

在Qwen3屠榜的时候,我发现有一个小众模型爬到了第三名。
我们开源了 Higgs Audio v2,这是一个强大的音频基础模型,预训练于超过 1000 万小时的音频数据和多样化的文本数据。尽管没有后训练或微调,Higgs Audio v2 在表达性音频生成方面表现出色,这得益于其深入的语言和声学理解。
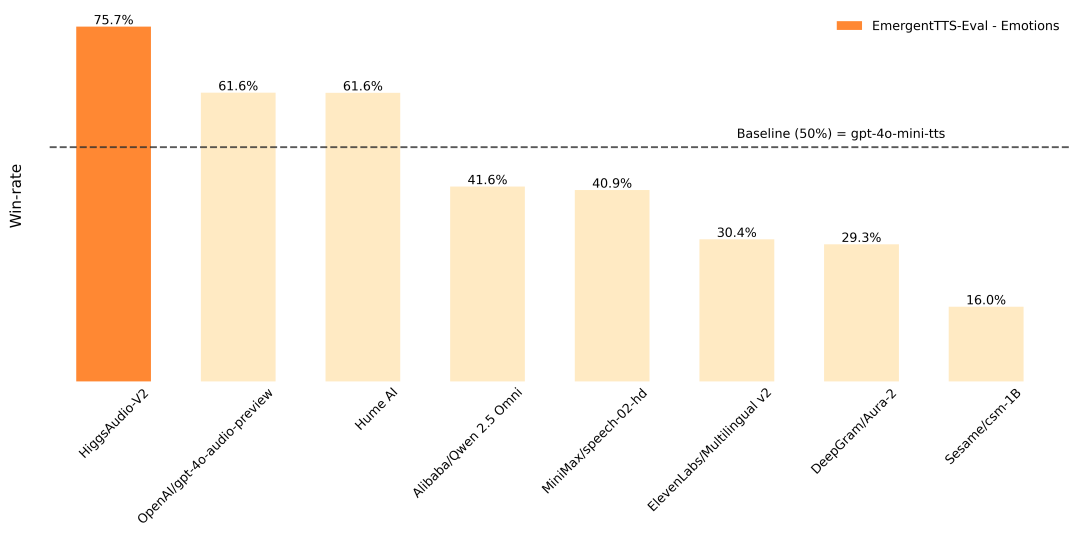
在 EmergentTTS-Eval 上,该模型在“Emotions”类别中以 75.7% 的胜率击败了“gpt-4o-mini-tts”,在“Questions”类别中以 55.7% 的胜率击败了“gpt-4o-mini-tts”。它还在传统 TTS 基准测试如 Seed-TTS Eval 和情感语音数据集(ESD)上取得了最先进的性能。此外,该模型展示了之前系统中很少见到的能力,包括在叙述过程中自动适应语调、零样本生成多种语言的自然多说话者对话、克隆声音的旋律哼唱,以及同时生成语音和背景音乐。
这是演示视频,展示了部分涌现能力(请记得开启音量):
这是另一个演示视频,展示了模型的多语言能力以及如何实现实时翻译(请记得开启音量):
技术细节
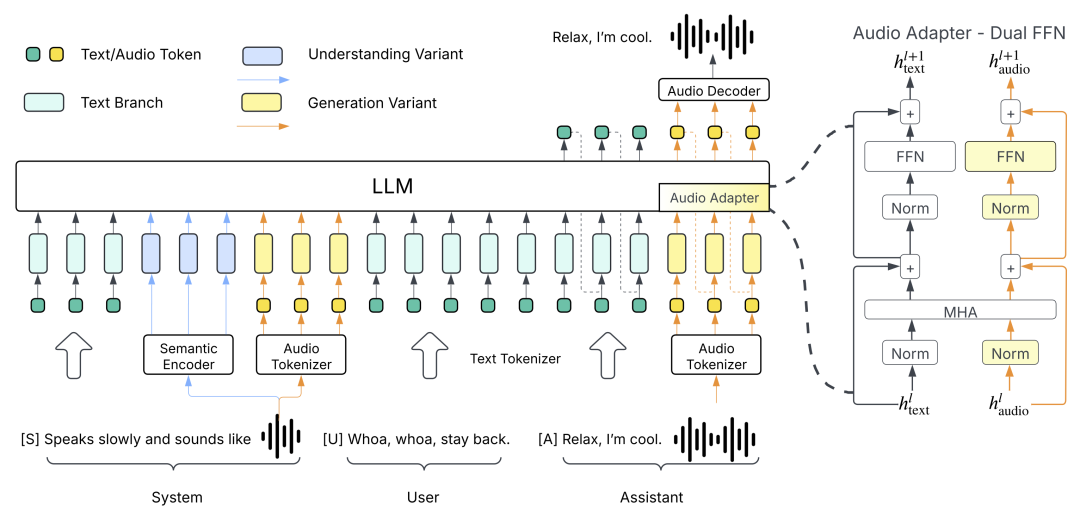
Higgs Audio v2 采用了上述架构图中所示的“生成变体”。其强大的性能得益于三项关键技术创新:
- 我们开发了一个自动注释流水线,利用了多个 ASR 模型、声学事件分类模型以及我们内部的音频理解模型。通过这个流水线,我们清理并标注了 1000 万小时的音频数据,我们称之为 AudioVerse。内部理解模型是在 Higgs Audio v1 理解的基础上进行微调的,后者采用了上述架构图中所示的“理解变体”。
- 我们从零开始训练了一个统一的音频分词器,能够捕捉到语义和声学特征。
- 我们提出了 DualFFN 架构,该架构在最小的计算开销下增强了LLM处理声学令牌的能力。
Audio Tokenizer
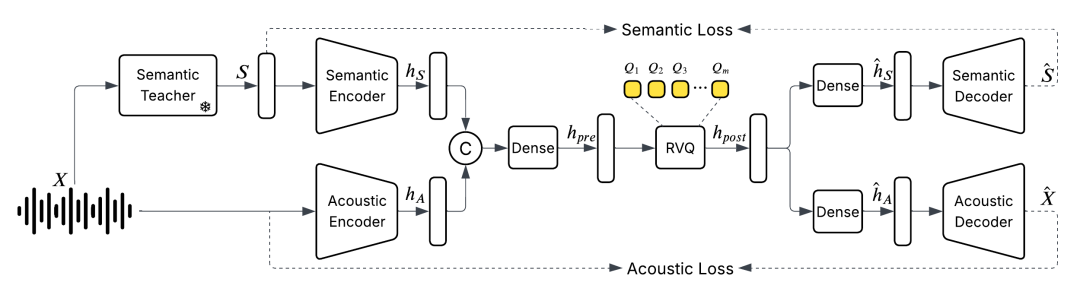
我们介绍了一种新的离散化音频分词器,其运行速度仅为每秒 25 帧,同时保持甚至改善了与比特率是其两倍的分词器相比的音频质量。我们的模型是首个在统一系统中训练 24 kHz 数据,涵盖语音、音乐和声音事件的模型。它还使用简单的非扩散编码器/解码器进行快速批量推理。它在语义和声学评估中达到了最先进的性能。更多信息请参阅 https://hf-mirror.com/bosonai/higgs-audio-v2-tokenizer。
模型架构 — 双重 FFN
Higgs Audio v2 基于 Llama-3.2-3B 构建。为了增强模型处理音频标记的能力,我们引入了“DualFFN”架构作为音频适配器。DualFFN 作为特定于音频的专家,通过最小的计算开销提升了 LLM 的性能。我们的实现保留了 91% 的原始 LLM 的训练速度,同时包含 DualFFN,其参数量为 2.2B。因此,Higgs Audio v2 的总参数量为 3.6B (LLM) + 2.2B (音频 DualFFN),其训练 / 推理 FLOPs 与 Llama-3.2-3B 相同。消融研究显示,配备 DualFFN 的模型在词错误率 (WER) 和说话人相似度方面始终优于其对照组。有关更多信息,请参阅我们的架构博客。
评估
这是 Higgs Audio v2 在四个基准上的性能,Seed-TTS 评估,情感语音数据集 (ESD),EmergentTTS-评估,以及多说话人评估:
Seed-TTS 评估 & ESD
我们使用参考文本、参考音频和目标文本对 Higgs Audio v2 进行零样本 TTS 提示。我们使用 Seed-TTS Eval 和 ESD 的标准评估指标。
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ElevenLabs 多语言 V2 | 1.43 |
|
|
|
|
|
|
|
1.49 |
|
| Higgs Audio v2(基础版) |
|
67.70 |
|
86.13 |
EmergentTTS-Eval(情绪和问题)
根据EmergentTTS-Eval 论文,我们报告了与”gpt-4o-mini-tts”和”alloy”声音的胜率对比结果。Higgs Audio v2 的声音是”belinda”。裁判模型是 Gemini 2.5 Pro。
|
|
情绪 (%) ↑ | 问题 (%) ↑ |
|---|---|---|
|
|
75.71% | 55.71% |
| gpt-4o-audio-preview |
|
|
|
|
|
|
| 基线:gpt-4o-mini-tts |
|
|
| Qwen 2.5 全能† |
|
|
|
|
|
|
| ElevenLabs 多语言 v2 |
|
|
|
|
|
|
| 芝麻 csm-1B |
|
|
‘†’ 表示使用了论文中描述的强提示方法。
多说话人评估
我们还设计了一个多说话人评估基准,以评估 Higgs Audio v2 在多说话人对话生成方面的能力。基准包含三个子集
两发言人对话: 1000 条合成对话,涉及两名发言人。我们固定两个参考音频片段,以评估模型在 4 到 10 条随机选择的人物之间对话的双语音克隆能力。闲聊(无参考): 250 条合成对话,与上述对话的收集方式相同,但以短语句和有限的对话轮次(4-6 轮)为特点,在这种情况下不固定参考音频,该数据集旨在评估模型自动为说话者分配合适声音的能力。- 短对话(参考):250 条合成对话,类似于上述内容,但包含更短的语句,因为这一组旨在包括参考片段,类似于两发言人对话。
我们在这些三个子集上报告了词错误率(WER)以及内发言人相似性和跨发言人差异性的几何平均值。除了 Higgs Audio v2 之外,我们还评估了 MoonCast 和 nari-labs/Dia-1.6B-0626,这是两个最受欢迎的开源多发言人对话生成模型。结果总结在下面的表格中。由于 nari-labs/Dia-1.6B-0626 对语句和输出音频长度的严格限制,我们无法在“两发言人对话”子集上运行该模型。
|
|
两方对话 |
|
聊天 |
|
聊天(无引用) |
|
|---|---|---|---|---|---|---|
|
|
|
平均相似度 ↑ |
|
平均相似度 & 不相似度 ↑ |
|
平均相似度 & 不相似度 ↑ |
| 月之播送 |
|
|
8.33 |
|
|
|
|
|
|
|
|
|
|
61.14 |
| Higgs Audio v2(基础版) | 18.88 | 51.95 |
|
67.92 | 14.65 |
|
Get Started
你需要首先安装 higgs-audio:
git clone https://github.com/boson-ai/higgs-audio.git
cd higgs-audio
python3 -m venv higgs_audio_env
source higgs_audio_env/bin/activate
pip install -r requirements.txt
pip install -e .
之后,尝试运行以下 Python 代码片段以将文本转换为语音。
from boson_multimodal.serve.serve_engine import HiggsAudioServeEngine, HiggsAudioResponse
from boson_multimodal.data_types import ChatMLSample, Message, AudioContent
import torch
import torchaudio
import time
import click
MODEL_PATH = "bosonai/higgs-audio-v2-generation-3B-base"
AUDIO_TOKENIZER_PATH = "bosonai/higgs-audio-v2-tokenizer"
system_prompt = (
"Generate audio following instruction.\n\n<|scene_desc_start|>\nAudio is recorded from a quiet room.\n<|scene_desc_end|>"
)
messages = [
Message(
role="system",
content=system_prompt,
),
Message(
role="user",
content="The sun rises in the east and sets in the west. This simple fact has been observed by humans for thousands of years.",
),
]
device = "cuda"if torch.cuda.is_available() else"cpu"
serve_engine = HiggsAudioServeEngine(MODEL_PATH, AUDIO_TOKENIZER_PATH, device=device)
output: HiggsAudioResponse = serve_engine.generate(
chat_ml_sample=ChatMLSample(messages=messages),
max_new_tokens=1024,
temperature=0.3,
top_p=0.95,
top_k=50,
stop_strings=["<|end_of_text|>", "<|eot_id|>"],
)
torchaudio.save(f"output.wav", torch.from_numpy(output.audio)[None, :], output.sampling_rate)
您可以查看 https://github.com/boson-ai/higgs-audio/tree/main/examples 获取更多示例脚本。
(文:路过银河AI)