

一个只有27M参数的小模型,在推理任务上击败了OpenAI的o3-mini-high。
这不是开玩笑——
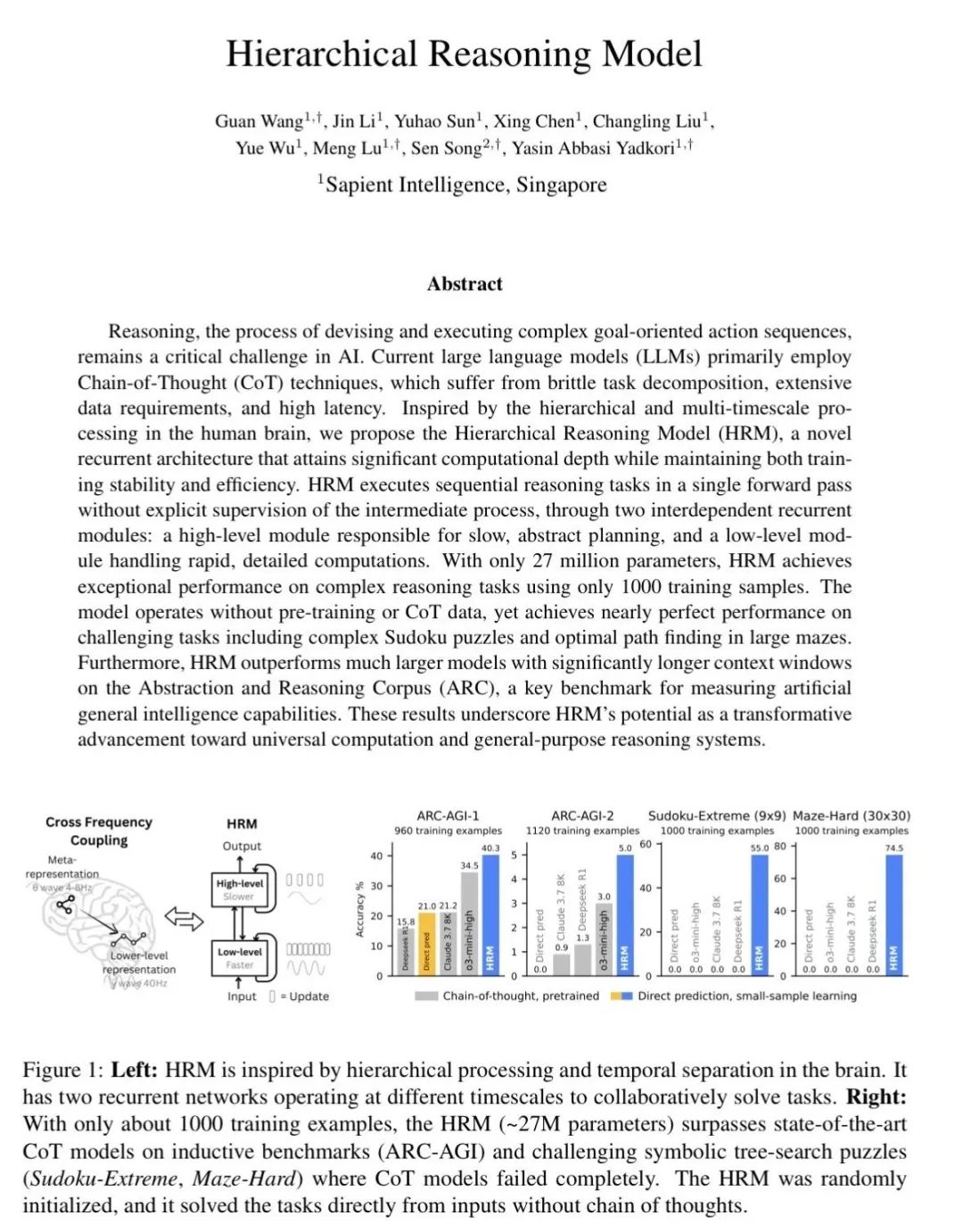
刚刚,清华大学的研究团队发布了一篇可能改变AI发展方向的论文,展示了他们的Hierarchical Reasoning Model(层次推理模型,简称HRM)如何用极少的参数和训练样本,在复杂推理任务上取得了令人震惊的成绩。
仅用1000个训练样本,这个27M参数的模型在ARC-AGI(一个测试AI通用智能的基准)上达到了40.3%的准确率,超过了o3-mini-high的34.5%和Claude 3.7的21.2%。
更疯狂的是,在极难的数独和30×30迷宫寻路任务上,HRM接近完美解决,而所有基于Chain-of-Thought的大模型全军覆没,0%准确率。
注意,是全军覆没。
硅谷知名投资人Deedy(@deedydas)直接称这是「AI领域最重要的论文之一」:
还是不敢相信这个清华毕业生的小实验室用40%的准确率解决了ARC-AGI,还能解决困难的数独和迷宫。我们还处在非常早期的阶段。
什么是ARC-AGI?
在解释这个突破之前,我还是先来介绍下什么是ARC-AGI。
(了解的朋友可以直接跳过)

ARC-AGI是一个专门设计来测试AI「真正智能」的测试集。它包含各种类似智商测试的谜题,要求AI从仅仅2-3个例子中提取和概括抽象规则。
想象一下,给你看几个<输入,输出>的网格对,比如输入是一个3×3的网格,有些格子是蓝色,输出是同样的网格,但所有蓝色格子都向右移动了一格。
然后给你一个新的输入网格,你需要推理出正确的输出。
这样的题目对正常的人类来说,可以说是相单简单轻而易举(不会做的需要自行反思去吧),但对AI来说极其困难,因为它需要真正的「理解」和「推理」,而不是简单的模式匹配。
模仿大脑的秘密
HRM的核心创新在于其模仿人脑的层次化处理结构。

这里让我用一个简单的比喻来解释。
想象你在解一道复杂的数学题。你的大脑会同时进行两种思考:
-
高层思考「我应该先求什么,再求什么」(整体策略)
-
低层思考「3×7等于21」(具体计算)
HRM正是模仿了这种机制,包含两个相互配合的模块。
高层模块像一个总指挥,负责制定整体策略,思考速度较慢。低层模块像一个执行者,负责快速完成具体计算。
这两个模块以不同的「节奏」工作——
低层模块快速运转多次后,高层模块才更新一次,就像你在做具体计算时,整体策略不会一直变化。
打破Transformer天花板
为方便理解HRM的突破性,这里对比一下当前主流的Transformer架构(ChatGPT、Claude、DeepSeek等模型都是基于该架构):
Transformer就像一个流水线,数据只能经过固定数量的处理步骤,每个词都分配相同的计算资源,无论简单还是复杂。
它需要把推理过程写成文字,一步步说出来(Chain-of-Thought的思维链)。
而HRM可以根据问题难度调整思考时间,在「脑海中」完成推理,不需要写出每一步。
高层制定策略,低层执行细节,真正实现了分工合作。
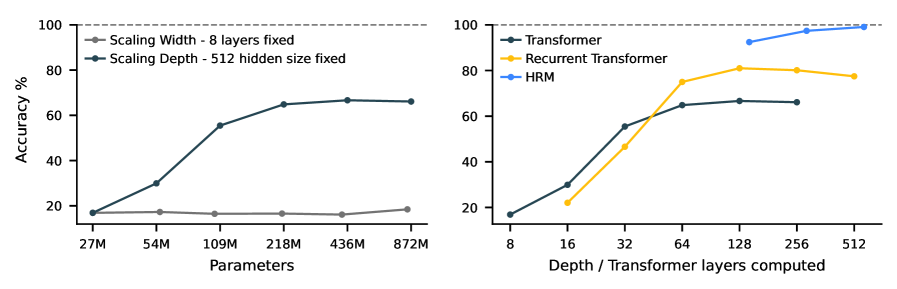
上图清楚地显示了差异:在解决极难数独时,增加Transformer的宽度(参数量)毫无帮助,而增加深度才有用。但标准架构会「饱和」——再深也没用了。HRM则完美利用了增加的深度。
网友直呼太野
看到这个论文的网友都震惊了。
Capx AI(@0xCapx)直接称太野了:
只有27M参数?太野了(wild)。

jason(@jasonth0)点赞感叹道:
这就是为什么我从来不相信「更大的模型=更好」的炒作……想象一下当他们扩展这个架构时会发生什么,效率可能会把当前的基准测试炸飞。

Maya Chen(@mayacfounder)给出高度评价:
这就是精益的样子。27M参数击败了建立在数十亿美元和万亿token数据集上的巨头。每个在超大型AI基础设施上烧钱的B2B创始人都应该研究这个。有时突破来自约束,而不是资本。
Causal Coder(@CausalCoder)发言犀利称这是个巨大的警钟:
等人们意识到这意味着大多数前沿实验室一直在错误的方向上扩展。27M参数击败大1000倍的模型应该是一个巨大的警钟。
Narasimha R N(@NarasimhaRN5)表示终于看到了新希望:
这感觉就像魔法来到了街头。一个小团队用小模型做到了大实验室才能做的事,这表明AI不再只属于富人或权贵。任何有头脑和信念的人现在都可以构建。车库天才的时代回来了,这一次,它会思考。
革命性训练方法
HRM的另一个重要创新是训练方法。
传统的循环神经网络需要「时间反向传播」(BPTT),就像你要记住整个思考过程的每一步,然后倒着回溯——这需要大量内存。
HRM提出了一步梯度近似,只需要记住最后的结果就行:
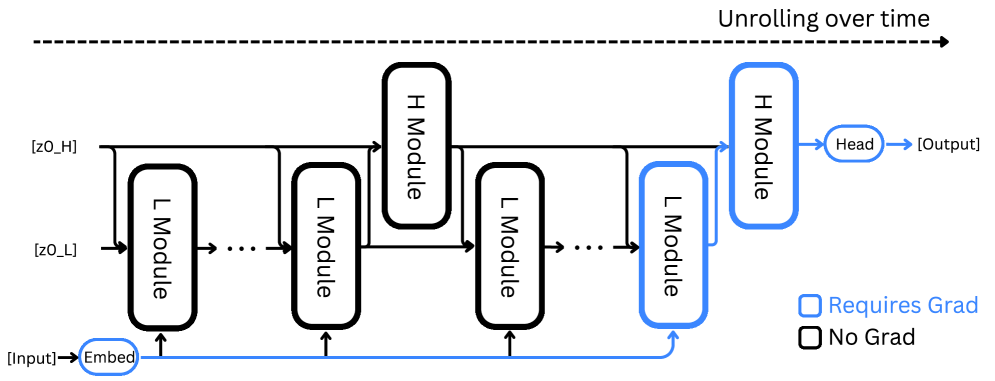
这不仅更高效,还更接近大脑的工作方式——
人类的真实大脑,并不会完整记录和回放整个思考过程。
会调节思考速度的AI
心理学家丹尼尔·卡尼曼提出人类有两种思考系统:
-
系统1是快速、直觉式(看到2+2立即知道等于4)
-
系统2是缓慢、深思熟虑(计算17×23需要思考)
HRM实现了类似的机制:
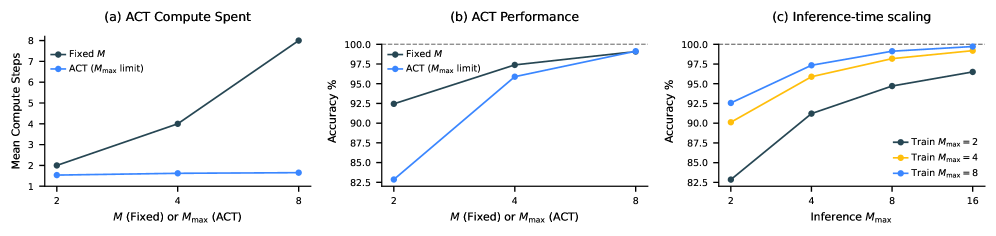
通过自适应计算时间(ACT),模型学会了简单问题快速解决,复杂问题自动分配更多思考时间。
更神奇的是,它在推理时还能「加时思考」——
训练时最多思考8步的模型,推理时可以思考16步,准确率继续提升。
这就像学生时候的你,平时做个简单题最多也就花个10分钟,但考试时遇到难题可能得花20分钟,而且一通死磕后,还真的能给做出来。
思考过程展示
研究团队展示了HRM解决问题时的思考过程:




在解迷宫时,HRM像人类一样先同时探索多条可能的路径,排除死路和低效路线,构建初步方案,然后反复优化直到找到最优解。
在解数独时,它采用类似「试错法」——
尝试填入数字,发现矛盾就回退,尝试其他可能性。
这种「内部思考」过程完全不需要像ChatGPT那样把每一步都说出来。
它真的在用脑「思考」,而不是在用嘴「说话」。
像大脑一样组织信息
最值得注意的是,HRM展现出了与真实大脑相似的组织结构:
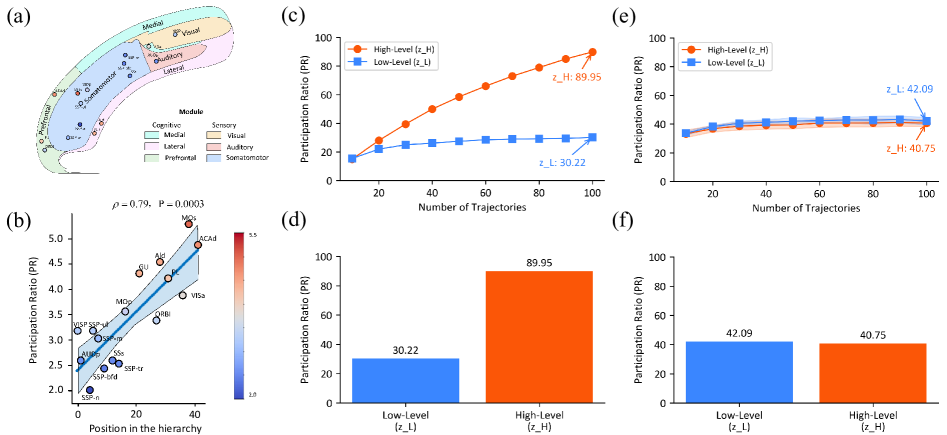
研究发现,低层模块的「思维空间」维度是30.22,高层模块的「思维空间」维度是89.95,比率约2.98。
这个比率与小鼠大脑皮层的测量值(约2.25)惊人地接近!
这意味着HRM自发地学会了像大脑一样组织信息——
高层次的抽象思考需要更大的「思维空间」,而具体执行只需要较小的空间。
论文中称,没有人教它这么做,它自己学会了。
这……太疯狂了……
新架构下的Aha Moment 啊!
小模型的逆袭
网友Aditya(@AadityaOnX)送上了幽默评论:
O3-mini在这里做俯卧撑,而一个27M的脑细胞模型走过去解决了迷宫。场面太尴尬了。
Karim Chaanine(@BrandGrowthOS)直言:
这是每个人都在忽视的效率突破。27M参数对比数十亿参数模型,它在推理上获胜?这改变了生产部署的一切。Mario可以在基础硬件上本地运行这个,而不是烧API积分。

这项研究来自清华大学和新加坡的Sapient Intelligence团队,已经开源在GitHub上。
很不Close AI.
当整个LLM 行业都在追求更大更猛更多数据和算力中心的大大大大模型时,这个小模型用20瓦功率告诉我们:
当我们真正理解并模仿大脑的计算原理时,是真可能会带来效率的极大飞跃。

此处必须得送上Yann LeCun先前放出的两句暴论:
暴论一:当前的大语言模型甚至不如一只猫聪明。
暴论二:不要再研究LLM 了!
没准此时的Yann LeCun:谁想打我脸来着?
可能还有老黄:……???

看完,我想,最优雅的解决方案往往不是大力堆砌和浪费计算资源,而是来自理解问题的真正本质。
当一件事不那么对劲之时,往往它可能就真的不对劲。
Transformer 架构极大地提升了人工智能的能力,但随着GPT-5难产,Claude 5 久久未出,DeepSeek R2 也暂无消息,大模型们似乎正纷纷撞墙——
这次的研究,让我们再次看到了新的希望。
也许,我们一直在用蛮力解决本该用智慧解决的问题。
可以确定的是,通向AGI的路必然不是更多的参数,而是更好的架构。
毕竟,爱因斯坦的大脑也只有1.23公斤。
论文地址: https://arxiv.org/pdf/2506.21734
[2]开源代码: https://github.com/sapientinc/HRM
(文:AGI Hunt)