


新智元报道
新智元报道
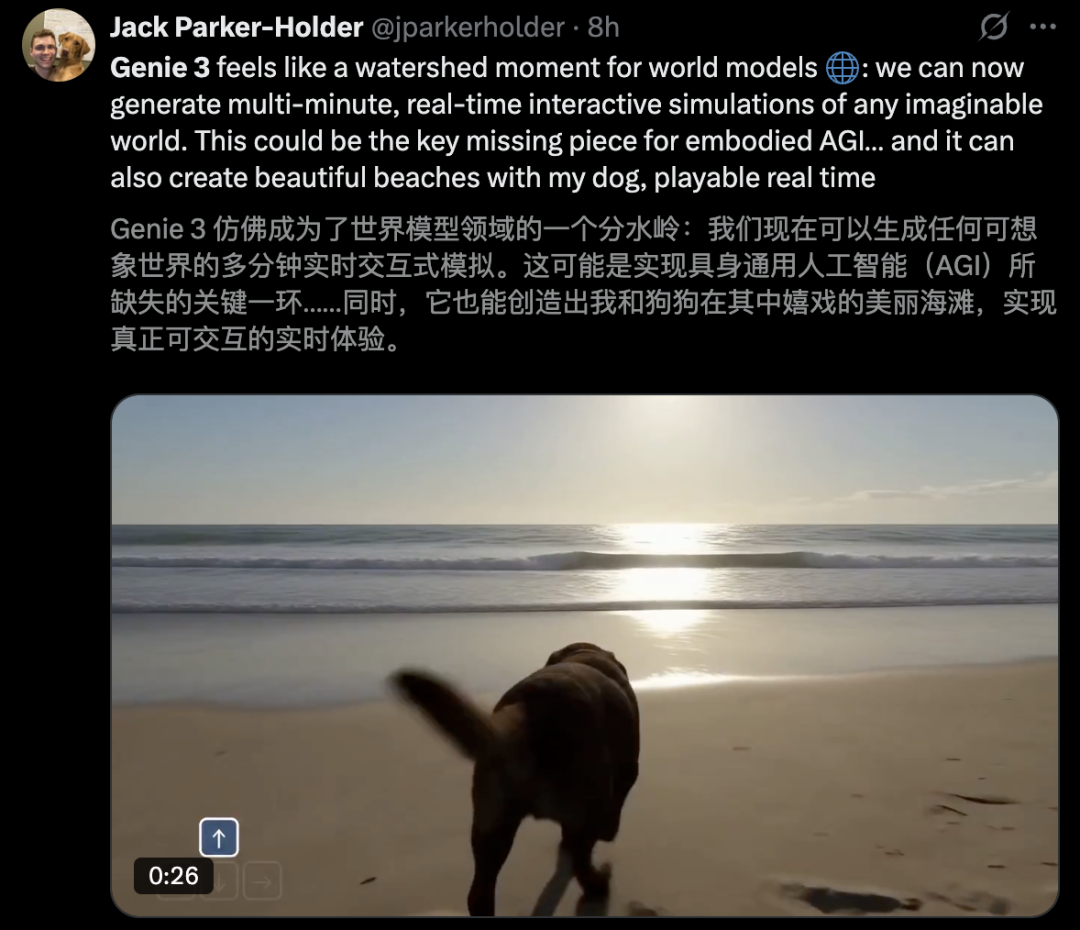
【新智元导读】老黄曾预言,每个像素都将由AI生成!刚刚,谷歌DeepMind放出的「通用世界模型」Genie 3,一句话即生720p实时模拟世界,1分钟视觉记忆一致性超高。
全球最强「世界AI模拟器」今夜诞生!
刚刚,谷歌DeepMind祭出新一代通用世界模型——Genie 3,能模拟出史无前例的丰富交互环境。

一句话,Genie 3即可生成一个动态世界。
令人惊艳的是,它能以每秒20-24帧速度,实时生成720p画面,还能持续数分钟一致性。

相比于前代,Genie 3在生成时长方面也得到了史诗级的加强——一口气能搞定长达数分钟,且内容连贯的可交互世界。
英伟达Jim Fan高度评价,「这就是游戏引擎2.0时代」!
总有一天,UE5所有复杂功能,都能被一个数据驱动的「注意力权重」吸纳。
未来,只需要将手柄指令作为输入,即可渲染一段时空中的像素画面。

如今,Genie 3的问世,标志着世界模拟AI迈向了全新高度,加速了人类通向AGI/ASI的终极目标。


一直以来,「世界模型」被业界看作是通往AGI道路上的关键基石。
因为,它能让AI智能体在无限丰富的模拟环境中接受训练。
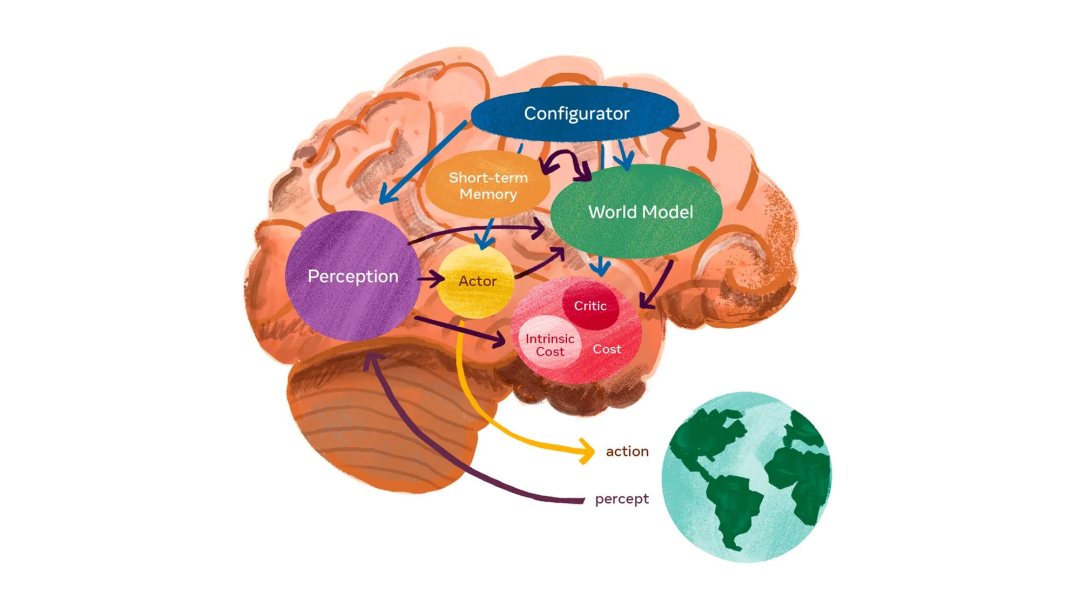
十多年来,谷歌DeepMind一直在模拟环境领域引领前沿研究,从训练AI智能体玩转即时战略游戏,到为开放式学习和机器人技术开发模拟环境。
正是在这些研究的推动下,他们开发出了「世界模型」。
它能够利用其对世界的理解,来模拟世界的方方面面,从而让AI智能体可以预测环境如何演变,以及自身行为带来的影响。
去年,谷歌DeepMind首次放出世界模型——Genie 1和Genie 2,它们能为AI智能体生成全新的环境。
此外,Veo 2、Veo 3模型相继迭代,也在不断突破视频生成的技术前沿,能够深刻理解物理世界的规律。
每一款模型,都标志着世界模拟在不同能力维度上的进步。
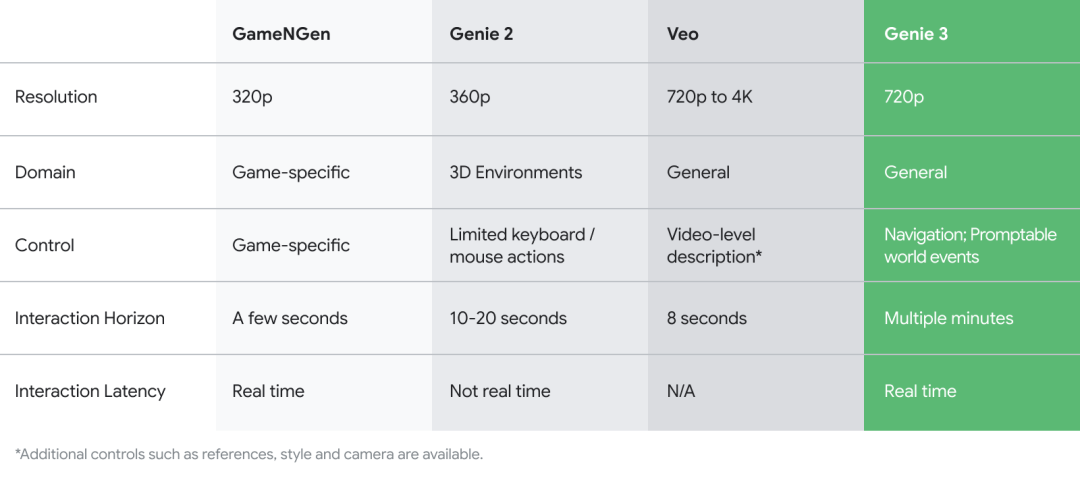
而Genie 3,是谷歌DeepMind首个支持「实时交互」的世界模型。
相较于Genie 2,一致性和真实感均有提升。

谷歌DeepMind研究员Ali Eslami惊叹道,Genie 3绝对是自ChatGPT以来最令人印象深刻的演示。
2016年,他曾研究「神经表示与渲染」隐约看到通往这一目标路径,但没想到这一天来得这么快。
Hassabis同样感慨道,上世纪90年代,当自己设计模拟游戏时,曾梦想有一天实现这一技术。如今,愿望终于达成。

接下来,具体看看Genie 3具备哪些强大能力?
· 模拟物理世界
理解物理世界,是任何一个世界模型必备能力。
Genie 3不仅可以生成水流、光照等自然现象,还能与复杂环境进行交互。





左右滑动查看
· 模拟自然世界
Genie 3还可以生成充满生命力的自然系统,不论是错综复杂的森林、花草等植物,还是各种生物,都能让人仿佛置身于真实生态之中。




左右滑动查看
· 创建动画奇幻世界
不仅如此,Genie 3的想象力也没有边界。
它能创造出奇幻场景,以及富有表现力的动画角色,比如彩虹桥上的卡通狐狸、森林中的萤火虫等等。




左右滑动查看
· 探索地点与历史场景
更令人想不到的是,Genie 3还能玩穿越。
不论是重现古代文明的辉煌,还是探索不同的地方,它都能带你跨越时空,体验景点的独特魅力。




左右滑动查看
不得不说,Genie 3的实时交互能力,令人叹为观止。
那么,谷歌DeepMind是如何具体实现的呢?
要实现Genie 3的实时交互与长时程一致性,技术团队攻克了诸多难题。
在自回归地生成每一帧画面的过程中,模型必须考虑到随时间推移而不断延长的先前轨迹。
举个栗子,当玩家在一分钟后重访某个地点时,模型必须调取一分钟前的相关信息。
为了实现实时交互,这种计算必须在新用户输入抵达时每秒执行多次,以做出即时响应。

此外,要让AI生成的世界富有沉浸感,就必须在很长的时间跨度内保持物理上的一致性。
然而,自回归地生成一个环境,通常比一次性生成整个视频的技术难度更大,因为微小误差会随时间累积。
尽管面临这一挑战,Genie 3生成的环境仍能在数分钟内基本保持一致,其视觉记忆最远可追溯到一分钟前。





左右滑动查看
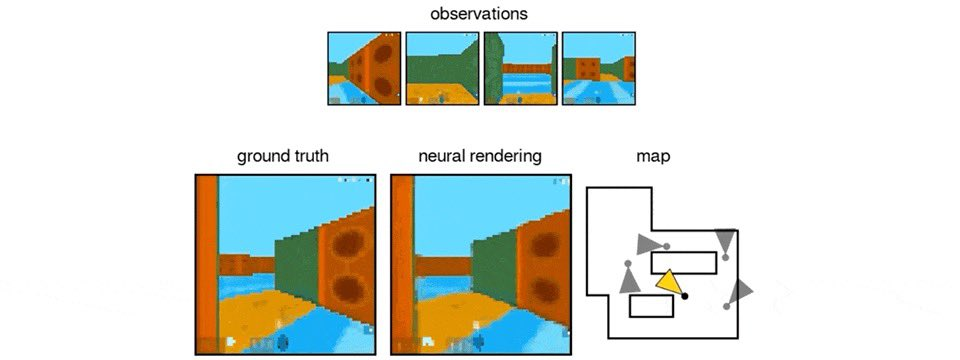
如下图可见,建筑左侧的树木在交互过程中始终如一,即使时隐时现也保持稳定。


Genie 3的一致性是一种涌现能力。
NeRFs和高斯溅射(Gaussian Splatting)虽然也能实现一致的可导航3D环境,但它们依赖于提供显式的3D表征。
相比之下,Genie 3 生成的世界则远为动态和丰富,因为它们是模型根据世界描述和用户行为逐帧创造出来的。

除了导航输入,Genie 3还支持一种更具表现力的文本交互形式,团队称之为「由提示词驱动的世界事件」。
直白讲,一句话生成世界。
不论是改变天气,还是引入新物体或角色,这种能力大幅提升了沉浸感。
与此同时,它也拓展了反事实(即what if)场景的广度,可供 AI 智能体在经验学习中用于处理各种意外情况。
比如,在北美大草原上,你可以让Genie 3即时生成一辆绿色拖拉机、一位骑马的人;在滑雪场景中,生成一个衣服上印有「Genie 3」的人,或是一个香蕉滑翔伞;在伦敦街景中,还可以空降Dragon。
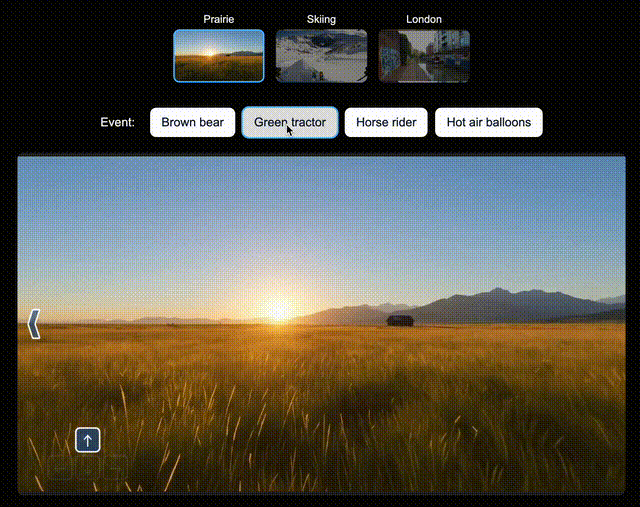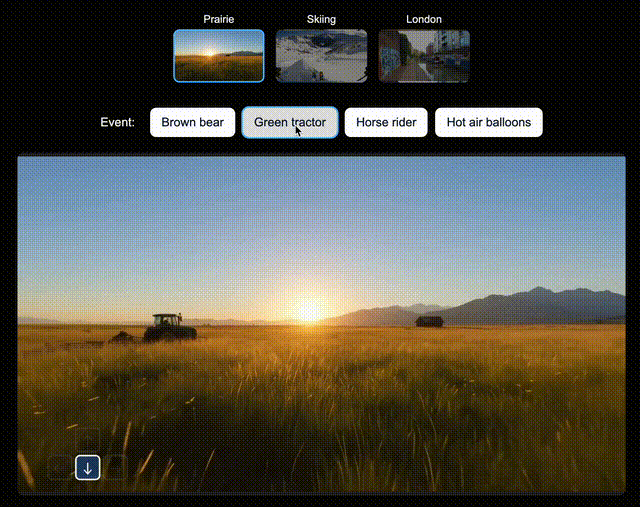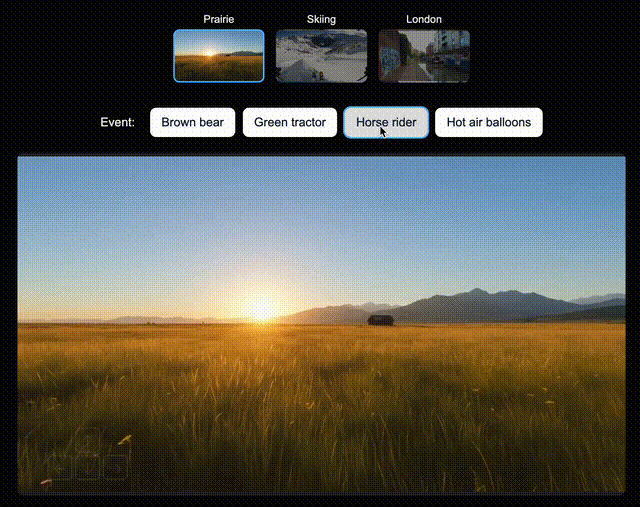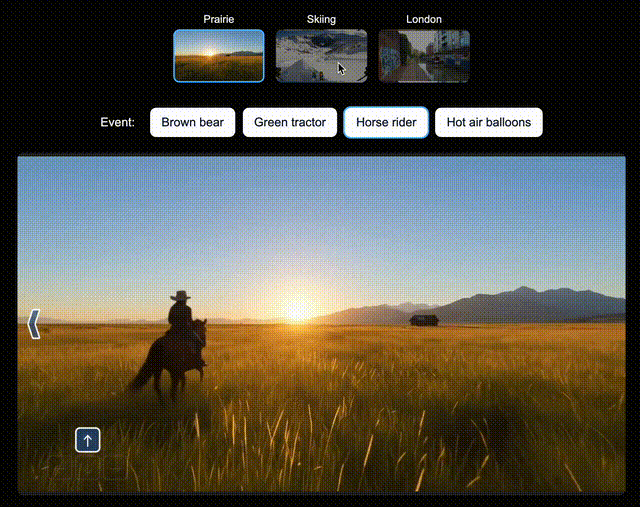
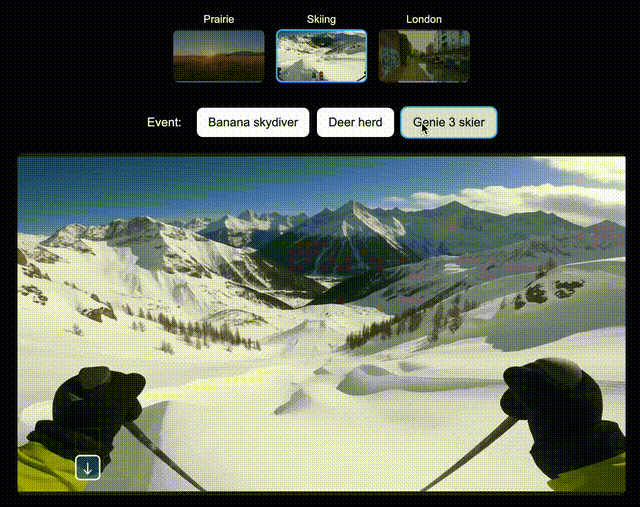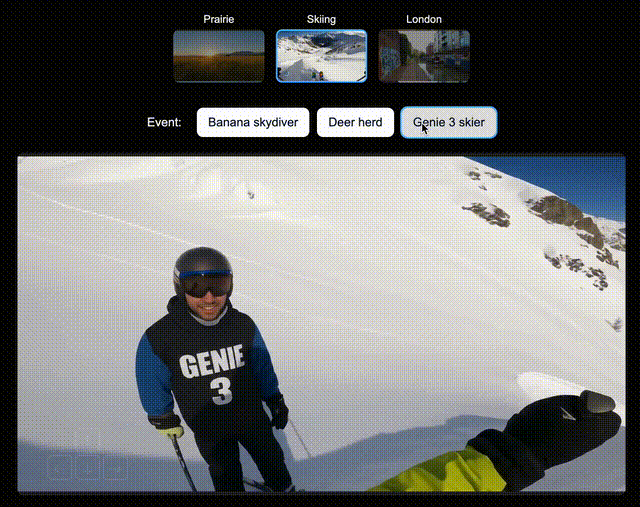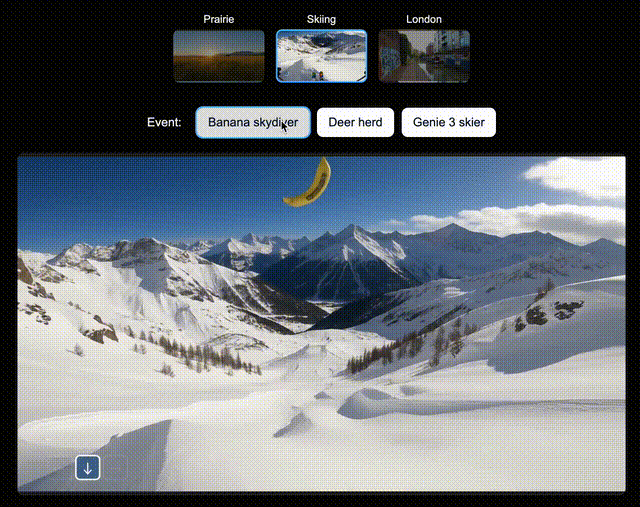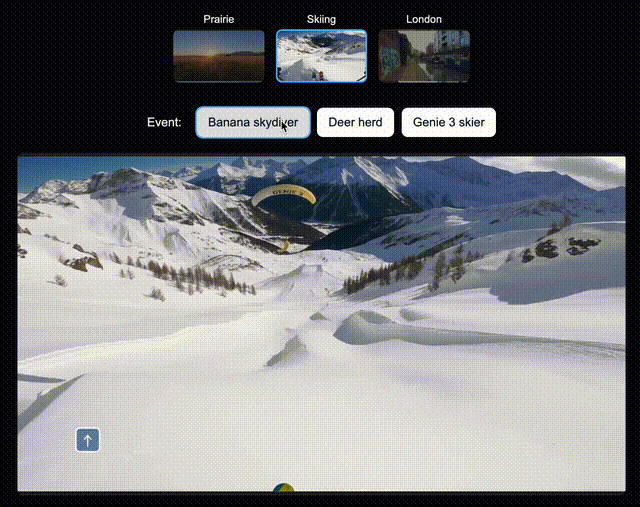
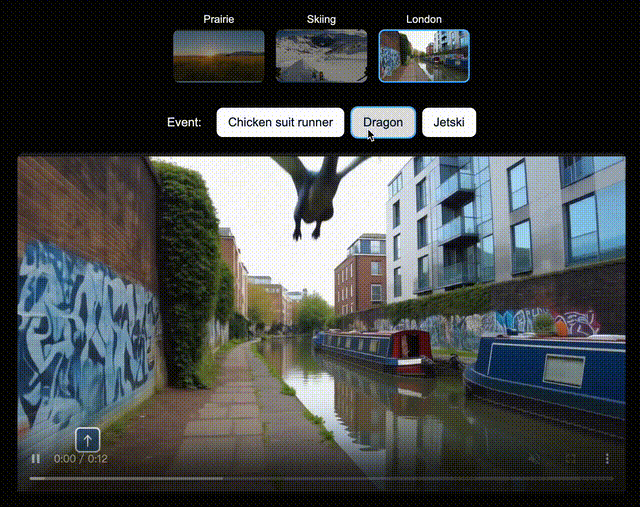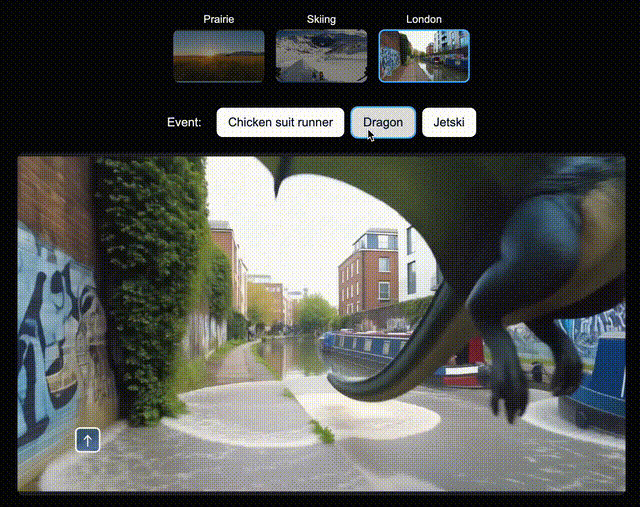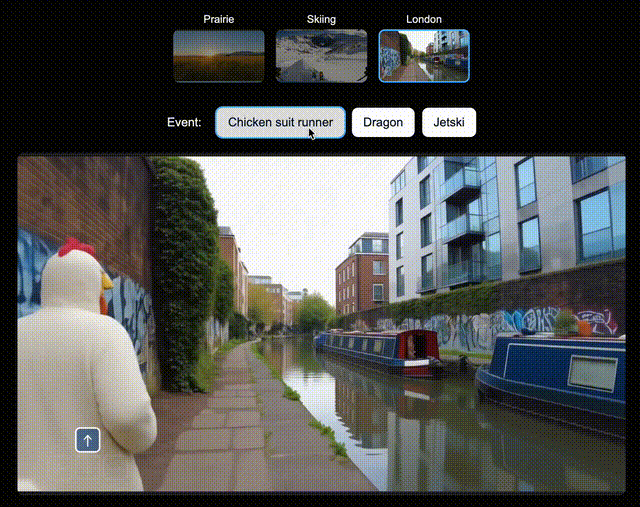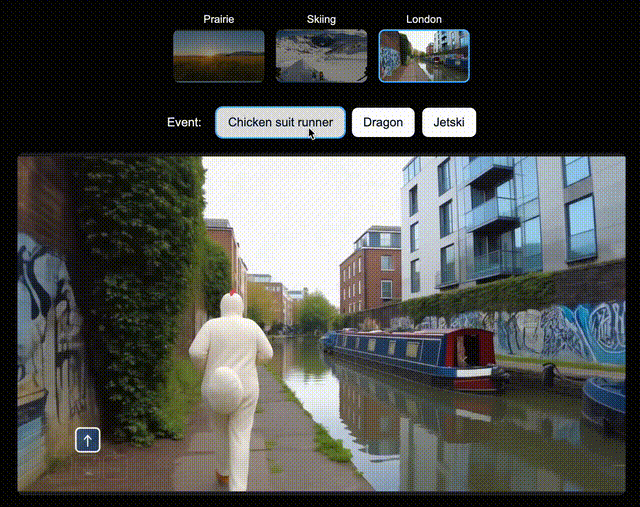
左右滑动查看
为了验证Genie 3所创世界,对未来AI智能体训练的兼容性,团队为新版SIMA智能体生成了多个世界。
在每个世界中,都指示该智能体去达成一系列特定目标。
它会通过向Genie 3发送导航指令,来尝试完成任务。假设让它走向和面机和面包架,Genie 3都能指示智能体去完成目标。

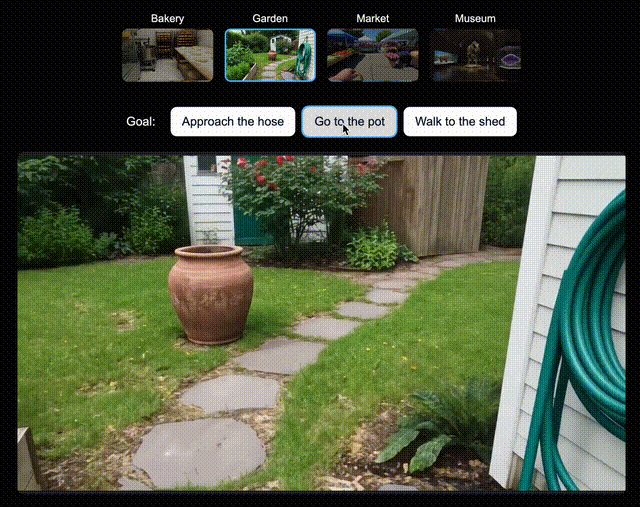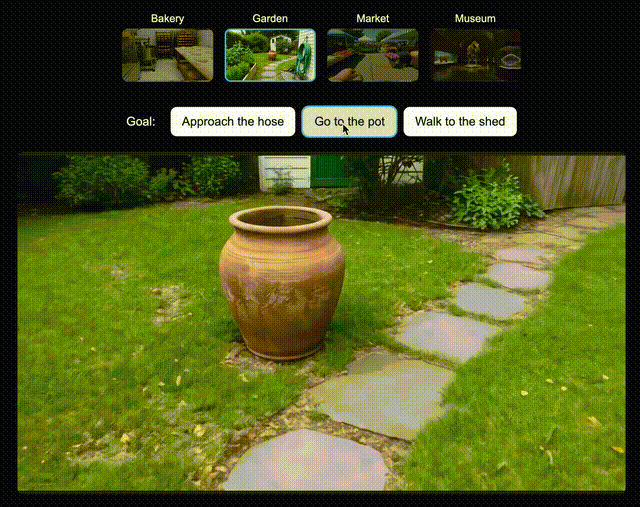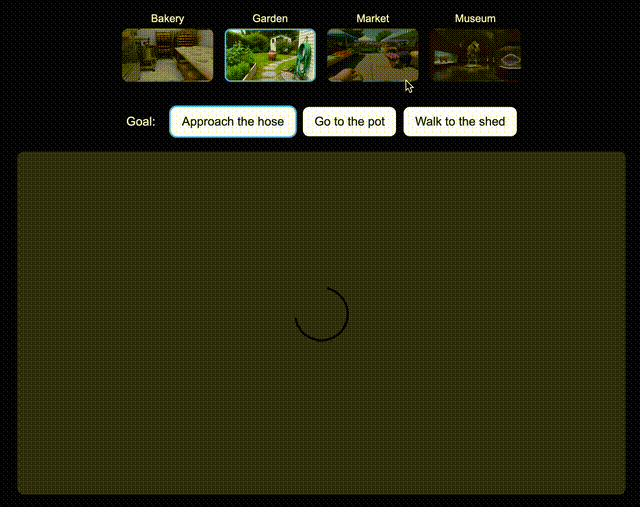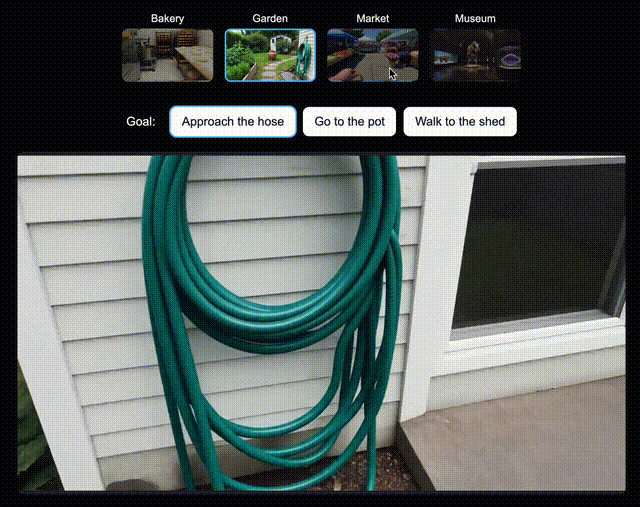
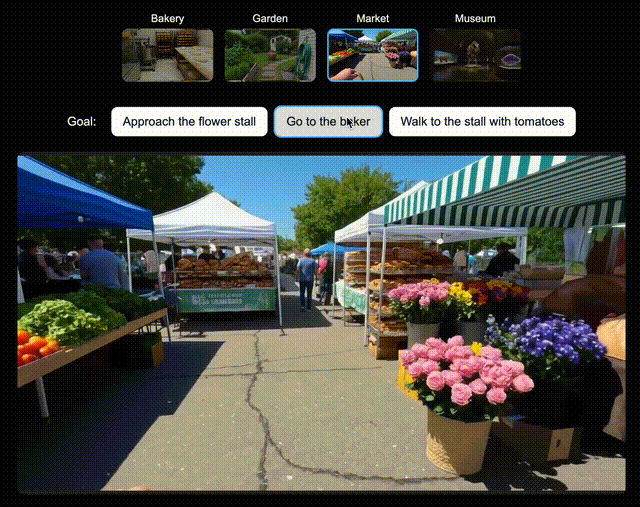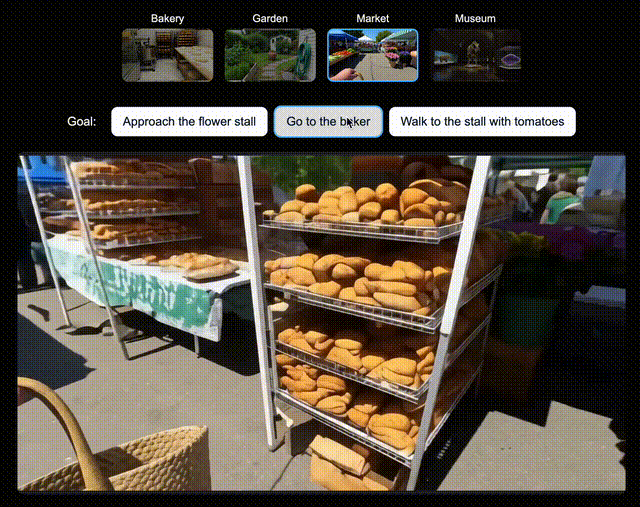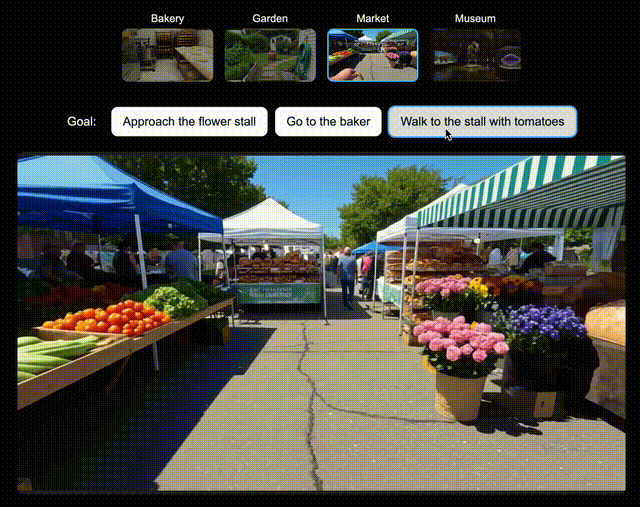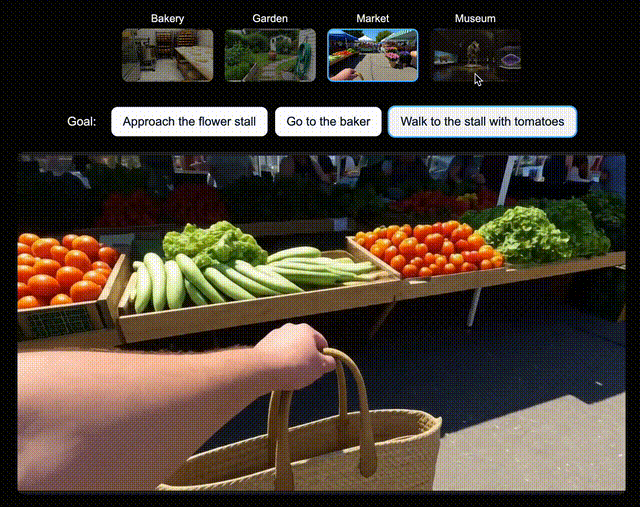

左右滑动查看
与所有其他环境一样,Genie 3并不知道智能体的目标,它只是根据智能体的行为来模拟世界的未来走向。
由于Genie 3能够保持一致性的能力,现在可以执行更长的动作序列,以实现更复杂的目标。



左右滑动查看
尽管Genie 3拓展了世界模型的能力边界,但也存在一定的局限性,具体包含以下5点:
-
有限的动作空间
虽然由「提示词驱动的世界事件」允许广泛的环境干预,但这些干预不一定由AI智能体自身执行。AI智能体目前能直接执行的动作范围仍然有限。
-
与其他智能体的交互和模拟
在共享环境中精确模拟多个独立智能体之间的复杂互动,仍是研究领域的一大挑战。
-
真实世界位置的准确表征
Genie 3 目前还无法以完美的地理精度模拟真实世界的地点。
-
文本渲染
通常只有在输入的世界描述中提供了文本信息时,模型才能生成清晰易读的文字。
-
有限的交互时长
模型目前可支持数分钟的连续交互,而非长达数小时的持续互动。
尽管如此,Genie 3是世界模型发展的一个重要里程碑。
它能为教育和培训创造新机遇,帮助学生学习、助力专家积累经验。
它不仅能为机器人和自主系统等 AI 智能体提供广阔的训练空间,还能用于评估智能体的性能并探究其弱点。
在迈向AGI征途中,Genie 3描绘了一个由AI加持,充满交互与创意的世界,一个世界模型全新的未来。
再次狙击Genie 3之后,OpenAI团队Steven Heidel献上彩虹屁,「真是一个见证AGI时刻」。

神仙打架的好戏,正式开演。
(文:新智元)