分区
from langchain_text_splitters import CharacterTextSplitterfrom unstructured.partition.pdf import partition_pdf# Extract elements from PDFdef extract_pdf_elements(path, fname):"""Extract images, tables, and chunk text from a PDF file.path: File path, which is used to dump images (.jpg)fname: File name"""return partition_pdf(filename=path + fname,extract_images_in_pdf=False,infer_table_structure=True,chunking_strategy="by_title",max_characters=4000,new_after_n_chars=3800,combine_text_under_n_chars=2000,image_output_dir_path=path,)# Categorize elements by typedef categorize_elements(raw_pdf_elements):"""Categorize extracted elements from a PDF into tables and texts.raw_pdf_elements: List of unstructured.documents.elements"""tables = []texts = []for element in raw_pdf_elements:if "unstructured.documents.elements.Table" in str(type(element)):tables.append(str(element))elif "unstructured.documents.elements.CompositeElement" in str(type(element)):texts.append(str(element))return texts, tables# File pathfpath = "/Users/rlm/Desktop/cj/"fname = "cj.pdf"# Get elementsraw_pdf_elements = extract_pdf_elements(fpath, fname)# Get text, tablestexts, tables = categorize_elements(raw_pdf_elements)# Optional: Enforce a specific token size for textstext_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=4000, chunk_overlap=0)joined_texts = " ".join(texts)texts_4k_token = text_splitter.split_text(joined_texts)
使用多向量检索器来索引图像(和/或文本、表格)摘要,但检索原始图像(以及原始文本或表格)。
from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAI# Generate summaries of text elementsdef generate_text_summaries(texts, tables, summarize_texts=False):"""Summarize text elementstexts: List of strtables: List of strsummarize_texts: Bool to summarize texts"""# Promptprompt_text = """You are an assistant tasked with summarizing tables and text for retrieval. \These summaries will be embedded and used to retrieve the raw text or table elements. \Give a concise summary of the table or text that is well optimized for retrieval. Table or text: {element} """prompt = ChatPromptTemplate.from_template(prompt_text)# Text summary chainmodel = ChatOpenAI(temperature=0, model="gpt-4")summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()# Initialize empty summariestext_summaries = []table_summaries = []# Apply to text if texts are provided and summarization is requestedif texts and summarize_texts:text_summaries = summarize_chain.batch(texts, {"max_concurrency": 5})elif texts:text_summaries = texts# Apply to tables if tables are providedif tables:table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})return text_summaries, table_summaries# Get text, table summariestext_summaries, table_summaries = generate_text_summaries(texts_4k_token, tables, summarize_texts=True)
图片摘要
import base64import osfrom langchain_core.messages import HumanMessagedef encode_image(image_path):"""Getting the base64 string"""with open(image_path, "rb") as image_file:return base64.b64encode(image_file.read()).decode("utf-8")def image_summarize(img_base64, prompt):"""Make image summary"""chat = ChatOpenAI(model="gpt-4-vision-preview", max_tokens=1024)msg = chat.invoke([HumanMessage(content=[{"type": "text", "text": prompt},{"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{img_base64}"},},])])return msg.contentdef generate_img_summaries(path):"""Generate summaries and base64 encoded strings for imagespath: Path to list of .jpg files extracted by Unstructured"""# Store base64 encoded imagesimg_base64_list = []# Store image summariesimage_summaries = []# Promptprompt = """You are an assistant tasked with summarizing images for retrieval. \These summaries will be embedded and used to retrieve the raw image. \Give a concise summary of the image that is well optimized for retrieval."""# Apply to imagesfor img_file in sorted(os.listdir(path)):if img_file.endswith(".jpg"):img_path = os.path.join(path, img_file)base64_image = encode_image(img_path)img_base64_list.append(base64_image)image_summaries.append(image_summarize(base64_image, prompt))return img_base64_list, image_summaries# Image summariesimg_base64_list, image_summaries = generate_img_summaries(fpath)
添加到矢量存储
import uuidfrom langchain.retrievers.multi_vector import MultiVectorRetrieverfrom langchain.storage import InMemoryStorefrom langchain_chroma import Chromafrom langchain_core.documents import Documentfrom langchain_openai import OpenAIEmbeddingsdef create_multi_vector_retriever(vectorstore, text_summaries, texts, table_summaries, tables, image_summaries, images):"""Create retriever that indexes summaries, but returns raw images or texts"""# Initialize the storage layerstore = InMemoryStore()id_key = "doc_id"# Create the multi-vector retrieverretriever = MultiVectorRetriever(vectorstore=vectorstore,docstore=store,id_key=id_key,)# Helper function to add documents to the vectorstore and docstoredef add_documents(retriever, doc_summaries, doc_contents):doc_ids = [str(uuid.uuid4()) for _ in doc_contents]summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]})for i, s in enumerate(doc_summaries)]retriever.vectorstore.add_documents(summary_docs)retriever.docstore.mset(list(zip(doc_ids, doc_contents)))# Add texts, tables, and images# Check that text_summaries is not empty before addingif text_summaries:add_documents(retriever, text_summaries, texts)# Check that table_summaries is not empty before addingif table_summaries:add_documents(retriever, table_summaries, tables)# Check that image_summaries is not empty before addingif image_summaries:add_documents(retriever, image_summaries, images)return retriever# The vectorstore to use to index the summariesvectorstore = Chroma(collection_name="mm_rag_cj_blog", embedding_function=OpenAIEmbeddings())# Create retrieverretriever_multi_vector_img = create_multi_vector_retriever(vectorstore,text_summaries,texts,table_summaries,tables,image_summaries,img_base64_list,)
我们需要将检索到的文档放入 GPT-4V 提示模板的正确部分。
import ioimport refrom IPython.display import HTML, displayfrom langchain_core.runnables import RunnableLambda, RunnablePassthroughfrom PIL import Imagedef plt_img_base64(img_base64):"""Disply base64 encoded string as image"""# Create an HTML img tag with the base64 string as the sourceimage_html = f'<img src="data:image/jpeg;base64,{img_base64}" />'# Display the image by rendering the HTMLdisplay(HTML(image_html))def looks_like_base64(sb):"""Check if the string looks like base64"""return re.match("^[A-Za-z0-9+/]+[=]{0,2}$", sb) is not Nonedef is_image_data(b64data):"""Check if the base64 data is an image by looking at the start of the data"""image_signatures = {b"\xff\xd8\xff": "jpg",b"\x89\x50\x4e\x47\x0d\x0a\x1a\x0a": "png",b"\x47\x49\x46\x38": "gif",b"\x52\x49\x46\x46": "webp",}try:header = base64.b64decode(b64data)[:8] # Decode and get the first 8 bytesfor sig, format in image_signatures.items():if header.startswith(sig):return Truereturn Falseexcept Exception:return Falsedef resize_base64_image(base64_string, size=(128, 128)):"""Resize an image encoded as a Base64 string"""# Decode the Base64 stringimg_data = base64.b64decode(base64_string)img = Image.open(io.BytesIO(img_data))# Resize the imageresized_img = img.resize(size, Image.LANCZOS)# Save the resized image to a bytes bufferbuffered = io.BytesIO()resized_img.save(buffered, format=img.format)# Encode the resized image to Base64return base64.b64encode(buffered.getvalue()).decode("utf-8")def split_image_text_types(docs):"""Split base64-encoded images and texts"""b64_images = []texts = []for doc in docs:# Check if the document is of type Document and extract page_content if soif isinstance(doc, Document):doc = doc.page_contentif looks_like_base64(doc) and is_image_data(doc):doc = resize_base64_image(doc, size=(1300, 600))b64_images.append(doc)else:texts.append(doc)return {"images": b64_images, "texts": texts}def img_prompt_func(data_dict):"""Join the context into a single string"""formatted_texts = "\n".join(data_dict["context"]["texts"])messages = []# Adding image(s) to the messages if presentif data_dict["context"]["images"]:for image in data_dict["context"]["images"]:image_message = {"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{image}"},}messages.append(image_message)# Adding the text for analysistext_message = {"type": "text","text": ("You are financial analyst tasking with providing investment advice.\n""You will be given a mixed of text, tables, and image(s) usually of charts or graphs.\n""Use this information to provide investment advice related to the user question. \n"f"User-provided question: {data_dict['question']}\n\n""Text and / or tables:\n"f"{formatted_texts}"),}messages.append(text_message)return [HumanMessage(content=messages)]def multi_modal_rag_chain(retriever):"""Multi-modal RAG chain"""# Multi-modal LLMmodel = ChatOpenAI(temperature=0, model="gpt-4-vision-preview", max_tokens=1024)# RAG pipelinechain = ({"context": retriever | RunnableLambda(split_image_text_types),"question": RunnablePassthrough(),}| RunnableLambda(img_prompt_func)| model| StrOutputParser())return chain# Create RAG chainchain_multimodal_rag = multi_modal_rag_chain(retriever_multi_vector_img)
检查检索;我们得到与我们的问题相关的图像。
# Check retrievalquery = "Give me company names that are interesting investments based on EV / NTM and NTM rev growth. Consider EV / NTM multiples vs historical?"docs = retriever_multi_vector_img.invoke(query, limit=6)# We get 4 docslen(docs)
项目擦考:https://github.com/facebookresearch/ImageBind
完整代码参考:https://github.com/langchain-ai/langchain/blob/master/cookbook/Multi_modal_RAG.ipynb
(文:AI技术研习社)