
随着多模态大语言模型(MLLMs)的快速发展,其在视频推理等前沿任务中快速进化,不断突破性能天花板。而强化学习(RL)作为推动这场技术革命的关键引擎,为大语言模型注入了强大的推理能力。
DeepSeek-R1凭借纯RL优化,让模型推理能力实现质的飞跃;VideoR1引入T-GRPO,赋予模型拆解视频时空逻辑的 “透视眼”;VideoChat-R1借助基于 GRPO 的多任务联合微调,让模型在视频理解与多步推理上表现得更加 “聪明伶俐”,相关成果不断涌现……
尽管基RL驱动的优化在指标提升上成绩亮眼,但在面对复杂多模态任务时,依然存在两大拦路虎:一方面,思维链推理应用到多模态时“水土不服”,不仅产出的推理过程冗长没重点,训练目标还常忽略关键时空线索,拖慢学习效率;另一方面,现有依赖单选题问答的稀疏二元奖励信号太“简单粗暴”,只认可全对答案,埋没部分正确内容。不过幸运的是,视频定位研究已证实,软奖励信号能稳定学习过程、提升精度。
▍提出TW-GRPO框架:革新加权机制与奖励设计
面对多模态大语言模型在视频推理任务中存在的推理质量和奖励粒度等挑战,来自中山大学、兰州大学、合肥工业大学、香港大学和新加坡国立大学研究团队的研究人员受传统GRPO框架启发提出了通过聚焦思维和密集奖励粒度增强视觉推理的全新框架TW-GRPO。
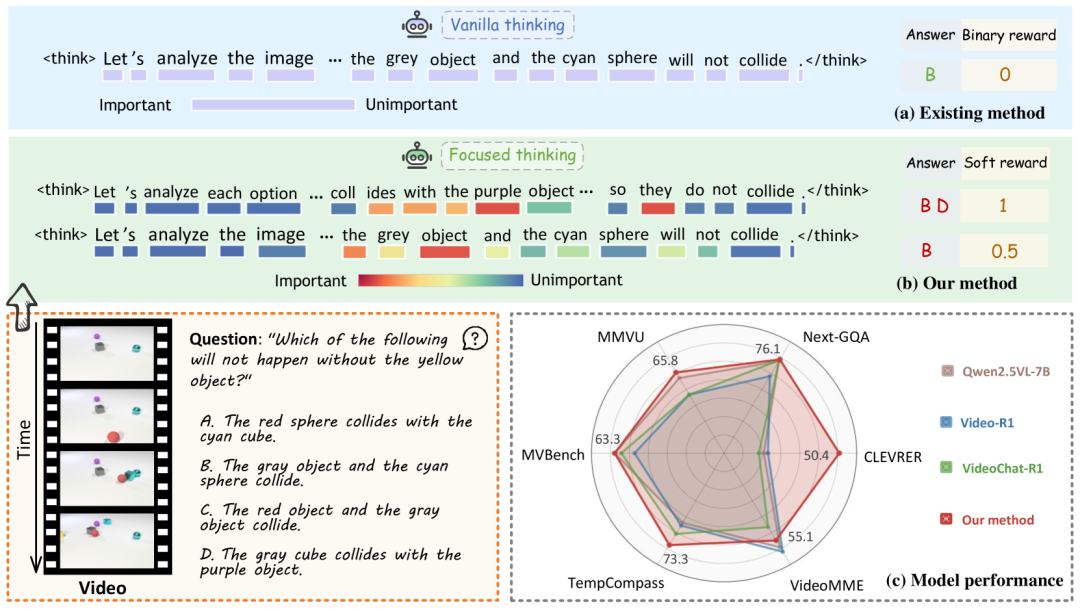
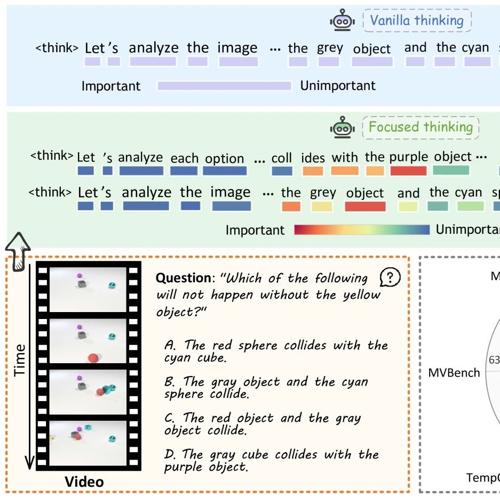
图1:TW-GRPO 集成了聚焦思维和多层次软奖励机制用于多选QA任务。
TW-GRPO框架在传统GRPO基础上进行了关键改进,着重优化了信息量加权和奖励机制设计,并借鉴了视频定位中的交并比(IoU)软奖励机制,将其应用于视频推理任务。具体而言:
-
动态加权机制
TW-GRPO通过动态加权机制,分析token位置的组内信息熵评估重要性,优先处理高信息密度的token,使模型精准锚定推理关键内容,规避前置声明、重复验证等通用短语的干扰,更加专注于有信息量的部分,从而提高了推理的精度和效率。
-
多层次奖励机制
TW-GRPO重新定义了奖励机制,将RL训练从传统单选题QA任务拓展为多选QA任务,借由源自视频定位 IoU 的软奖励机制,以多层次奖励区分答案部分正确性,实现更精细的梯度估计与稳定的策略更新。新的软奖励设计,使得模型不仅能够识别完全正确的答案,还能够对部分正确的答案提供奖励,大大改善了训练的稳定性和效率。
-
问答反转策略
针对多选数据稀缺问题,TW-GRPO引入了问答反转(QAI)数据增强技术,通过否定问题、反转答案的方式,将单选题任务转换为多选格式,有效扩充训练数据池。这种设计彻底颠覆传统模型对token的等权重处理模式,以差异化信息处理与精细化奖励反馈驱动模型训练效率与推理性能的双重提升。
在六个基准测试中开展大量实验与消融研究,研究团队验证TW-GRPO在视频推理和通用理解任务中的有效性。实验结果显示,应用该框架的模型在CLEVRER、NExT-GQA和MMVU等基准测试中,性能分别比Video-R1高出18.8%、1.8%和1.6%。定性分析则表明,TW-GRPO能精简推理链,聚焦关键视觉和逻辑线索,多级奖励机制降低了训练过程中的奖励差异。
目前,该研究成果的相关论文预印本版本已以“Reinforcing Video Reasoning with Focused Thinking”为题发表在arXiv上(2505.24718)。论文第一作者为党吉圣,共同作者还包括吴竞择、王腾、林轩辉、朱楠楠、陈洪波、郑伟诗、汪萌、蔡达成。
▍方法具体解析:TW-GRPO框架的设计与实现
研究团队提出TW-GRPO框架,主要针对现有GRPO算法存在的两大问题,从两个维度进行改进:一方面,引入token层次的重要性加权机制,解决token重要性被忽视的问题;另一方面,将单选QA任务重新表述为多选设置,并设计多层次软奖励,克服二元奖励的局限性,实现更精细的策略学习。
-
Token 层次的重要性加权
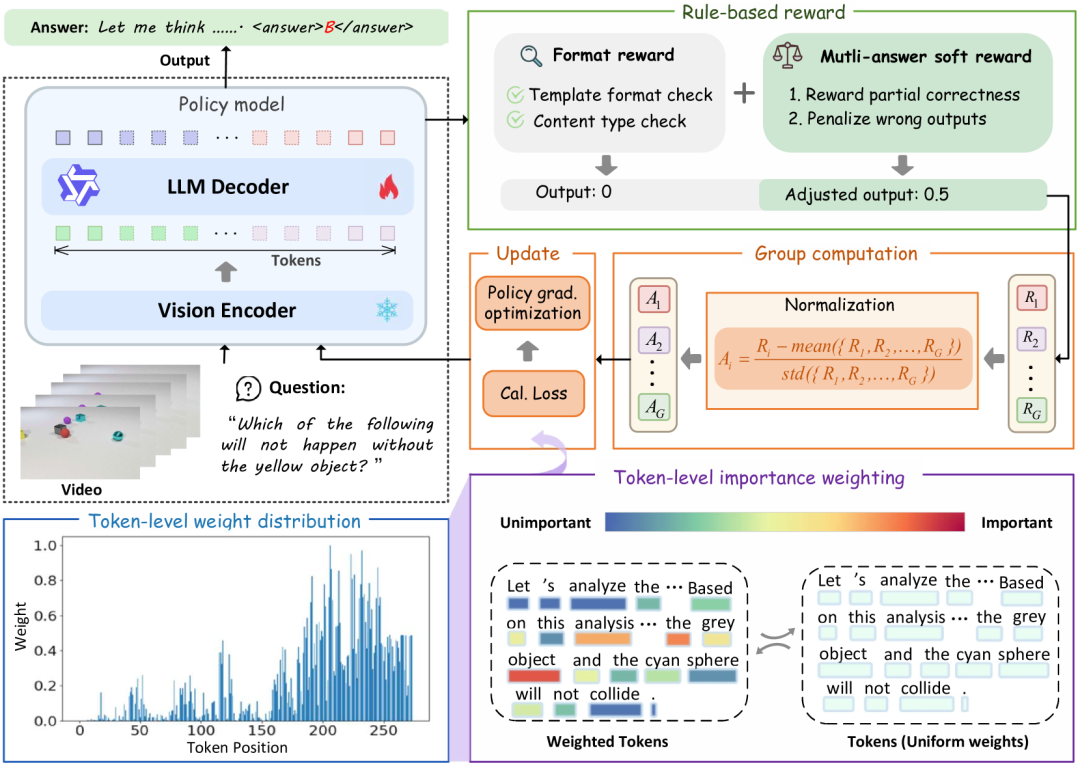
在策略优化过程中,有效区分token的信息性至关重要。常规的细粒度推理质量评估依赖辅助评论模型,会增加参数,削弱GRPO的优势。受相关研究启发,研究团队提出基于信息熵的轻量级方法,通过token层次的分布差异识别关键推理 token。其核心在于,候选输出中某些token位置的分布与预期分布差异越大,携带的信息可能越丰富,借此可估算token重要性,且无需引入额外模型组件。
研究团队提出token重要性加权$w_t$来量化各token位置的信息内容。使用Kullback-Leibler(KL)散度$D_{\text{KL}}$测量了token在位置$t$的概率分布与该位置预期分布之间的差异,并针对变长序列进行处理,用均匀分布填充缺失token。为保证数值稳定与权重可比性,团队还采用最小-最大归一化,引入超参数$\alpha$控制重要性缩放。最终,将$w_t$融入目标函数,实现位置敏感的优化,使模型能根据token信息量调整学习信号,且无需额外评估模型。
图
-
多选软奖励
单选问题中,二元奖励信号效率较低。为解决这一问题,研究团队采取两步策略。首先,受标准化测试多选题格式启发,将单选QA任务重新表述为多选设置,使每个问题可能存在一个或多个正确答案。但此转变面临数据稀缺问题,团队引入问答反转(Question-Answer Inversion,QAI)数据增强技术,通过否定问题和反转答案将单选题转化为多选题,并随机去除正确选项,构建了包含多个正确答案的多选NExT-GQA数据集,增加任务复杂性。
然而,多选设置带来新挑战,传统基于二元准确度的奖励机制在单选与多选问题间产生显著奖励波动,影响模型收敛。为此,研究团队借鉴视频定位任务中的交并比(IoU)奖励,提出多层次软奖励。该奖励依据预测答案与真实答案的重叠程度,为部分正确的预测赋予相应分数,惩罚完全错误的预测,改善了细粒度的梯度估计和策略稳定性,使模型在多选QA任务中获得更有效的反馈。
通过在视频推理任务和通用视频基准上的实验,TW-GRPO框架展现出良好性能。与其他方法相比,TW-GRPO在奖励标准差上收敛更快,学习过程更稳定高效;同时,生成的输出长度更短,推理更简洁有效,验证了框架改进的有效性。
▍大量实验研究:验证TW-GRPO框架有效性
研究团队以Qwen2.5-VL-7B为基础模型,配备两块NVIDIA H800 GPU,在1000个CLEVRER反事实训练数据集上执行500步强化学习训练。训练阶段,视频帧以128×28×28的分辨率进行处理;进入推理阶段后,将帧分辨率提升至 256×28×28,并将单段视频的最大帧数限制为16帧,以此优化模型性能表现。为系统性评估TW-GRPO框架的有效性,研究团队选取MVBench、TempCompass、VideoMME、MMVU、NExT-GQA和CLEVRE六大视频基准数据集开展测试,这些基准涵盖视频语义理解、时序推理等多维度复杂任务。
-
TW-GRPO性能优越性
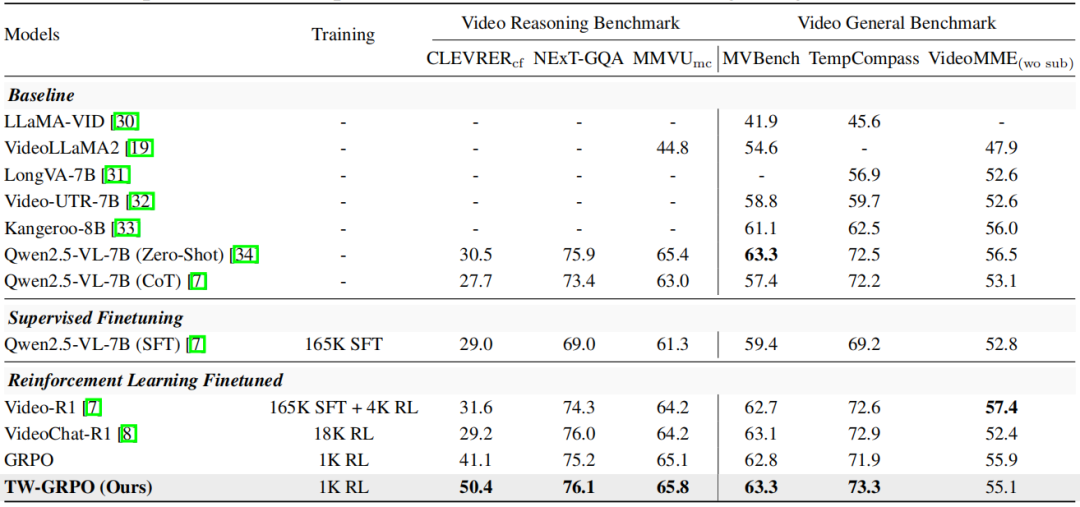
实验数据如表1所示,在视频推理与整体理解任务中,TW-GRPO持续优于现有模型,尤其在训练样本有限的场景下依然表现出色。在CLEVRER、NExT-GQA和MMVU等推理任务基准测试中,相较于未融入软奖励和token层次加权的原始GRPO模型,TW-GRPO展现出显著优势。
表
推理任务表现:在CLEVRER基准上,TW-GRPO准确率达到50.4%,较Video-R1提升超18%;在NExT-GQA和MMVU基准上,分别超越Video-R1和VideoChat-R1,提升幅度为1.8% 和1.6%。
通用视频理解任务:在MVBench基准上,TW-GRPO与Qwen2.5-VL-7B的零样本性能(63.3%)相当,且优于Video-R1和VideoChat-R1;在TempCompass基准上,以73.3%的准确率领先,超出表现最佳的基线模型0.4%;即使在VideoMME基准上,TW-GRPO仍比VideoChat-R1高出 2.7%。
在相同训练条件下,TW-GRPO在五个基准上均显著优于GRPO,充分体现了token 层次的重要性加权和多层次奖励策略的有效性,使模型实现更高效稳定的策略学习,提升了在各类任务中的表现。
-
训练动态与收敛行为
图3展示了不同GRPO变体的训练动态。图3(a)显示,TW-GRPO在奖励标准差上实现更快收敛,学习过程更为稳定。这得益于多层次软奖励和token加权策略的引入,使模型能够更好地处理模糊问题。传统GRPO在多选任务中,因固定准确度奖励导致收敛缓慢;而TW-GRPO的软奖励策略有效降低奖励标准差,实现更稳定的优化。同时,token层次的重要性加权机制促使模型聚焦关键信息token,提升优化效率,加速收敛进程。
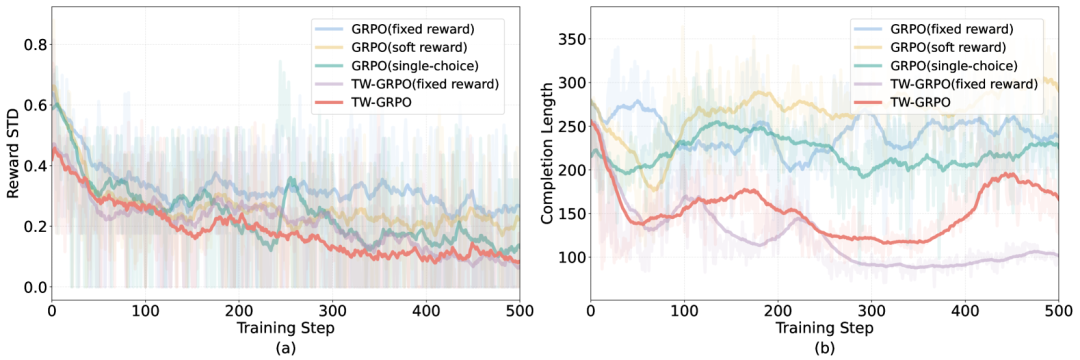
图
从图3 (b)可见,TW-GRPO生成的输出序列更短,表明其学会了更简洁的推理方式,进一步证明奖励目标与模型最终行为的高度契合,彰显了训练设计的有效性。TW-GRPO通过精心设计的策略,实现了更平滑的收敛过程、更少的输出token以及更高效的推理。
-
推理路径的定性分析
研究团队选取MMVU数据集中基于物理的密度估计任务,对T-GRPO和TW-GRPO的推理路径进行定性对比。该任务需先获取石头在空气中(230克)和浸入水中(表观重量138克)的重量,再运用阿基米德原理,根据92克的浮力推导排开体积,进而计算密度。
T-GRPO模型在计算时错误假设体积为100 cm³,得出2.3 g/cm³ 的错误密度;随后又误将2.5 g/cm³ 认定为最接近答案,即便尝试反思也未能纠正错误,导致 token使用低效,甚至最终选择2.7 g/cm³,与先前估计矛盾。

图
而经TW-GRPO训练的模型,能够精准提取视频关键数值,正确运用物理原理推断体积,并准确匹配答案选项。这一实例直观展现了TW-GRPO在基于动态视觉线索推理时,在推理准确性、因果推理和定量推理方面的显著提升。
参考文章:
https://arxiv.org/html/2505.24718v3#S3
(文:机器人大讲堂)