

西风 发自 凹非寺
量子位 | 公众号 QbitAI
无需CUDA代码,给H100加速33%-50%!
Flash Attention、Mamba作者之一Tri Dao的新作火了。
他和两位普林斯顿CS博士生提出了一个名叫QuACK的新SOL内存绑定内核库,借助CuTe-DSL,完全用Python写,一点CUDA C++代码都没用到。
在带宽3TB/s的H100上,它的速度比像PyTorch的torch.compile、Liger这类已经过深度优化的库还要快33%-50%。
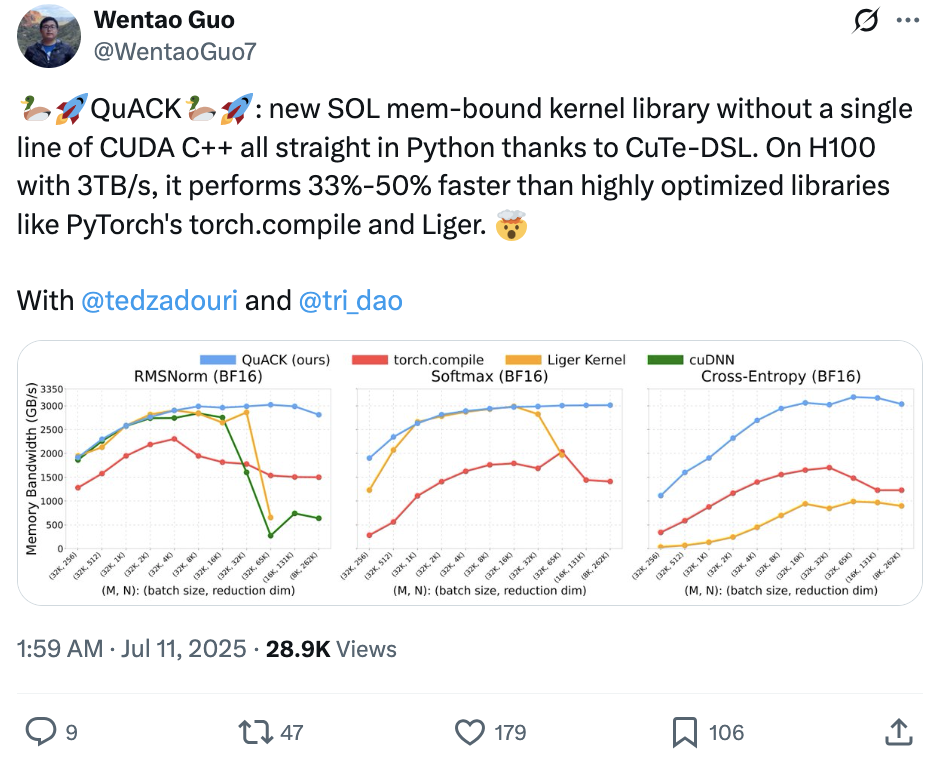
Tri Dao表示,让内存密集型的内核达到“光速”并非什么神秘技巧,只需把几个细节处理到位就行。

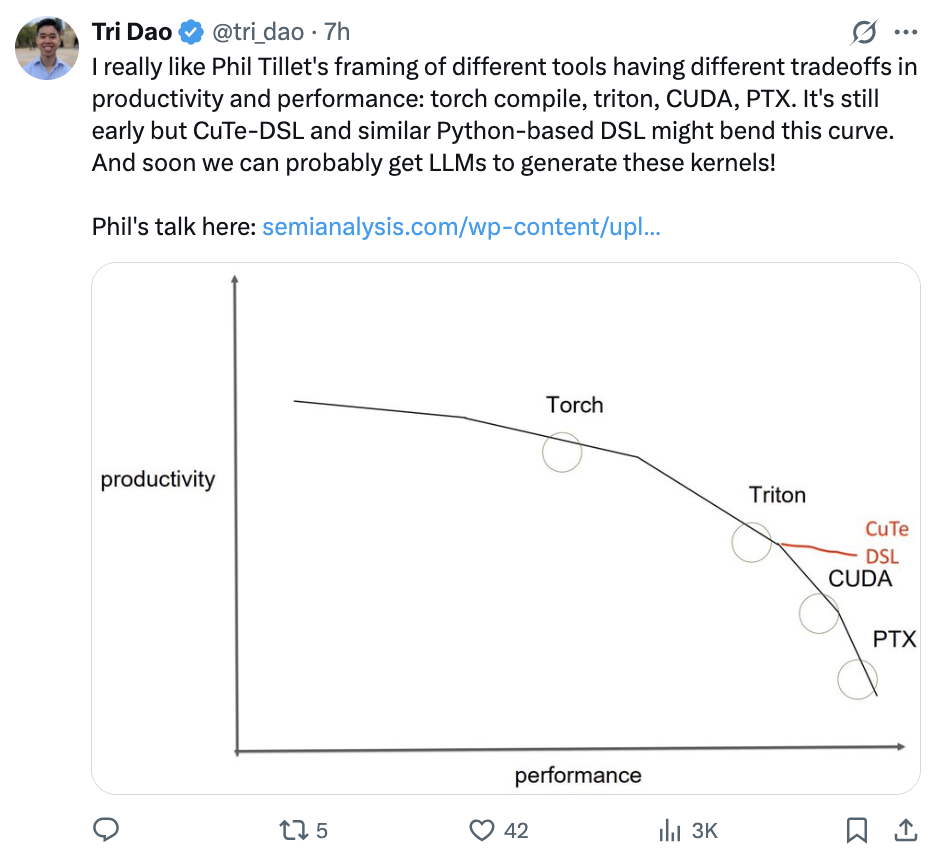
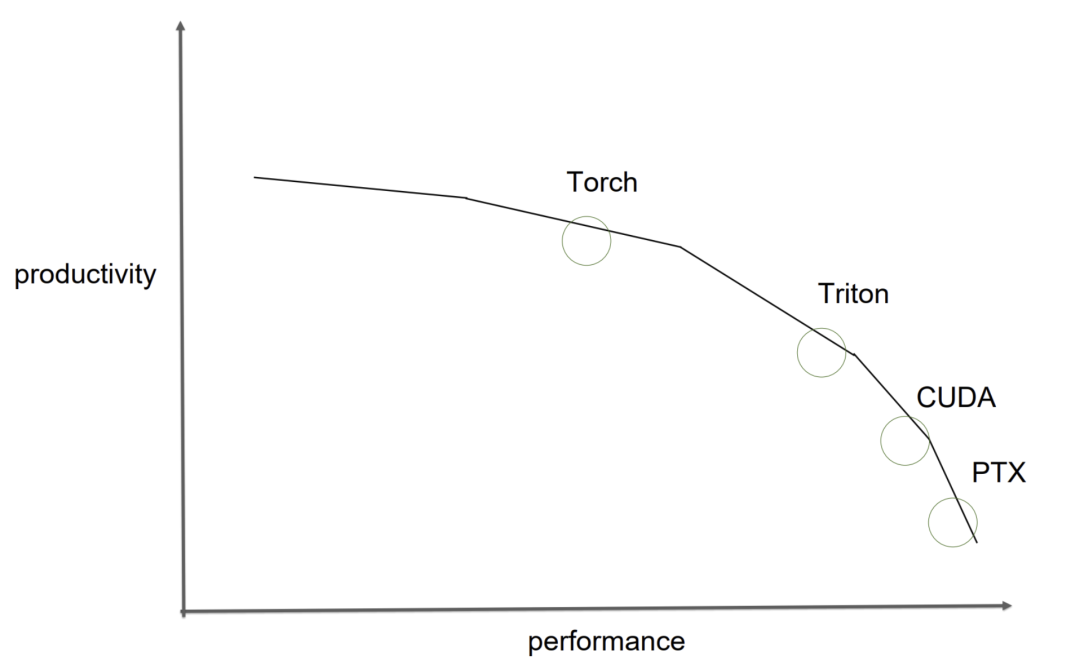
我很喜欢Phil Tillet对不同工具在生产力和性能方面各有取舍的观点,比如torch compile、triton、CUDA、PTX。
但CuTe-DSL以及类似的基于Python的DSL或许能改变这一局面,虽然目前还处于早期阶段。而且,说不定很快我们就能让大语言模型来生成这些内核了!
新作一经发出,吸引不少大佬关注。
英伟达CUTLASS团队资深架构师Vijay转发,自夸他们团队做的CuTe-DSL把各种细节都打磨得很好,由此像Tri Dao这样的专家能够让GPU飞速运行。
同时他还预告今年会有更多相关内容推出。
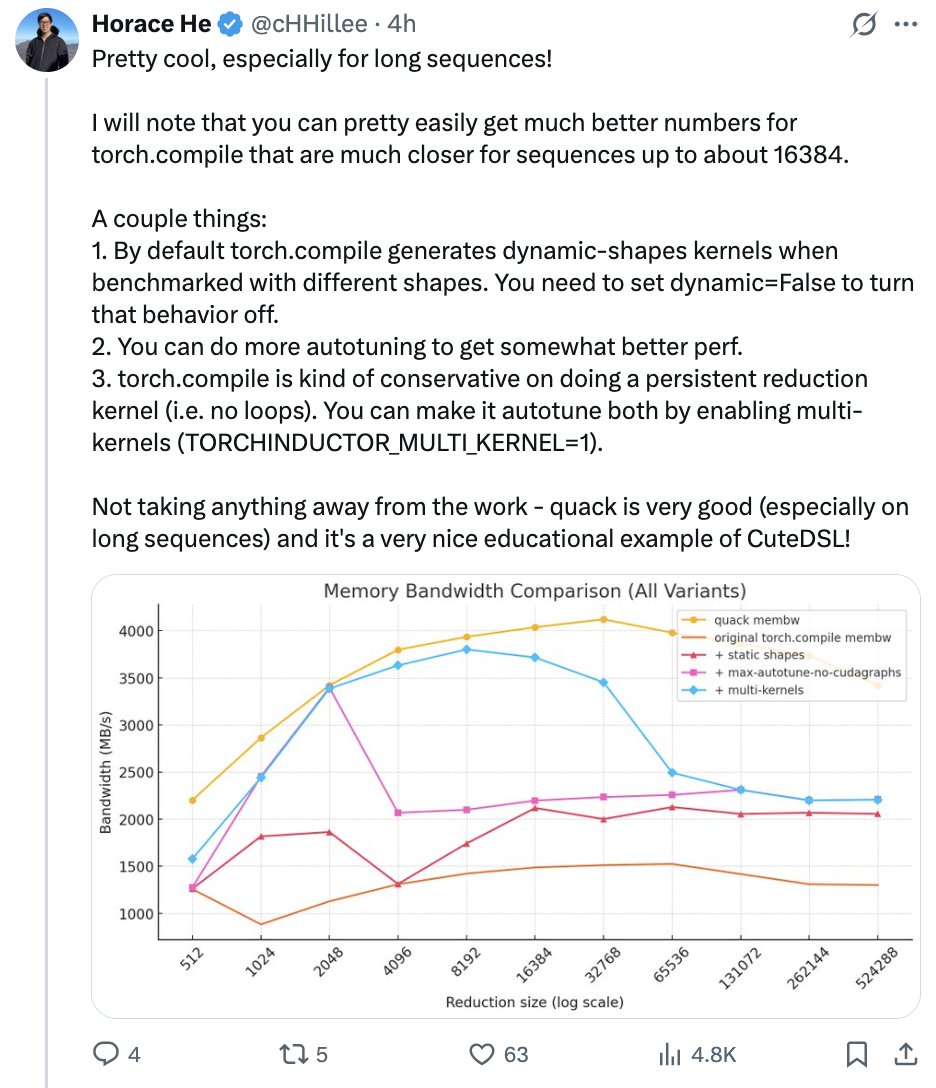
同样被吸引而来的还有PyTorch团队成员Horace He,上来就夸赞“太酷了,尤其对于长序列来说”。
不过他还指出,在处理长度不超过约16384的序列时,PyTorch的torch.compile的性能数据能较轻松地得到优化,更接近理想状态。
接着给出了几点优化torch.compile性能的建议:
默认情况下,若用不同形状数据测试,torch.compile会生成动态形状内核,可通过设置dynamic=False关闭该行为。
进行更多自动调优操作能进一步提升性能。
torch.compile在生成无循环的持久化归约内核上较保守,可通过启用多内核(设置
(TORCHINDUCTOR_MULTI_KERNEL=1)来让其自动调优。
最后他表示,还是不可否认QuACK是一项非常出色的工作,而且它也是CuTe-DSL一个很好的教学示例。
Tri Dao也作出了回应,“太棒了,这正是我们想要的,我们会试试这些方法,然后更新图表”。

食用指南
QuACK作者们写了一篇教程来介绍具体做法,里面的代码可以直接使用。
让内存密集型内核达到“光速”
想让GPU在模型训练和推理时都高速运转,就得同时优化两种内核:一种是计算密集型(比如矩阵乘法、注意力机制),另一种是内存密集型(像逐元素运算、归一化、损失函数计算)。
其中,矩阵乘法和注意力机制已经是优化得相当到位了。所以作者这次把重点放在内存密集型内核上——这类内核大部分时间都耗在内存访问(输入输出)上,真正用来计算的时间反而不多。
只要搞懂并利用好现代加速器的线程和内存层级结构,就能让这些内核的速度逼近“理论极限”。而且多亏了最新的CuTe-DSL,不用写CUDA C或C++代码,在顺手的Python环境里就能做到这一点。
内存密集型的内核有个特点:它的算术强度(也就是浮点运算量FLOPs和传输字节数的比值)很小。一旦内核的算术强度落到内存密集型的范畴,它的吞吐量就不再由每秒能完成多少浮点运算决定,而是看每秒能传输多少字节了。
在这类内存密集型的内核里,逐元素的激活操作处理起来相对简单。因为每个元素的计算互不干扰,天生就适合完全并行处理。
不过,像softmax、RMSNorm这些深度学习算子中,还经常用到“归约”操作,需要对所有值进行聚合。
并行的结合性归约算法会执行O (log (归约维度数)) 轮的部分归约,这些归约在不同空间的线程间进行,而作者对 GPU内存层级的了解将在此过程中发挥作用。
并行最大归约:
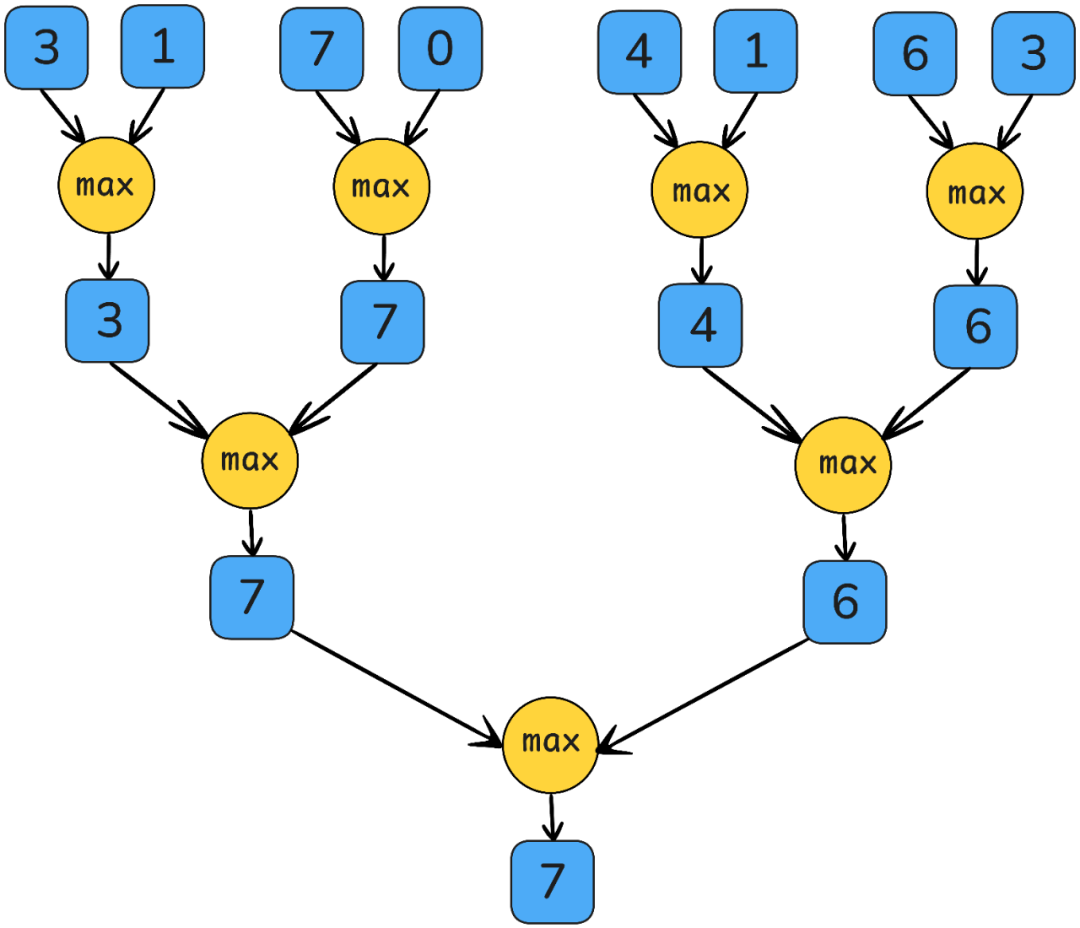
接下来,作者将介绍如何利用GPU的内存层级结构来实现高效的归约内核。
作为示例,使用CuTe DSL实现了大语言模型里常用的三个内核:RMSNorm、softmax和交叉熵损失。
目标是达到硬件的最大吞吐量,即 “GPU光速吞吐量”,而这需要两个关键要素:1)全局内存的合并加载/存储;2)硬件感知的归约策略。
此外,作者还将解释集群归约,以及它如何助力超大规模归约任务,这是英伟达GPU从Hopper架构(H100)开始引入的一个较新特性。
然后,详细讲解这些关键要素的细节,并阐述它们如何帮助编写“光速”内核。

GPU内存层级结构
在写内核代码前,得先搞明白现代GPU的内存层级是怎么回事。这里以Hopper架构的GPU(比如 H100)为例进行说明。
Hopper架构的GPU里,CUDA的执行分为四个层级:线程(threads)、线程块(thread blocks)、新引入的线程块集群(thread block cluster)以及完整网格(the full grid)。
单个线程是在流式多处理器(SM)里,以32个线程一组的“warp”形式运行的;每个线程块拥有一块192-256 KB的统一共享内存(SMEM),同一线程块内的所有warp都可访问该内存。
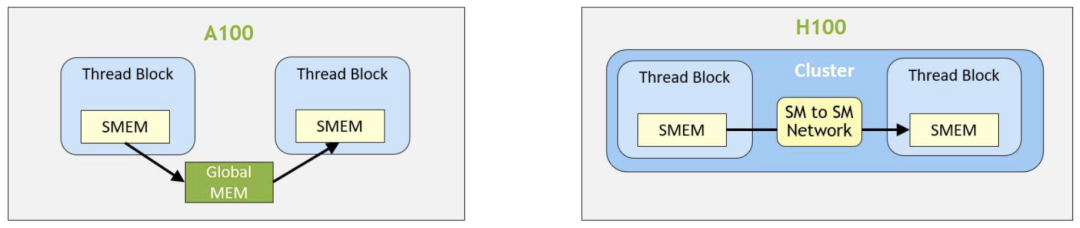
H100的线程集群允许最多16个运行在相邻SM上的线程块,通过分布式共享内存(DSMEM)结构读取、写入彼此的共享内存并执行原子操作。这一过程通过低延迟的集群屏障进行协调,从而避免了代价高昂的全局内存往返传输。
内存的每个层级都有用于本地归约的读写原语。因此,作者将在CuTe DSL中开发一个通用的归约模板,使H100在256-262k的归约维度范围内始终达到“光速”吞吐量。
H100中的内存层级结构:
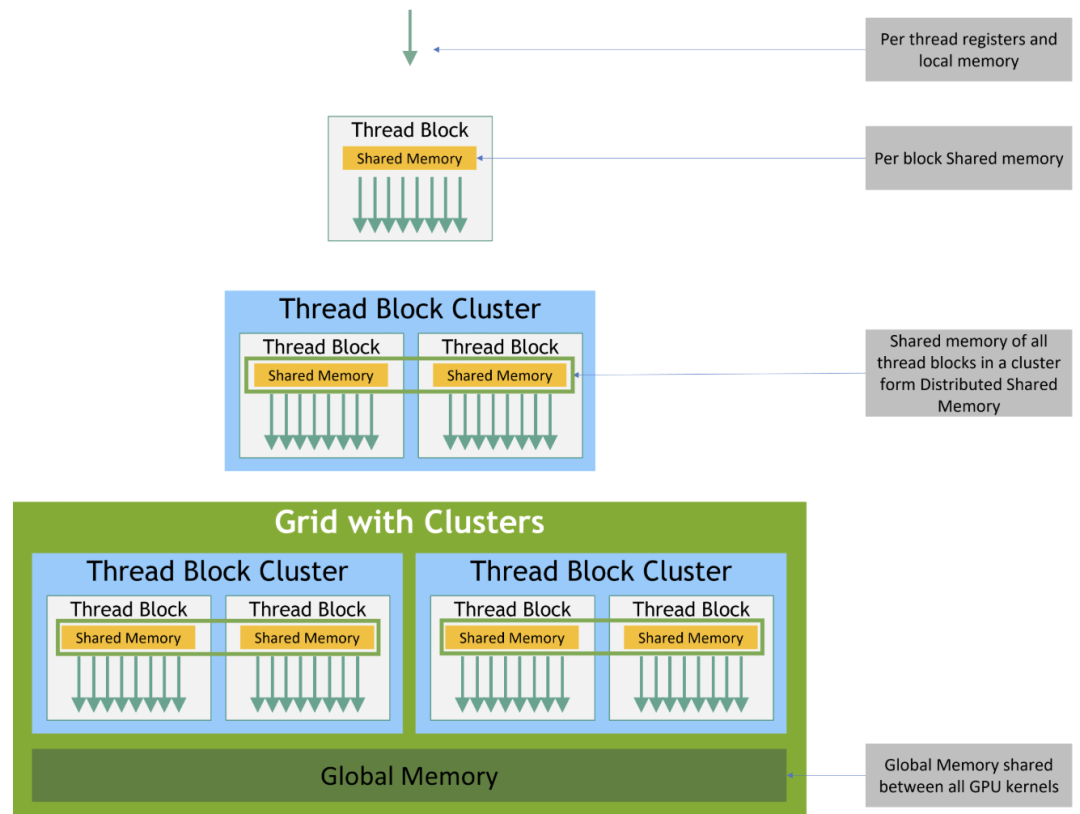
Hopper GPU的执行粒度与内存层级之间的对应关系:
每个内存层级的访问延迟和带宽都不一样。
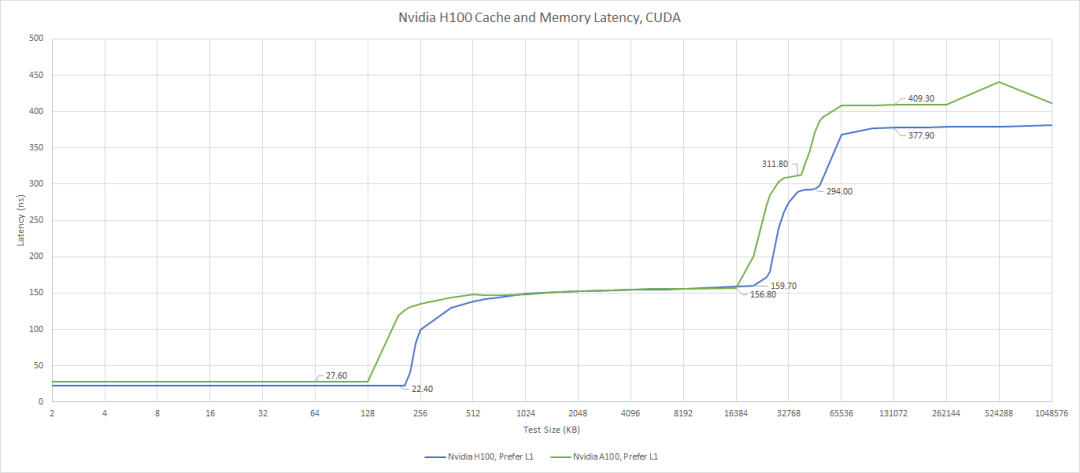
比如,访问线程自己的寄存器也就几纳秒,访问共享内存大概要 10-20纳秒。再往上,访问L2缓存的延迟就会飙升到150-200纳秒,最后访问DRAM(主存)得花约400纳秒。
带宽方面,访问寄存器能达到100 TB/s,访问共享内存(SMEM)约为20-30 TB/s,访问L2缓存是5-10 TB/s。对于受内存限制的内核来说,H100的HBM3显存带宽(3.35TB/s)往往是性能瓶颈。
所以,为了把硬件性能榨干,设计内存密集型的内核时,得顺着内存层级来:
最好将大部分本地归约操作分配在较高的内存层级上,只将少量经过本地归约后的值传递到下一个内存层级。Chris Fleetwood在博客里对A100(不含线程块集群)的内存访问延迟进行了类似的说明,而H100则在共享内存(SMEM)和全局内存(GMEM)之间增加了一个额外的内存层级抽象。
H100中内存访问的延迟:
硬件感知的加载与存储策略
写内核代码时,第一个要解决的问题就是“怎么加载输入数据、存储结果”。对于受内存限制的内核来说,HBM的3.35 TB/s通常是瓶颈,这意味着需要在加载和存储策略上做到极致优化。
在启动内核之前,首先会通过特定的线程-值布局(TV-layout)对输入数据进行分区。这决定了每个线程怎么加载和处理归约维度上的值。
由于每个线程都要从全局内存(GMEM)加载数据,所以得想办法确保每次加载操作在硬件上连续地传输最大数量的bits。这种技术通常被称为内存合并(memory coalescing)或全局内存的合并访问(coalesced access to global memory),CUDA最佳实践指南对这一概念进行了更详细的解释。
合并内存访问:
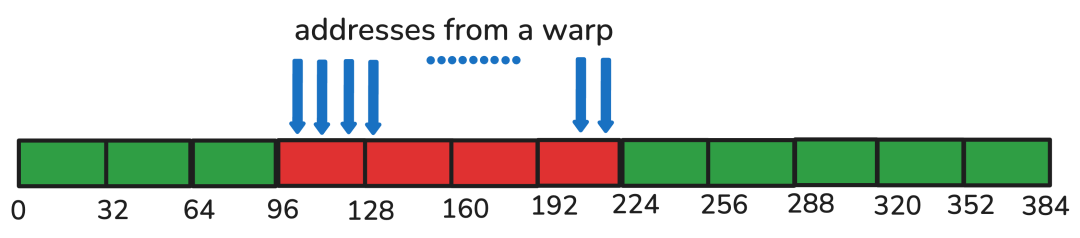
在H100中,这意味着每个线程处理的数据量得是128bits的倍数, 即4xFP32或者8xBF16。因此,对于FP32来说,这会将4次加载和存储操作组合(或“向量化”)为一次内存事务,从而最大化吞吐量。
具体操作上,作者会异步地将数据从全局内存(GMEM)加载到共享内存(SMEM),然后将加载操作向量化到寄存器中。等归约出最终结果后,就直接存回全局内存。
有时候,还可以把输入数据从全局内存或共享内存重新读到寄存器,这样能减少寄存器的占用,避免数据“溢出”。
下面是用Python CuTe DSL写的加载操作代码片段,为了看着简单,这里省略了数据类型转换和掩码谓词的相关代码。

硬件感知的归约策略
当每个线程持有一个小的输入向量后,就可以开始对它们进行归约了。每次归约都需要进行一次或多次完整的行扫描。
回想一下,从内存层级的顶层到低层,访问延迟逐渐增加,而带宽逐渐减少。
因此,归约策略应遵循这种硬件内存层级:
一旦部分结果存留在内存金字塔的较高层级中,就立即对其进行聚合,只将经过本地归约后的值传递到下一个内存层级。
作者会按照下表从顶层到低层对值进行归约,并且每一步都只在对应的内存层级中进行加载和存储操作。
不同内存层级中的归约策略:
1、线程级归约(读写寄存器)
每个线程会在本地对多个向量化加载的值进行归约。作者使用TensorSSA.reduce函数,其中需要传入一个可结合的归约算子op、归约前的初始值init_val,以及归约维度reduction_profile。

2、Warp级归约(读写寄存器)
warp是由32个连续线程组成的固定组,每周期会执行相同的指令。(同步的)warp归约允许同一Warp内的每个线程通过专用的洗牌(shuffle)网络,在一个周期内读取另一个线程的寄存器。经过蝶式warp归约后,同一warp中的每个线程都会得到归约后的值。
作者定义了一个辅助函数warp_reduce,用于以“蝶式”归约顺序执行Warp归约。关于warp级原语的详细解释,读者可参考Yuan和Vinod撰写的CUDA博客“Using CUDA Warp-Level Primitives”。
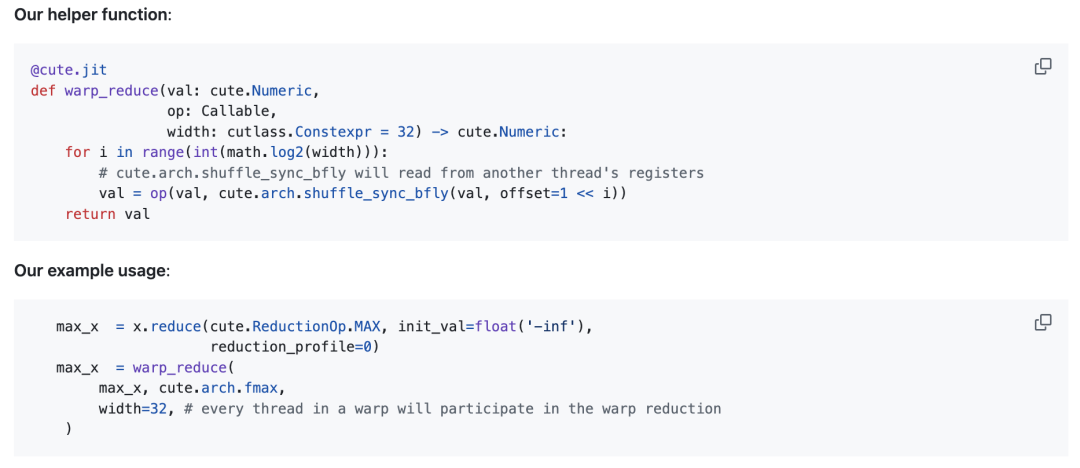
蝶式warp归约(Butterfly warp reduction),也称为 “xor warp shuffle”:
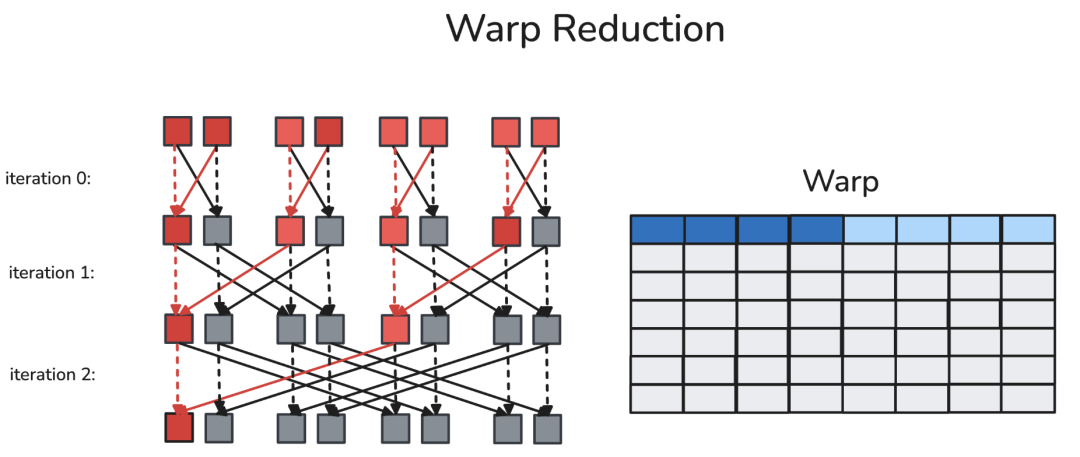
3、线程块级归约(读写共享内存)
一个线程块通常包含多个(在H100中最多32个)warp。在线程块归约中,每个参与归约的warp中的第一个线程会将该warp的归约结果写入共享内存中预先分配的归约缓冲区。
在经过线程块级同步(屏障)确保所有参与的warp都完成写入后,每个warp的首线程会从归约缓冲区中读取数据,并在本地计算出线程块的归约结果。

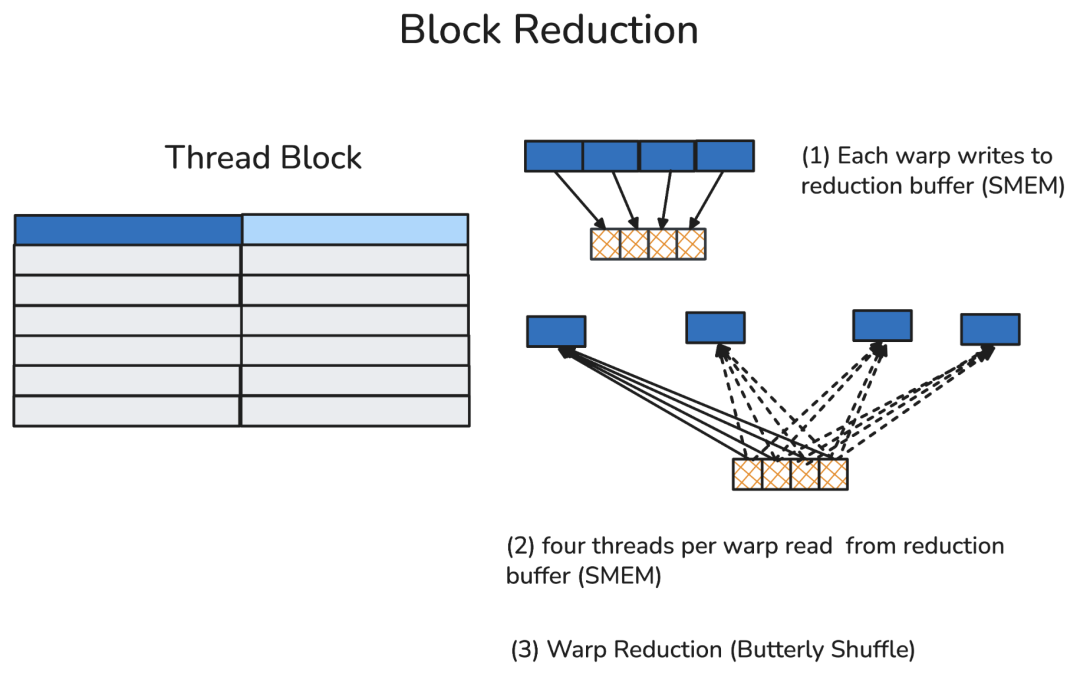
4、集群归约(读写分布式共享内存)
线程块集群是Hopper架构中新增的执行层级,由一组相邻的线程块(最多16个)组成。同一集群内的线程块通过分布式共享内存(DSMEM)进行通信,这种内存有专门的高速SM间网络支持。
在同一集群中,所有线程都可通过DSMEM访问其他SM的共享内存,其中共享内存的虚拟地址空间在逻辑上分布于集群内的所有线程块。DSMEM可通过简单的指针直接访问。
分布式共享内存:
在集群归约中,作者首先把当前warp的归约结果通过专用的SM间网络(也就是DSMEM),发送到其他对等线程块的共享内存缓冲区里。
随后,每个warp从其本地归约缓冲区中获取所有warp的值,并对这些值进行归约。
这里还得用到一个内存屏障用来统计数据到达的数量,以避免过早访问本地共享内存(否则会导致非法内存访问的错误)。
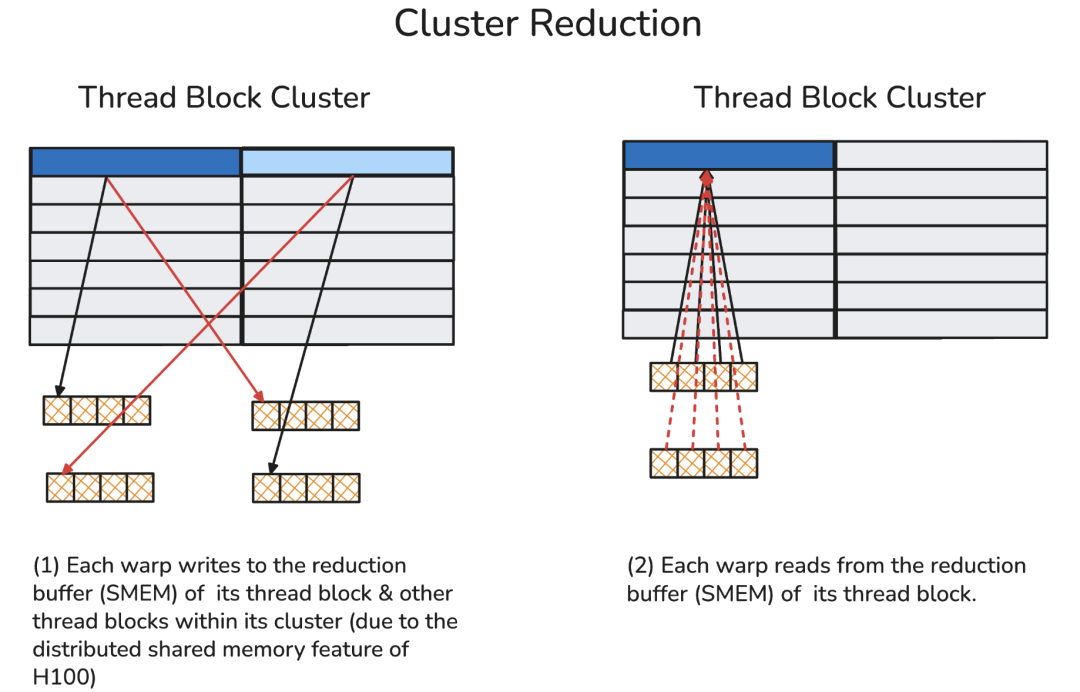

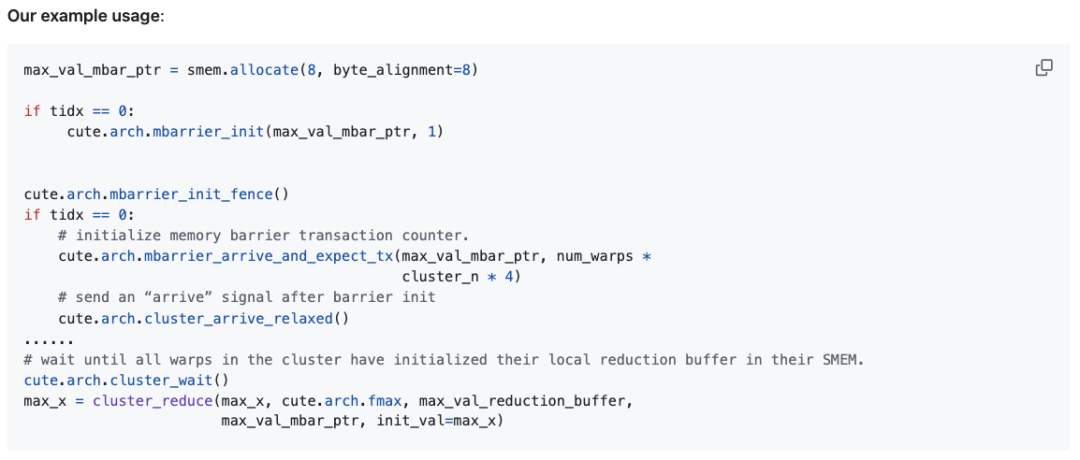
把整个归约流程串起来看:首先做线程级归约,然后在同一个warp内聚合线程级归约的结果(即warp级归约),接着根据归约维度的数量,在每个线程块或线程块集群上进一步传递归约后的值。
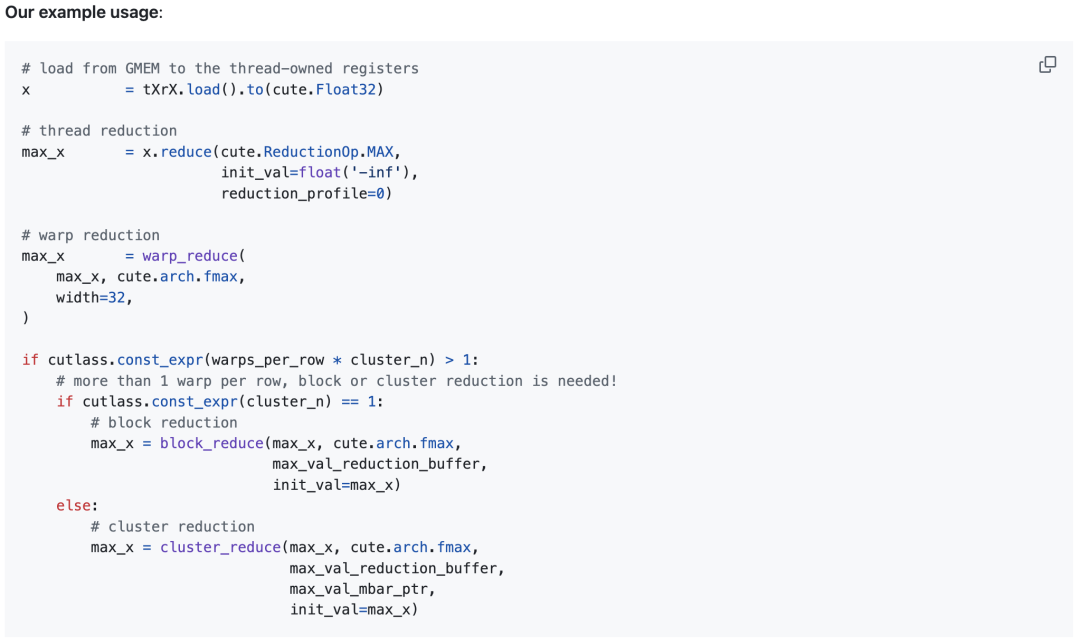
NCU 性能分析(Softmax 内核)
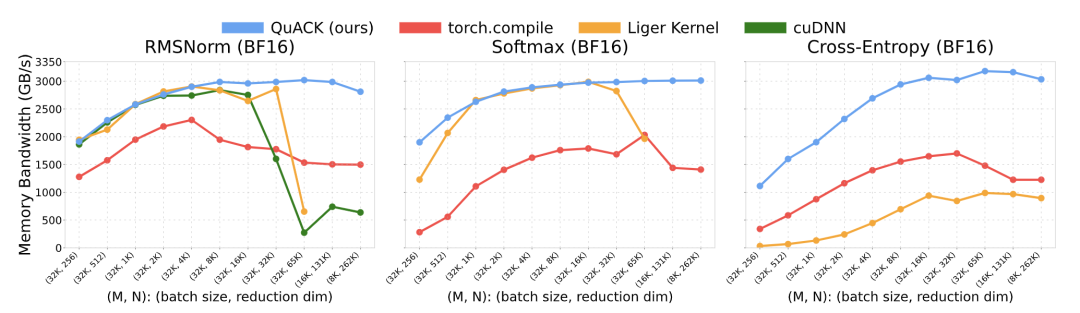
作者在配备HBM3显存(DRAM峰值吞吐量=3.35 TB/s)的NVIDIA H100 上,对批量维度为16K、归约维度为 131K的softmax内核做了性能测试。内存工作负载图由Nsight Compute生成。
配置是:线程块集群大小为4,每个线程块有256个线程,输入数据类型为FP32。加载和存储操作都做了向量化处理,每条指令一次搬运128 bits数据(也就是4 FP32值)。
最终测出来的DRAM吞吐量也就是显存带宽利用率达到了3.01TB/s,相当于DRAM峰值吞吐量的89.7%。除了共享内存(SMEM)外,还高效利用了分布式共享内存(DSMEM)。
该方案的内存工作负载图:
作者还拿自己的实现与torch.compile(PyTorch 2.7.1 版本)进行了对比。
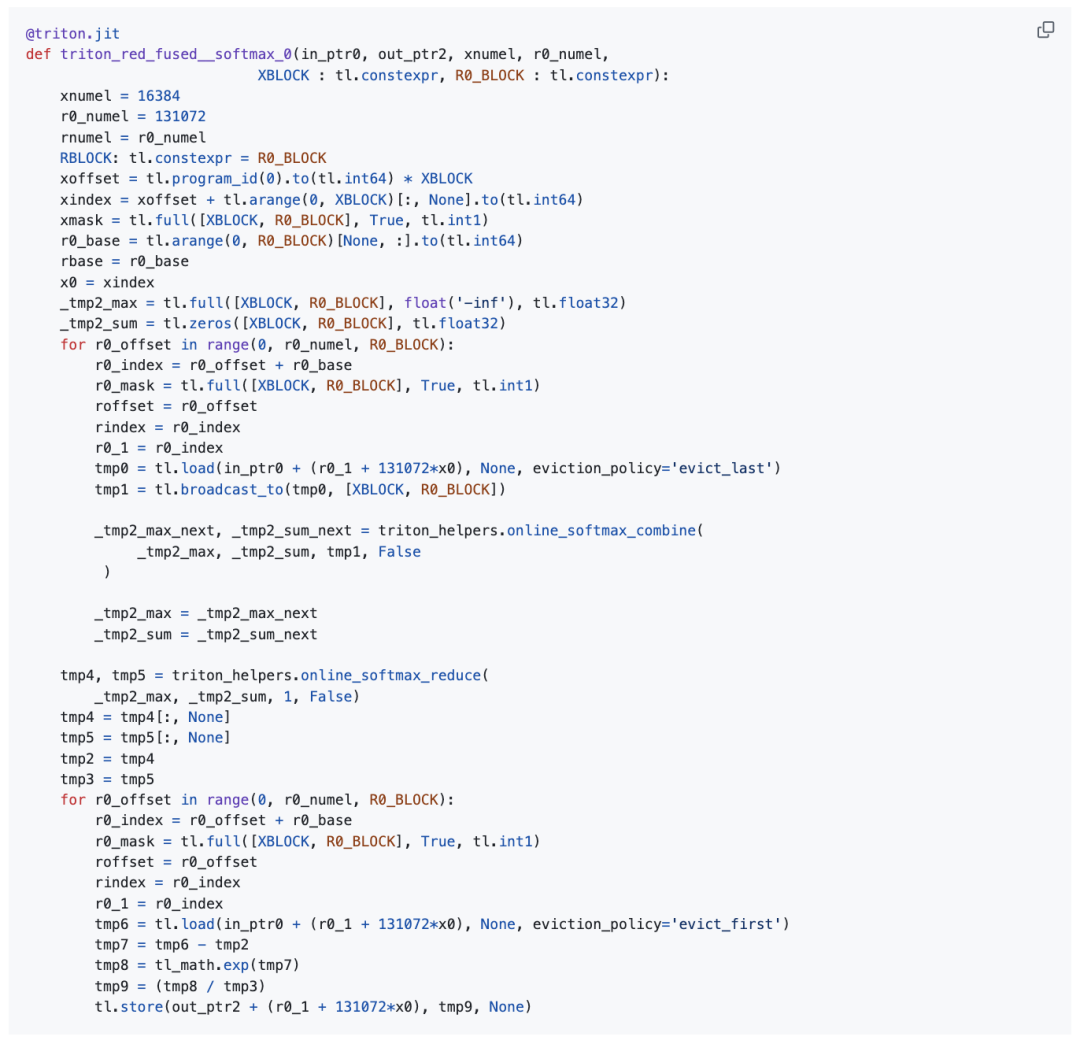
首先,获取了torch.compile生成的Triton内核代码。
该内核实现softmax时包含2次全局内存加载(计算行最大值和部分指数和时各加载1次,以及最终的softmax 值)和1次存储。
在这种情况下,尽管该Triton内核仍能使硬件的DRAM吞吐量跑满,但额外的1次不必要加载会导致Triton 内核的有效模型内存吞吐量(约2.0 TB/s)仅为本文作者实现方案的三分之二(约3.0 TB/s)。
torch.compile生成的Triton内核(调优配置部分省略):
内存吞吐量
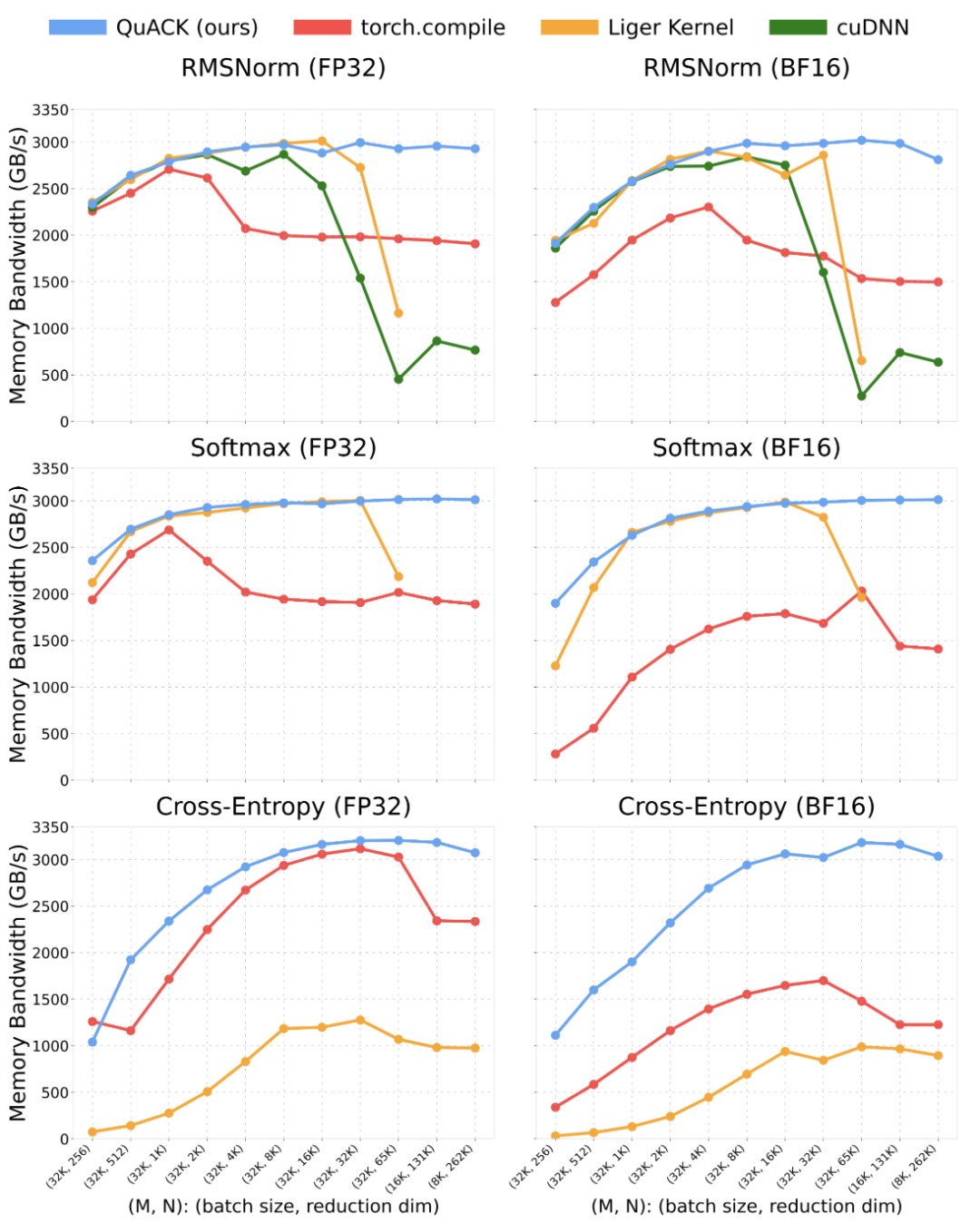
作者对RMSNorm、softmax和交叉熵损失这几个内核做了基准测试。测试仍在配备HBM3显存的1块NVIDIA H100 80GB GPU和Intel Xeon Platinum 8468 CPU上进行。
测试中使用的批量大小范围为8k-32k,归约维度范围为256-262k(256×1024),输入数据类型为FP32和 BF16。
基准对比方案如下:
-
Torch.compile(PyTorch 2.7.1版本):使用默认编译模式。 -
Liger 内核 v0.5.10版本 :只测了RMSNorm 和 softmax,且归约维度最多到65k(因为它目前不支持更大的维度)。 -
cuDNN v9.10.1版本:只测了RMSNorm内核。
作者基于CuTe DSL的实现方案,在归约维度大于4k时,内存吞吐量一般能稳定在3TB/s左右(差不多是峰值的90%)。
归约维度262k时,FP32的softmax吞吐量能到3.01TB/s,而torch.compile只有1.89TB/s,快了近50%。对于这3个内核,当归约维度≥65k 时,该实现方案显著优于所有基准对比方案。
多个内核的模型内存吞吐量:
作者认为,在输入规模≥65k时的优异性能得益于成功利用了H100中的集群归约。
当输入数据量大到把SM的寄存器和共享内存都占满时,如果不用集群归约,就只能换成在线算法(比如在线softmax);不然的话,寄存器里的数据会大量“溢出”,导致吞吐量显著下降。
举个例子,作者观察到,当使用Liger softmax内核时,输入规模从32k涨到65k,吞吐量就从约3.0 TB/s掉到了2.0 TB/s左右。
作者用NCU(Nsight Compute)工具分析了它的内存负载图和SASS代码,发现当每个SM要加载65k数据时,SM的资源被耗尽,结果就是大量寄存器溢出,还会频繁往HBM里回写数据,这才拖慢了速度。
Liger softmax内核在批量维度为16k、归约维度为65k且数据类型为FP32时的内存工作负载:
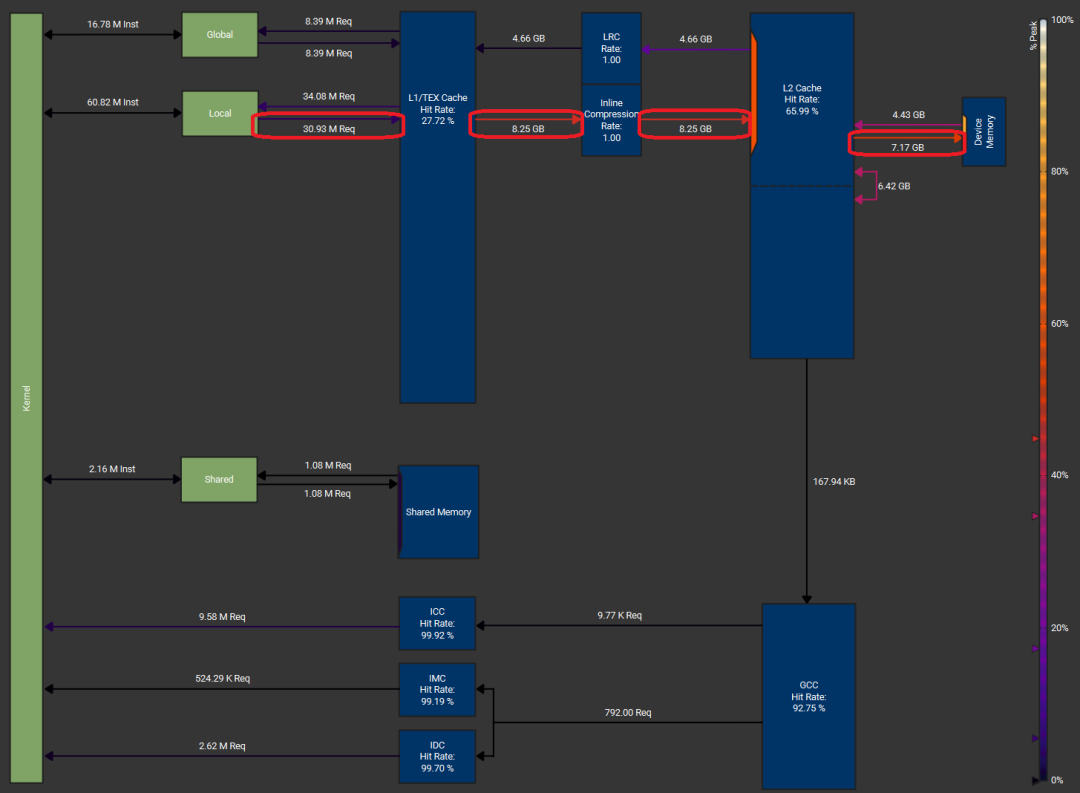
Liger softmax内核汇编代码中的寄存器溢出(LDL指令):

但集群归约能让多个SM协同工作,共享各自的资源,相当于组成一个“超级”SM(靠DSMEM实现)。
假设单个SM仅能处理32k输入,那么一个大小为16的集群将允许处理50万(0.5M)输入,而无需从全局内存(GMEM)重新加载数据。
由于作者对硬件知识有清晰的理解,即使使用常规的3遍扫描softmax算法,也能轻松充分利用所有内存层级的每一个字节,实现“光速”级别的吞吐量。
总结
作者通过实践证明,只要精心手工编写CuTe内核,就能把硬件里所有内存层级的潜力都榨干,实现“光速”级别的内存吞吐量。
但这种效率是以针对每个算子甚至每个输入形状进行调优为代价的,这自然在效率与开发成本之间形成了一种权衡。
Phil Tillet(Triton的作者)在他的演讲中用这张图很好地阐述了这一点。
根据作者使用CuTe-DSL的经验,它既具备Python的开发效率,又拥有CUDA C++的控制能力和性能。
作者认为,高效的GPU内核开发流程是可以自动化的。
例如,RMSNorm中的输入张量TV布局、加载/存储策略以及归约辅助函数,可直接应用于softmax内核并仍能达到相近的吞吐量。
此外,CuTe DSL将为开发者或基于CuTe DSL运行的其他代码生成应用提供灵活的GPU内核开发能力。
目前,将大语言模型应用于自动生成GPU内核是一个活跃的研究方向,未来,或许只需调用“LLM.compile” 就能生成高度优化的GPU内核。
作者简介
这项工作作者有三位。
Wentao Guo
Wentao Guo目前是普林斯顿大学计算机科学专业的博士生,师从Tri Dao。
在这之前,他在康奈尔大学获得了计算机科学的本科和硕士学位。
Ted Zadouri
Ted Zadouri同样是普林斯顿大学计算机科学专业的博士生,本硕分别读自加州大学欧文分校、加州大学洛杉矶分校
此前Ted Zadouri曾在英特尔实习,也曾在Cohere研究大语言模型的参数高效微调。

Tri Dao
Tri Dao目前是普林斯顿大学计算机科学助理教授,还是生成式AI初创公司Together AI的首席科学家。
他因提出一系列优化Transformer模型注意力机制的工作而闻名学界。
其中最有影响力的,是其作为作者之一提出了Mamba架构,这一架构在语言、音频和基因组学等多种模态中都达到了SOTA性能。
尤其在语言建模方面,无论是预训练还是下游评估,Mamba-3B模型都优于同等规模的Transformer模型,并能与两倍于其规模的Transformer模型相媲美。
另外他还参与发表了FlashAttention1-3版本,FlashAttention被广泛用于加速Transformers,已经使注意力速度提高了4-8倍。
GitHub链接:https://github.com/Dao-AILab/quack/blob/main/media/2025-07-10-membound-sol.md
(文:量子位)