
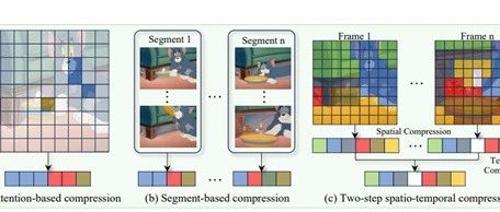
视频模型相比单图像输入需要对每一帧图像单独编码,这种序列化处理方式会导致token数量成倍增长,严重影响模型推理速度与扩展性。
传统的token压缩方法主要依赖于基于注意力机制的筛选,例如FastV、VisionZip、PLLaVA等方法虽然在图像领域取得了一定进展,但在视频理解中却暴露出语义覆盖不足,时序冗余无法处理等一系列问题。
为了解决这些难题,阿里巴巴通义实验室与南开大学计算机科学学院联合发布了创新压缩方法LLaVA-Scissor。

LLaVA-Scissor的核心在于SCC方法,这是一种基于图论的算法,用于识别token集中的不同语义区域。SCC方法主要通过计算token之间的相似性,构建一个基于相似性的图,并识别出图中的连通分量。这种方法不仅能够捕捉全局语义关系,还能避免因位置邻近性导致的局部偏见。
举个例子,假设我们有一组token,每个token都代表视频中的一个小片段。我们首先计算这些token之间的相似性,如果两个token在语义上很相似,就认为它们之间有一条连接线。通过这种方式,我们可以构建一个图,其中每个token是一个节点,相似的token之间有连接线。
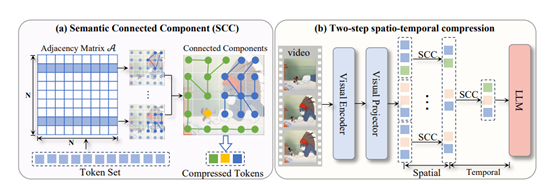
接下来,我们需要找出这个图中的“连通分量”。连通分量是指图中相互连接的一组节点,这些节点之间可以通过连接线互相到达。例如,如果token A和token B相似,token B和token C相似,那么A、B和C就构成了一个连通分量。我们为每个连通分量选择一个代表性的token,这样就可以用较少的token来代表整个视频的内容。
为了高效地计算连通分量,LLaVA-Scissor采用了一种近似方法。从所有token中随机选择一部分token作为样本,然后计算这些样本token与其他所有token之间的相似性。通过这种方式,我们可以快速识别出图中的连通分量。
如果有些token没有被包含在任何连通分量中,我们就将它们视为独立的连通分量。然后,我们根据每个连通分量中token的重要性对它们进行排序,以保留最重要的语义信息。
通过这种方式,SCC方法能够将token集分割成不同的语义区域,每个区域由一个代表性的token表示,从而将原始的token集压缩为更小的、更高效的表示。这种方法不仅能够有效地减少token的数量,还能保留视频内容的关键语义信息。
LLaVA-Scissor的两步时空压缩策略进一步优化了视频token的表示。这一策略分为两个阶段:空间压缩和时间压缩。
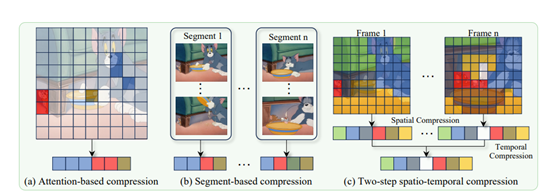
在空间压缩阶段,对于每个视频帧,我们使用SCC方法识别出该帧中不同语义区域,并为每个区域选择一个代表性的token。这些代表性的token能够有效地表示每个视频帧中的独特语义信息。然后,我们将所有帧的代表性token连接起来,形成一个时间序列。
在时间压缩阶段,我们再次应用SCC方法,去除时间序列中跨帧的语义区域的时间冗余,并进行进一步的融合。具体来说,我们识别时间序列中的连通分量,去除重复的语义信息,最终生成一组能够有效表示整个视频的非重叠语义token。
为了将压缩后的token与原始token进行融合,我们计算原始token和压缩token之间的相似性,并为每个原始token找到最相似的压缩token。然后,我们将每个原始token分配给最相似的压缩token,并进行平均融合,得到最终的压缩token。
这种方法不仅能够有效地减少token的数量,还能保留视频内容的关键语义信息,从而实现更高效的视频表示。
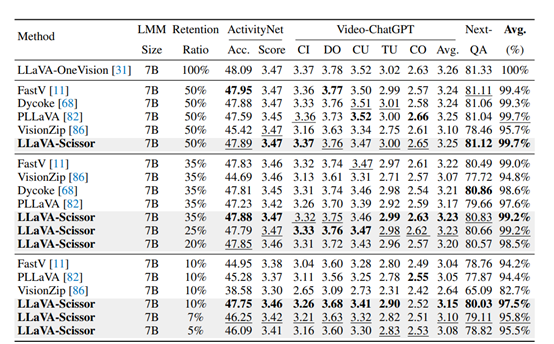
为了验证LLaVA-Scissor的有效性,研究人员在多个视频理解基准测试中进行了广泛的实验,包括视频问答、长视频理解和多选基准测试。实验结果表明,LLaVA-Scissor在各种视频理解基准测试中均优于其他token压缩方法,尤其是在低token保留率下,其性能优势更为明显。
在视频问答基准测试中,LLaVA-Scissor在50%的token保留率下,与原始模型的性能相当,而在35%和10%的token保留率下,LLaVA-Scissor的性能显著优于其他方法。
例如,在ActivityNet-QA数据集上,LLaVA-Scissor在35%的token保留率下,准确率达到了47.89%,而在10%的token保留率下,准确率仍能达到47.75%。这表明LLaVA-Scissor在保留关键语义信息方面具有显著的优势。
在长视频理解基准测试中,LLaVA-Scissor同样表现出色。在EgoSchema数据集上,LLaVA-Scissor在35%的token保留率下,准确率达到了57.94%,而在10%的token保留率下,准确率仍能达到57.52%。
这些结果表明,LLaVA-Scissor不仅能够在高token保留率下保持良好的性能,还能在低token保留率下有效地保留关键语义信息,从而实现更高效的长视频处理。
(文:AIGC开放社区)