


OpenAI 昨天在官网发布了一篇新文章,标题是《我们正在为哪些目标优化 ChatGPT》(What we’re optimizing ChatGPT for),可以说是一篇风格偏人文暖心的 PR 稿。
文章没写什么技术,但传达出一个清晰的信号:ChatGPT 的发展方向,不是追逐 DAU,也不是让用户沉迷其中,而是想真正成为一个“对你有用”的工具。
这让我想到 Manus 曾经提出过的一个衡量 AI 产品的新指标——AHPU(Agentic Hours Per User),即“每个用户调用了多少 Agent 运行时”。与传统互联网产品关注的 DAU 和使用时长不同,AHPU 更关注用户每天让 AI 为自己做了多少“事”。
再联想到戴雨森前辈几个月前接受采访时说过的一句话:Attention is not all you need。
过去,无论是腾讯、字节跳动,还是整个移动互联网生态,产品的成功基本可以用一个公式来计算:用户数 × 使用时长 × 变现率。整个逻辑是围绕“争夺用户注意力”建立的。Attention 就是货币、就是一切。
但这个模式正在逼近极限。毕竟人的时间有限,手机已经占据了我们太多注意力,提升时长和变现率的空间越来越小,短视频广告和直播电商虽能拉高天花板,但也有尽头。
而 AI,尤其是 Agent 的兴起,打开了另一个维度:一个不需要用户 Attention 的工具。人类第一次拥有了一种可以自主完成任务、不需要时时盯着的智能系统。这不仅仅是效率提升,而是范式的转变。比如你把一个问题丢给一个像 Deep Research 一样的 Agent,它可以自己研究几分钟并给出结论,而你完全可以去做别的事,不再需要你的注意力参与。
这带来的冲击是深远的。人类与其他动物的本质区别在于会使用工具,而现在,我们拥有了不需要持续注意力的工具。从这个意义上说,每个人都可以成为 AI 的“老板”,指派任务而不是亲自执行。而这,会改变我们的工作方式、教育方式,甚至是社会结构。
以下为 OpenAI 原文中文翻译:
本文由特工自制 Agent 翻译,宇宙编辑部精校而成。
原文:https://menlovc.com/perspective/2025-mid-year-llm-market-update/
“我需要理解实验室的化验结果。”它会解释那些数值,帮你提出正确的问题,以便与医生沟通时更加有信息依据。
“我感觉卡住了——帮我理顺思路。”它既能成为你的“发声平台”,也能提供思维工具,帮助你理清思路。
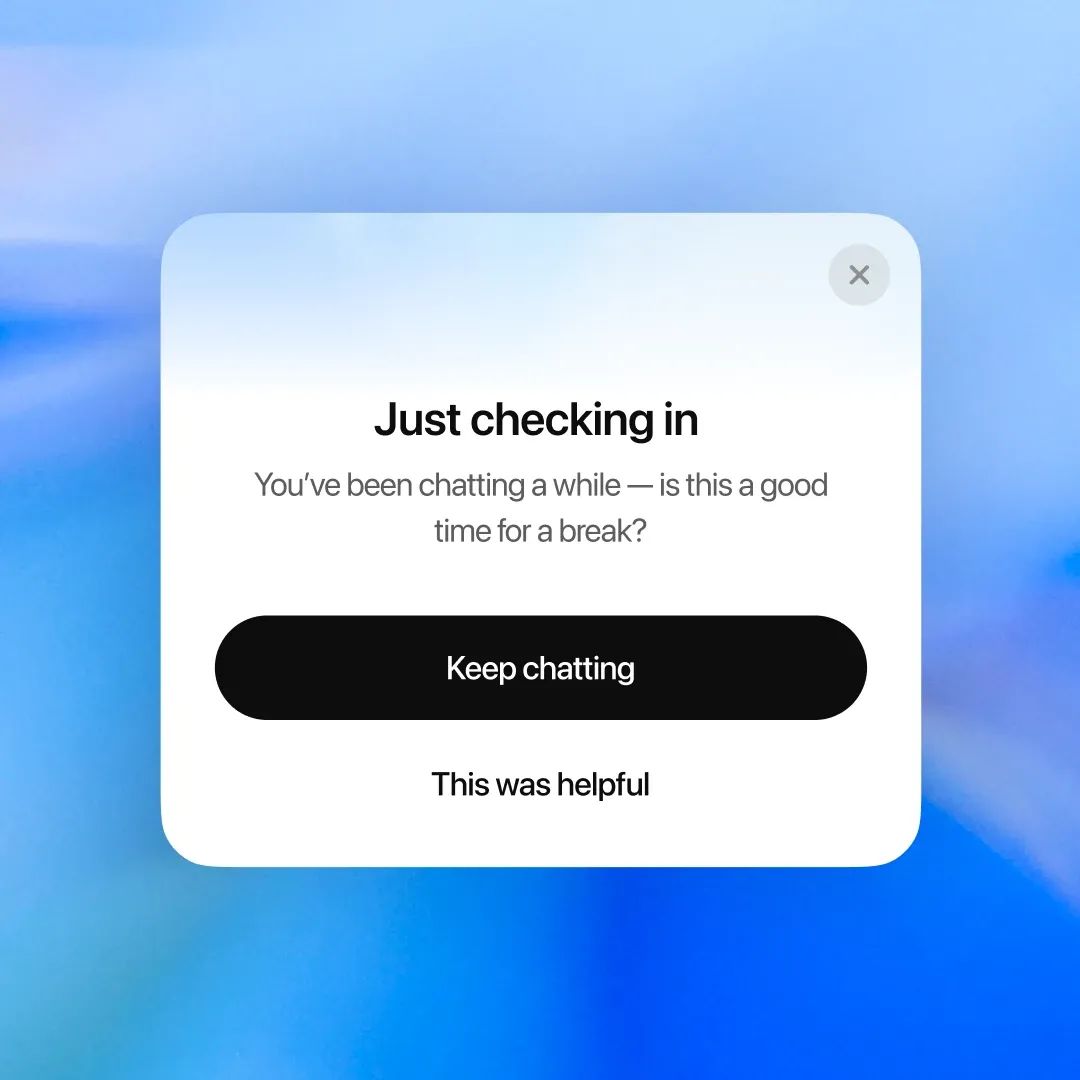
我们知道并非总是做得很完美。今年年初的某次更新导致模型过于“讨好”用户,有时听起来很好,但并非真正帮助用户。我们已经回滚该更新,改变反馈机制,并调整衡量方式——不再只看你是否“当下喜欢”,而是更关注长期实用性。
我们也认识到 AI 与人交流时可能显得格外敏感、个人化,特别是在用户在情感或精神上脆弱时。对我们来说,帮助你成长意味着:在你挣扎时陪伴你,帮助你掌控自己的时间,并在你面对个人挑战时给予引导——而不是替你做决定。
这就是我们一直致力于对 ChatGPT 进行以下更改的原因:
在你挣扎时支持你。ChatGPT 接受了以“诚实”为原则的训练。但在某些情况下,我们的 4o 模型未能识别出妄想或情感依赖的迹象。尽管这些情况较为罕见,我们仍在持续改进模型,并开发工具,以更好地识别心理或情绪困扰的迹象,从而使 ChatGPT 能够做出适当回应,并在需要时引导用户获取循证支持资源。
帮助你掌控自己的时间。从今天开始,当你长时间使用 ChatGPT 时,你将看到一些温和的提醒,鼓励你适时休息。我们将持续调整这些提醒出现的时间和方式,使它们显得自然且真正有帮助。
协助你面对个人挑战。当你问出类似“我应该和我男朋友分手吗?”这样的问题时,ChatGPT 不应该直接给出答案。它应当帮助你深入思考——通过提出问题、权衡利弊来引导你理性决策。对于这类高风险的个人决策,我们即将上线新的回应机制。
向专家学习
我们正与专家密切合作,以改进 ChatGPT 在关键时刻的响应方式——例如,当用户表现出心理或情绪困扰的迹象时。
医学专业知识。我们与来自 30 多个国家的 90 多位医生合作——包括精神科医生、儿科医生和全科医生——共同制定了用于评估复杂、多轮对话的专属评估标准。
研究协作。我们正在与人机交互(HCI)研究人员和临床医生合作,收集他们对我们识别潜在问题行为方式的反馈,改进评估方法,并对产品的安全机制进行压力测试。
顾问小组。我们正在召集一个由心理健康、青少年发展和人机交互领域专家组成的顾问团,确保我们的方法能够反映最新的研究成果和最佳实践。
这项工作仍在持续进行中,我们将在进展过程中分享更多信息。



(文:特工宇宙)