

今天是2025年7月26日,星期六,北京,晴。
我们继续回到文档智能这个主题。
文档智能目前模型侧逐步消停了一段时间,所以,我们可以做下归拢,前面做了许多技术总结的,从场景和技术角度。这次从数据工程角度来看,尤其是在进行多模态文档大模型研发时,怎么获取高质量的、大量的训练数据。
但是,为了回答这个问题,其实是可以看典型的工作的,其中有思路上的论述,因此,做个记录,以待后续会用到。
这里讲两个典型的,一个是DocGenome、一个是MonkeyOCR。
技术滚滚向前,让我们聚焦、深度,其中的核心还是梳理清楚逻辑,多思考。
一、DocGenome的文档解析数据合成方案
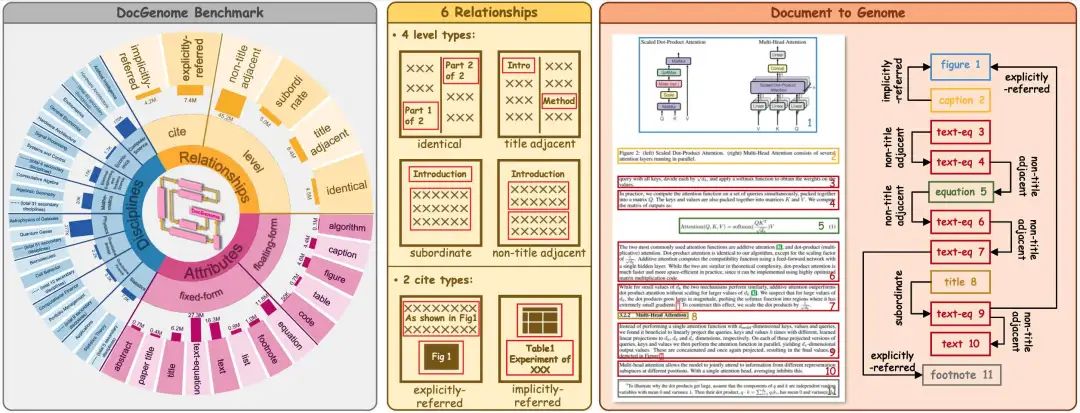
这是一个很不错的工作,并且至今已经过去了一年,《DocGenome: An Open Large-scale Scientific Document Benchmark for Training and Testing Multi-modal Large Language Models》,https://arxiv.org/pdf/2406.11633.pdf,包含500K个结构化的科学文档,其中有13种组件单元和它们之间的6种逻辑关系,还涵盖了科学文档中的各种数据类型,例如图、公式、表格、算法、列表、代码、脚注。
对应的数据集开放在:https://www.modelscope.cn/datasets/iic/DocGenome12K/files,https://github.com/Alpha-Innovator/DocGenome,以及https://drive.google.com/drive/folders/1OIhnuQdIjuSSDc_QL2nP4NwugVDgtItD?usp=sharing
而其中,最关键的,其实还是数据合成的方式,该数据集为了构建DocGenome,设计了DocParser,从大量arXiv论文的源代码中生成标注信息。
这个的细节比较有意思,我们来看下具体是如何实现的,用的组件是DocParser,将完整文档的LATEX源代码转换为组件单元的标注,包含源代码、属性、关系和边界框,以及整个文档的渲染后的PNG图像。
下图是DocParser的实现流程图,分为四个不同的阶段:1)数据预处理,2)单元分割,3)属性分配和关系检索,以及4)颜色渲染。
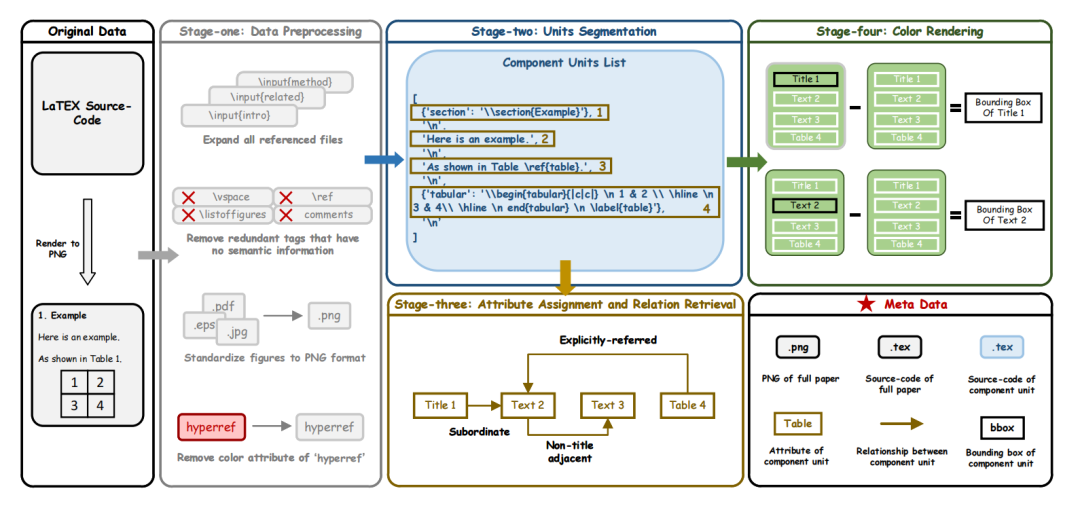
第一阶段:数据预处理
这个阶段是为了提高数据质量和增强LATEX源代码的编译成功率。
首先,对所有由\input和\include命令引用的文件进行扩展,然后进行一系列关键的预处理步骤,包括集成所需的环境包,排除注释行,并删除诸如\vspace、\ref和其他不参与文档语义本质的标注等多余字符。
随后,专注于标准化LATEX源代码中的图表格式,将所有图形元素转换为PNG格式。
此外,从“hyperref”中移除颜色属性,确保LATEX源代码在第四阶段的标注过程中准备好进行目标颜色渲染。
第二阶段:单元分割
此阶段的目标是自动化内容单元的分割,从而简化不同部分的渲染过程。
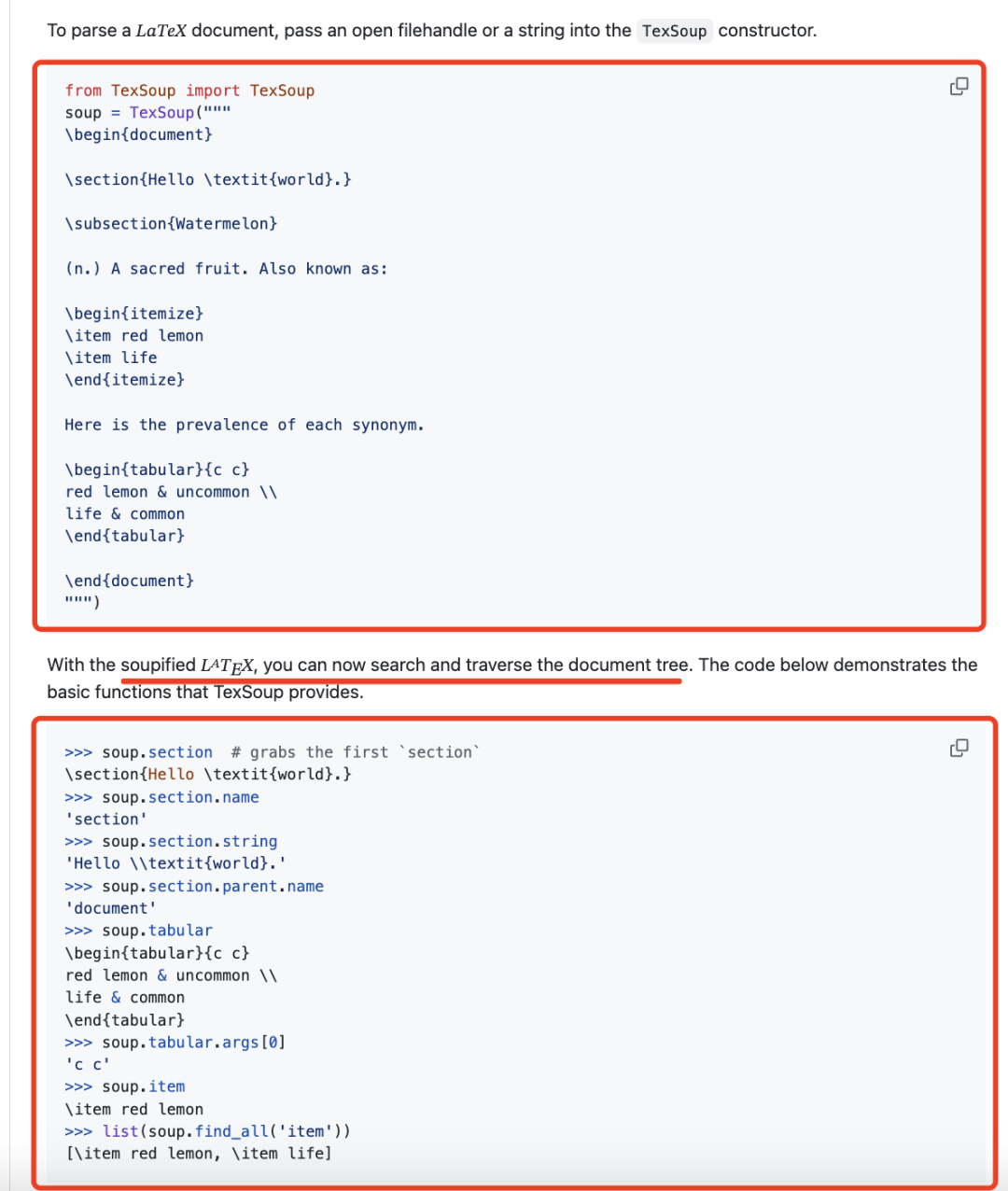
使用TexSoup用于将LATEX源代码分解为结构化列表的库,明确列出每个单独的组件单元。此列表按照阅读顺序进行组织,确保逻辑上的连贯性,并有助于后续检索组件单元之间的关系。
其中,TexSoup地址在:https://github.com/alvinwan/TexSoup
第三阶段:属性分配与关系检索
为第二阶段分解的组件单元定义了13个细粒度的布局属),包括算法、图注、公式等元素。对于每个单元,使用关键词查询和正则化技术从预定义集合中匹配适当的属性,以确保定制化和精确的分类,这个层次关系如下:
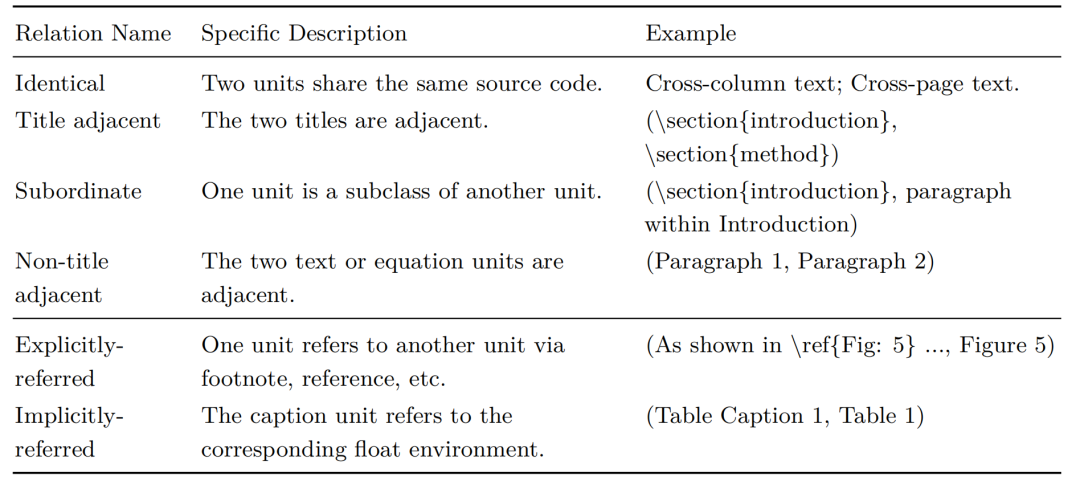
在分析组件单元关系时,单元被分为两类:1)固定格式单元,包括文本、标题、摘要等,其特点是按顺序阅读且层次关系可以从第二阶段获得的列表中识别,以及2)浮动格式单元,包括表格、图形等,它们通过\ref和\label等命令与固定格式单元建立方向性引用。
第四阶段:颜色渲染
组件单元的边界框是旨在提取的附加标签。在第二阶段的分割之后,将目标单元渲染为黑色,其他所有单元渲染为白色,以生成两个不同的PDF。

通过对这些文档进行减法运算,可以获得仅包含当前单元的检测框,对于跨越障碍物或页面的组件单元,根据其统一的源代码信息对边界框标签进行标准化。
整体的DocParser方案实现开源在:https://kkgithub.com/Alpha-Innovator/DocParser
然后,还有一个,就是基于这个解析的数据集,来做多模态问答对数据的合成,例如使用GPT-4V的模板提示进行文档问答对生成。

二、MonkeyOCR的文档训练数据构建方案
此外,我们再看另一个,《MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm》(https://arxiv.org/pdf/2506.05218),也可以关注其数据构建方式。
如下图,MonkeyDoc数据生成流水线的三个核心阶段。
结构检测阶段汇集并协调开源数据集,辅以合成的高质量中文样本;内容识别阶段采用手动与自动标注相结合的方式,包括合成数据生成与元素提取;关系预测阶段结合手动标注与模型辅助策略,以确立阅读顺序及区域间的关系。
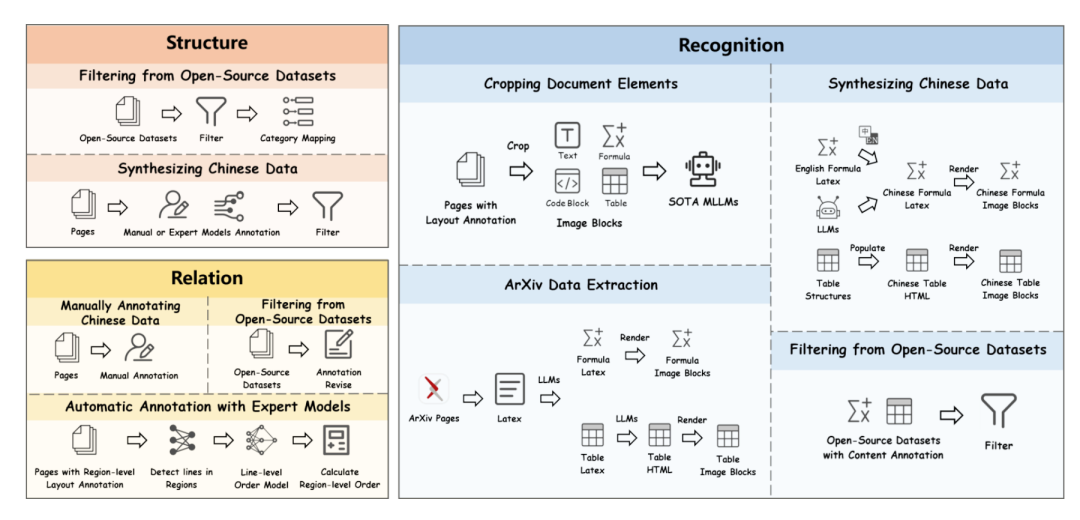
1、结构检测阶段
首先从多个公开可用的结构检测数据集中汇总并筛选数据,包括M6Doc、DocLayNet、D4LA和CDLA,涵盖了中英文文档,总计88k页。
通过将不同的标注方案映射到统一的十一类别标签集来协调类别标签,遵循MinerU的规范。
为了确保一致性和数据质量,通过仅保留每个元素的最大区域来移除嵌套的边界框,并通过舍弃面积小于页面35%的边界框来过滤低信息实例。
此外,收集了超过300,000页涵盖十多种中文文档类型,如财务报告、教科书和学术论文。
2、内容识别阶段
在内容识别上,涉及对关键文档元素的识别与转录,包括文本块、表格、公式及代码块,跨越多种格式与语言。
其一,基于结构检测阶段生成的布局标注,首先从原始文档图像中分割并裁剪出各个元素,包括文本块、公式区域、表格和代码块,共得到190万个样本。
部分元素使用Gemini2.5Pro进行转录和标注,以确保标注的准确性。
其二,从开源数据集中筛选。对于表格识别,从PubTabNet中筛选数据,应用严格的质量检查,如HTML标签闭合、表头存在性、合并单元验证、表头与主体对齐、异常字符检测以及语法验证,这一过程生成了一个包含470,000张表格的精选数据集;
对于公式识别,利用UniMER-1M数据集,该数据集汇集了来自多种公开来源的公式,包括Pix2tex、CROHME和HME100K,以及来自ArXiv、Wikipedia和StackExchange的大规模LaTeX表达式集合,涵盖了印刷和手写两种风格。
其三,合成中文数据,为缓解表格和公式识别任务中中文样本的不足,通过编程方式合成了具有高结构多样性的数据。
对于表格,构建多种行列配置的布局,填充中文内容,并生成配对的HTML和图像数据,例如tablegeneration。
对于公式,使用多模态模型生成常用的中文表达式,并通过大模型翻译和渲染来自UniMER-1M的英文公式,共生成526,000个额外的中文样本。
其四,arXiv数据提取,为了进一步扩展数据集的广度,从arXiv论文中提取并处理了表格和公式的LaTeX源数据,然后使用大模型过滤无关内容,并将生成的数据渲染为图像和结构化标注,新增了36,000个高质量的样本。
3、关系预测阶段
关系预测用于确定检测到的文档元素间的逻辑阅读顺序,这对于重建连贯且语义忠实的文档内容至关重要,尤其是在处理复杂布局、多栏页面或跨页结构的情况,但是构建挺难的,主要方式如下:
1)对开源数据进行处理,主要的开源数据集是DocGenome,它提供了通过自动化标注生成的区域级阅读顺序标注。但,这些标注可能存在噪声或不完整,特别是对于图像和表格等元素。
所以,为了提高标注的准确率,通过明确地将每张图像和表格与其对应的标题关联起来,并过滤掉低质量的样本(如包含未标注区域或过多空白区域的页面)来过滤这些标签,然后进一步根据元素类型的多样性对每个页面进行评分,选择高分页面进行收录。最终,得到了一套包含951,000个高质量样本的精选数据集。
2)手动标注中文文档。针对中文区域级阅读顺序标注资源有限的问题,手动标注多样化的中文文档,包括研究报告、学术论文、用户手册、书籍、试卷、幻灯片、官方文件、报纸、期刊和合同,生成154,000个高质量样本;
3)基于专家模型的自动标注。对于仅提供区域级边界框而无阅读顺序信息的数据集,利用专家模型自动生成区域级阅读顺序标注。
具体实现上,使用PPOCR对每个区域内的文本进行逐行识别,获取文本行位置,然后应用LayoutReader预测这些行的阅读顺序,区域级顺序通过聚合区域内所有文本行的预测顺序来确定。通过这种方法,生成了78,000个额外的区域级标注。
参考文献
1、https://arxiv.org/pdf/2506.05218
2、https://arxiv.org/pdf/2406.11633.pdf
(文:老刘说NLP)