跳至内容
作者|沐风
来源|AI先锋官
近日,华为宣布开源其盘古大模型核心组件(PanguProMoE),包括70亿参数稠密模型和720亿参数的混合专家模型,并高调宣称“昇腾生态迈出关键一步”。
但谁也没料到,就在4天后,来自GitHub用户@HonestAGI发布的一份技术报告,将华为盘古大模型推入了巨大的争议漩涡。
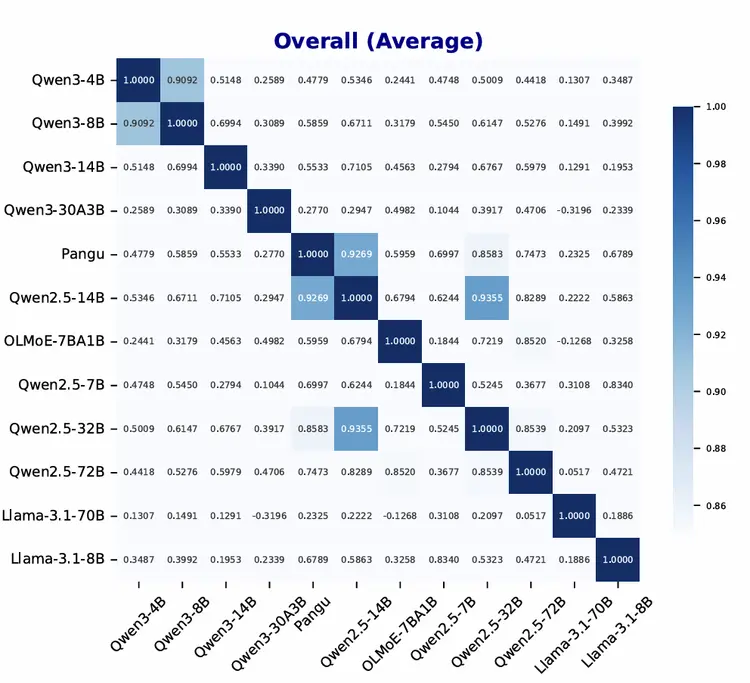
该研究团队通过“LLM指纹技术”分析发现,华为盘古Pro MoE模型与阿里通义千问Qwen-2.5的注意力机制(QKV投影层)参数,相似度高达0.927。
要知道,这个参数如果达到1.0。就是完全一致,正常模型差异范围通常≤0.7。
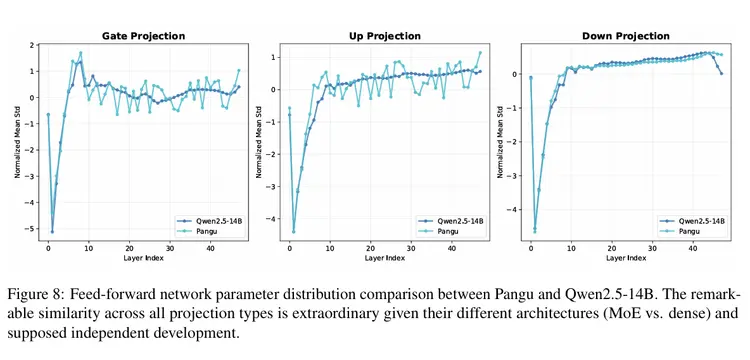
另外,QKV偏差分析显示,pangu和Qwen2.5-14B在三种投影类型(Q、K、V)上,均表现出惊人的相似性,尤其是在早期层的特征峰值,以及随后的收敛行为方面。
值得注意的是,QKV偏差是Qwen 1代至2.5代的一个显著设计特征,而大多数开源模型(包括 Qwen3),都放弃了这种方法。
随后,有自称是盘古大模型团队的人在GitHub上进行了回应,否认抄袭指控,并且认为该作者的评估方法不科学。
-
pangu-72b-a16b .vs. Qwen2.5-14b = 0.92
-
baichuan2-13b .vs. Qwen1.5-14b = 0.87
-
baichuan2-13b .vs. pangu-72b-a16b = 0.84
-
baichuan2-13b .vs. Qwen2.5-14b = 0.86
不同其他相近参数规模的模型,在该评估方法下,也得到了与Qwen-2.5 14B模型高度相似的结果。
对于该回应,@HonestAGI表示,其无法信服盘古大模型团队的说法。
随后,@HonestAGI提供了Qwen和Hunyuan A13B之间的对比,结果显示,二者在不同层级上展现出截然不同的内部模式,这表明它们拥有截然不同的架构和学习到的表征。
不过,目前@HonestAGI似乎已经下线了之前关于盘古大模型的研究报告。
但是,其在最新的回应中表示,“我们计划在论文最终定稿并提交所有代码后,将其提交给同行评审会议。”
还值得注意的是,通过查询盘古官方发布的“盘古Pro”大模型开源代码,可以发现未删除的阿里版权声明——“Copyright 2024 The Qwen team, Alibaba Group”。
随后,华为诺亚方舟实验室7月5日发布最新声明,表示盘古Pro MoE开源模型是基于昇腾硬件平台开发、训练的基础大模型,并非基于其他厂商模型增量训练而来。
盘古团队表示,“盘古 Pro MoE 开源模型部分基础组件的代码,实现参考了业界开源实践,涉及其他开源大模型的部分开源代码。我们严格遵循开源许可证的要求,在开源代码文件中清晰标注开源代码的版权声明。这不仅是开源社区的通行做法,也符合业界倡导的开源协作精神。”
尽管华为解释此为合规引用开源组件(遵循Apache 2.0协议),但结合参数异常,舆论迅速将其解读为“抄袭实锤”。
一位自称盘古团队前成员的知乎用户发布的自曝长文,开始在各个技术社区疯传。
他称,由于团队初期算力非常有限,虽做出了很多努力和挣扎,但没有预期效果,内部的质疑声和领导的压力也越来越大。
后来,小模型实验室多次套壳竞品,领导层被指默许造假行为换取短期成果。
自曝文中称:“经过内部的分析,他们实际上是使用Qwen 1.5 110B续训而来,通过加层,扩增ffn维度,添加盘古pi论文的一些机制得来,凑够了大概135B的参数。”
并表示,“听同事说他们为了洗掉千问的水印,采取了不少办法,甚至包括故意训了脏数据。”
“他们选择了套壳DeepSeek v3续训。他们通过冻住DeepSeek加载的参数,进行训练。”他说。
举报信的作者还表示,自己已经申请从盘古部分技术报告的作者名单中移除,并希望以此为行业正名。
他坦言:“我以生命、人格和荣誉发誓,我写的以上所有内容均为真实(至少在我有限的认知范围内)。”
(文:AI先锋官)