

智东西8月6日消息,昨夜,谷歌DeepMind宣布推出通用世界模型Genie 3,首个可实时交互世界模型来了。
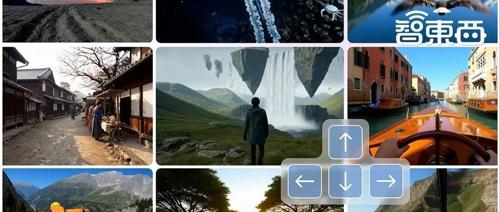
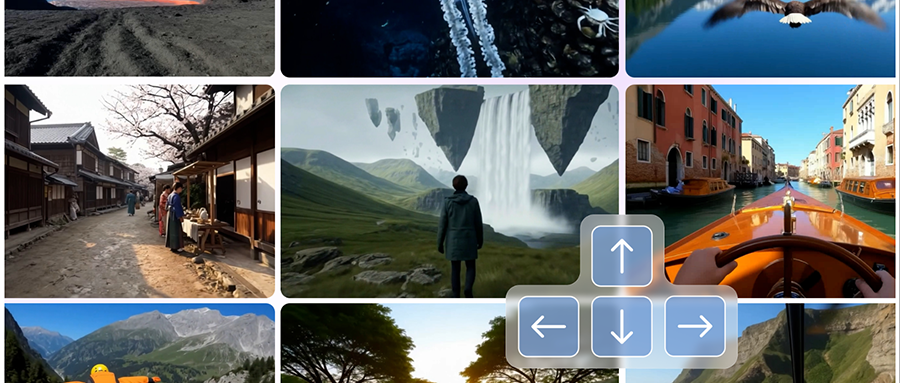
基于文本提示,Genie 3可以允许用户以每秒24帧的速度,以720p的分辨率生成长达数分钟的交互式3D环境,Genie 2仅能生成10到20秒。

去年年底,谷歌DeepMind发布能生成各种可控制动作、可玩3D环境的大型基础世界模型Genie 2,此次发布的Genie 3,是其第一个允许实时交互的世界模型,在一致性和真实感方面相较前代有提升。如下面的示例中,Genie 3生成内容的机器人本体、周围环境质感更佳:


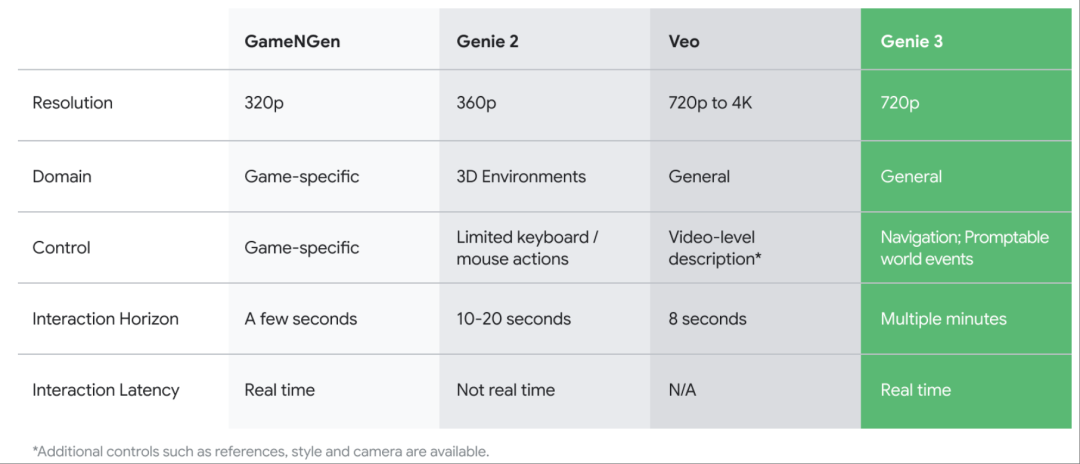
此次,谷歌DeepMind宣布以有限研究预览版的形式发布Genie 3,为一小部分学者和创作者提供早期使用机会。在博客的致谢部分,还出现了被谷歌挖来的OpenAI视频生成工具Sora的联合负责人之一蒂姆·布鲁克斯(Tim Brooks)。




1、模拟世界的物理特性:复杂环境没有失真
下面的案例中,3D世界在表现水蔓延到马路上、海平面、灯光映照在水面的光影变化等都没有失真。

2、模拟自然世界:动植物表现逼真
Genie 3可以创建从动物到植物等各种复杂且充满活力的生态系统,如下面演示的庭院、湖泊、海底世界等。

3、动画和小说建模:动画人物活灵活现
Genie 3还能创建动画场景以及动画人物,动画人物的色彩、形象都符合整体环境。

4、突破时空界限:探索未知地点和过去时刻
Genie 3创建的内容可以超越地理和时间界限,探索未知的地方或者过去的时代,如下面的翼装飞行、山地骑车等场景。

除了导航输入之外,Genie 3还支持基于文本的交互形式,谷歌DeepMind的博客将其称为可提示的世界事件。也就是说,其可以改变已经生成的世界,如改变当前世界的天气条件、引入新物体等。
这种能力还扩展了模型对反事实或假设场景的学习,Agent可以从经验中学习这些场景来处理意外情况。
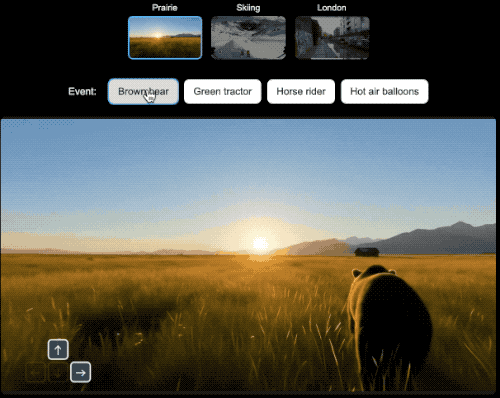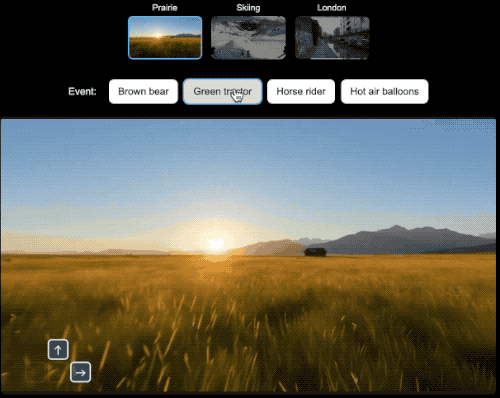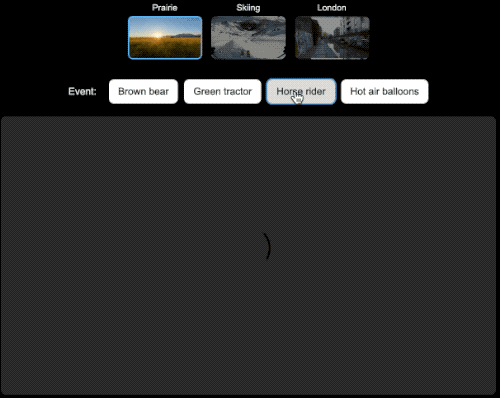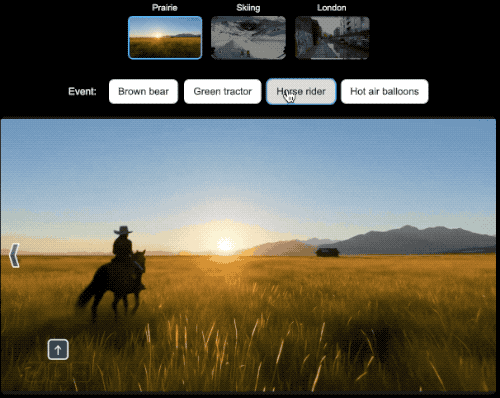
此外,为了测试Genie 3创建的世界与未来Agent训练的兼容性,研究人员为用于3D虚拟场景的通用Agent SIMA生成了世界。
在每个世界中,其都指示Agent完成不同任务,并通过向Genie 3发送导航操作来实现这些目标。与其他环境一样,Genie 3并不知道代理的目标,而是根据代理的操作来模拟未来。

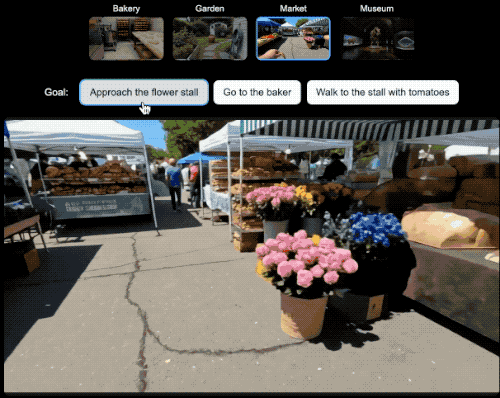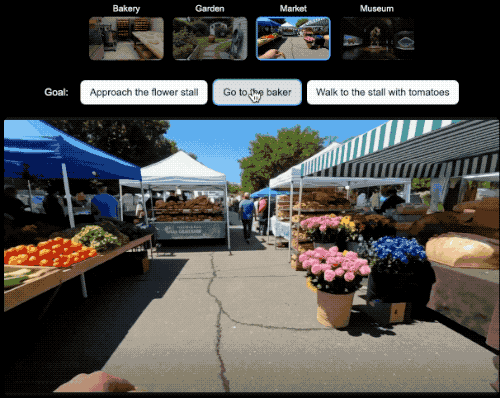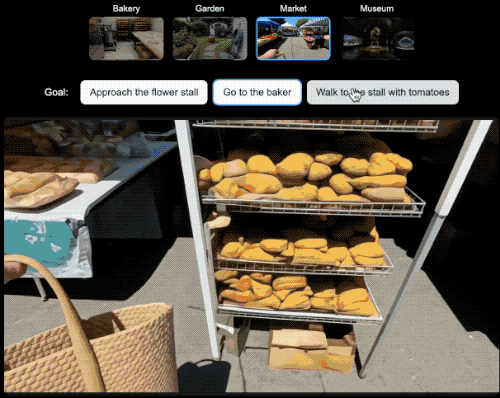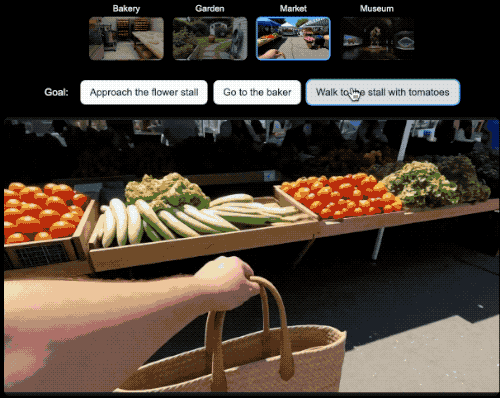
在具身Agent的研究领域,研究人员就可以选择一个世界设定,然后选择希望Agent实现的目标并观察它如何实现目标。
基于Genie 3在保持一致性方面的优势,现在其可以执行更长的操作序列,从而实现更复杂的目标。
想要使AI生成的世界具有沉浸感,生成内容必须在很长一段时间内保持物理一致性。然而,自回归生成环境通常比生成完整视频更难,因为误差往往会随着时间的推移而累积。
Genie 3的环境在几分钟内仍能保持基本一致,视觉记忆可以追溯到一分钟前。如下图所示的“建筑物左侧的树木”,在互动过程中始终保持一致:
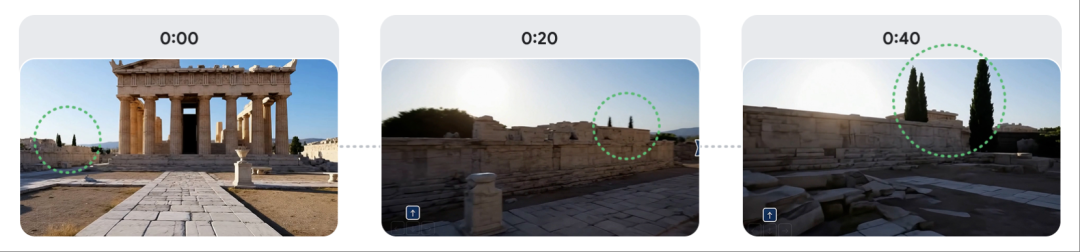
其博客提到,Genie 3的一致性是一项新兴能力。NeRF和高斯分布等方法在实现一致的可导航3D环境同时,需要依赖于提供明确的3D表示,相比之下,Genie 3生成的世界是根据世界描述和用户操作逐帧创建的,因此生成内容更为丰富、真实。
谷歌DeepMind的博客中也提到了Genie 3目前的局限性:
行动空间有限:尽管可触发的世界事件允许进行广泛的环境干预,但它们不一定由Agent本身执行,Agent可直接执行的操作范围目前受到限制;
与其他Agent的交互和模拟:准确建模共享环境中多个独立Agent之间的复杂交互仍然是一个持续的研究挑战;
准确表示真实世界的位置:Genie 3目前无法以完美的地理精度模拟真实世界的位置;
文本渲染:通常只有在输入世界描述中提供时才会生成清晰易读的文本;
交互时长有限:该模型目前支持几分钟的持续交互,无法支持长达数小时的交互。
从目前的应用场景来看,Genie 3或许可以为机器人和自主系统等提供训练空间并评估其表现。未来,这项技术或许能在我们迈向AGI的过程中发挥关键作用。
(文:智东西)