

不圆 发自 凹非寺
量子位 | 公众号 QbitAI
DeepSeek推理要详细还是要迅速,现在可以自己选了?
来自特拉维夫大学的研究团队开发出了一种新方法,可以监控和控制LLM中的思考路径长度。
给LLM的推理任务装上进度条,还能控制推理的深度、调整推理速度。
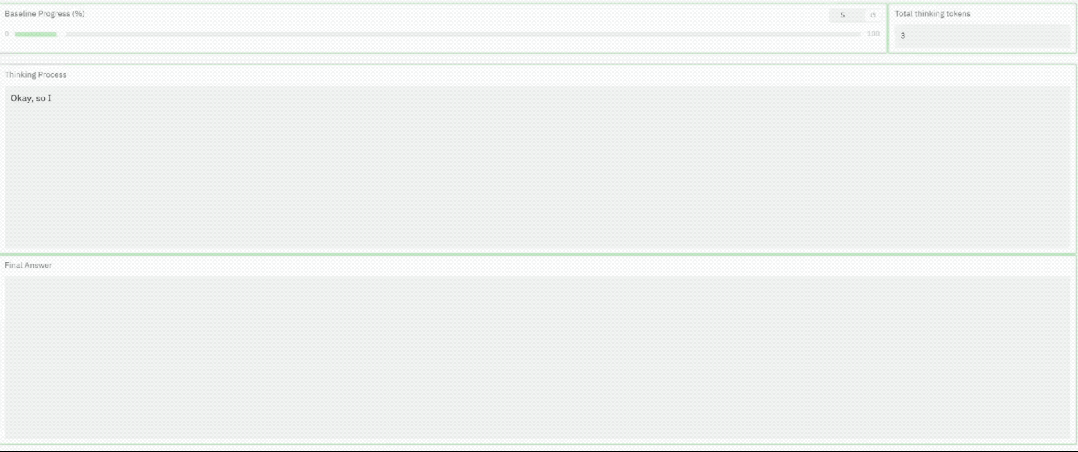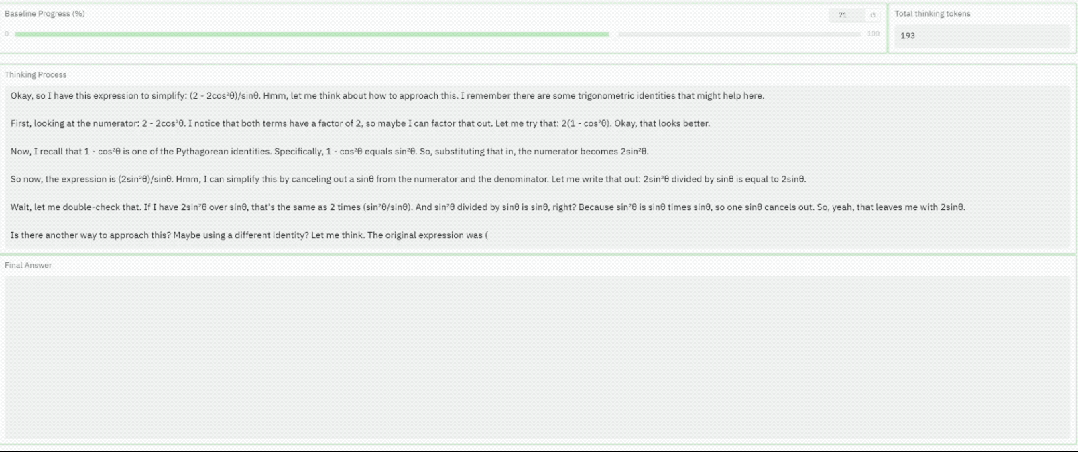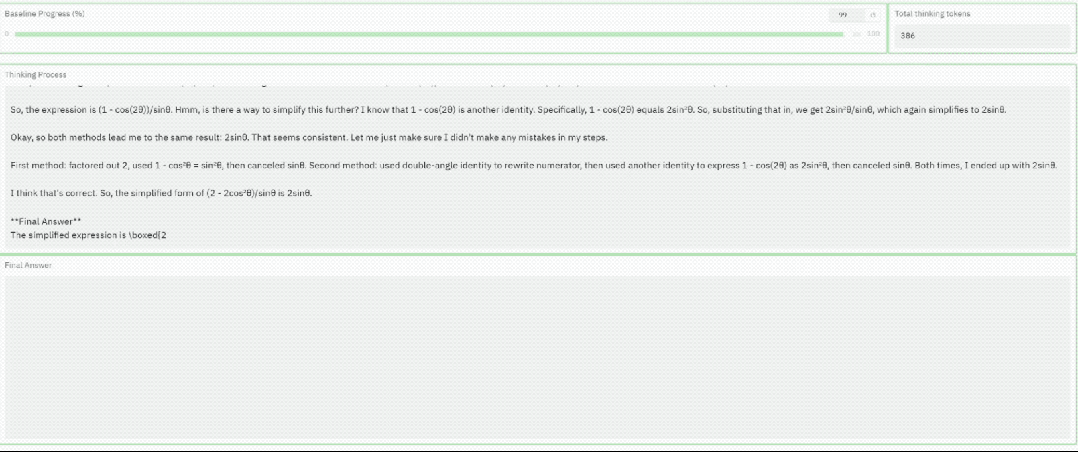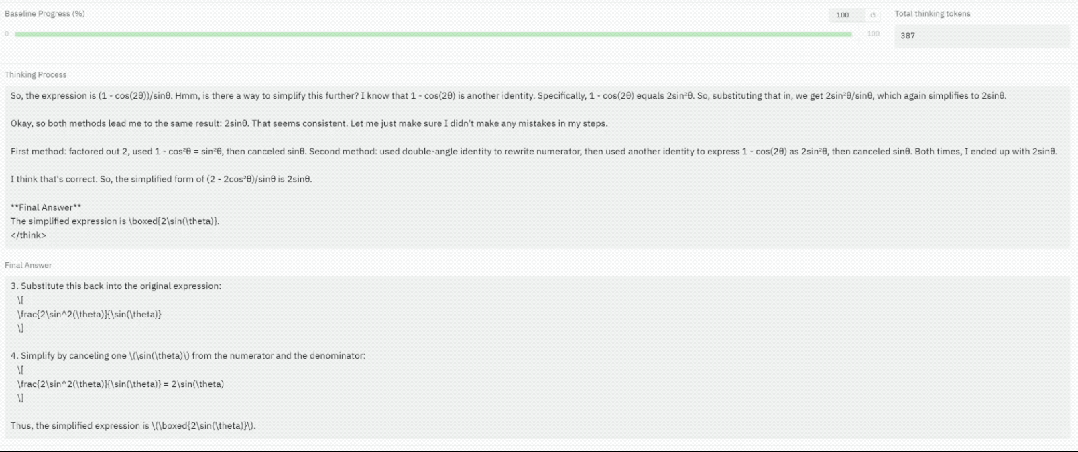
加速后的模型和原模型相比,使用的token数减少了近6倍,且都得出了正确答案。

LLMs在显示结构化推理时,会隐式跟踪其在思考阶段的相对位置,并通过隐藏状态编码这一信息。
而论文提出了一种“思维进度向量”(Thinking Progress Vector, TPV),可用于实时预测模型在推理阶段的相对位置,并通过可视化进度条展示模型的推理动态。
通过干预TPV,可以加速或减速模型的推理过程,实现“超频”(overclocking)和“降频”(downclocking)。
超频能够减少不必要的推理步骤,使模型更快地得出结论,同时避免因过度推理导致的性能下降。

该模型已在gitHub上开源。
方法:实时监控并控制推理深度
在有效推理学习过程中,模型必须隐式地学习跟踪其思考阶段进度,并保持对例如距离最终答案有多近的估计。
由于进度跟踪依赖于输入,这类信息不能存储在模型的静态权重中,而必须动态编码在层间传递的隐藏表示中。
为此,论文的研究团队选择从最终隐藏层提取信息。
研究团队专注于执行显式结构化推理的模型,这种模型的特点是具有一个由<think>和</think>标记明确界定且连续的推理阶段,如DeepSeek-R1。
由此可以通过根据每个标记的相对位置精确地用介于零和一之间的插值值进行标记,来量化模型在推理阶段的进展。
形式上,通过以下方式构建数据集𝒟:
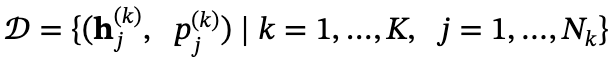
其中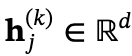 是第k个思考轨迹中第j个词的隐藏表示,
是第k个思考轨迹中第j个词的隐藏表示,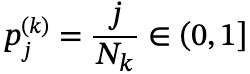 是该词在其思考序列中的相对位置 。K表示采样轨迹的数量,𝒟中的总样本数为
是该词在其思考序列中的相对位置 。K表示采样轨迹的数量,𝒟中的总样本数为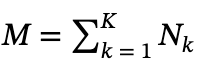 。
。
在此基础上优化一个进度提取函数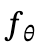 ,将隐藏表示映射为其相对位置,形式为一个回归任务
,将隐藏表示映射为其相对位置,形式为一个回归任务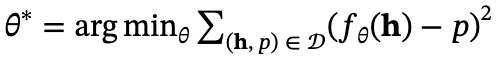 。
。
使用参数为 的线性回归器作为函数来进行拟合进度属性
的线性回归器作为函数来进行拟合进度属性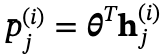 ,将参数向量𝜽称为称为“思考进度向量”(TPV)。
,将参数向量𝜽称为称为“思考进度向量”(TPV)。
为了提高预测效果,利用模型的自回归特性,并对预测历史应用指数平滑以减少噪声。在Math-500测试集中进行TPV预测,结果如下图所示:
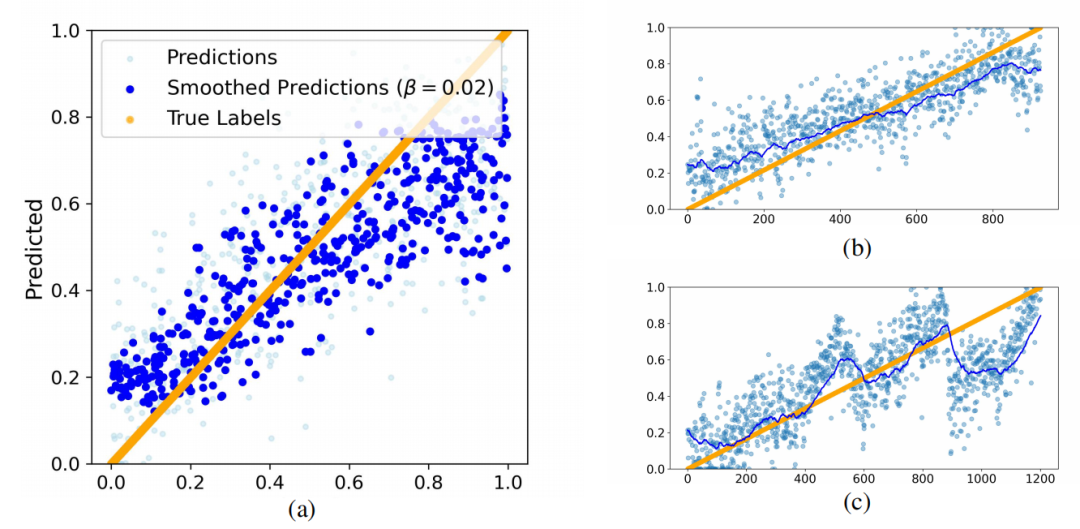
其中图(a)展示了多个思考轨迹的数据点的汇总视图,图 (b, c)则展示了Math-500测试集中单个问题的思考轨迹上的TPV预测和平滑预测。
可以看到,两种方法都成功预测了相对位置,而后者产生了更精确的结果,可用于创建更清晰、更易于解释的进度条。
受此启发,为了更好地利用进度条预测任务的时序结构,使用可训练的序列模型替换指数平滑,即使用与𝒟相同的训练样本,只是将相对位置序列作为输入,而不是进行单步预测:
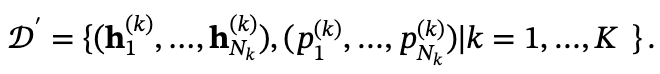
通过这种方法,就可以实现推理进度的可视化。
一个关键问题是,TPVs是否反映了模型用来跟踪其推理进度的基本机制,或者它们是否仅仅是与进度相关但不起因果作用计算的残余物?
为解决这一疑惑,对TPY进行干预:通过投影向量𝜽的方向将隐藏表示𝐡移动量α,即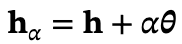 ,修改后的表示具有新的预测值
,修改后的表示具有新的预测值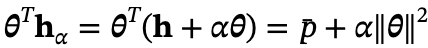 。
。
通过在所有注意力层执行此干预,就可以干预下一个词的预测,并避免编辑在连续解码步骤中缓存和使用的表示值。
在实验中,将α视为决定干预强度的超参数。设置α=0会导致没有干预,保留原始计算。 α的正值会导致超频。
实验证明,超频将加速模型的推理阶段,使其更短、更果断:

上图比较了DeepSeek-R1-Distill-Qwen-32B模型生成的两种思考序列——干预前和干预后。
原始序列表现出犹豫和冗长,而TPV加速版本则显著更简洁,使用的token数量减少了近6倍。
并且,两条轨迹最终都得到了正确的答案。
效果:最高提速近6倍,准确率不降反升
在DeepSeek-R1-Qwen-32B和DeepSeek-R1-LLaMA-8B上测量TPV的有效性,结果如下所示:
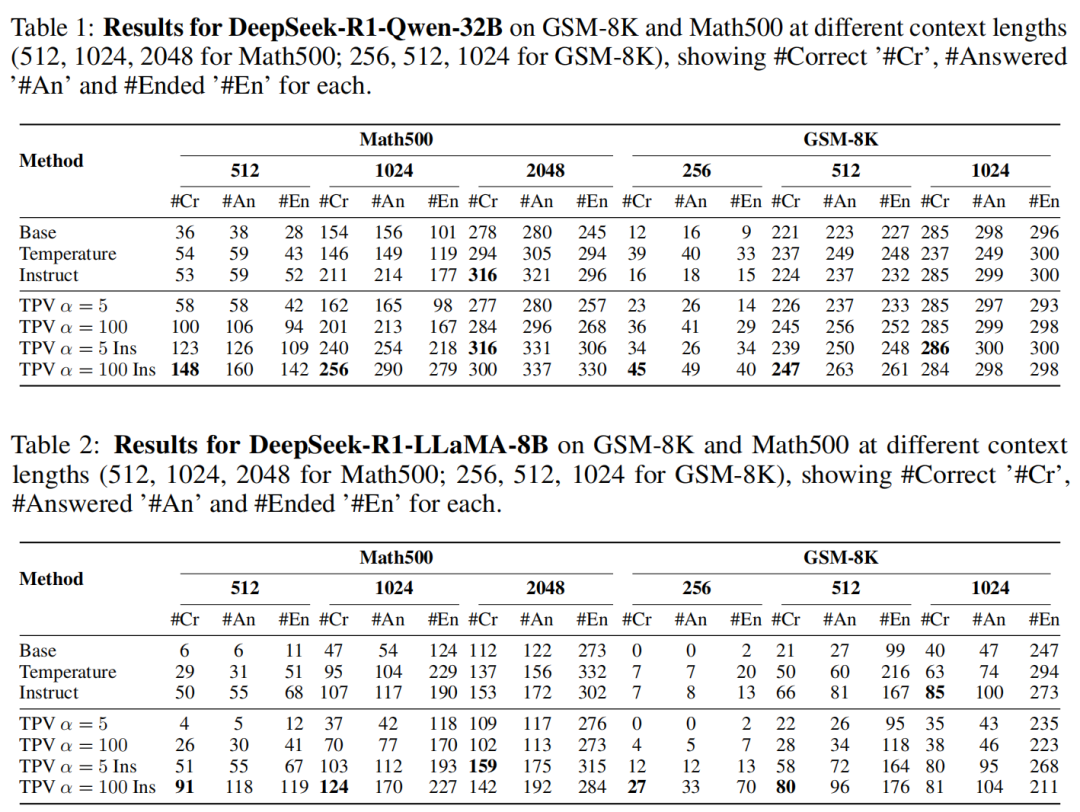
实验结果揭示了四个显著趋势:
1、α 的影响:增加α从5到100,无论是否使用基于指令的加速,都会增加模型生成的完成、结束和正确答案的数量,证明TPV的干预方法影响了思考长度。
2、将加速基线与基础模型进行比较:基线(ii)和(iii)通过提示响应和基于温度的集成来加速基础模型。在大多数情况下,这两种方法都提高了所有三个指标,证明它们是评估TPV超频方法的强基线。
3、与基线方法的比较:尽管基线方法表现优异,且基于温度的基线方法需要大约五倍的计算资源,但TPV的方法通过产生更多正确答案和更明确的响应,在性能上超越了它们。
在计算预算较低(如256或512个token)的情况下,TPV的方法增加了80%的正确答案,并且这些正确答案的增加并未以增加错误率为代价,错误率保持不变。这表明,TPV方法缩短了推理过程而不增加错误,促进了更明确的思考。
对于大于512的计算预算,通常遵循相同趋势,在大多数情况下正确答案数量有所提升,而错误率并未增加。
4、互补性贡献:尽管实证研究结果证实TPV方法比基线方法更有效,但仍有该方法落后于基于提示的方法(记为“指令”)的情况。一个突出的例子是在 Math 500 上使用 2048个token 预算的机制,其中指令基线正确回答的比例比TPV方法高出10%。
这一观察引发了这样的问题:这些改进是正交的还是相互竞争的?
将基于指令的提示技术与TPV的干预方法相结合,并与每种方法单独进行比较。结果如表中最后两行所示:这种混合方法在大多数情况下始终表现出最佳性能,平均提高了66% ,最高提高了285% ;相对于基础模型平均提高了223% ,最高提高了1416% 。
这些发现表明TPV方法与提示策略相辅相成,可以有效地与其他加速技术相结合。
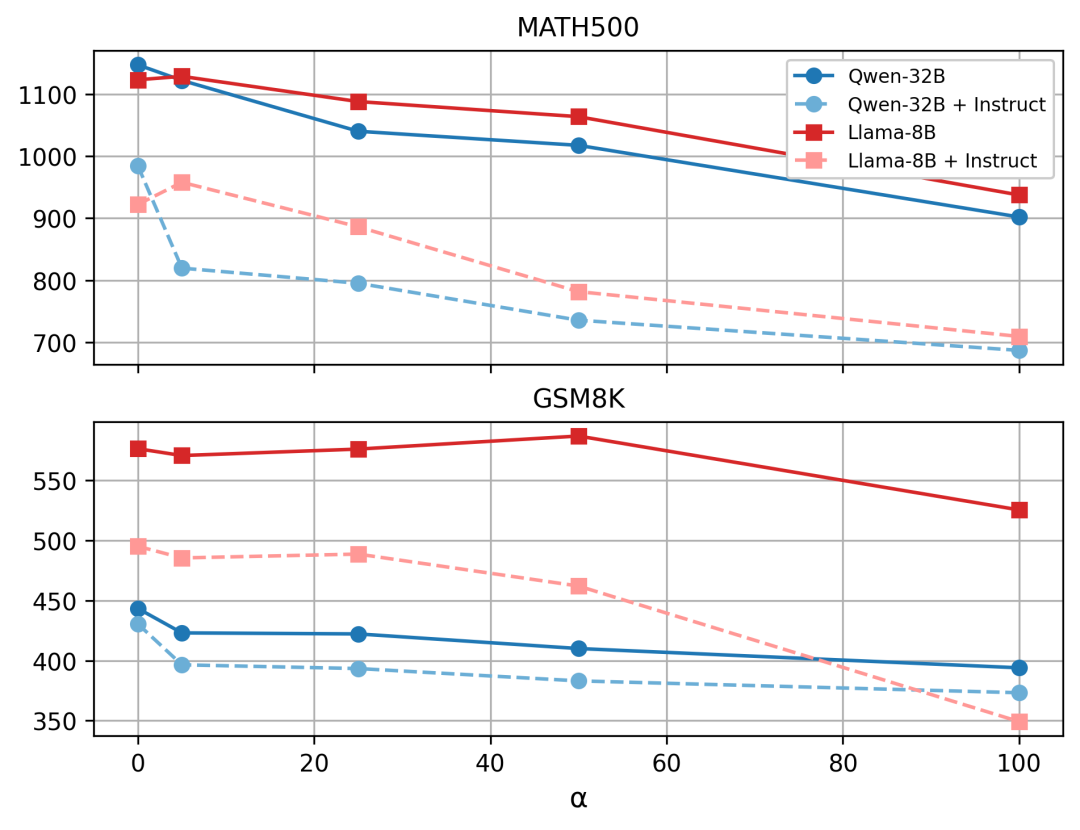
对Math-500和GSM8K数据集进行一系列干预实验,通过改变干预参数α来超频模型的思考阶段。
结果显示,增加α可以持续缩短思考阶段的长度,使推理过程更加高效。
这些发现支持TPV在模型内部计算中充当一种主动控制的信号,而不是被动相关。
当使用提示策略(基线 iii)在GSM8K数据集上对 DeepSeek-R1 LLaMA模型应用TPV方法时,平均 token 数量从大约500减少到不到350,计算量减少了30%。
此外,所有α的正值都相对于基线( α=0 )持续加速思考阶段,并提高了其有效性。
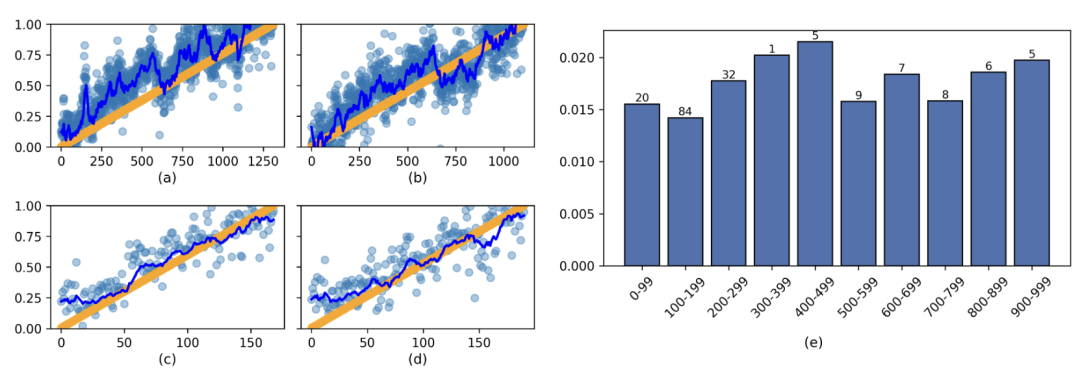
为进一步评估TPVs在估计模型在其推理过程中位置时的可靠性,研究团队还在两种附加条件下测试了它们的性能:
-
(i) 不同的提示策略 -
(ii) 不同的推理序列长度
图(a-d) 显示TPVs在各种指令中仍然有效,这与训练期间使用的原始提示不同。
图(e) 显示在不同思考序列长度分箱中测试损失始终较低,表明对推理深度的变化具有鲁棒性。
更多内容可见论文详细。
(文:量子位)