

随着人工智能技术的飞速发展,尤其是大型语言模型(LLM)的广泛应用,对于高质量数据的需求更是与日俱增。然而,获取这些数据并非易事,尤其是在网络环境中,数据往往分散在各个网站中,难以直接获取。
为了解决这一问题,开源项目 Firecrawl MCP Server 应运而生。它通过强大的 Web 爬虫功能,为 LLM 客户端提供了高效的数据采集和处理能力,极大地拓展了 LLM 的应用场景和价值。
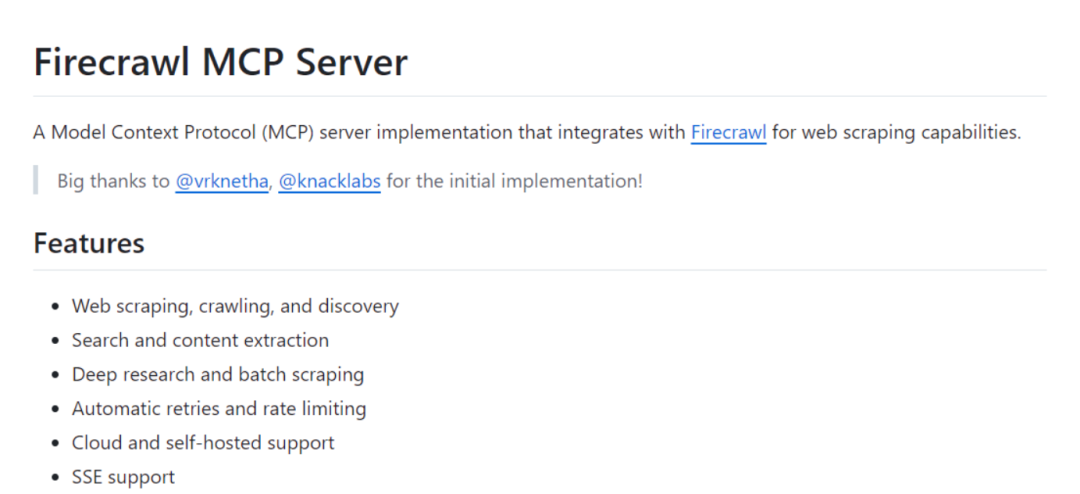
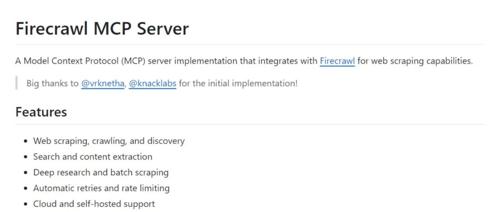
一、Firecrawl MCP Server 是什么?
Firecrawl MCP Server 是一个基于模型上下文协议(Model Context Protocol,简称 MCP)的服务器实现,它通过与 Firecrawl 的集成,为各种 LLM 客户端(如 Cursor、Claude 等)提供了强大的 Web 爬虫能力。该项目由 mendableai 团队开发并开源,旨在帮助用户更高效地从网络中获取数据,以支持 LLM 的训练、研究和应用开发。
二、Firecrawl MCP Server 的技术原理
(一)模型上下文协议(MCP)
MCP 是一种用于在 LLM 客户端和数据源之间建立高效通信的协议。它允许 LLM 客户端通过标准化的接口请求数据,并从数据源获取所需的信息。Firecrawl MCP Server 作为 MCP 的一个实现,遵循该协议,为 LLM 客户端提供了与 Web 数据交互的桥梁。
(二)Web 爬虫技术
Firecrawl MCP Server 利用了先进的 Web 爬虫技术,能够自动发现、抓取和解析网页内容。它支持 JavaScript 渲染,可以处理动态生成的内容,确保获取的数据是最新的。此外,它还具备智能的 URL 映射和内容提取功能,能够根据用户的请求自动选择最佳的爬虫策略。
(三)自动重试与指数退避
为了应对网络请求中的各种问题,如服务器超时、网络波动等,Firecrawl MCP Server 实现了自动重试机制。它采用指数退避算法,根据失败的次数动态调整重试的间隔时间,从而在保证请求成功率的同时,避免对服务器造成过大压力。
(四)批量处理与速率限制
在处理大量请求时,Firecrawl MCP Server 能够高效地进行批量处理。它通过内置的速率限制功能,合理控制请求的频率,确保在遵守目标网站的爬虫政策的同时,最大化数据获取的效率。这种智能的请求调度机制使得 Firecrawl MCP Server 能够在高并发环境下稳定运行。
(五)日志记录与信用使用监控
Firecrawl MCP Server 提供了全面的日志记录功能,记录操作状态、性能指标、信用使用情况等信息。这使得用户能够实时监控服务器的运行状态,及时发现并解决问题。此外,它还具备信用使用监控功能,当信用使用达到预设的阈值时,会自动发出警告,帮助用户合理规划资源使用,避免因信用耗尽而导致的服务中断。
三、Firecrawl MCP Server 的核心功能
(一)Web 爬取与内容提取
Firecrawl MCP Server 能够从单个或多个网页中提取内容,支持多种格式,如 Markdown、HTML 等。用户可以根据需要选择提取整个页面的内容,或者仅提取页面的主要部分。此外,它还提供了灵活的选项,如等待页面加载的时间、超时时间、是否使用移动设备模式等,以适应不同的爬取场景。
(二)批量爬取
对于需要从多个已知URL 中获取内容的场景,Firecrawl MCP Server 提供了高效的批量爬取功能。它能够自动处理多个请求,并通过内置的速率限制和并行处理机制,确保在遵守目标网站规则的前提下,快速完成数据采集任务。
(三)网站映射与URL 发现
在某些情况下,用户可能需要先了解一个网站的结构和可用的URL,然后再决定要爬取哪些页面。Firecrawl MCP Server 的网站映射功能可以自动发现网站上的所有索引 URL,为用户提供了一个清晰的网站结构视图。这使得用户能够更有针对性地进行数据采集,提高工作效率。
(四)搜索与内容提取
除了直接从已知URL 中获取内容外,Firecrawl MCP Server 还支持基于关键词的搜索功能。用户可以通过输入关键词,让服务器在互联网上搜索相关信息,并从搜索结果中提取内容。这一功能特别适用于那些不确定具体信息来源的场景,帮助用户快速找到所需的数据。
(五)深度研究
对于复杂的、需要多源信息综合分析的研究问题,Firecrawl MCP Server 提供了深度研究工具。它能够智能地进行网络爬取、搜索,并利用 LLM 的分析能力,生成最终的研究报告。这一功能使得用户能够轻松应对各种复杂的分析任务,提高研究效率和质量。
(六)LLMs.txt 文件生成
为了帮助用户更好地管理AI 模型与网站之间的交互,Firecrawl MCP Server 提供了 LLMs.txt 文件生成功能。该文件定义了 AI 模型如何与网站进行交互,包括允许访问的 URL、数据使用规则等。通过生成 LLMs.txt 文件,用户可以为 AI 模型提供清晰的指导,确保其在合法合规的前提下使用网站数据。
四、Firecrawl MCP Server 的应用场景
(一)数据分析与研究
在数据分析和研究领域,Firecrawl MCP Server 可以帮助研究人员快速收集大量的网络数据,为后续的数据分析和挖掘提供丰富的素材。无论是进行市场趋势分析、用户行为研究,还是学术研究,Firecrawl MCP Server 都能够高效地获取所需的数据,提高研究效率和质量。
(二)机器学习与AI 模型训练
对于机器学习和AI 模型的开发人员来说,获取高质量的训练数据至关重要。Firecrawl MCP Server 能够从网络中提取各种类型的数据,为模型训练提供丰富的数据源。通过批量爬取和内容提取功能,用户可以轻松地收集大量的标注数据或未标注数据,加速模型的训练和优化过程。
(三)内容创作与知识管理
在内容创作和知识管理方面,Firecrawl MCP Server 可以帮助用户快速获取网络上的最新信息和知识,为内容创作提供灵感和素材。例如,通过搜索和内容提取功能,用户可以找到相关的文章、新闻报道、研究报告等,然后结合自己的理解和分析,创作出高质量的内容。此外,它还可以用于知识库的构建和更新,帮助组织和管理大量的知识资源。
(四)监控与预警
Firecrawl MCP Server 还可以用于网络监控和预警系统。通过定期爬取特定网站的内容,用户可以实时了解网站的动态变化,及时发现潜在的风险和问题。例如,企业可以利用 Firecrawl MCP Server 监控竞争对手的网站,获取市场动态信息;安全机构可以监控网络上的安全威胁信息,及时发出预警。
五、Firecrawl MCP Server 的使用指南
(一)安装
1. 使用 npx 运行
env FIRECRAWL_API_KEY=fc-YOUR_API_KEY npx -y firecrawl-mcp2. 手动安装
npm install -g firecrawl-mcp(二)配置
1. 环境变量配置
`FIRECRAWL_API_KEY`:您的 Firecrawl API 密钥,使用云 API 时必须提供。
`FIRECRAWL_API_URL`(可选):自托管实例的自定义 API 端点。
2. 可选配置
重试配置:`FIRECRAWL_RETRY_MAX_ATTEMPTS`、`FIRECRAWL_RETRY_INITIAL_DELAY`、`FIRECRAWL_RETRY_MAX_DELAY`、`FIRECRAWL_RETRY_BACKOFF_FACTOR`
信用使用监控:`FIRECRAWL_CREDIT_WARNING_THRESHOLD`、`FIRECRAWL_CREDIT_CRITICAL_THRESHOLD`
(三)使用示例
1. 单页内容提取
{"name": "firecrawl_scrape","arguments": {"url": "https://example.com","formats": ["markdown"],"onlyMainContent": true,"waitFor": 1000,"timeout": 30000,"mobile": false,"includeTags": ["article", "main"],"excludeTags": ["nav", "footer"],"skipTlsVerification": false}}
2. 多页内容批量提取
{"name": "firecrawl_batch_scrape","arguments": {"urls": ["https://example1.com", "https://example2.com"],"options": {"formats": ["markdown"],"onlyMainContent": true}}}
3. 网站映射
{"name": "firecrawl_map","arguments": {"url": "https://example.com"}}
4. 搜索与内容提取
{"name": "firecrawl_search","arguments": {"query": "latest AI research papers 2023","limit": 5,"lang": "en","country": "us","scrapeOptions": {"formats": ["markdown"],"onlyMainContent": true}}}
5. 深度研究
{"name": "firecrawl_deep_research","arguments": {"query": "What are the environmental impacts of electric vehicles compared to gasoline vehicles?","maxDepth": 3,"timeLimit": 120,"maxUrls": 50}}
结语
Firecrawl MCP Server 作为一个开源的 Web 爬虫服务器,为 LLM 客户端提供了强大的数据采集和处理能力。它不仅具备先进的技术原理和丰富的核心功能,还能够满足多种应用场景下的需求。无论是数据分析师、研究人员,还是机器学习工程师和内容创作者,都可以利用 Firecrawl MCP Server 提高工作效率,获取高质量的数据。
开源仓库:https://github.com/mendableai/firecrawl-mcp-server
官网地址:https://mcp.so/server/firecrawl-mcp-server
(文:小兵的AI视界)