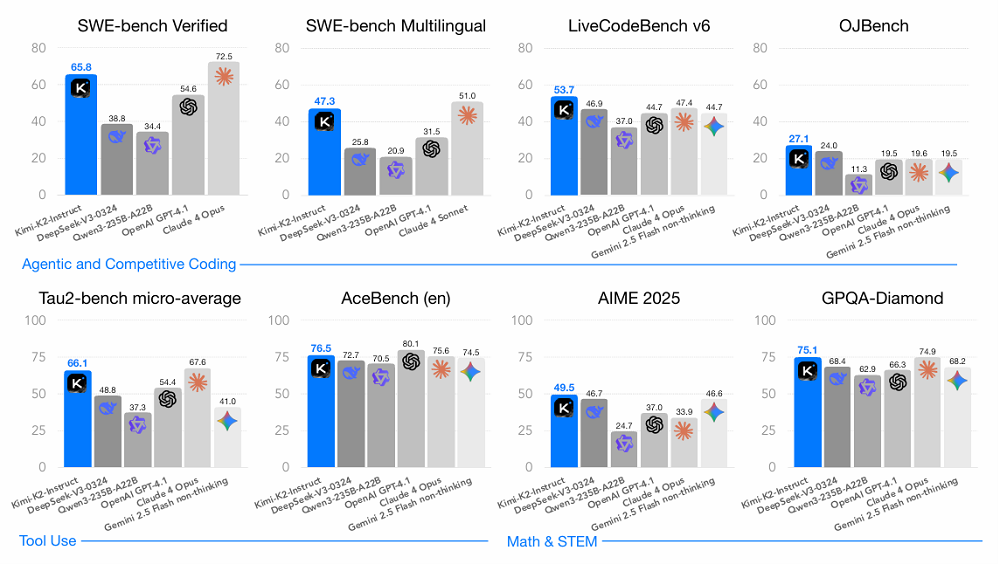
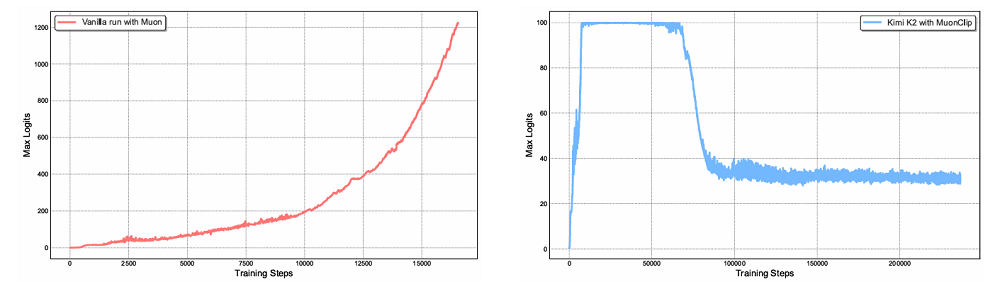
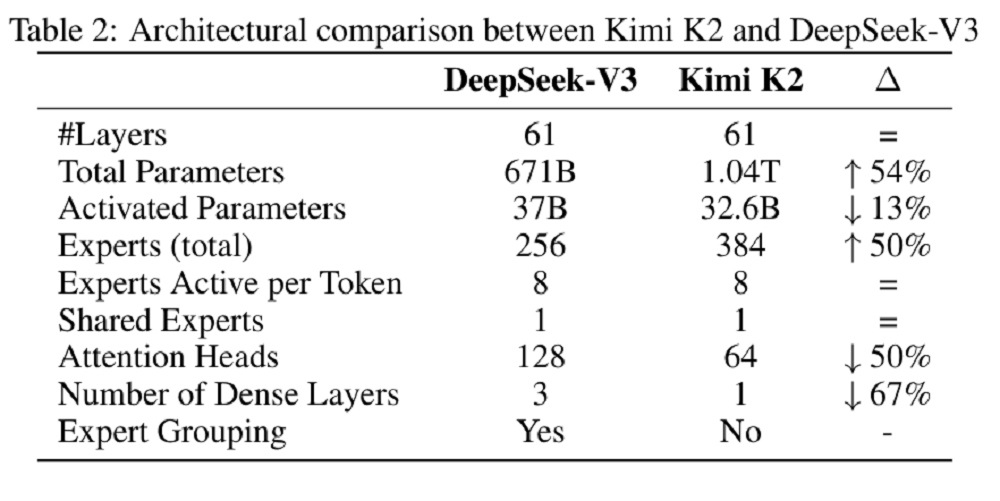
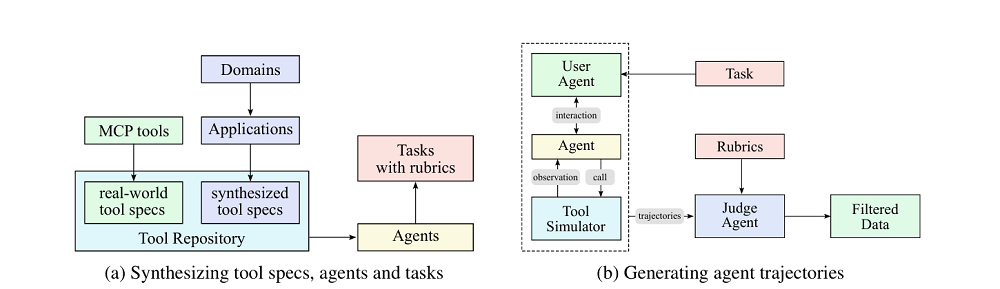
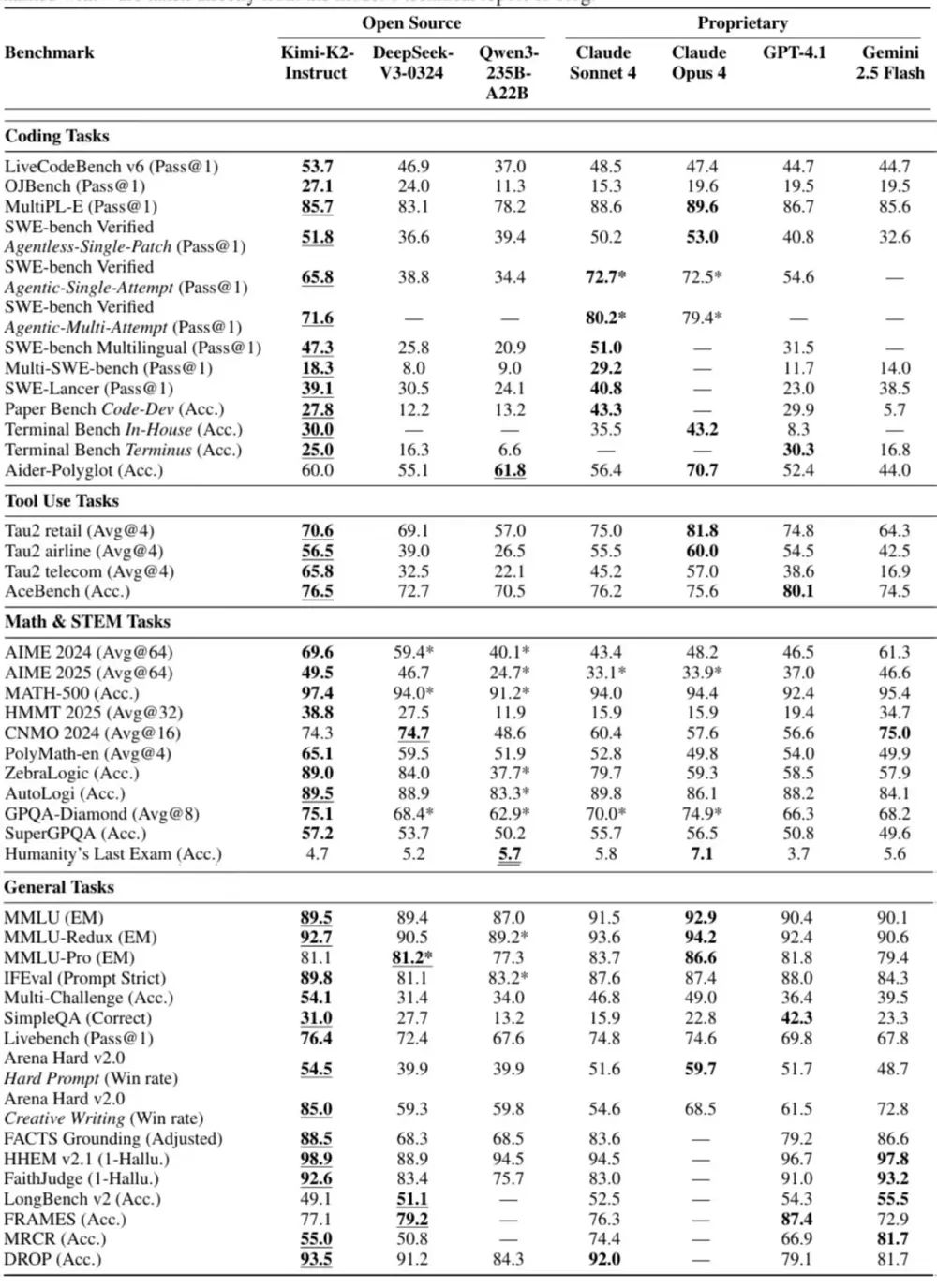
Kimi K2的后训练由两个核心阶段组成。在有监督微调阶段,Kimi K2依旧使用了Muon优化器,并构建了一个覆盖多领域的大规模指令微调数据集,重点是提示词多样性和响应质量。这些数据使用了K1.5及其他领域专家模型生成候选回答,再由大模型或人工进行质量评估与过滤。月之暗面特别为工具使用(Tool Use)能力构建了一个大规模Agentic数据合成流水线,整合3000+真实MCP工具和2万+合成工具,生成数千个不同能力组合的智能体与配套任务。紧接着,该团队模拟多轮交互,并过滤出高质量的智能体轨迹,然后在代码/软件工程等场景中,使用真实执行环境提升数据真实性。强化学习阶段,月之暗面的目标是在可验证奖励任务与主观偏好任务中提升模型能力。在可验证的任务上,该团队打造了一个可验证奖励的“训练场”,用于提升模型在数学、STEM、逻辑任务、复杂指令遵循、编程等领域的能力。针对无明确答案的任务(如创意写作、开放问答),月之暗面引入了模型自评机制,让模型通过对比自身输出并打分。RL算法优化方面,月之暗面限制了每任务最大token数,避免冗长输出,并利用PTX损失函数防止模型在训练过程中遗忘高价值数据。该团队还在后训练阶段逐步降低模型的temperature,从而降低随机性,确保模型输出的可靠性和一致性。后训练阶段,月之暗面还对训练基础设施进行了针对性设计,采用协同架构,将训练和推理引擎部署在同一节点,动态分配GPU资源以提升效率。针对长周期任务,该团队采用并行Rollout和分段执行优化GPU利用率,并通过标准化接口支持多样化环境,实现高效的大规模RL训练。基准测试的结果印证了上述训练流程的效果。