

想象一下,你在解决一道复杂的几何题时,会自然地在草稿纸上画辅助线来验证思路——这不仅是“看”图,而是“用”图思考。然而,当前的多模态AI(如GPT-4V)大多停留在“静态看图”阶段:先将图像编码为固定特征,再纯文本推理。这导致“语义鸿沟”——视觉世界的丰富细节(如模糊边界、动态交互)被压缩成离散符号,模型在需要迭代视觉分析的任务(如物理模拟或长期规划)中频频失误。

-
论文:Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers -
地址:https://arxiv.org/pdf/2506.23918 -
github:https://github.com/zhaochen0110/Awesome_Think_With_Images (已有400+star啦~)
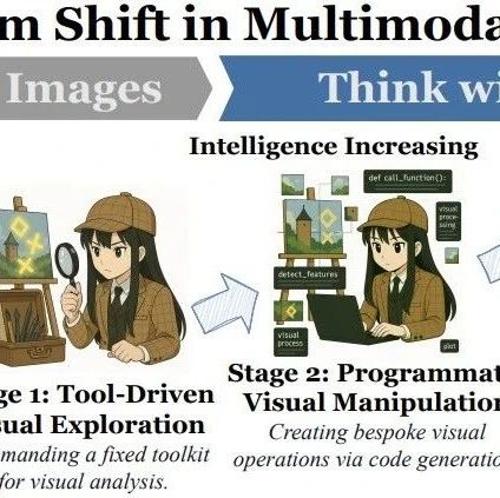
这篇由香港科技大学、微软、UIUC等机构联合发表的综述论文,首次系统性地提出“思考图像”(Thinking with Images)新范式:让AI像人类一样,将图像作为动态“认知画布”,在推理过程中主动查询、修改甚至生成图像作为中间步骤。这不仅是一次技术升级,更是认知模式的革命——从“关于图像的思考”转向“用图像思考”。论文通过三阶段进化框架(工具调用→代码生成→内在想象),结合详实的评估和应用案例,为下一代多模态AI绘制了清晰路线图。以下,我们将深入解读这一变革性研究。
1. 论文背景与动机
传统多模态模型(如基于文本链式思考的CoT方法)虽在问答任务中表现出色,但存在根本缺陷:视觉输入仅作为一次性静态上下文(范式I)。例如,模型看到一张房间照片后,仅靠文本推理“沙发能否放进门”,却无法动态缩放门框区域测量尺寸。这种“语义鸿沟”源于视觉信息的连续性(像素级细节)与语言符号的离散性之间的不匹配,导致模型在需要精细视觉交互的任务中(如机器人避障或科学模拟)表现脆弱。
论文的动机是弥合这一鸿沟。人类认知常以图像为“心智草图板”——解题时画辅助线,规划时模拟场景。受此启发,作者提出“思考图像”范式:图像不再是起点,而是推理过程中的可操作工作空间。这一转变赋予AI三项关键能力:动态感知探索(如放大局部)、结构化视觉推理(如添加几何元素)、目标导向生成规划(如预测未来帧)。其核心价值在于,将视觉从被动输入升级为主动认知工具,推动AI向更鲁棒、类人的多模态智能演进。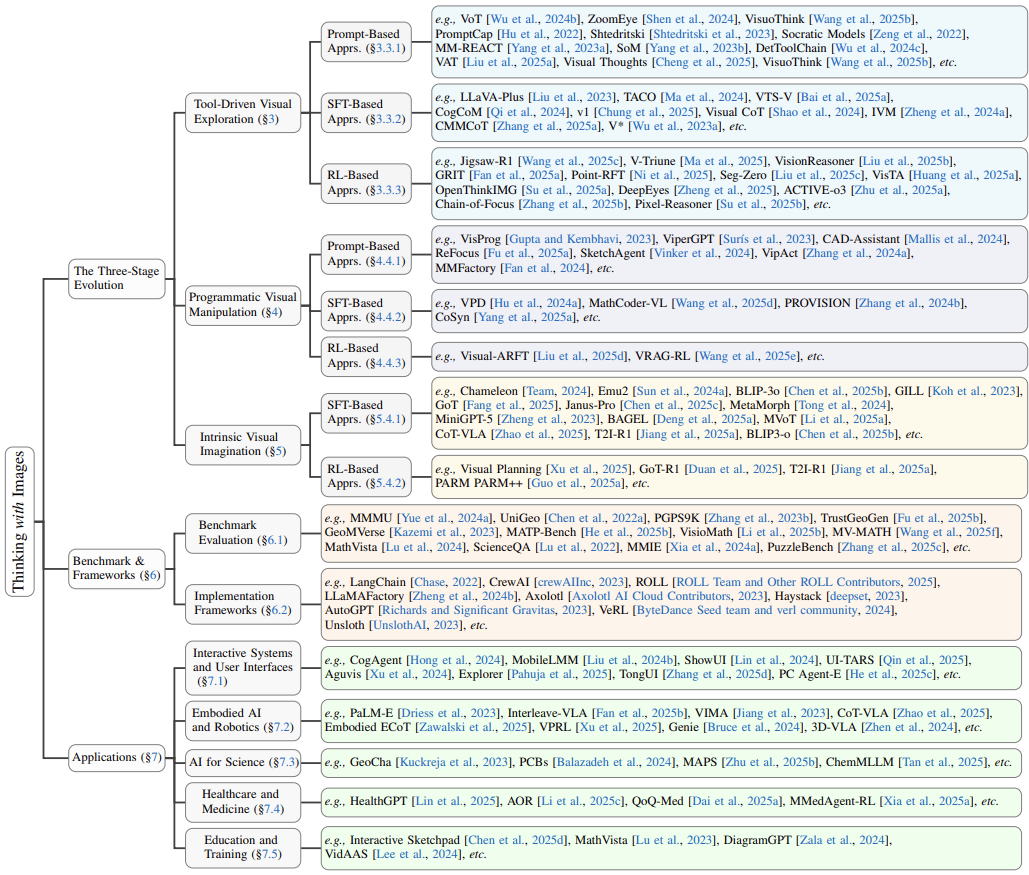
2. 核心范式定义
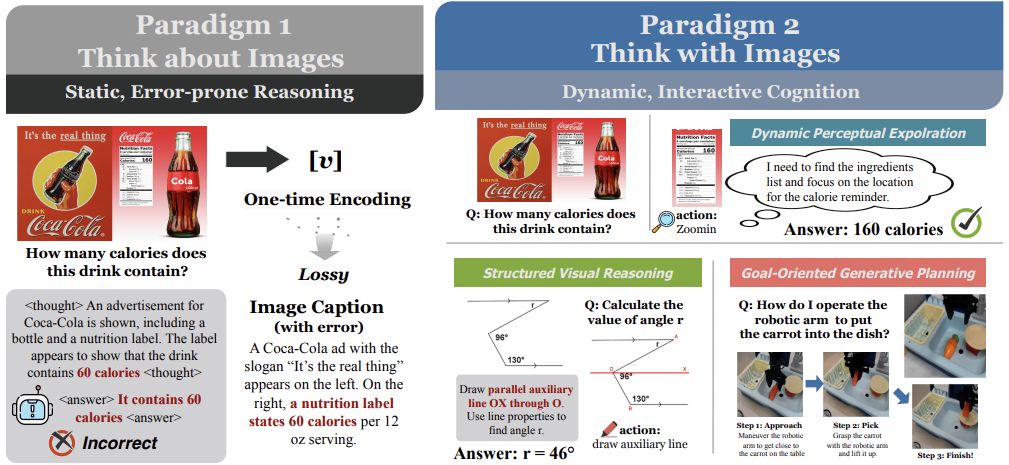 论文严格区分了两种范式:
论文严格区分了两种范式:
-
范式I:思考图像(Thinking about Images)
模型将图像编码为固定特征向量 ,仅通过文本序列生成答案。数学定义为: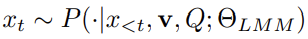 符号解释:
符号解释: -
:图像 通过编码器生成的静态特征。 -
:第 步生成的文本token。
重要性:此公式反映视觉信息的“一次性使用”,限制了迭代分析能力。 -
范式II:思考图像(Thinking with Images)
模型可生成文本或视觉步骤作为中间状态,形成动态多模态历史序列: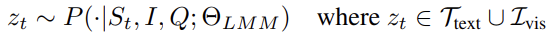 符号解释:
符号解释: -
:包含文本或视觉步骤的推理历史。 -
:视觉产物空间(如外部工具输出、生成图像)。
重要性:此公式允许模型在推理中插入动态视觉步骤(如调用裁剪工具或生成新图),将图像转化为“可操作证据”,是范式突破的核心。
这一转变的本质是认知自主性的提升:模型从依赖静态输入,发展为通过视觉中间步骤验证假设,类似人类“边画边想”的思维模式。
3. 三阶段进化框架
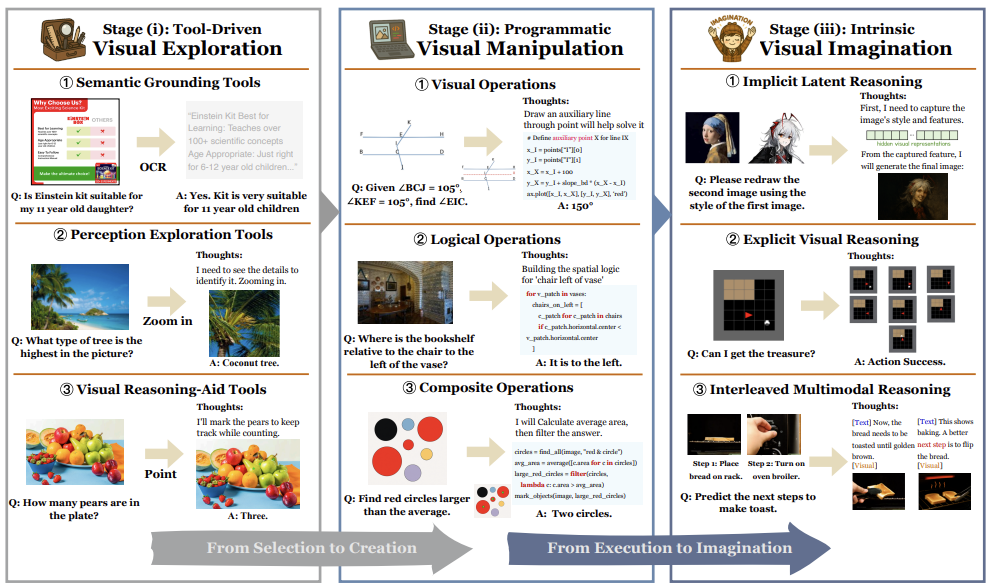
论文将“思考图像”的实现分为三阶段,体现认知自主性的递进。
-
阶段1:工具驱动视觉探索
模型作为“指挥官”,调度预定义工具库(如目标检测器、OCR)。例如,判断家具布局时,调用距离估算工具测量空间。 -
语义基础工具(如OCR):将像素转为符号。 -
感知探索工具(如区域裁剪):聚焦细节。 -
推理辅助工具(如高亮关键区):外化思维。 -
核心机制:生成工具调用指令 ,执行后反馈结果 至状态序列。 -
优势:透明且易调试;局限:工具功能固定,无法解决新问题。 -
工具类型:
-
阶段2:程序化视觉操作
模型升级为“程序员”,生成Python等代码创建定制化视觉操作(如绘制热力图测试家具布局)。 -
视觉操作(如旋转/绘图):直接处理图像。 -
逻辑操作(如循环/条件):嵌入控制流。 -
复合操作(如“找出大于平均面积的红色圆圈”):融合视觉与逻辑。 -
核心机制:输出代码段 ,外部引擎执行后返回修改后的图像或数据。 -
优势:组合灵活性(支持循环/条件分支)、可解释性(代码即推理链);局限:依赖外部执行环境。 -
操作类别:
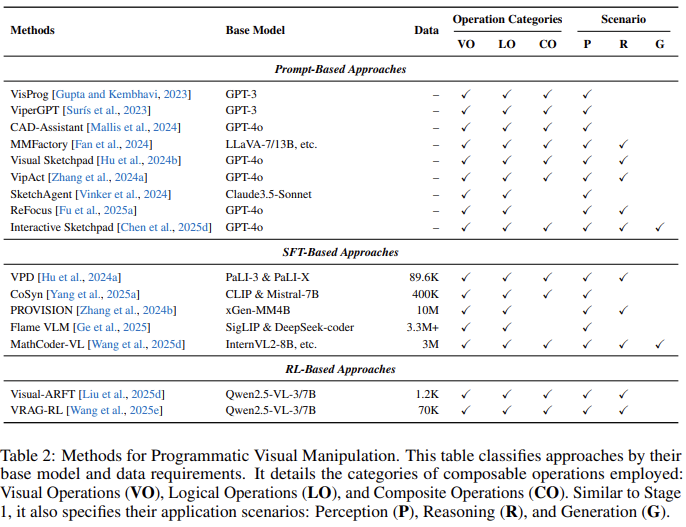
-
阶段3:内在视觉想象
模型成为“思考者”,内部生成图像作为推理步骤(如直接输出沙发摆放后的房间渲染图)。 -
隐式潜在推理(内部特征操作)。 -
显式视觉草图(如添加辅助线)。 -
交错多模态对话(文本与图像交替生成)。 -
核心机制:模型直接生成新图像 作为 ,并反馈至自身进行批判(如检测通道阻塞)。 -
优势:封闭认知循环,无需外部调用;局限:算力成本高。 -
生成思维类型:
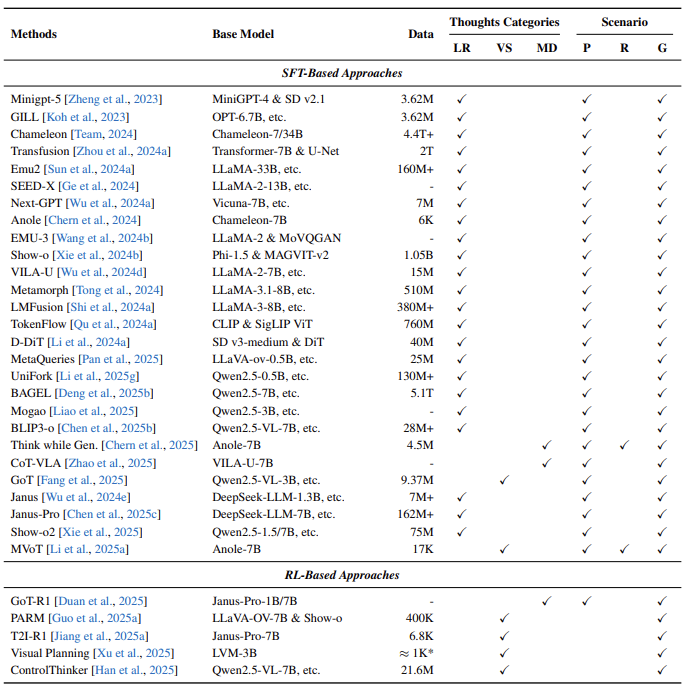
关键洞见:三阶段非严格线性——智能体需按任务选择最优策略(如先用工具测门宽,再模拟布局)。
4. 实施方法与技术细节
不同阶段共享三类实现方法,但侧重点各异:
-
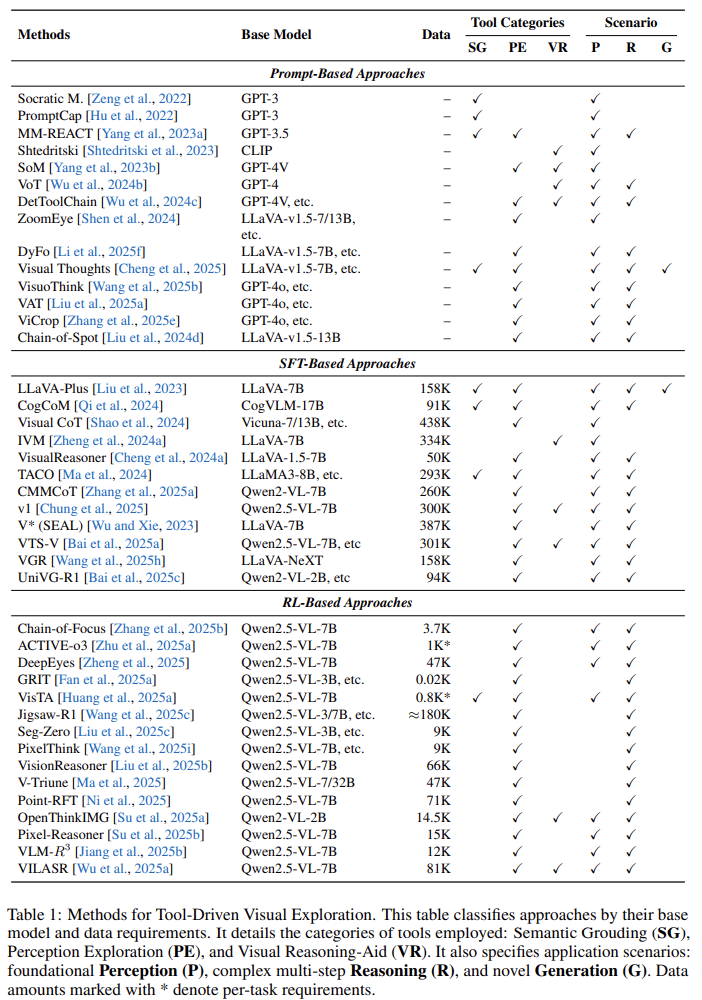
基于提示的方法(零样本)
-
阶段1应用:通过指令协调工具(如MM-REACT用GPT-3调度视觉专家)。 -
阶段2应用:引导代码生成(如VisProg用自然语言生成Python程序)。 -
优势:无需训练;案例:Visual Sketchpad让模型生成几何辅助线图像指导后续推理。 -
基于监督微调(SFT)的方法
-
阶段1应用:训练工具编排能力(如LLaVA-Plus学习“技能库”激活)。 -
阶段2应用:教授程序化逻辑(如VPD将代码执行轨迹转为训练数据)。 -
阶段3应用:对齐文本与图像生成(如Chameleon模型统一自回归目标)。 -
优势:高效学习复杂行为;挑战:需高质量多步推理数据集。 -
基于强化学习(RL)的方法
-
阶段1应用:优化工具选择策略(如OpenThinkIMG训练自适应调用策略)。 -
阶段2应用:通过执行反馈改进代码生成(如Visual-ARFT奖励可运行代码)。 -
阶段3应用:鼓励视觉想象(如PARM模型评估生成图像质量)。 -
优势:自主发现策略;案例:DeepEyes模型通过RL内化“缩放”操作,减少外部依赖。
创新点:RL推动模型从“模仿”到“创造”——例如,阶段2中模型学习生成代码调用阶段1工具,实现跨阶段协同。
5. 评估基准与框架
为验证“思考图像”的有效性,论文系统化评估生态:
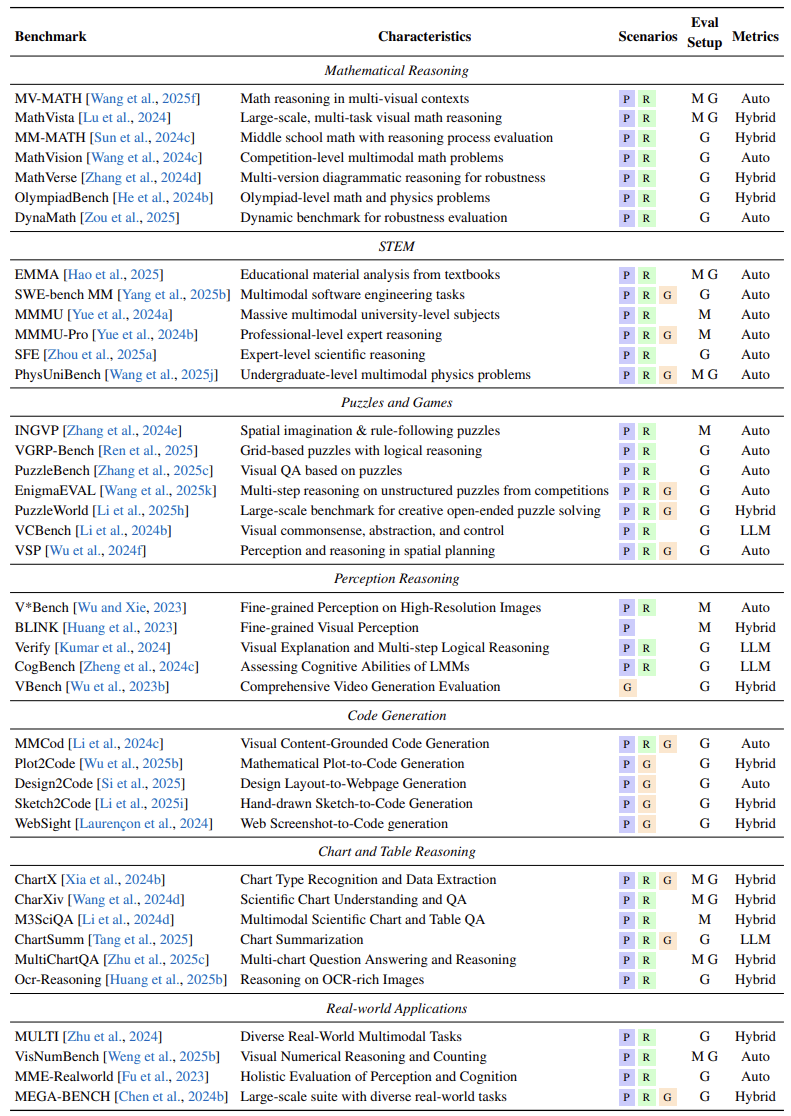
-
评估基准: -
数学推理:MathVista等基准要求模型添加视觉元素解题(如几何辅助线),测试结构化推理能力。 -
STEM与科学:MMMU评测大学级多学科问题,需动态模拟物理过程(如化学反応可视化)。 -
游戏与谜题:PuzzleBench评估长时程规划(如迷宫路径想象)。 -
感知推理:V*Bench聚焦高分辨率细节理解,揭露“幻觉”风险。 -
代码生成:Design2Code测试将UI草图转为网页代码的“视觉反编译”能力。
趋势:从单轮问答转向多步交互评测,强调过程可解释性。 -
实施框架: -
提示框架:LangChain支持工具集成,AutoGen实现代码交互。 -
SFT框架:LLaMAFactory统一微调接口,Unsloth优化训练效率。 -
RL框架:VeRL支持分布式训练,ROOL处理百亿参数模型。
作用:降低实现门槛,如OpenThinkIMG整合RL流程训练工具调用策略。
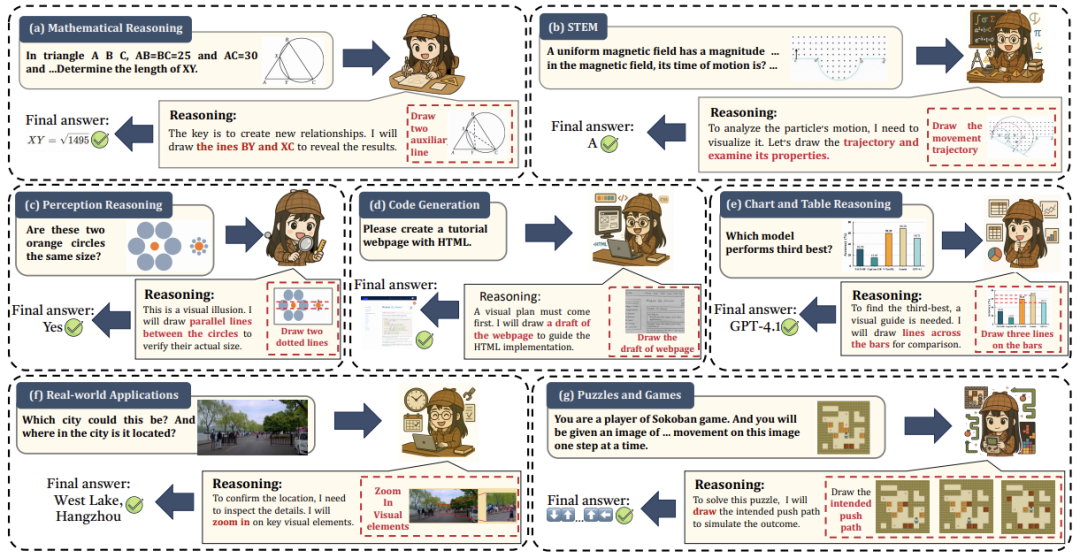
6. 应用场景分析
论文通过案例证明范式的实用价值:
-
交互系统与GUI:模型从依赖HTML转向像素级推理。 -
案例:CogAgent直接解析屏幕像素,指导点击操作;Aguvis仅凭截图训练跨平台控制。 -
关键:视觉链式思考实现多步任务规划(如“登录→搜索→下单”)。 -
具身AI与机器人:视觉规划提升行动可靠性。 -
案例:CoT-VLA模型先预测机器人动作的中间帧图像,再生成指令;VPRL纯视觉模拟导航路径。 -
突破:图像推理优于纯文本在空间任务中——例如,避障成功率提升31%。 -
科学发现:领域定制解决专业挑战。 -
案例:GeoChat分析卫星图像检测地貌变化;物理学模型训练于模拟数据,预测物体运动轨迹。 -
局限:通用模型难理解显微镜图像等专业场景,需针对性微调。 -
医疗诊断:从静态预测到动态推理。 -
案例:HealthGPT生成X光报告时高亮病变区域;病理学模型通过视觉层次学习细胞分析。 -
重点:引入临床工作流模拟(如多代理协作)提升可信度。 -
教育:视觉化辅导增强学习效果。 -
案例:Interactive Sketchpad为学生动态绘制几何证明步骤;VidAAS分析教室视频反馈教学行为。 -
价值:将抽象概念转化为可视交互,降低认知负荷。
7. 挑战与未来方向
尽管前景广阔,论文揭示四大挑战:
-
计算成本:视觉步骤的“token爆炸”问题——单图分解为数千patch,多步推理算力需求倍增。 -
解决方向:开发轻量模块(如潜在空间操作),避免像素级渲染。 -
信息密度:视觉错误引发连锁失真——若模型误聚焦无关区域,后续推理可能“自圆其说”但完全偏离主题。 -
解决方向:引入自校正机制(如代码执行的中间验证)。 -
架构瓶颈:视觉与语言模块分离导致信息损失(如空间细节扁平化)。 -
解决方向:设计统一架构支持直接感知-行动循环。 -
泛化性:单一视觉策略无法覆盖多样任务(如几何需构造性思维,诊断需分析性缩放)。 -
解决方向:元策略学习——模型自主选择适配任务的工具包。
未来前沿:
-
认知效率:让模型动态选择推理深度(如简单任务用文本,复杂任务用视觉模拟)。 -
安全可信:防御恶意视觉论证(如生成虚假“证据链”),开发可审计的推理轨迹。 -
跨模态扩展:从图像到视频/音频的“动态思考”(如预测未观测事件帧)。 -
人机协作:人类引导AI视觉想象(如科学假设共创)。
8. 讨论与展望
论文结尾升华范式意义:
-
与代理框架的关系:
“思考图像”是代理的“认知引擎”——代理提供感知/行动接口,三阶段赋予其智能决策。例如: -
代理用阶段1调度工具探索环境。 -
代理用阶段2编程分析传感器数据。 -
代理用阶段3模拟行动后果。
二者协同实现“感知-思考-行动”闭环。 -
统一视觉思考者蓝图: 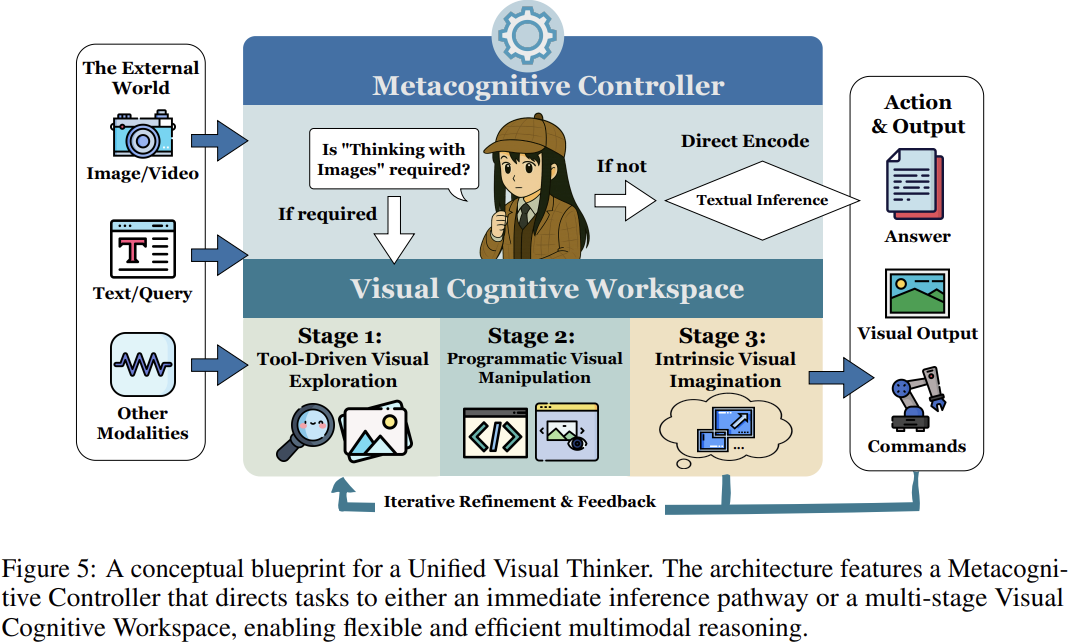 作者提出集成架构:
作者提出集成架构: -
多模态核心:统一处理文本/图像序列。 -
元认知控制器:按任务复杂度分配阶段策略。 -
视觉工作空间:动态切换三阶段模式。 -
感知-行动接口:连接外部世界。
愿景:模型自主选择最优推理路径——如先用工具测尺寸(阶段1),再代码模拟布局(阶段2),最终想象效果(阶段3)。
终极目标:让AI拥有“心智之眼”,将视觉深度融入认知语言,迈向真正通用的多模态智能。
结论
这篇论文开创性地定义了“思考图像”范式,通过三阶段进化框架(工具→代码→想象),系统化解构了多模态AI的认知升级路径。其核心贡献在于:
-
理论奠基:确立视觉作为动态认知工作空间的原则,弥合语义鸿沟。 -
方法整合:跨越提示、SFT、RL三大技术,提供可扩展实现方案。 -
评估体系:构建多领域基准,推动公平量化与比较。 -
应用验证:在GUI控制、机器人规划、医疗诊断等场景证明变革潜力。
研究价值远超技术层面——它重新定义了“推理”的本质:从纯符号演算到视觉-语言交融的类人思维。未来,随着计算效率优化和安全机制完善,这一范式将催化更强大的AI代理:能自主选择视觉策略,模拟物理世界,甚至与人类共创知识。正如作者所展望:“思考图像”不是终点,而是通向多模态通用智能的必经之路。
(文:机器学习算法与自然语言处理)