

向量数据库工程师分享了37条关于信息检索的硬核经验!
Leonie (@helloiamleonie) 在向量数据库公司 Weaviate 工作满两年之际,发布了一篇详细的经验总结,分享了她在信息检索领域学到的37个重要知识点。
这份总结涵盖了从BM25到RAG的方方面面,包括向量数据库、嵌入模型和向量搜索的各种细节。
37条检索经验
1. BM25是搜索的强大基线。 虽然大家可能期待先讲向量搜索,但第一课恰恰是关于关键词搜索的。在转向向量搜索等更复杂的技术之前,先从BM25这样简单的方法开始。
2. 向量数据库中的向量搜索是近似的,而非精确的。 理论上可以运行暴力搜索来计算查询向量与数据库中每个向量之间的距离,使用精确的k最近邻(KNN)。但这无法扩展。因此向量数据库使用近似最近邻(ANN)算法,如HNSW、IVF或ScaNN,在牺牲少量准确性的情况下加速搜索。向量索引使向量数据库在规模化时如此快速。
3. 向量数据库不仅仅存储嵌入。 它们还存储原始对象(例如生成向量嵌入的文本)和元数据。这使它们能够支持向量搜索之外的其他功能,如元数据过滤、关键词搜索和混合搜索。
4. 向量数据库的主要应用不是生成式AI。 而是搜索。但为LLM寻找相关上下文就是”搜索”。这就是为什么向量数据库和LLM像饼干和奶油一样搭配。
5. 你必须指定想要检索多少结果。 需要定义想要检索的最大结果数。简化来说,如果没有limit或top_k参数,向量搜索会返回数据库中存储的所有对象,按与查询向量的距离排序。
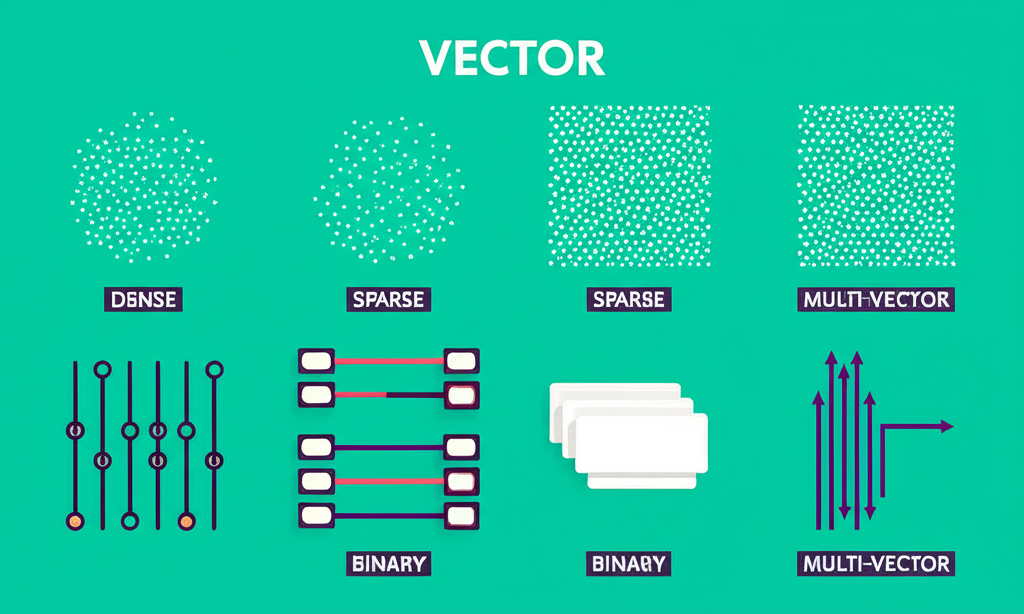
6. 有许多不同类型的嵌入。 当想到向量嵌入时,通常会想象[-0.9837, 0.1044, 0.0090, …, -0.2049]这样的东西。这叫做密集向量,是最常用的类型。但还有许多其他类型:稀疏向量([0, 2, 0, …, 1])、二进制向量([0, 1, 1, …, 0])和多向量嵌入([[-0.9837, …, -0.2049], [ 0.1044, …, 0.0090], …, [-0.0937, …, 0.5044]]),可用于不同目的。
7. 优秀的嵌入模型及其查找位置。 首选是Massive Text Embedding Benchmark (MTEB)。它涵盖了嵌入模型的各种任务,包括分类、聚类和检索。如果专注于信息检索,可以查看BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models。
8. MTEB上的大多数嵌入模型都是英文的。 如果处理多语言或非英语语言,值得查看MMTEB (Massive Multilingual Text Embedding Benchmark)。
9. 向量嵌入的一点历史: 在今天的上下文嵌入(如BERT)之前,有静态嵌入(如Word2Vec、GloVe)。它们是静态的,因为每个词都有固定的表示,而上下文嵌入根据周围的上下文为同一个词生成不同的表示。虽然今天的上下文嵌入更具表现力,但在计算受限的环境中,静态嵌入可能有用,因为它们可以从预计算的表中查找。
10. 不要混淆稀疏向量和稀疏嵌入。 稀疏向量可以通过不同方式生成:通过将TF-IDF或BM25等统计评分函数应用于词频(通常通过倒排索引检索),或使用SPLADE等神经稀疏嵌入模型。这意味着稀疏嵌入是稀疏向量,但并非所有稀疏向量都是稀疏嵌入。
11. 嵌入一切。 嵌入不仅仅用于文本。可以嵌入图像、PDF作为图像(参见ColPali)、图等。这意味着可以对多模态数据进行向量搜索。
12. 向量嵌入的经济学。 向量维度会影响所需的存储成本。因此,在选择具有1536维的嵌入模型而不是768维的模型之前,要考虑是否值得冒着存储需求翻倍的风险。是的,更多维度捕获更多语义细微差别。但”与文档聊天”可能不需要1536维。一些模型实际上使用Matryoshka Representation Learning,允许在计算资源较少的环境中缩短向量嵌入,性能损失最小。
13. “与文档聊天”教程是生成式AI的”Hello world”程序。
14. 你需要大量调用嵌入模型。 仅仅因为在摄入阶段嵌入了文档,并不意味着完成了对嵌入模型的调用。每次运行搜索查询时,查询也必须被嵌入(如果没有使用缓存)。如果稍后添加对象,这些也必须被嵌入(和索引)。如果更改嵌入模型,必须重新嵌入(和重新索引)所有内容。
15. 相似不一定意味着相关。 向量搜索通过与查询向量的相似性返回对象。相似性通过向量空间中的接近程度来衡量。仅仅因为两个句子在向量空间中相似(例如”如何修理水龙头”和”哪里可以买到厨房水龙头”)并不意味着它们彼此相关。
16. 余弦相似度和余弦距离不是同一回事。 但它们彼此相关。距离和相似度是反向的:如果两个向量完全相同,相似度是1,它们之间的距离是0。
17. 如果使用归一化向量,使用余弦相似度还是点积作为相似性度量并不重要。 因为数学上它们是相同的。对于计算,点积更高效。
18. 常见误解:RAG中的R代表”向量搜索”。 它不是。它代表”检索”。检索可以通过许多不同的方式完成(见后续要点)。
19. 向量搜索只是检索工具箱中的一个工具。 还有基于关键词的搜索、过滤和重新排序。这不是非此即彼。要构建出色的东西,需要将它与不同的工具结合起来。
20. 何时使用基于关键词的搜索vs基于向量的搜索: 用例主要需要匹配语义和同义词(例如”粉彩颜色”vs”浅粉色”)还是精确关键词(例如”A字裙”、”荷叶边连衣裙”)?如果两者都需要(例如”粉彩色A字裙”),可能会从结合两者并使用混合搜索中受益。在某些实现中(例如Weaviate),可以使用混合搜索功能,然后使用alpha参数来改变权重,从纯关键词搜索、两者的混合到纯向量搜索。
21. 混合搜索可以是不同搜索技术的混合。 最常见的是,当人们谈论混合搜索时,他们指的是关键词搜索和向量搜索的结合。但”混合”一词并未指定要结合哪些技术。所以,有时可能会听到人们谈论混合搜索,指的是向量搜索和结构化数据搜索(通常称为元数据过滤)的结合。
22. 误解:过滤使向量搜索更快。 直觉上,使用过滤器应该加速搜索延迟,因为减少了要搜索的候选数量。但在实践中,预过滤候选可能会破坏HNSW中的图连接性,而后过滤可能导致根本没有结果。向量数据库有不同的、复杂的技术来处理这一挑战。
23. 两阶段检索管道不仅用于推荐系统。 推荐系统通常有第一个检索阶段,使用更简单的检索过程(例如向量搜索)来减少潜在候选的数量,然后是第二个检索阶段,进行计算密集但更准确的重新排序。也可以将其应用于RAG管道。
24. 向量搜索与重新排序的区别。 向量搜索从整个数据库返回一小部分结果。重新排序接收一个项目列表并返回重新排序的列表。
25. 找到合适的块大小来嵌入并不简单。 太小,会失去重要的上下文。太大,会失去语义意义。许多嵌入模型使用平均池化将所有标记嵌入平均成块的单个向量表示。所以,如果有一个具有大上下文窗口的嵌入模型,技术上可以嵌入整个文档。有人用了这个类比:可以把它想象成通过叠加电影中的每一帧来创建电影海报。所有信息都在那里,但你不会理解电影是关于什么的。
26. 向量索引库与向量数据库不同。 两者对于向量搜索都非常快。两者都很适合在”与文档聊天”风格的RAG教程中展示向量搜索。但是,只有其中一个添加了数据管理功能,如内置持久性、CRUD支持、元数据过滤和混合搜索。
27. RAG自第一个长上下文LLM发布以来就一直在”死亡”。 每次发布具有更长上下文窗口的LLM时,都会有人声称RAG已死。但它从未死亡…
28. 你可以丢弃97%的信息,仍然(在某种程度上)准确检索。 这叫做向量量化。例如,通过二进制量化,可以将[-0.9837, 0.1044, 0.0090, …, -0.2049]这样的东西变成[0, 1, 1, …, 0](从32位浮点数到1位的32倍存储减少),你会惊讶地发现检索在某些用例中仍然能很好地工作。
29. 向量搜索对拼写错误不够健壮。 有一段时间认为向量搜索对拼写错误很健壮,因为这些大型文本语料库肯定包含大量拼写错误,因此帮助嵌入模型学习这些拼写错误。但仔细想想,一个词的所有可能拼写错误不可能在训练数据中有足够的反映。所以,虽然向量搜索可以处理一些拼写错误,但不能真正说它对此很健壮。
30. 知道何时使用哪种指标来评估搜索结果。 有许多不同的指标来评估搜索结果。查看学术基准测试,如BEIR,会注意到NDCG@k很突出。但像精确率和召回率这样的简单指标对许多用例来说都很合适。
31. 精确率-召回率权衡 通常用渔夫撒网的类比来描述,但这个电商类比更清晰:想象你有一个有100本书的网店,其中10本是ML相关的。如果用户搜索ML相关的书,你可以只返回一本ML书。太棒了!你有完美的精确率(在返回的k=1结果中,有多少是相关的)。但这是糟糕的召回率(在存在的相关结果中,我返回了多少?在这种情况下,10本相关书中的1本)。另一个极端是返回你的整个书籍选择。全部100本。未排序…这是完美的召回率,因为返回了所有相关结果。只是也返回了一堆不相关的结果,这可以通过糟糕的精确率来衡量。
32. 有包含顺序的指标。 当想到搜索结果时,通常会想象类似Google搜索的东西。所以,自然会认为搜索结果的排名很重要。但像精确率和召回率这样的指标不考虑搜索结果的顺序。如果搜索结果的顺序对用例很重要,需要选择排名感知指标,如MRR@k、MAP@k或NDCG@k。
33. 分词器很重要。 如果在Transformer的泡沫中待得太久,可能已经忘记了除了字节对编码(BPE)之外还有其他分词器。分词器对关键词搜索及其搜索性能也很重要。如果分词器影响基于关键词的搜索性能,它也会影响混合搜索性能。
34. 域外不同于词汇外。 早期的嵌入模型曾经在词汇外术语上失败。如果嵌入模型从未见过或听说过”Labubu”,它只会遇到错误。通过智能分词,未见过的词汇外术语可以被优雅地处理,但问题是它们仍然是域外术语,因此,它们的向量嵌入看起来像是正确的嵌入,但它们是无意义的。
35. 查询优化: 你知道如何学会在Google搜索栏中输入”longest river africa”,而不是”What is the name of the longest river in Africa?”。你已经学会了为关键词搜索优化搜索查询。同样,我们现在需要学习如何为向量搜索优化搜索查询。
36. 向量搜索之后是什么? 首先是基于关键词的搜索。然后,机器学习模型实现了向量搜索。现在,具有推理能力的LLM实现了基于推理的检索。
37. 信息检索现在正火热。 能在这个令人兴奋的领域工作很幸运。虽然研究和使用LLM似乎是现在的酷事,但弄清楚如何为它们提供最佳信息同样令人兴奋。这就是检索领域。
回顾过去两年,Leonie表示自己只是刚刚触及表面,还有很多东西要学。当她加入Weaviate时,向量数据库是热门新事物。
然后是RAG。
现在,我们在谈论”上下文工程”。
但没有改变的是找到最佳信息给LLM以便它能提供最佳答案的重要性。

看完这37条经验,你可能会发现:我们总是急于追求最新最炫的技术,却忘了最简单的往往是最有效的。
BM25排在第一条,不是偶然。
当所有人都在谈论向量数据库有多么强大时,一个在向量数据库公司工作的人却说:「先试试BM25吧。」
这是真的诚实……
更重要的是,这37条经验勾勒出了一个完整的技术演进图景:从关键词搜索到向量搜索,再到基于推理的检索。

技术在进步,但核心问题始终未变:如何找到最相关的信息?
而答案,往往不在于使用最新的技术,而在于选择最合适的工具。
就像Leonie说的:「虽然使用LLM似乎是现在的酷事,但弄清楚如何为它们提供最佳信息同样令人兴奋。」

因为最终,无论技术如何演变,找到正确的信息始终是一切的起点。
原文链接: https://www.leoniemonigatti.com/blog/what_i_learned.html
(文:AGI Hunt)