


前言
在之前的文章(https://zhuanlan.zhihu.com/p/16266665042)中,我们探索了近几代NVIDIA GPU执行LDG指令时的预取(Prefetch)行为。在本篇文章中,我们将会进一步探索cp.async指令(https://docs.nvidia.com/cuda/parallel-thread-execution/index.html?highlight=cp%2520async#data-movement-and-conversion-instructions-cp-async)的Prefetch行为。考虑到许多同学都是基于CUTLASS CuTe的封装使用cp.async,而非直接使用内联PTX,本文将会以CUTLASS CuTe作为编程工具,对cp.async的Prefetch行为进行研究,若读者对于CUTLASS CuTe中的Copy抽象并不熟悉,建议读者先阅读reed大佬的博客专栏(https://www.zhihu.com/column/c_1696937812497235968)以及笔者之前介绍CUTLASS CuTe TiledCopy的文章后,再来阅读本文:
注:本文中的实验代码已上传至Github:
https://github.com/HydraQYH/cuda_prefetch_experiment/blob/master/cp_async_prefetch_4.cu
读者可自行下载并编译运行该代码,编译该代码所依赖的CUTLASS版本为3.8.0。
基础实验
实验场景说明
在上一篇文章中我们了解到,Prefetch行为主要发生在H20 GPU(sm_90)上,因此,在本文中,我们仅对H20 GPU上的cp.async指令(确切的说是LDGSTS指令)进行Prefetch行为分析。
在上一篇文章中,我们对于具有不同Access Size的LDG指令都进行了Prefetch行为的验证,但是在本篇文章中,由于我们需要使用CuTe作为编程工具,而在CuTe中,针对cp.async指令的封装,较为常用的是SM80_CP_ASYNC_CACHEGLOBAL(https://github.com/NVIDIA/cutlass/blob/afa1772203677c5118fcd82537a9c8fefbcc7008/include/cute/arch/copy_sm80.hpp#L74),这个CopyOperation封装的cp.async指令会bypass L1 Cache,因此它需要每个CUDA thread都拷贝16Byte的数据(原因详见:CUDA C++ Best Practices Guide 12.8 documentation(https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/index.html#asynchronous-copy-from-global-memory-to-shared-memory)),CuTe(https://github.com/NVIDIA/cutlass/blob/afa1772203677c5118fcd82537a9c8fefbcc7008/include/cute/arch/copy_sm80.hpp#L80)在编译期会对这个条件做检查,代码如下:
static_assert(sizeof(TS)==16,"cp.async sizeof(TS) is not supported");
因此,在本篇文章中,我们仅分析Access Size为128bit,bypass L1 Cache的cp.async指令的Prefetch行为。
注:本文的附录中会给出实验代码链接,若读者想要验证其它GPU架构或其它cp.async指令的Prefetch行为,可自行下载该代码并加以修改进行实验。
实验内容说明
明确实验场景后,实验内容自然就会变得简单清晰。我们模仿上一篇文章中的实验,Launch一个quarter warp(8 CUDA threads),通过循环执行4条cp.async指令,每条指令加载128Byte(8*16Byte)的数据到Shared Memory中,4条指令加载连续的512Byte的数据。我们基于Nsight Compute(ncu)的Memory Workload Analysis(https://docs.nvidia.com/nsight-compute/ProfilingGuide/index.html#memory-tables)分析这个kernel的访存行为,如图1所示:
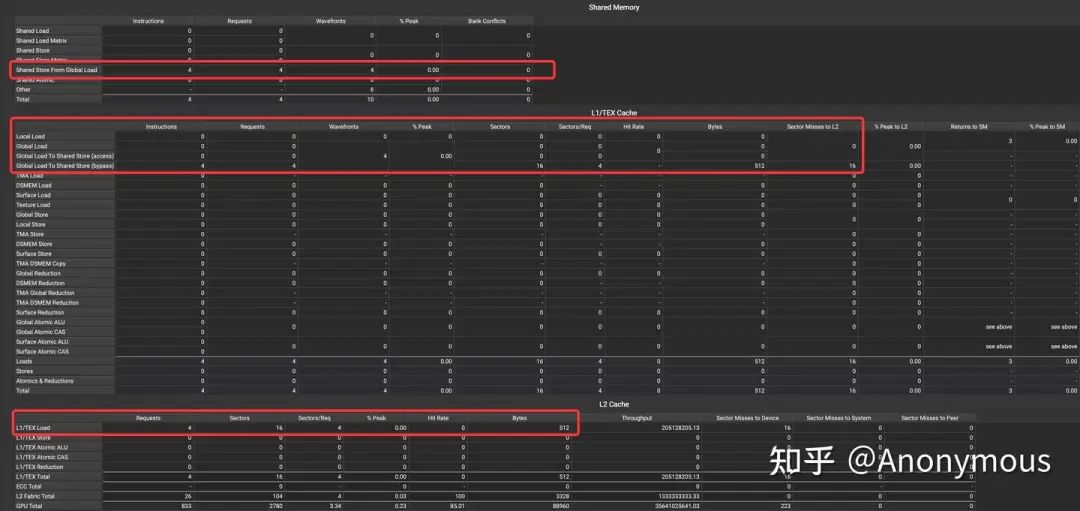
可以观察到,在L2 Cache上,请求的数据量和程序的运行逻辑是一致的。回过头来,观察CuTe所封装的cp.async:
TS const* gmem_ptr = &gmem_src;uint32_t smem_int_ptr = cast_smem_ptr_to_uint(&smem_dst);asm volatile("cp.async.cg.shared.global.L2::128B [%0], [%1], %2;\n":: "r"(smem_int_ptr),"l"(gmem_ptr),"n"(sizeof(TS)));
可以发现,这条cp.async指令使用了.L2::128B这个qualifier,但似乎并未导致实际的Prefetch行为。当然,有上一篇文章的经验,我们对此并不感到意外,查阅PTX文档(https://docs.nvidia.com/cuda/parallel-thread-execution/index.html?highlight=cp%2520async#data-movement-and-conversion-instructions-cp-async)可以发现,在cp.async这个指令中,.level::prefetch_size这个qualifier还可以设置为.L2::256B,在上一篇文章中,为数不多的能够发生Prefetch的几种情况都是依赖于设置.level::prefetch_size为.L2::256B,因此,我们修改了CuTe的代码,并重新编译运行程序,得到如图2所示的结果:
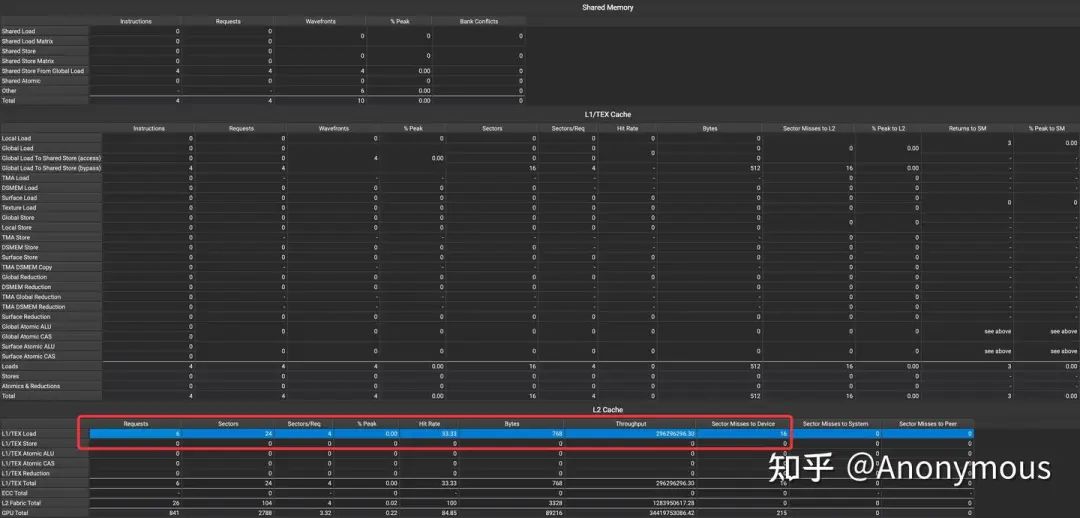
由图2可知,将.level::prefetch_size设置为.L2::256B后,L2 Cache的Requests从4个增加到了6个,额外Prefetch了256Byte的数据,Hit Rate也显示有1/3的Requests命中了L2 Cache。虽然预取行为的确发生了,但是我们还是不禁要问,为什么Requests的数量是6个,而不是8个,毕竟,我们执行的每一条LDGSTS指令都带有Prefetch Modifier,如图3所示:
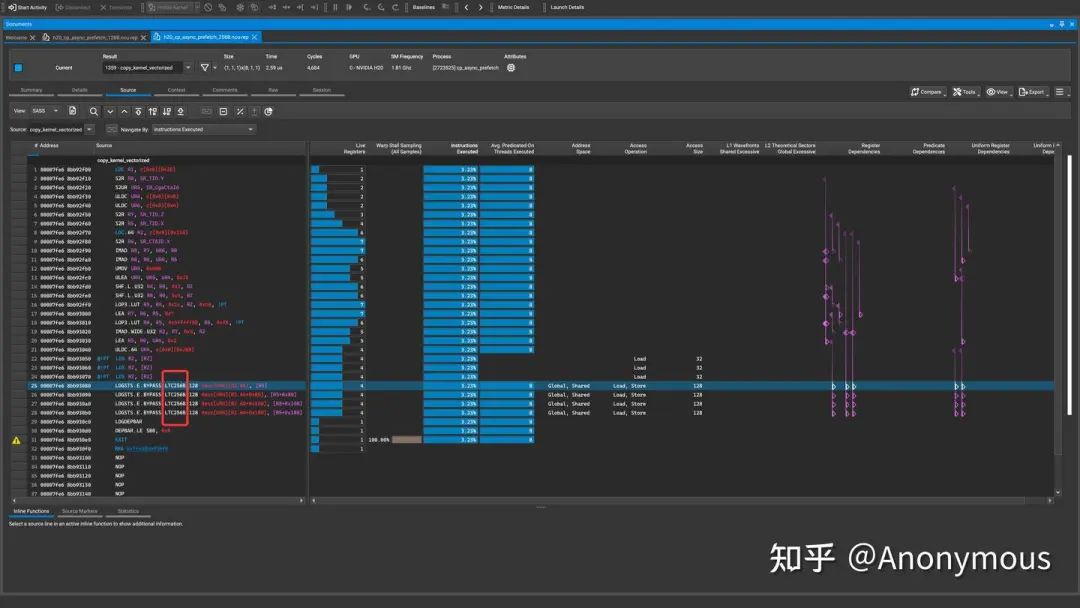
对于这个现象,我们展开了进一步的研究。我们调整了循环的次数,以控制实际执行的LDGSTS指令的数量,我们对比了执行1~4次LDGSTS指令的情况,并将关键的统计数据整理成为如下表格:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
显然,在四次循环中,只有第一次循环和第三次循环执行的LDGSTS指令导致了额外的Prefetch Requests,关于其原因,我们推测是cp.async指令的Prefetch行为对Alignment有着更加严格的要求,可能为256Byte,而恰好第一次和第三次循环满足Alignment的要求。
Scale Up实验
实验配置说明
为了进一步探索如何在实际应用中发挥Prefetch的能力,我们对基础实验进行了Scale Up。我们launch了一个较大的grid进行异步数据拷贝,与上一篇文章中的应用实验类似,我们对数据进行分组,每组数据由一个quarter warp进行拷贝,我们令每组数据的大小为512Byte,与基础实验一样,由quarter warp通过循环执行四次cp.async指令完成拷贝。
在代码实现上,我们首先利用了CUDA Cooperative Group(https://developer.nvidia.com/blog/cooperative-groups/)所提供的tiled_partition(https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html?#tiled-partition)功能,对grid以quarter warp为粒度进行划分。同时,我们利用CuTe的Tensor抽象(https://github.com/NVIDIA/cutlass/blob/v3.8.0/media/docs/cute/03_tensor.md),通过tiled_divide对数据Tensor进行划分,并以quarter warp的meta_group_rank作为坐标,获取特定quarter warp所对应的需要拷贝的目标Tensor分块。
我们将grid的大小设置为32768,thread block(cta)的大小设置为128,因此,我们一共launch了32768*(128/8)个quarter warp,每个quarter warp拷贝512Byte的数据,整个kernel一共拷贝256MiB的数据。
我们将.level::prefetch_size分别设置为.L2::128B和.L2::256B,对比L2 Cache上请求的数据量,如图4和图5所示:
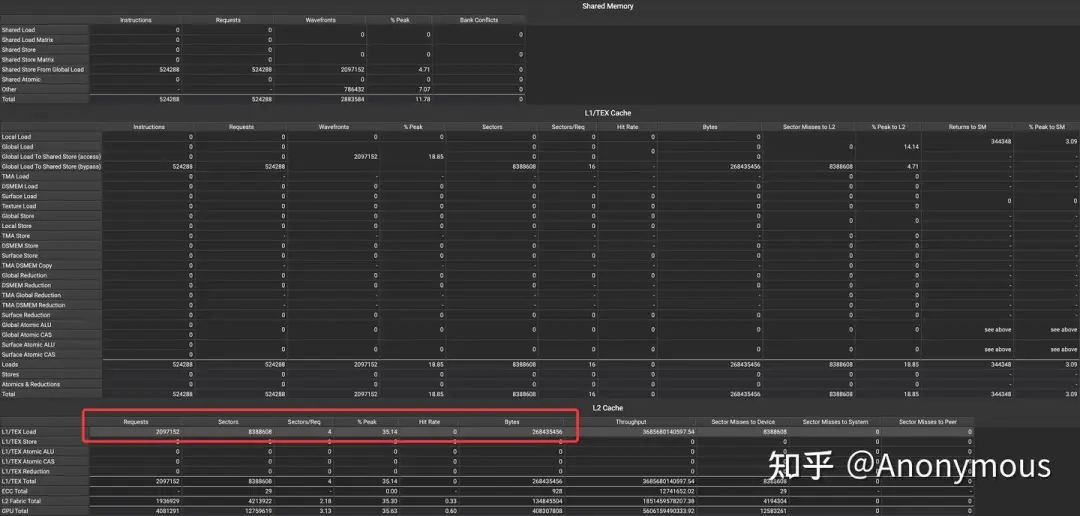
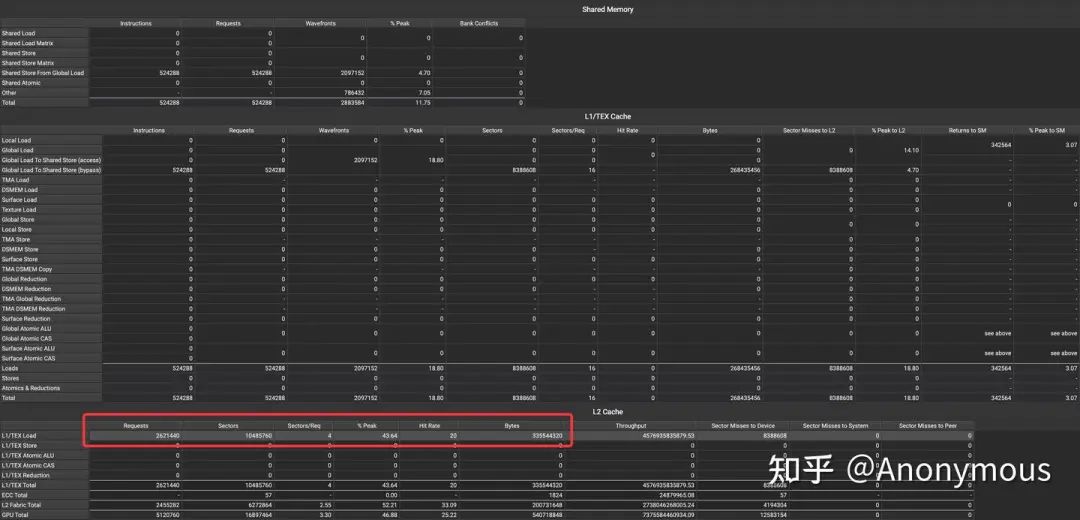
由图4可见,将.level::prefetch_size设置为.L2::128B时,L2 Cache上请求的数据量与程序的运行逻辑是完全一致的,kernel运行过程中并无Prefetch行为,而在图5中,将.level::prefetch_size设置为.L2::256B时,L2 Cache上发生了Prefetch行为,请求的数据量增加了25%(335544320 / 268435456 = 1.25)。
虽然.level::prefetch_size设置为.L2::256B时确实发生了Prefetch行为,但是我们还是发现了一些与基础实验不一致的地方。在基础实验中,单个quarter warp也是执行的4条cp.async指令,其中有两条指令都会导致额外的Prefetch行为,请求的数据量是标准数据量的1.5倍,但是在Scale Up实验中,请求的数据量仅为标准数据量的1.25倍,似乎Prefetch的行为被进一步的压缩了。
Warp Level实验
对于请求的数据量不及预期的现象,我们展开了进一步的实验。首先,我们将Scale Up实验中的grid大小缩减为1,仅保留一个thread block,观察其Prefetch行为,如图6所示:
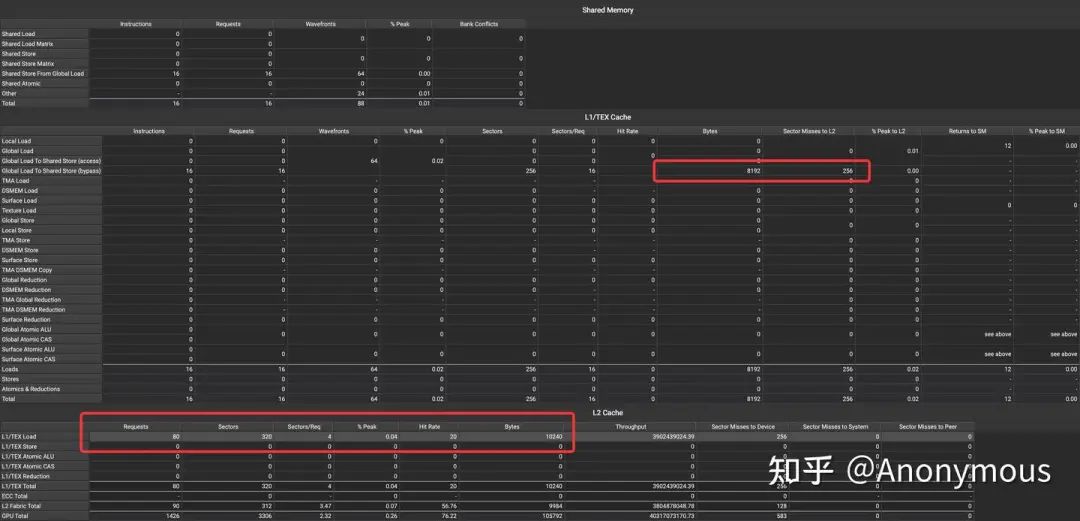
显然,仅保留一个thread block时,就可以复现请求的数据量不及预期的现象。我们进一步缩减thread block内warp的数量,以观察哪些warp没有按照我们的预期进行Prefetch,我们将关键数据整理为如下表格:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
每个warp包含4个quarter warp,每个quarter warp请求512Byte的数据,不进行Prefetch时,一个warp共请求2048Byte的数据。启用Prefetch时,每个quarter warp额外请求256Byte数据,因此,一个warp共请求3072Byte的数据。
从表格所展示的数据中我们可以发现,当warp的数量<=2时,Prefetch行为会正常的发生,但是当warp的数量进一步增加时,新增的warp不会进行Prefetch。我们进一步做了一个更加大胆的实验,我们仍然launch 4个warp,但是仅有后两个warp执行cp.async指令,前两个warp不进行任何数据请求,代码如下:
if (cg.meta_group_rank() >= 8) {for (int i = 0; i < loop_count; i++) {Tensor thr_tile_S = g2s_thr_copy.partition_S(cg_loop_divide_tile_S(make_coord(_), i));Tensor thr_tile_D = g2s_thr_copy.partition_D(cg_loop_divide_tile_D(make_coord(_), i));// Copy from GMEM to SMEM via cp.asynccopy(g2s_tiled_copy, thr_tile_S, thr_tile_D);}// cp_async_fence();cp_async_wait<0>();}
实验结果如图7所示:
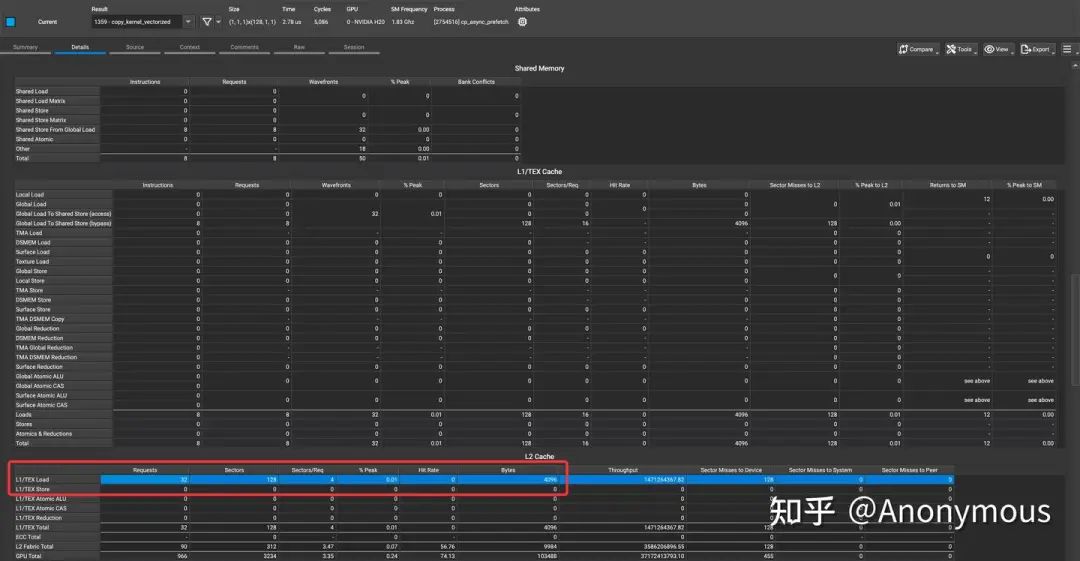
从图7中我们可以观察到,即便是仅有后两个warp请求数据,Prefetch行为也依然不会发生。GPU硬件似乎会进行一次“判断”,当warp id > 1时,忽略其Prefetch请求。我们推测,这可能是一种在硬件层面规避缓存抖动(Cache Thrashing)的机制,毕竟如果Prefetch的数据过多,肯能会影响到Cache中原有的数据。
Rescale Up实验
既然我们已经了解到,当一个thread block内的warp数量超过两个时,Prefetch行为可能会被硬件限制,那么我们可以对Scale Up实验的配置进行略微的修改,以达到同样的目的,我们将thread block的大小缩减为64,grid的大小增加一倍至65536,这样就能够达到与原实验相同的效果,又不会触发硬件层面的限制。然而,事实真的是这样吗?我们进行了实验,得到了如图8所示的结果:
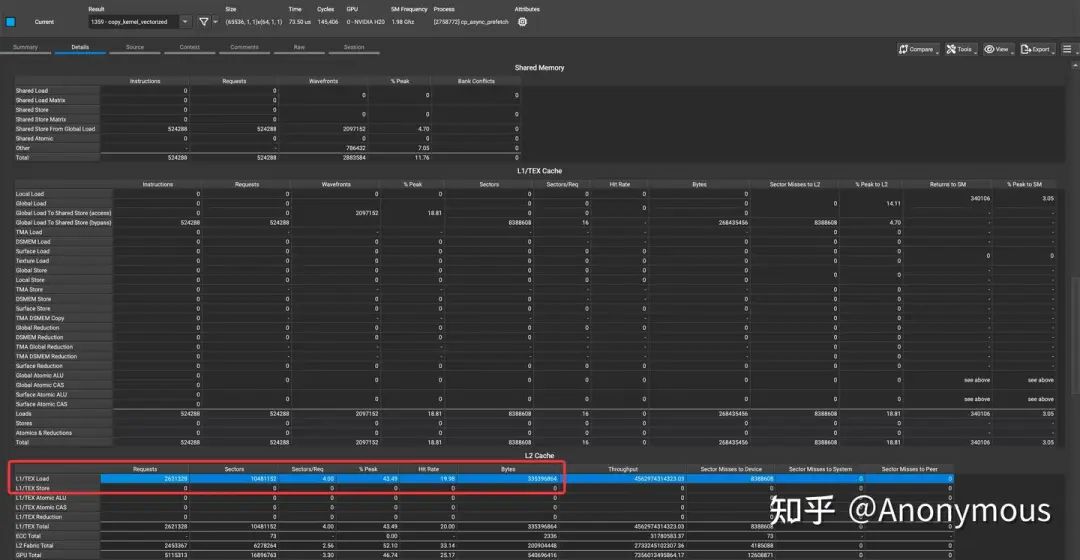
由图8可知,即便采用新的配置,Prefetch的数据量也仍无法达到我们的预期,Prefetch的数据量几乎与原配置相差无几。难道GPU硬件层面还有其它的机制用于限制Prefetch数据的数量吗?对于这个问题,我们也简单的展开了一些实验,这一次,我们将thread block的大小固定为64,转而launch不同数量的thread block,观察Prefetch的数据量,我们将结果整理为如下表格:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
除了launch 8个thread block这种情况,其它几种情况Prefetch的数据量均为基础数据量的25%。因此,我们推测GPU硬件可能具备某种动态限制Prefetch数据量的机制,这种机制大体能够将Prefetch的数据量控制在读取的基础数据量的25%左右,其目的仍然是为了避免Prefetch数据所导致的Cache Thrashing问题。
关于性能
我们探索Prefetch行为的最终目的其实是为了协助广大的开发者进行kernel性能的优化,因此,在本小节中我们回归主题,讨论性能。我们按照Rescale Up实验中的配置,对比了将.level::prefetch_size分别设置为.L2::128B和.L2::256B时的kernel性能,实验结果显示,这两个kernel的性能几乎是一致的,这似乎不太符合预期,但实际上,如果我们仔细观察ncu的Profile结果,就可以发现,这个结果是合理的,因为,这个kernel的主要性能瓶颈源自于GPU显存带宽,无论是否进行Prefetch,从GPU显存读取到L2 Cache的数据量是一致的,如图9所示:
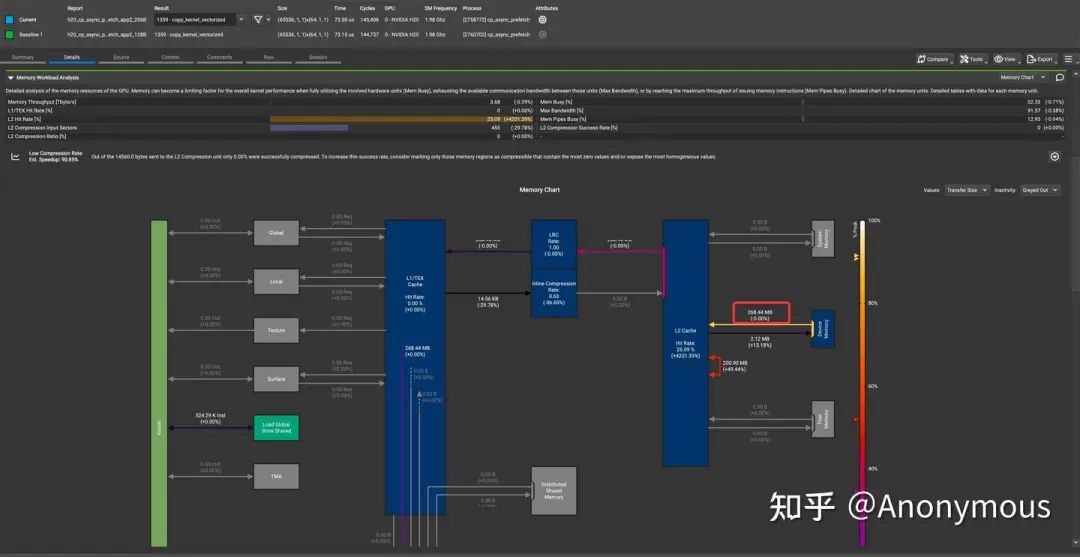
因此,这两个kernel的性能也是一致的,这是符合预期的。
那么,Prefetch的优势会体现在哪里呢?我们可以简单的思考一下,kernel的执行逻辑是每个quarter warp通过循环读取连续的数据,当我们Prefetch数据时,先行执行的循环会提前发出针对后续数据的请求,在执行后续循环的时候,这些数据就有可能已经达到了L2 Cache,因此L2 Cache的命中率可能会提高,数据请求的延迟也可能会降低。从图9中我们确实可以观察到L2 Cache命中率的显著提升,对于数据请求的延迟,我们可以通过观察ncu中的Warp State Statistics中显示的Stall Long Scoreboard进行确认,如图10所示:
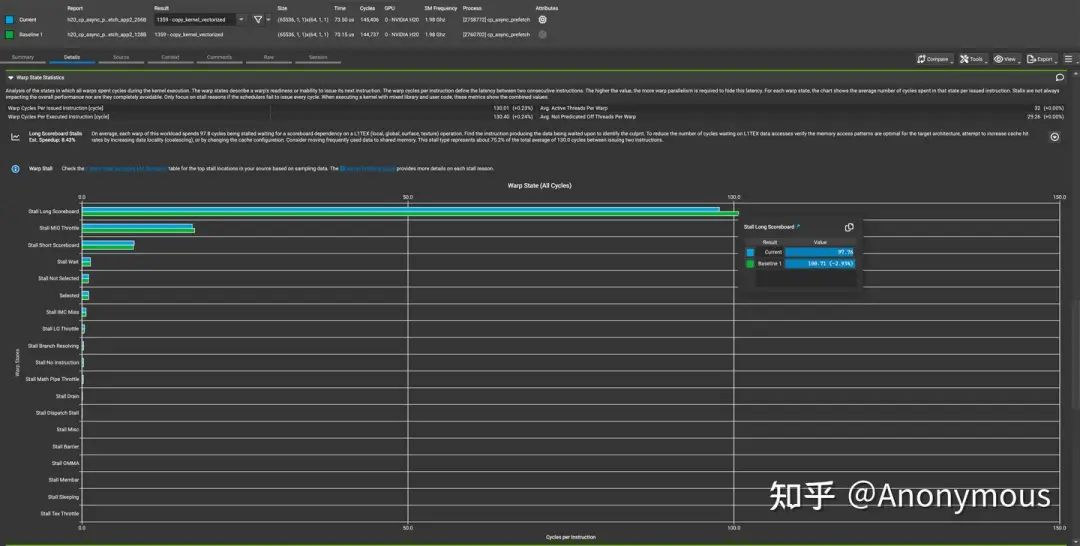
由图10可见,开启Prefetch时,Stall Long Scoreboard有略微的下降。但是由于主要的性能瓶颈并不在于访存请求的延迟,因此这部分的差异并不足以影响kernel的性能。
总结
在本篇文章中,我们以CuTe作为编程工具,分析了在H20 GPU(sm_90)上执行cp.async(LDGSTS)指令时的Prefetch行为。我们观察到,将cp.async的.level::prefetch_size设置为.L2::256B后,GPU硬件会进行Prefetch,Prefetch的数据量会由GPU硬件动态的控制在基础数据的25%左右。Prefetch可以一定程度的降低访存请求的延迟,因此Prefetch可以用于提升某些Latency Bound的kernel的性能。
希望本文的内容能够帮助到广大的开发者,如果对于本文的内容有任何的疑问,也欢迎大家在评论区积极的展开讨论。
– The End –

长按二维码关注我们
本公众号专注:
1. 技术分享;
2. 学术交流;
3. 资料共享。
欢迎关注我们,一起成长!
(文:GiantPandaCV)