

今天是2025年7月21日,星期一,北京,晴。
我们来看下当前的主流大模型对比,涉及到llama-3.2,Qwen3-4B,SmolLM3-3B,DeepSeek-V3,Qwen3-235B-A22B,Kimi-K2等,做个总结,也不错。
另外一个,继续看GraphRAG进展,开始卷向事件领域,如果是一个事件图谱,尤其是加入一些事件信息,有时间属性的,该怎么做?怎么构图,也是值得关注的,我们也来看一个工作。
一、当前主流大模型架构对比
大模型架构进展,大模型LLM架构对比列举了llama-3.2,Qwen3-4B,SmolLM3-3B,DeepSeek-V3,Qwen3-235B-A22B,Kimi-K2的架构并详细探讨了他们的区别和优势:https://sebastianraschka.com/blog/2025/the-big-llm-architecture-comparison.html,其中有几个图,我们做下记录:
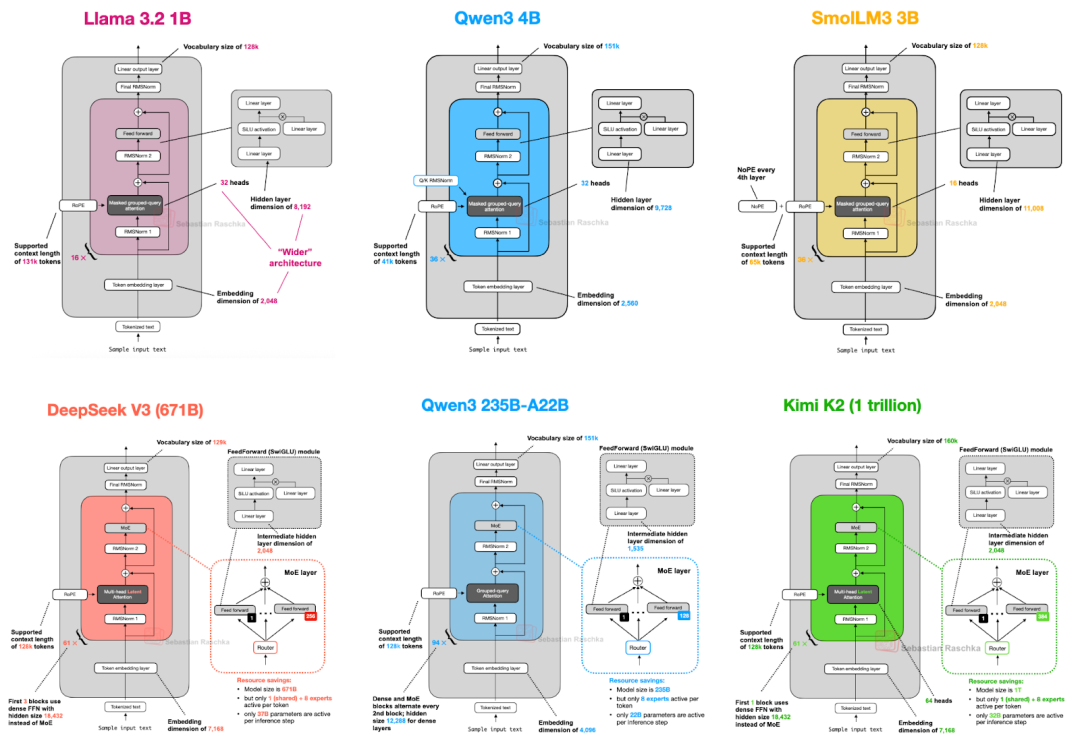
涉及到几个术语解释:

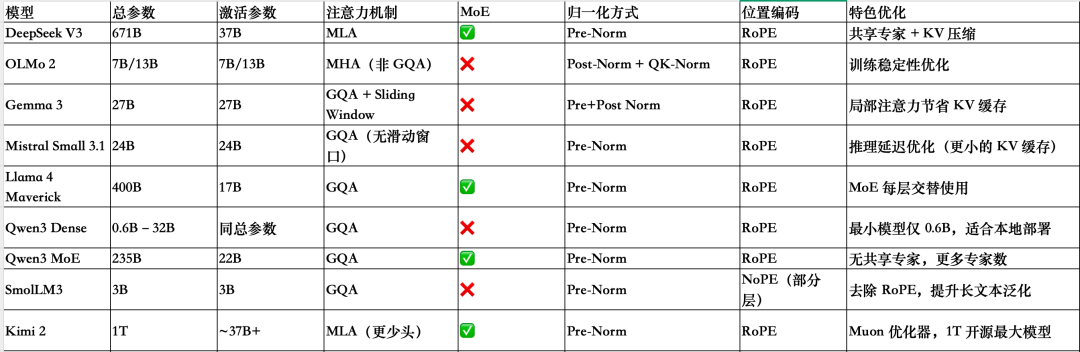
几个模型的对比总结
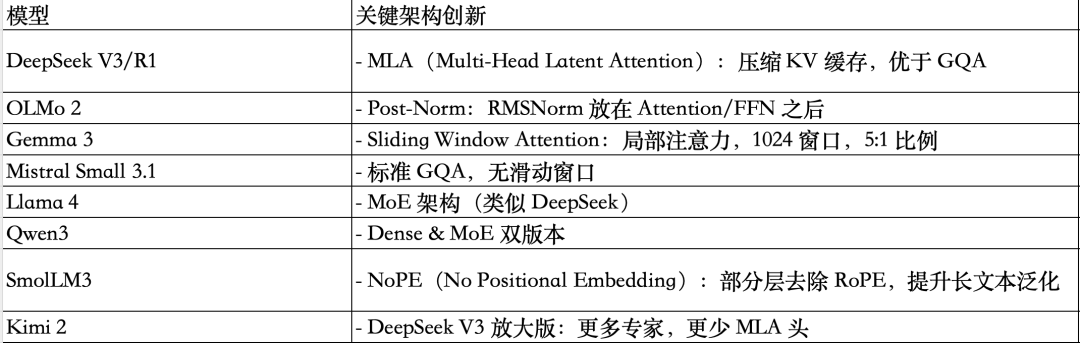
几个模型的创新汇总:
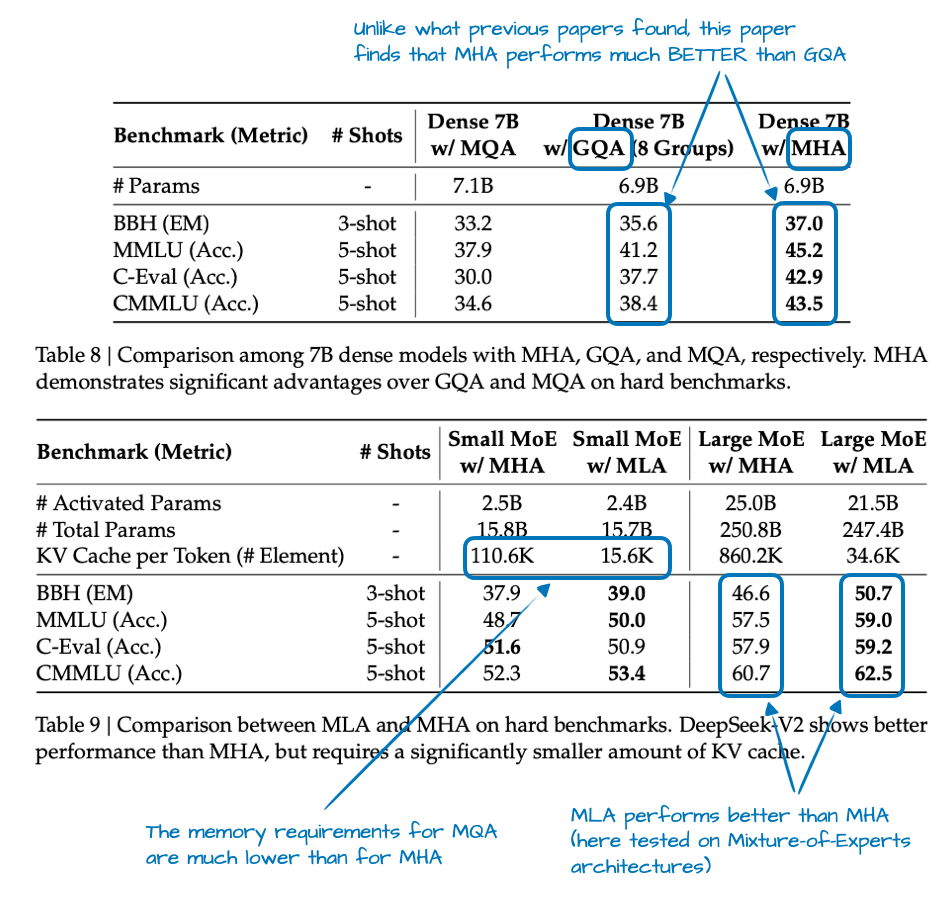
1、MH VS GQA
与MHA不同,MHA中的每个head都有自己的一组键和值,为了减少内存占用,GQA将多个head分组以共享相同的键和值投影。
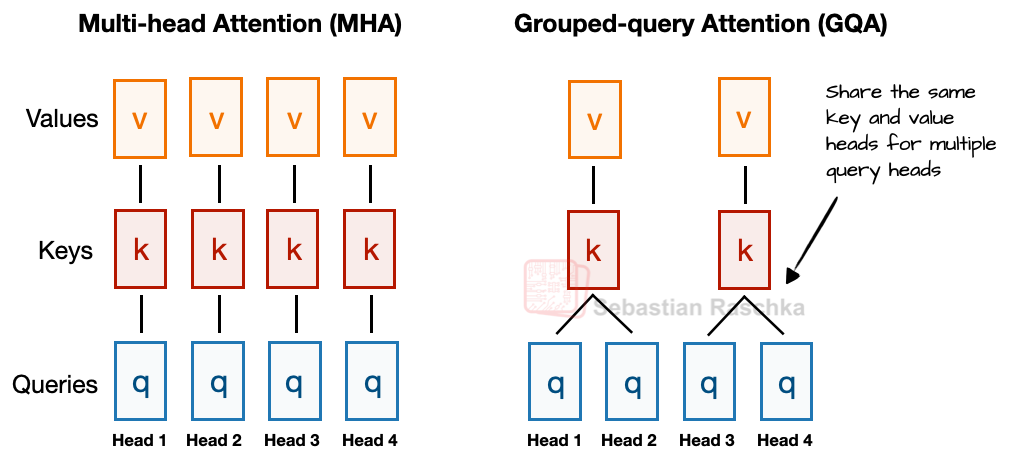
例如,如果有2个键值组和4个注意力头,那么注意力头1和2可能共享一组键值对,而注意力头3和4则共享另一组键值对。这减少了键值对的计算总量,从而降低了内存占用并提高了效率。
2、无位置嵌入(NoPE)
在基于Transformer的LLM中,位置编码通常是必需的,因为自注意力机制会独立于顺序来处理token。绝对位置嵌入通过添加一个额外的嵌入层来解决这个问题,该嵌入层会将信息添加到token嵌入中。RoPE通过相对于其标记位置旋转查询和键向量来解决这个问题。
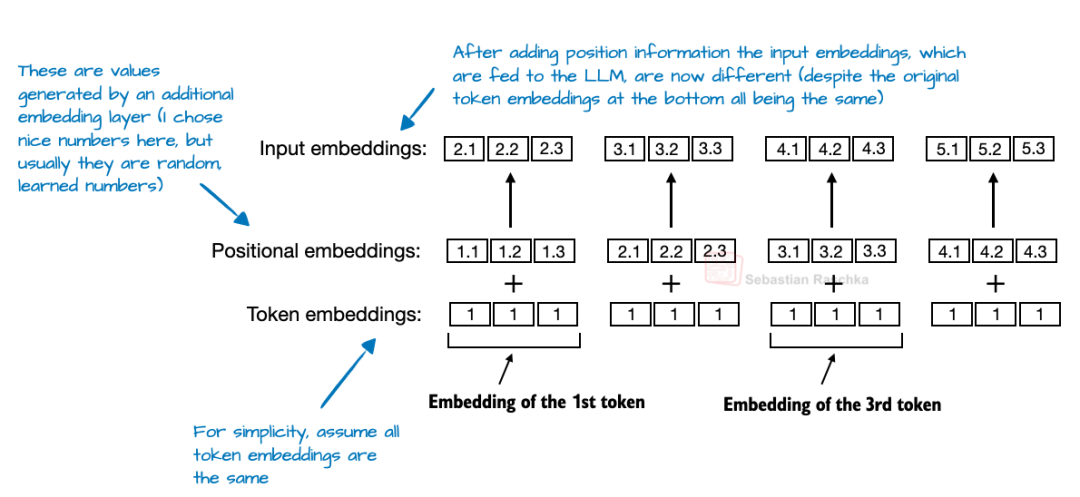
在NoPE层中,根本没有添加任何位置信号:不是固定的,不是学习到的,也不是相对的,。什么都没有。
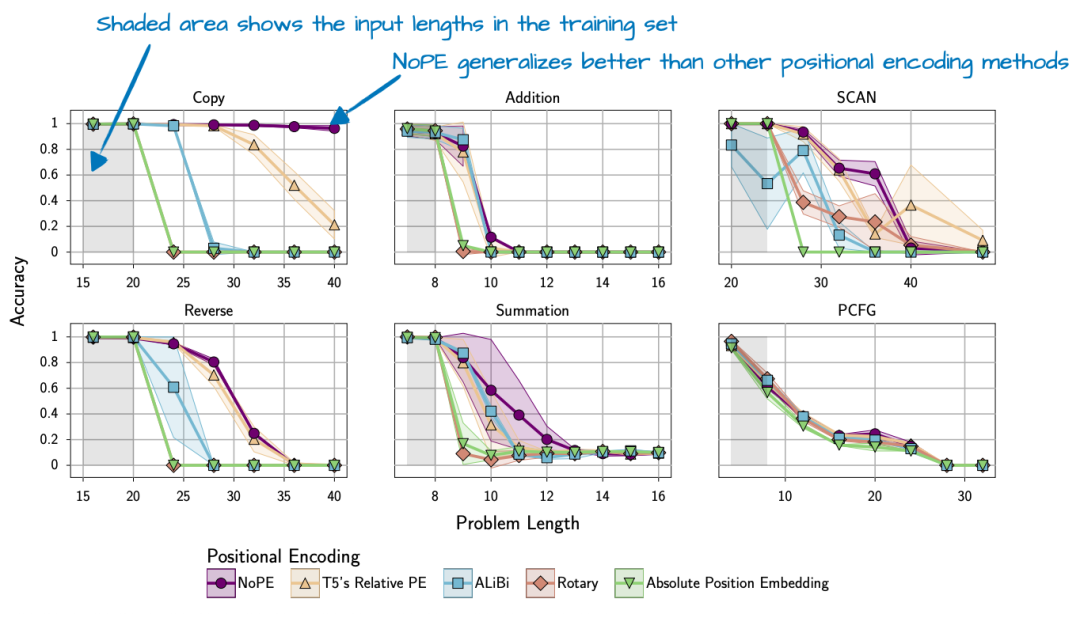
即使没有位置嵌入,由于因果注意力掩码的存在,模型仍然知道哪些标记在前面。此掩码阻止每个标记关注后面的标记。
因此,位置t处的标记只能看到位置≤t处的标记,从而保持了自回归排序,其发现不需要位置信息注入,而且还发现NoPE具有更好的长度泛化能力,这意味着随着序列长度的增加,LLM应答性能下降得更少。
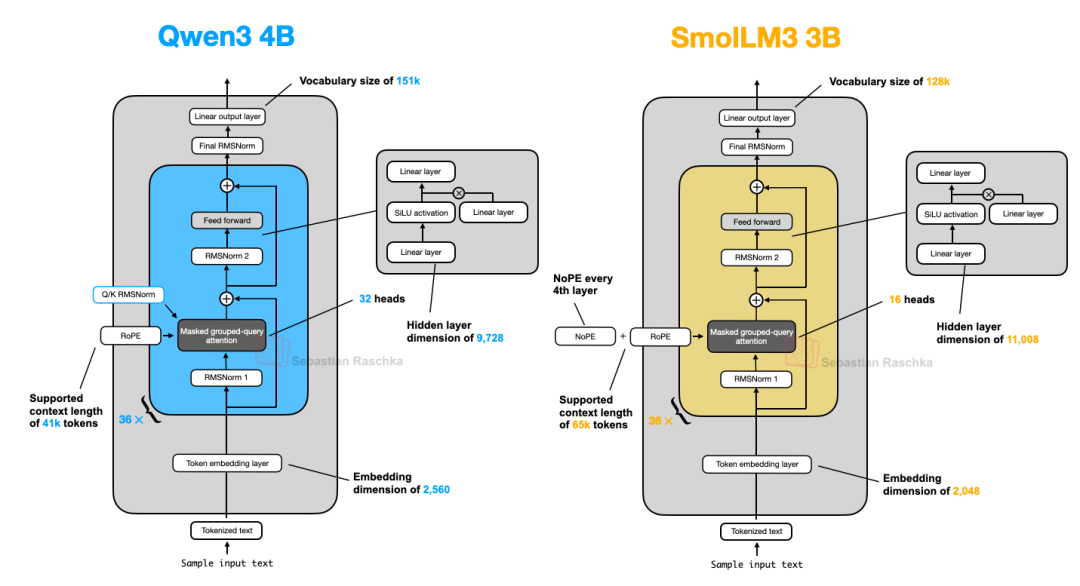
3、Qwen3 4B VS SmolLM3 3B
架构都一样,只是SmolLM3 3B使用了 NoPE(无位置嵌入)。
4、Qwen3(MoE)VS DeepSeek-V3
Qwen3有两种MoE版本:30B-A3B 和 235B-A22B,从架构上看,DeepSeek-V3和Qwen3235B-A22B架构非常相似。值得注意的是,Qwen3模型不再使用共享专家(早期的Qwen模型,例如Qwen2.5-MoE,确实使用了共享专家)。
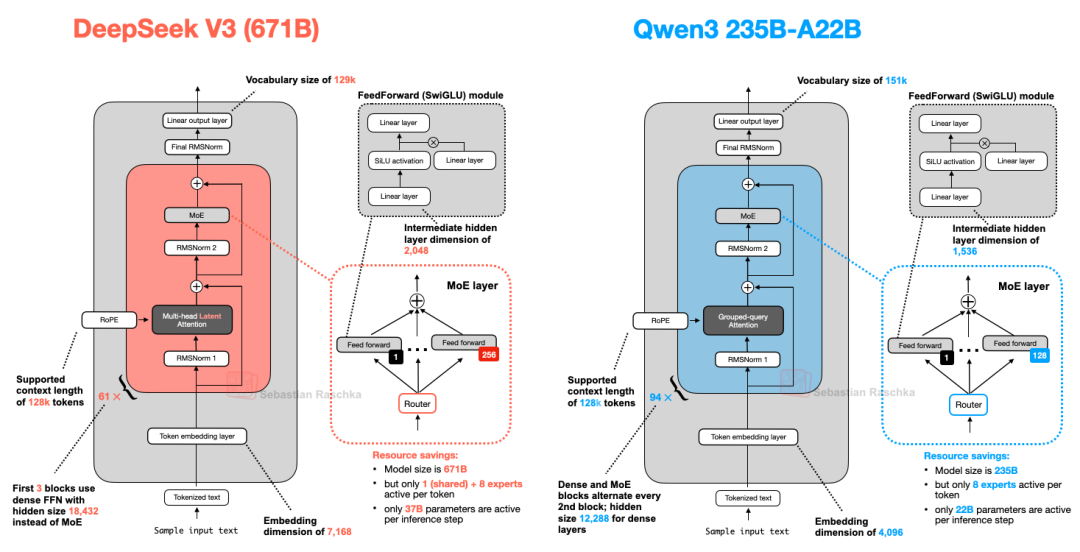
这里的猜测是,他们之所以将专家数量从2个(Qwen2.5-MoE中)增加到8个(Qwen3中),或许只是为了提高训练稳定性而没有必要。而且,他们能够通过只使用8个专家而不是8+1个专家来节省额外的计算/内存成本。
5、Qwen3 0.6B VS Llama 3 1B
Qwen3包括7个Dense模型:0.6B、1.7B、4B、8B、14B 和 32B。
Qwen3是一种更深的架构,具有更多的层,而Llama3是一种更宽的架构,具有更多的注意力头。
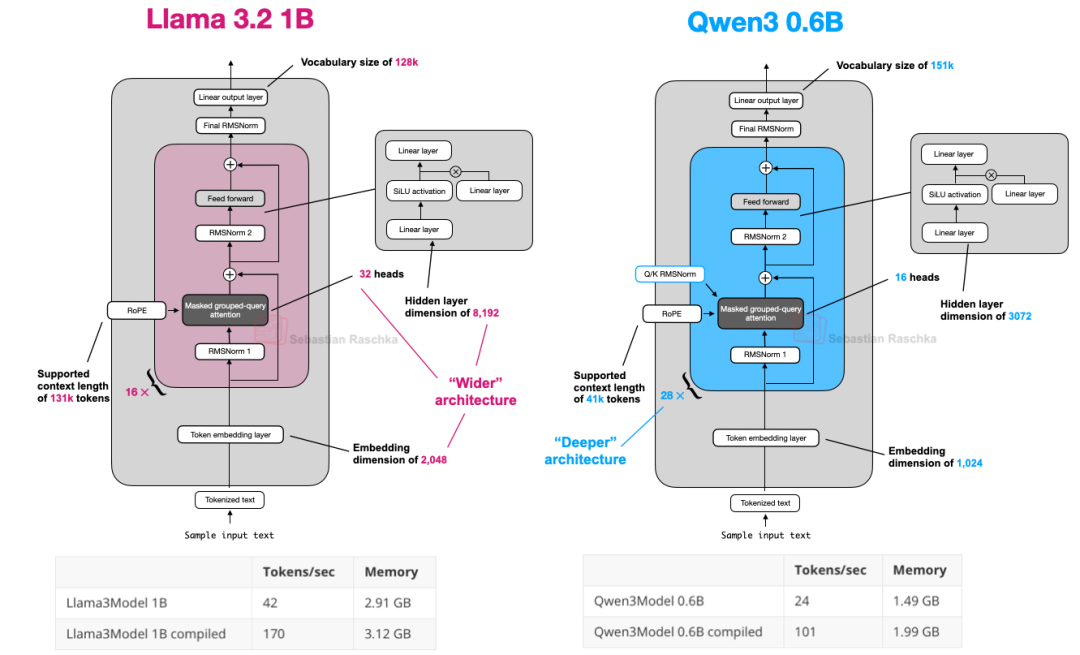
Qwen3的内存占用较小,因为它的整体架构较小,但使用的隐藏层和注意力头也更少。然而,它使用的Transformer模块比Llama3更多,这导致运行速度较慢(每秒生成token的速度较低)。
6、DeepSeek V3 vs Llama 4
Llama4Maverick架构总体上与DeepSeek-V3非常相似。
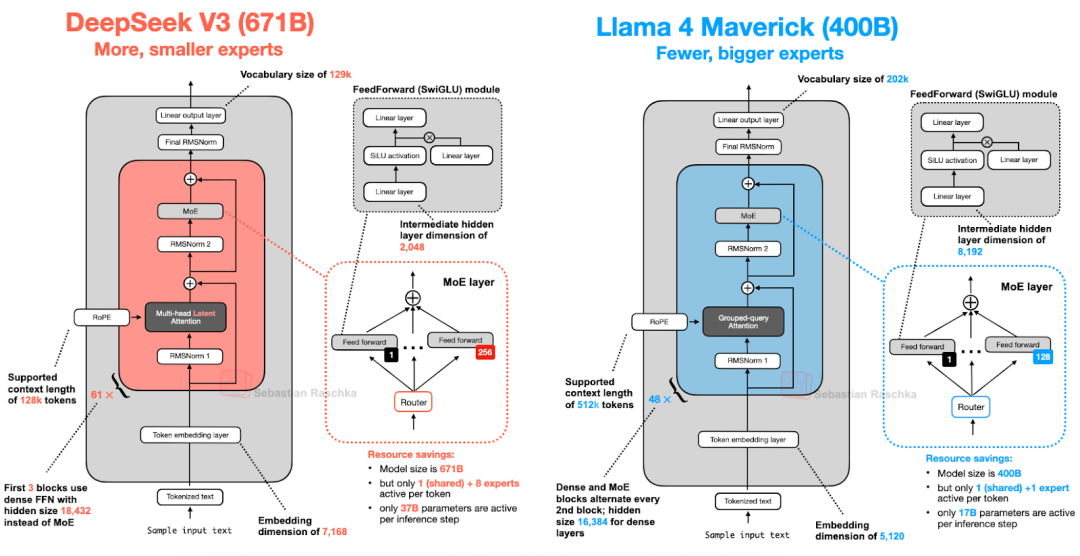
首先,Llama4使用了与其前代产品类似的分组查询注意力机制(Grouped-QueryAttention),而DeepSeek-V3则使用了多头潜在注意力机制(Multi-HeadLatentAttention)。
DeepSeek-V3和Llama4Maverick都是非常庞大的架构,**其中DeepSeek-V3的总参数数量大约比Llama4Maverick多68%**。然而,DeepSeek-V3拥有370亿个活跃参数,是Llama4Maverick(170亿)的两倍多。
Llama4Maverick采用了更经典的MoE设置,其专家数量更少但规模更大(2名活跃专家,每名专家的隐藏层大小为8,192),而DeepSeek-V3则使用了9名活跃专家,每名专家的隐藏层大小为2,048。
此外,DeepSeek在每个转换器模块(前3个除外)中都使用了MoE层,而Llama4则在每个转换器模块中交替使用MoE和密集模块。
7、Kimi-k2 VS DeepSeek V3
使用了相对较新的Muon优化器的一个变体来替代 AdamW。这是Muon 首次用于这种规模的生产模型,而非Adam,此前,它仅被证明可以扩展到16B
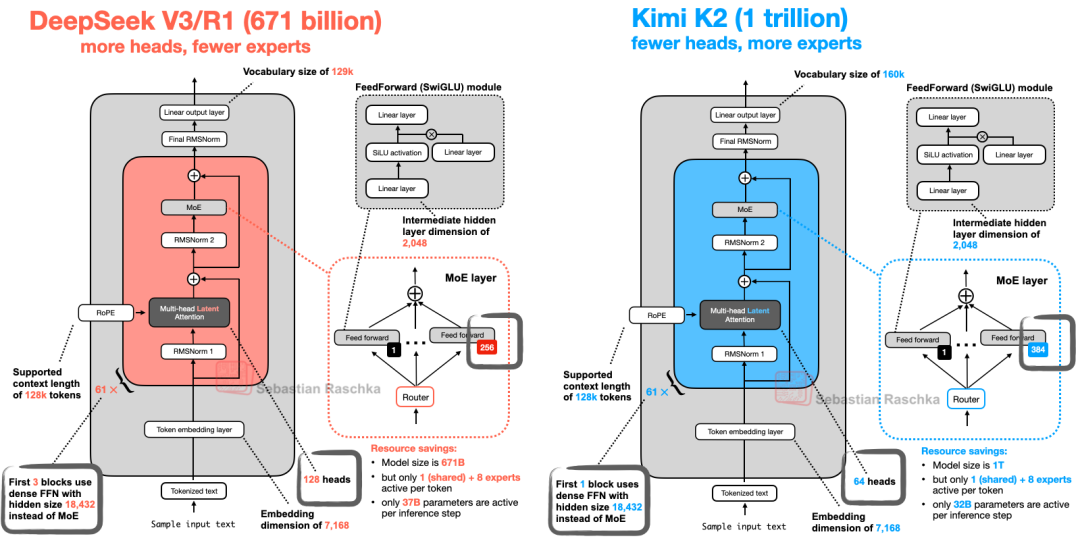
Kimi2.5与DeepSeek V3基本相同,只是它在 MoE模块中使用了更多的专家,而在多头潜在注意力 (MLA) 模块中使用了更少的头。
8、OLMo 2 vs Llama 3
OLMo2架构设计决策主要是RMSNorm的放置:将RMSNorm放在注意力和前馈模块之后而不是之前(后范式的一种),以及在注意力机制内为查询和键添加RMSNorm(QK-Norm),这两者共同有助于稳定训练损失。
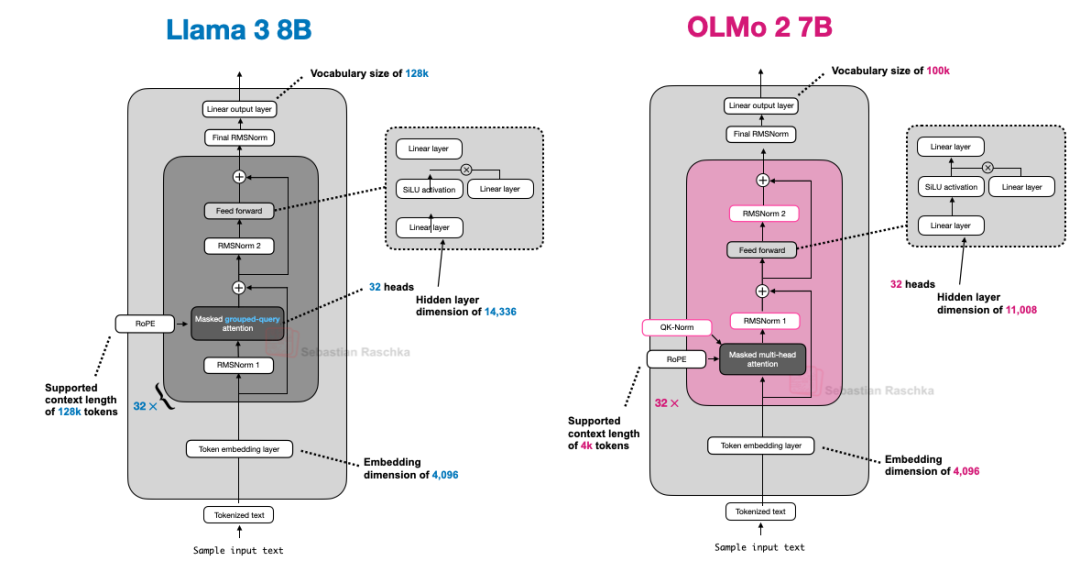
与Llama 3相比,除了OLMo2仍然使用传统的MHA而非GQA之外,它们的架构在其他方面相对相似。
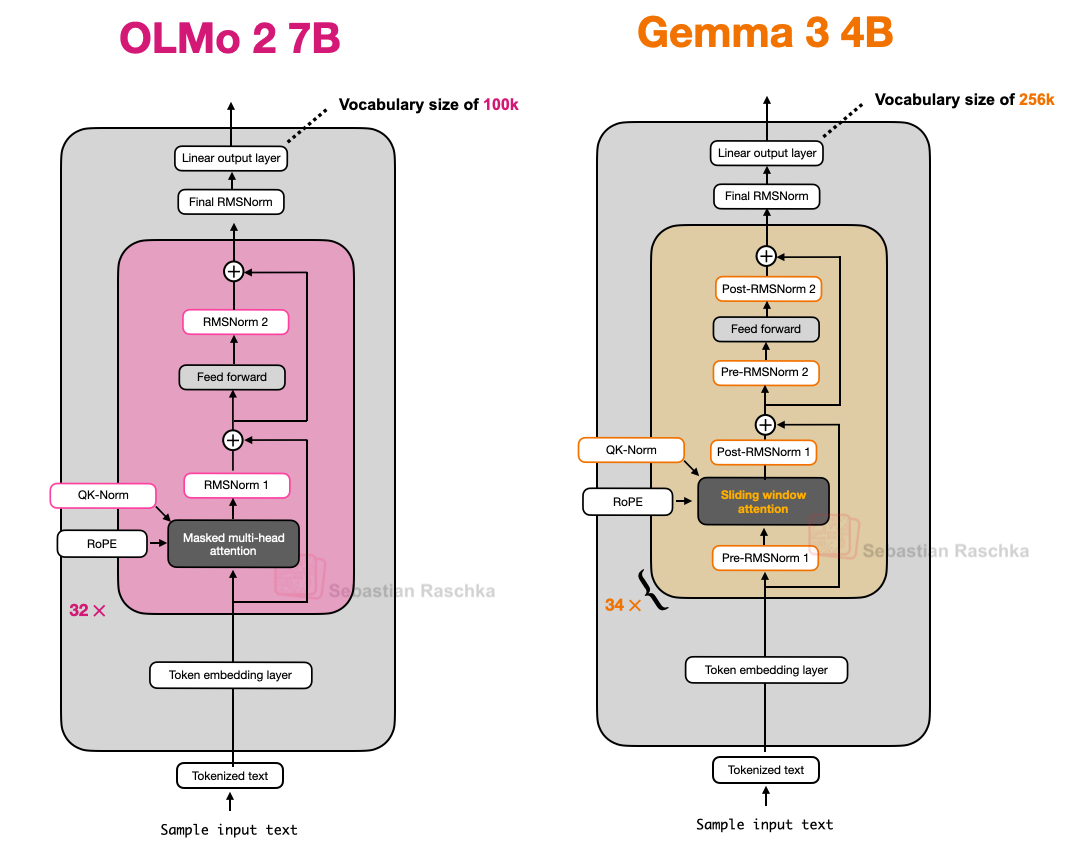
9、OLMo2 VS Gemma 3 & Gemma3n
Gemma的一大特色是其词汇量相当大(以便更好地支持多种语言),并且更注重27B的规模(而非8B或70B),借助滑动窗口注意力机制,Gemma3能够大幅减少KV缓存中的内存需求。
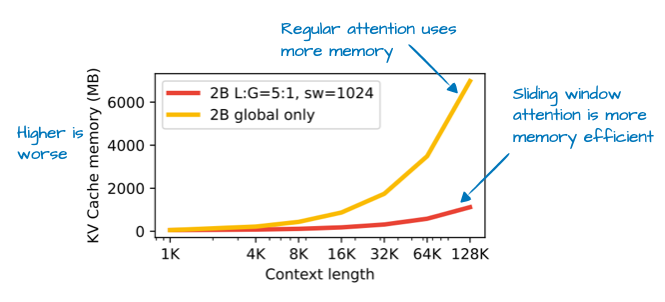
滑动窗口注意力机制也称为局部注意力机制,因为局部窗口会围绕当前查询位置并随之移动。相比之下,常规注意力机制则是全局的,因为每个标记都可以访问所有其他标记。
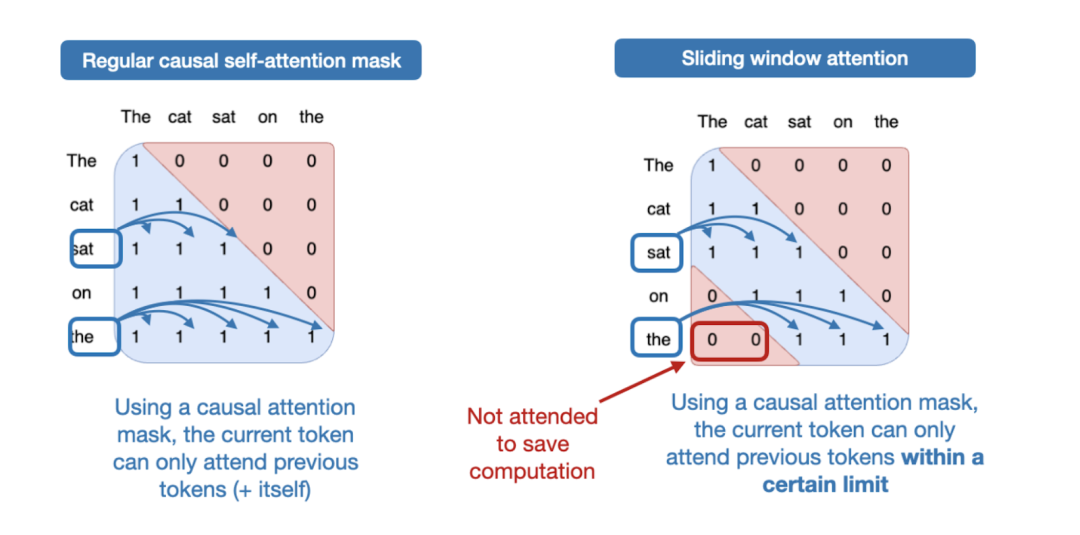
Gemma3的不同之处在于,调整了全局(常规)注意力机制和局部(滑动)注意力机制之间的比例。Gemma2采用了一种混合注意力机制,将滑动窗口(局部)注意力和全局注意力以1:1的比例组合在一起,每个token可以关注附近上下文的4k个token窗口,Gemma2每隔一层都使用滑动窗口注意力机制,而Gemma3则采用了5:1的比例,这意味着每5个滑动窗口(局部)注意力层中只有一个完整的注意力层;
此外,滑动窗口大小从4096(Gemma2)减小到1024(Gemma3)。这使得模型的重点转向更高效的局部计算。
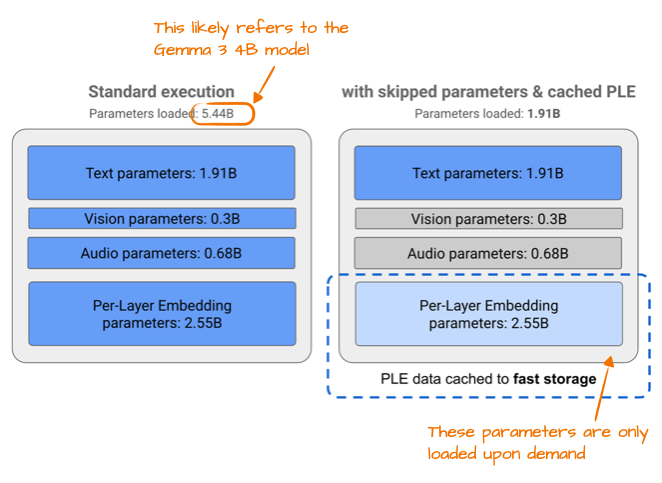
此外,Gemma3n,针对小型设备效率进行了优化,为了提高效率而做出的改进之一是所谓的“逐层嵌入 (PLE)”参数层。其核心思想是仅将模型参数的子集保存在 GPU 内存中。然后,特定于token层的嵌入(例如用于文本、音频和视觉模态的嵌入)将按需从 CPU 或 SSD 流式传输。
10、Gemma 3 27B VS Mistral 3.1 Small 24B
Mistral Small 3.1推理延迟低于Gemma 3 的原因很可能在于其自定义的分词器,以及缩减了键值缓存和层数。
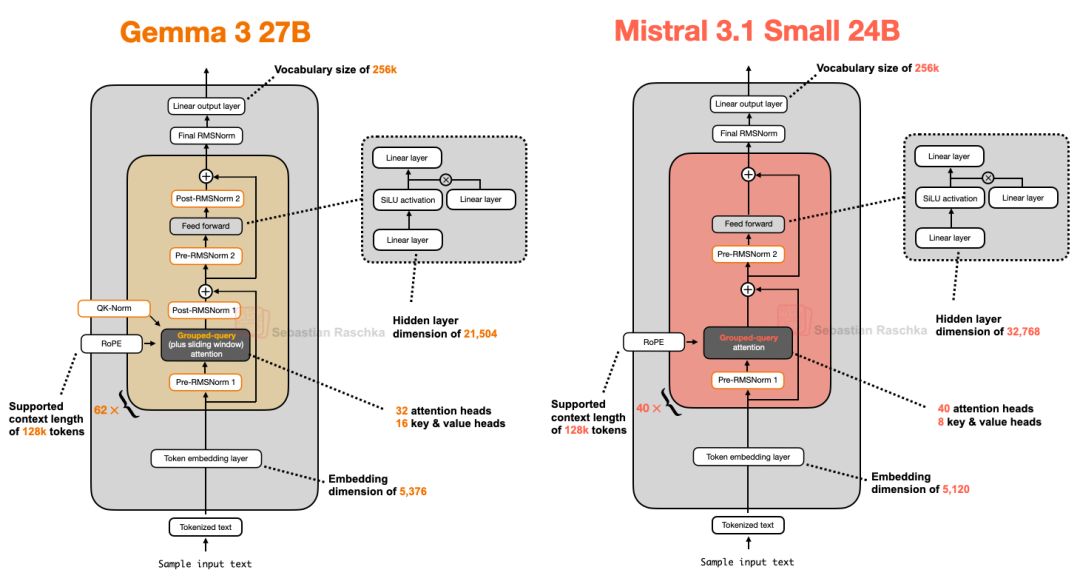
虽然滑动窗口注意力机制可以减少内存使用量,但它并不一定能降低推理延迟。
二、引入事件为核心的GraphRAG思路
GraphRAG进展,这次是结合事件去做,《DyG-RAG: Dynamic Graph Retrieval-Augmented Generation with Event-Centric Reasoning》,https://arxiv.org/pdf/2507.13396,https://github.com/RingBDStack/DyG-RAG,
这个其实是GraphRAG跟事件结合一个尝试,主要是回答这类问题:例如,“贝拉克·奥巴马在2008年之前做了什么?”、“贝拉克·奥巴马在2008年之后做了什么?“奥巴马的第一任期后他的外交政策是如何发展的?”之类的问题,需要推理一系列事件。
然后,怎么解决这个问题,那就是用图去做,但是基于图结构的检索增强生成(Graph RAG)方法在建模动态时序知识方面存在显著局限,无法有效处理现实世界中事件的结构演变与时序依赖关系,比如下面这个图,图中的节点和关系都不具备这种能力。
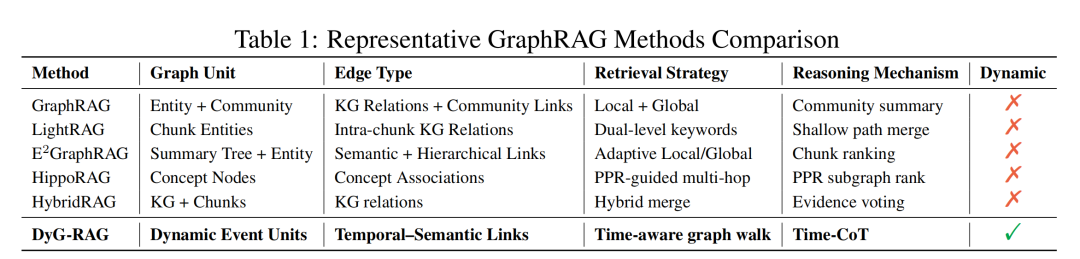
所以,一个很自然的想法就是结合使用时间知识图谱(TKGs),其中边被标注有时间戳来编码关系成立的时间。
所以做了一个基于事件中心推理的动态图检索增强生成,通过将事件的时间动态显式建模为图结构化表示,将文本分解为语义明确且时间锚定的原子事件单元,通过实体共现与时序邻近性建立事件间关联,支持多跳因果推理。
然后,在检索端,引入了一个事件时间线检索pipeline,通过时间感知的向量搜索和遍历来检索事件序列,提出了一种时间链式思维策略(Time Chain-of-Thought)用于时间感知的答案生成,有助于增强时间推理能力。
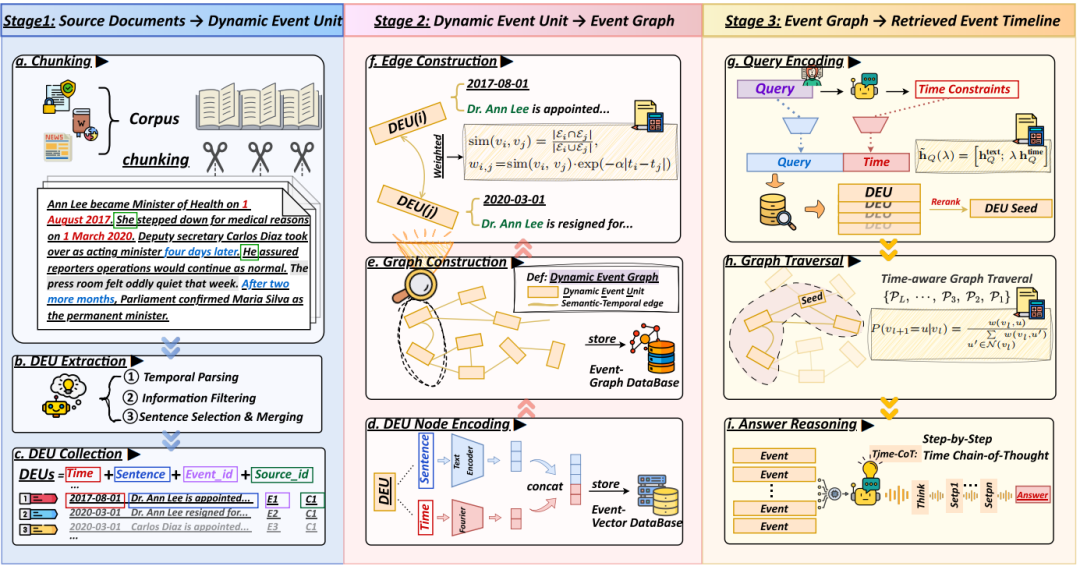
其中核心的核心是这个图怎么构建,包括两块。
1、事件单元怎么抽取?
提取流程包括四个关键组成部分:文档分块、时间解析、信息过滤以及句子选择和合并,核心是得到**动态事件单元(DEU)**。
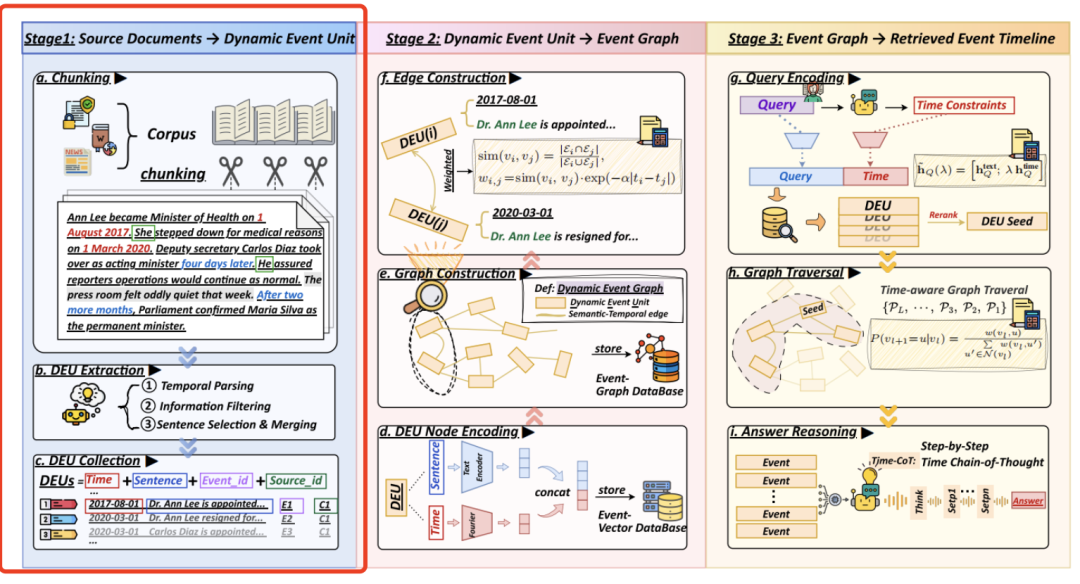
1)文档分块
首先将每个源文档di∈D分割成固定长度的重叠片段,以保持上下文连贯性并限制计算成本。为了减轻主题漂移并保持语义一致性,将文档标题添加到每个片段的开头。短于预定义片段长度的文档作为单个片段保留。随后,使用大模型从每个片段中提取候选事件以供下游处理。
2)时间解析
识别每个候选事件中的时间表达,并将它们规范化以创建一致的时间锚点,识别并按粒度优先级排列绝对时间戳(例如,“2008年3月”,“2021年6月15日”)。最细粒度的日期被指定为ti并存储在时间栈中以锚定未来事件。相对或模糊的表达(例如,“那一年早些时候”,“最近”)通过引用同一段落或上下文窗口内最新的绝对日期来解决。
时间间隔(例如(从2010年到2015年)在文本中保留其完整的时间跨度,但使用最早的时间点作为索引的ti。如果无法提取可靠的时间锚点,ti将被赋予一个静态值,表示无时间限制的背景事实。
3)信息过滤
为了确保检索到相关内容,根据关键属性的存在为每个候选事件句子计算一个信息分数:
1)包含命名实体或可互指代的指代。2)描述状态变化或具有事件性质谓词(例如,“变得”、“辞职”、“发起”)。3)包括结果或定量指标;4)以月级别精度或更高的精度锚定时间。
然后,为候选句子满足的每个标准分配一分。只有分数score(s)≥1的候选项被保留,此步骤移除了通用、描述不清或离题的句子。
4)句子选择与合并
对有效的事件单元进行规范化、消歧和聚合,以确保适当的粒度和语义连贯性。对于共指消解,用明确的实体提及替换模糊的代词。关于事件粒度,为每句话分配一个事件单元,除非多个紧密相关的事件共享相同的时间锚点,在这种情况下,它们谓词合并成一个协调的事件单元。
对于时间解析约束,具有不同日级别时间戳的事件不会被合并,以保持时间精度。
2、事件关系边怎么拉?
为了支持结构化检索和时间推理,将提取的DEU组织成一个动态事件图。
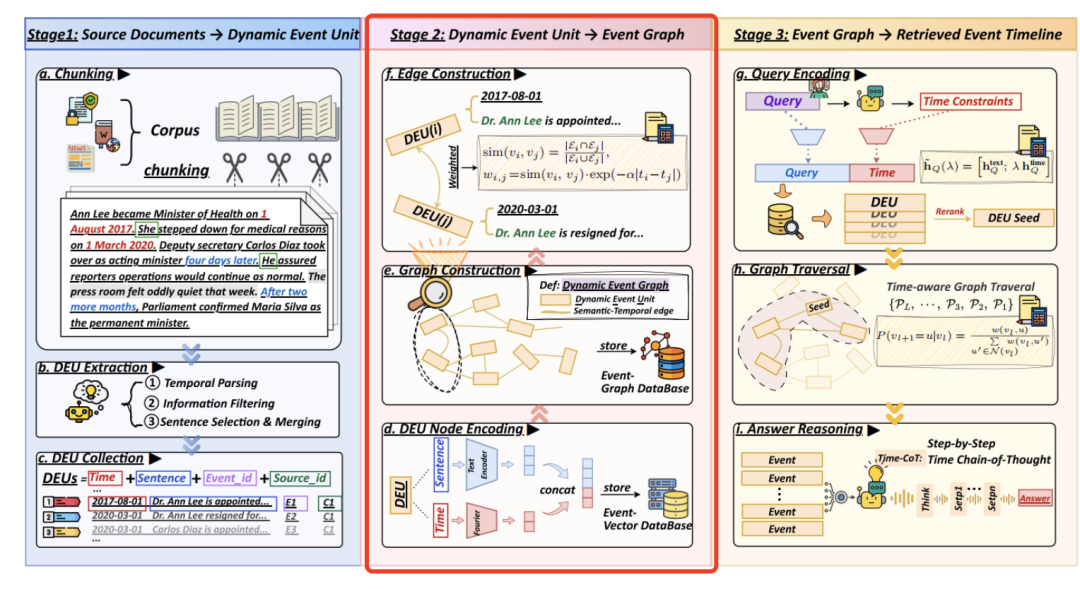
每个DEU被编码成一个融合了语义和时间的密集向量表示。具体来说,给定一个DEUvi及其句子文本si和时间戳ti,计算出一个嵌入。边构建和加权。
事件图中DEU节点之间的边,也就是当节点vi和vj之间满足以下条件时,才会拉一条边:两个DEU必须至少提到一个共同的命名实体或共指实体,它们的时间戳之间的绝对时间差必须在阈值窗口Δt内。
这里的逻辑是,两个事件之间的语义接近性,可以利用它们所涉及的实体来计算各自实体集的重叠部分。
这两个图构建好之后,剩余的检索就自然而然了,这个不再赘述,我们重点还是关注构图本身。
参考文献
1、https://sebastianraschka.com/blog/2025/the-big-llm-architecture-comparison.html
2、https://arxiv.org/pdf/2507.13396
(文:老刘说NLP)