


在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。
但华为与香港科大的最新研究发现了一个出人意料的现象:在多模态视觉语言模型(VLM)中,这对组合难以实现协同增益,甚至有时会互相拖后腿。

-
论文标题:The Synergy Dilemma of Long-CoT SFT and RL: Investigating Post-Training Techniques for Reasoning VLMs
-
论文地址:https://www.arxiv.org/abs/2507.07562
推动这项研究的一个关键见解是认识到多模态推理评测与纯语言评测存在微妙差异。虽然文本推理任务通常侧重于逻辑要求高的问题,但多模态评测通常包含简单基于感知的问题和复杂的认知推理挑战。作者假设,这种异质性是 Long-CoT SFT 和 RL 在多模态设置中表现出不同现象的核心原因。
为探索各种后训练技术如何影响不同类型问题性能,作者们引入了一个简单有效的难度分类方法,并基于此构建了难度层级细化后的多模态推理榜单数据集(包括新的 MathVision、MathVerse、MathVista、MMMU val 和 MMStar val)。该方法根据基线模型 Qwen2.5-VL-Instruct-7B 在五个数据集的每个问题上 16 次独立运行的成功率,将题目分为五个级别(L1-L5),分别代表从简单到困难:
-
L1 (简单):通过率 ≥ 12/16 (75%)
-
L2 (中等偏易):8/16 ≤ 通过率 < 12/16 (50-75%)
-
L3 (中等):5/16 ≤ 通过率 < 8/16 (31-50%)
-
L4 (中等偏难):2/16 ≤ 通过率 < 5/16 (13-31%)
-
L5 (困难):通过率 < 2/16 (13%)
数据、模型地址:https://github.com/JierunChen/SFT-RL-SynergyDilemma
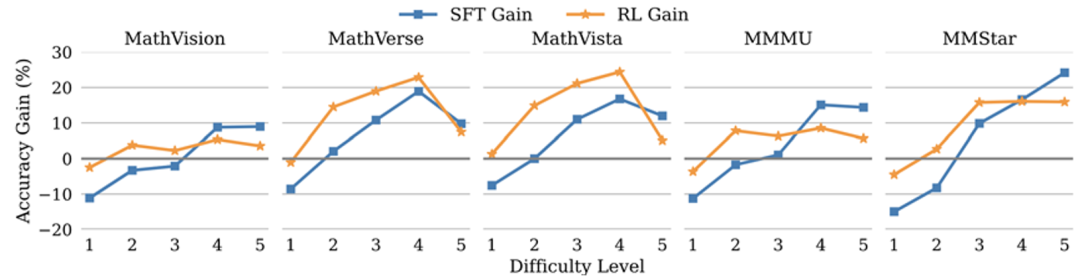

长思维链 SFT 引导模型反复演算,专攻难题
长思维链 SFT 就像给模型配备了 「超级草稿本」,通过少量带反思验证等思考模式的推理样本训练,让模型学会层层拆解复杂问题:
-
在 L5 级难题上,它能让 VLM 准确率显著提升,尤其擅长处理 MathVision 中的图文结合推理难题
-
但在最简单的 L1 级题目(如 「图中有几个红色圆形」)上,反而比基础模型表现更差:多余的推理步骤变成 「画蛇添足」,导致 「摇摆不定」 甚至 「矫枉过正」
-
经过 Long-CoT SFT 的模型会频繁使用 「首先验证」「其次推导」 等逻辑词,甚至出现 「这里可能算错了」 的人类化思考痕迹,虽然逻辑深度增加,但冗余度飙升至原来的数倍。
RL 强化模型整体性能,能力均衡不偏科
强化学习则像给模型装上 「精准导航」,通过奖励机制引导模型输出高质量答案:
-
在所有难度级别(L1-L5)均能实现较为稳定的提升,简单题不翻车,中等题表现稳健
-
输出文本保持了基线模型的高效简洁,极少出现冗余推理
-
但 RL 的短板也很明显:在 L5 级难题上的提升不及 Long-CoT SFT,复杂逻辑链的构建能力以及反思验证等认知行为无法高效激活
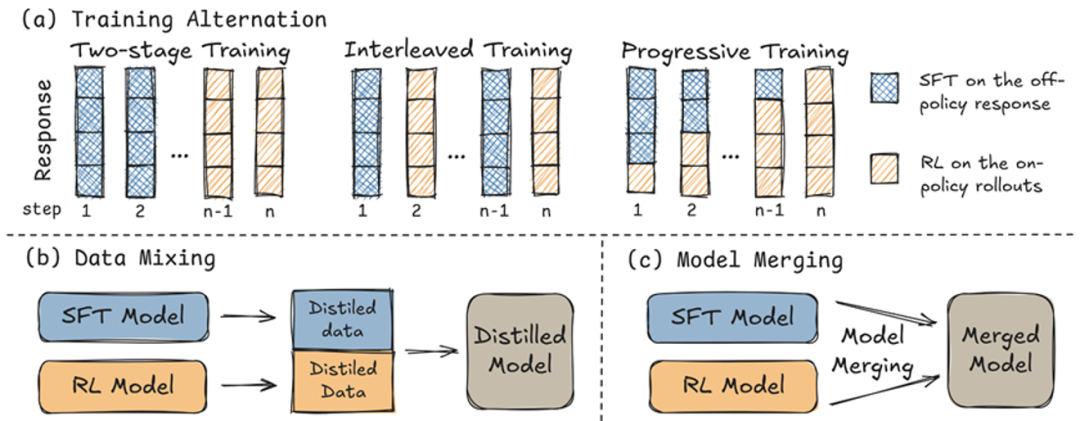
协同困境:五种组合策略全失效
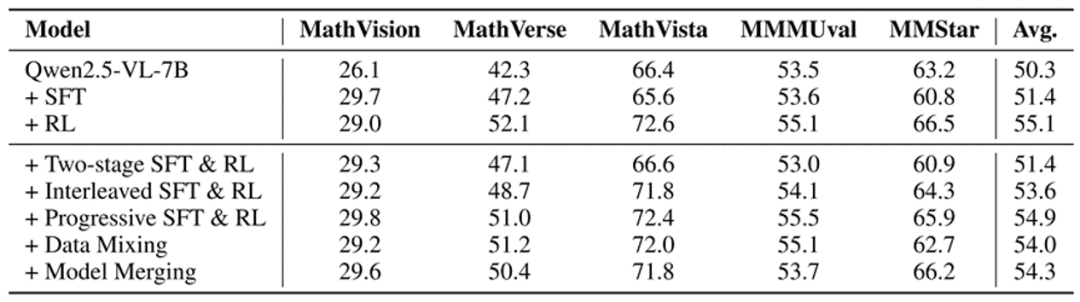
既然 SFT 强于难题、RL 长于均衡,研究团队尝试了五种组合方案,结果令人意外,所有方法都没能实现 「1+1>2」 的效果:
-
两阶段(先 SFT,后 RL):回答范式固化于冗长思考,性能困于 SFT 水平,RL 优势难以体现
-
交替式(相邻训练步数交替使用 SFT 和 RL,SFT 损失仅应用于通过率为零的问题,RL 损失应用于其他问题):性能始终卡在两种方法之间,无法突破单一方法上限
-
渐进式(在训练过程中逐渐减少 SFT 监督,过渡到纯 RL):显示出最大的潜力,难题解决能力高于纯 RL、媲美纯 SFT,但仍是一种折衷,牺牲了部分简单题目的性能
-
数据混合(将 SFT 和 RL 模型的输出合并到一个统一的数据集中,用于后续训练,其中只有 RL 模型不会做的题目采用 SFT 模型的输出):模型缺乏题目难度感知能力,导致推理风格难以自适应切换,在简单题出现冗长回答和掉点风险
-
模型合并(使用线性、TIES 和 SLERP 合并技术在不同混合比例下的无训练参数插值):表现出的是性能插值而非叠加增强
其中两阶段、交替式和渐进式的混合训练曲线如图所示
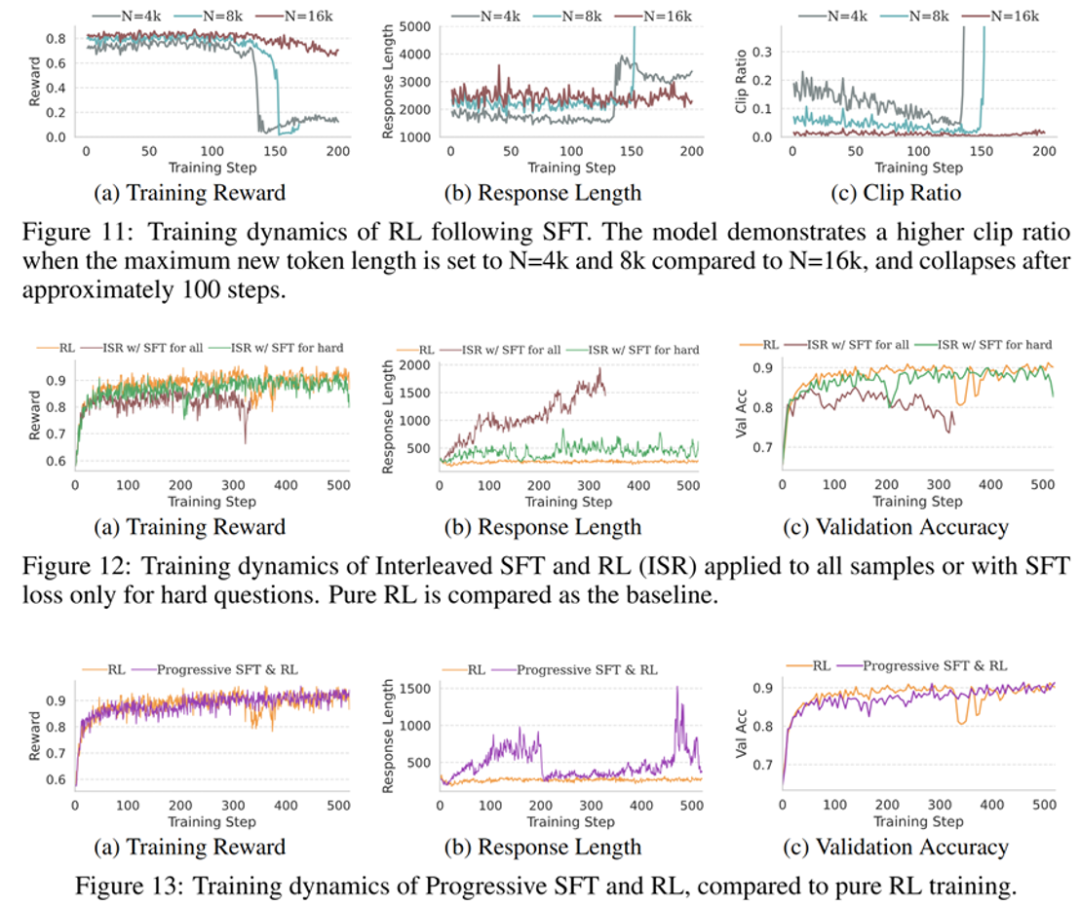
其他实验发现
-
推理轨迹的质量比数据规模和模态匹配更重要。用 1k 条高质量文本思维链数据(来自 s1.1)做 SFT 微调的效果优于用 34k 多模态推理数据 Eureka-Distill。
-
KL 正则化项有效保持了 RL 长稳训练。没有它,模型容易陷入奖励崩溃、熵减小和响应长度的剧烈波动,最终导致性能不佳。
-
简单题是 「性能压舱石」。即便简单题的归一化奖励为零,把它们纳入 RL 训练数据也至关重要。它们能通过 KL 约束发挥作用,避免因专注难题训练而丢失处理简单题的基础能力。
未来方向:让模型学会 「见题下菜碟」
1. 自适应推理:长思维链 SFT 带来的慢思考和 RL 强化的快思考两种回答范式难以兼容,VLM 的题目异质性更是放大了这种冲突,未来研究应考虑如何有效实现模型自适应推理,对简单题给出简洁回答,对难题采用深度推理。
2. 构建模型亲和的训练数据:在此项研究中,长思维链数据是从外部模型蒸馏而来,可能和基线模型存在亲和性不足的风险。为避免损害模型基础能力,应考虑采用其他方式如提示词工程自蒸馏构建训练数据。
3. 分层评估体系:将榜单分为不同难度题目,有助于差异化、针对性地评测和优化模型。

©
(文:机器之心)