

大家好,我是歸藏(guizang),今天来讨论一下最近圈子很火的上下文工程概念。
这几天 AI 圈子有个非常有必要也非常热的讨论就是提示工程是不是应该被称为“上下文工程”更加适合。
最早由 Shopify CEO Tobi Lutke 在推特说,他觉得相比提示工程更喜欢“上下文工程”这个术语。
因为这个词可以更加准确的描述岗位所需要的核心技能:需要为 LLM 提供完成任务所需要的所有上下文。

之后 Andrej Karpathy 也发表了意见,“提示”通常让人联想到日常使用的 LLM 聊天机器人中的简短任务描述。
但是在每一个工业级 LLM 应用中,上下文工程是精心艺术和科学地填充上下文窗口,使其包含下一步所需恰到好处的信息。
因为做到这一步需要的不只是提示词这一个东西,还需要任务描述和解释、少量样本、RAG(检索增强生成)、相关的(可能是多模态)数据、工具、状态和历史、以及压缩等信息。
如果信息太少或形式不对,LLM 可能无法获得最佳性能所需的正确上下文。
但如果信息过多或不相关,LLM 的成本可能会上升,性能也可能下降。
所以上下文工程师需要提供恰到好处的信息,而且这需要对 LLM“心理”有一种引导性的直觉。
我认为只有不断的使用和优化提示词和上下文内容对模型的边界足够了解才能形成这种直觉。
同时前几天很火的是否要进行多Agent构建的争论中的两个主体 Cognition 和 Anthropic 都提到了在 AI Agent 构建中上下文管理的重要性。
Cognition 强调说:上下文工程是构建 AI Agent 工程师的“首要任务”。
Anthropic 说:Agent经常需要进行长达数百轮对话的交互,这要求采用精细的上下文管理策略。


那么上下文工程为何如此重要呢?
首先是Cognition 在他们的文章中说过的,不充分的上下文共享可能导致子Agent工作不一致或行动基于冲突的假设。
另外就是刚才说的过长的上下文可能限制LLM回忆事实或遵循指令的能力,导致性能下降。不相关的信息过多也可能降低性能。
调用反馈可能使上下文窗口膨胀,导致成本和延迟增加。比如在语音AIAgent中,延迟是关键指标(目标中位语音到语音延迟800ms),任何增加上下文的步骤都需谨慎。
最后就是最重要的指令遵循(特别是函数调用准确性)对于 Agent 至关重要。即使是顶级模型,在多轮对话中指令遵循性能也会显著下降(如GPT-4o在多轮测试中准确率仅50%)。所以优化上下文长度和准确性使得在多轮 Agent 项目中变得尤为重要。
应该如何优化上下文工程
提示工程的内容我们看的很多了,上面也了解了上下文工程的重要性那么上下文工程的应该如何做呢?
Lance Martin 这个老哥将上下文工程定义为一个伞状学科,涵盖了指令上下文(提示、记忆、少样本示例)、知识上下文(检索、记忆,例如 RAG)、以及操作上下文(通过工具从环境中流动的上下文)
从而提出了一整套的上下文工程的三种常见策略:压缩、持久化和隔离。
首先是压缩上下文:
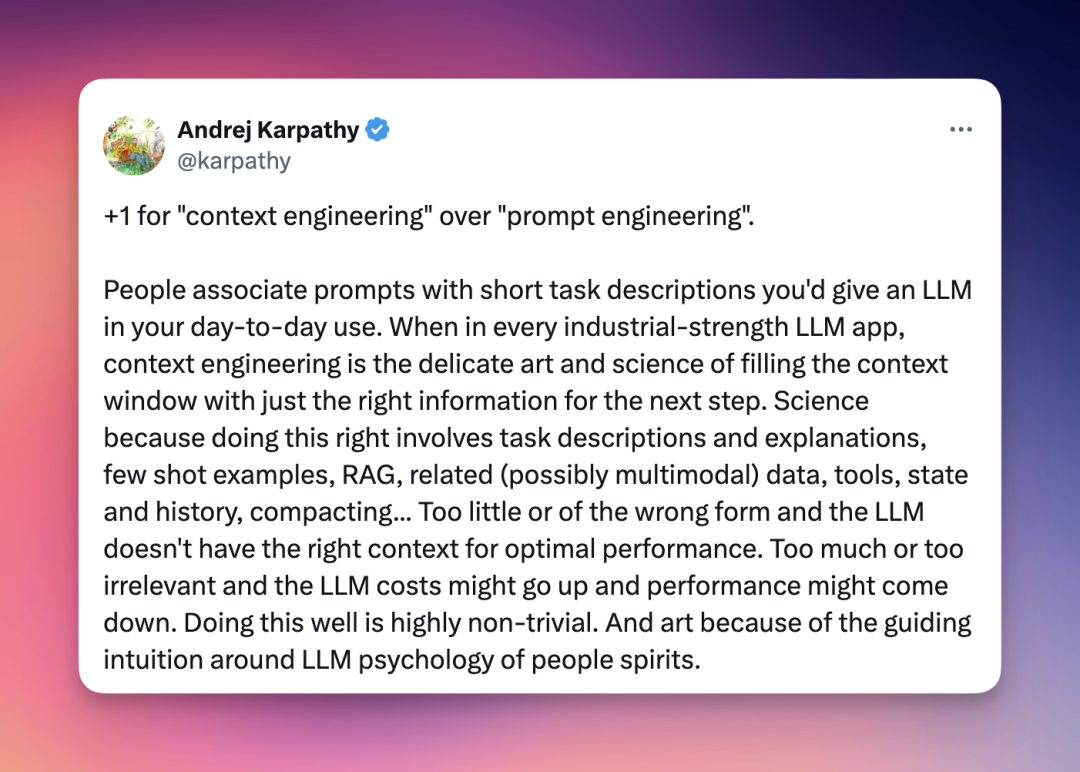
核心目标是在 Agent 每一轮对话中只保留最有价值的Token。
Agent 交互可能涉及数百个回合,并可能包含大量标记的工具调用。所以最主要的方法就是上下文摘要。
比如 Claude Code 就用了这个,当上下文窗口使用量超过 95%时,Claude Code 会自动执行”压缩”操作。Anthropic 的多 Agent 深度研究在完成工作阶段也会生成摘要。
做好上下文摘要其实非常困难,Cognition 甚至在 Devin 中使用了专门的微调模型进行上下文压缩。
接下来是持久化上下文:
核心目标是构建用于随时间存储、保存和检索上下文的系统。
主要措施需要考虑三个部分:上下文存放方式、上下文保存策略和上下文的检索。
上下文存放方式:
文件是存储上下文的一种简单方式。许多主流Agent采用这种方法:Claude Code 使用 CLAUDE.md 格式,Cursor 和 Windsurf 使用规则文件,部分插件(如 Cursor 记忆库)/MCP 服务器则管理着记忆文件集合。
某些Agent需要存储难以用少量文件捕获的信息。例如,我们可能需要存储大量事实和/或关系数据。为此涌现出若干工具,它们展示了常见的处理模式。
Letta、Mem0 和 LangGraph/Mem 存储嵌入式文档。Zep 和 Neo4J 使用知识图谱对事实或关系进行持续/时序索引。
上下文保存策略:
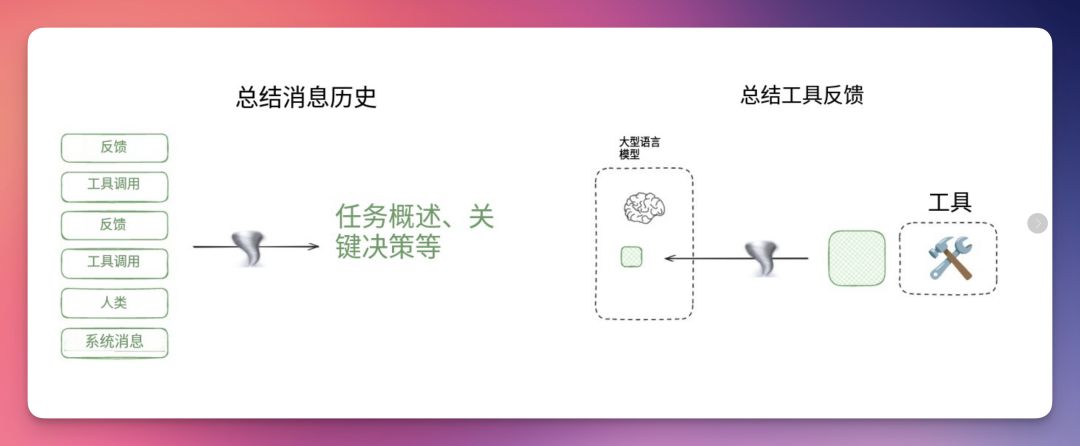
Claude Code 委托用户创建/更新记忆(例如 # 快捷方式)。但在许多情况下,我们希望Agent能自主创建/更新记忆。
Reflexion 论文提出了在每个 Agent 轮次后进行反思并复用这些自生成提示的概念。生成式 Agent 通过综合过往反馈集合来创建记忆摘要。
这些概念已融入 ChatGPT、Cursor 和 Windsurf 等热门产品中,这些产品都具备基于用户与Agent交互自动生成记忆的机制。
上下文的检索:
最简单的方法是将所有记忆直接载入Agent的上下文窗口。例如 Claude Code 会在每次会话开始时读取所有 CLAUDE.md 文件到上下文中。
但当记忆库规模庞大时,选择性检索机制就变得至关重要。存储方式将决定具体采用何种方法(例如基于嵌入向量的搜索或图检索技术)。
实践中这是个深奥的话题。检索过程可能很棘手。
例如,生成式Agent曾根据相似性、时效性和重要性对记忆进行评分。西蒙·威尔逊分享过一个记忆检索出错的案例——GPT-4o 根据他的记忆将位置信息注入到图像中,而这并非用户本意。
糟糕的上下文检索会让用户感觉这个上下文窗口”不属于他们”,也就是说聊着聊着你发现 AI 跑题了,开始说你在另一个聊天窗口聊过的主题。
最后是上下文隔离:
核心目标是在不同Agent或环境间划分上下文的方法。
主要措施需要考虑三个部分:上下文模式 (Context Schema)、多Agent和环境隔离的上下文管理。
上下文模式 (Context Schema):
通常,消息用于构建Agent上下文。工具反馈会被附加到消息列表中。然后在每个Agent轮次将完整列表传递给 LLM。
问题在于,列表可能会因占用大量Token的工具调用而变得臃肿。使用结构化运行时状态(如 Pydantic 模型)来更好地控制 LLM 在每轮Agent对话中看到的内容,避免消息列表膨胀。可将 Token 量大的部分隔离,按需选择性获取。
这样,你就能更好地控制在每个Agent回合中 LLM 所看到的内容。
例如,在深度研究Agent的一个版本中,模式同时包含 messages 和 sections 。 messages 会在每个回合传递给 LLM,但作者会将占用大量 token 的部分隔离在 sections 中,并选择性获取。
多Agent:
一种流行的方法是将上下文分散到子Agent中。OpenAI Swarm 库的开发动机就是”关注点分离”,即一组Agent可以处理子任务,每个Agent都有自己的指令和上下文窗口。
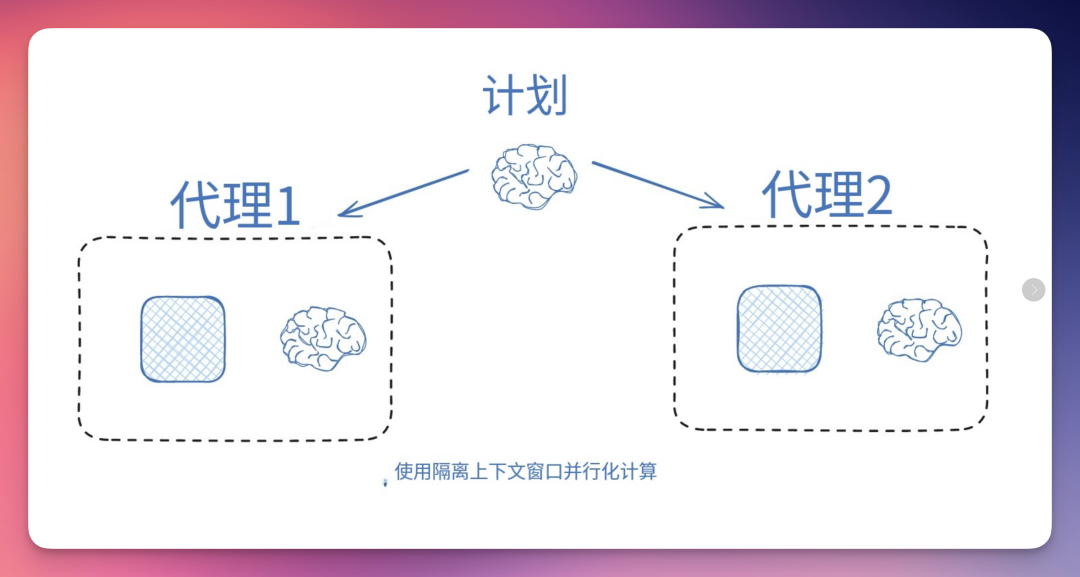
Anthropic 的多Agent研究为此提供了有力证明:采用隔离上下文的多Agent比单Agent性能高出 90.2%,这主要归功于 token 使用效率的提高。
多Agent系统存在诸多问题,包括Token消耗过高(例如比单次对话多消耗 15 倍Token)、子Agent规划需要精心设计提示与上下文环境,以及子Agent间的协调难题。基于这些原因,Cognition 团队不推荐采用多Agent架构。
解决这一问题的一种方法是确保任务可并行化。关键在于 Anthropic 的深度研究多Agent系统将并行化应用于研究过程。这比写作任务更容易实现,因为写作需要报告各部分之间紧密衔接以确保整体流畅性。
环境隔离的上下文管理:
HuggingFace 的深度研究Agent是上下文隔离的另一个优秀范例。大多数Agent使用工具调用 API,这些 API 返回可传递给工具(如搜索 API)的 JSON 对象(参数)以获取工具反馈(如搜索结果)。
HuggingFace 采用 CodeAgent 架构,该Agent输出可执行工具的代码。代码在沙箱环境中运行,并将从代码执行中筛选出的工具反馈传回给 LLM。
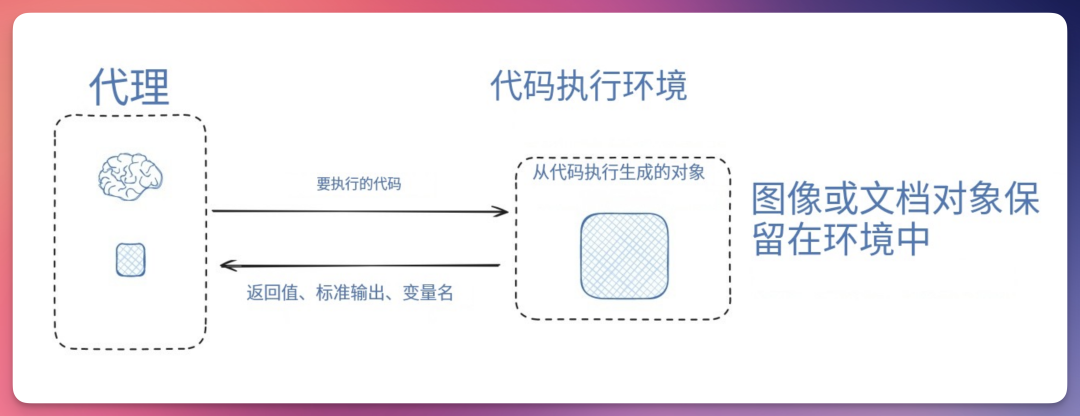
沙盒环境会存储执行过程中生成的对象(如图片),使其与 LLM 的上下文窗口隔离,但Agent仍能通过变量后续引用这些对象。
一些实践经验
构建智能Agent的通用原则仍处于萌芽阶段。模型迭代速度极快,而”苦涩教训”警示我们:应避免设计那些会随着 LLMs 进化而失效的上下文工程方案,Lance Martin 也提出了一些以前的经验和教训。
- 工具先行:始终优先关注数据。构建Agent时务必建立Token追踪机制。这为任何上下文工程工作奠定了基础。
- 思考Agent状态:Anthropic 提出要”像你的Agent一样思考”。实现方式之一是梳理Agent在运行时需要收集和使用的信息。明确定义的状态模式能有效控制Agent运行过程中暴露给 LLM 的内容。
- 在工具边界处压缩:如有需要,工具边界是天然适合添加压缩的位置。例如,可通过简单提示的小型 LLM 对Token密集的工具调用输出进行摘要。
- 从简单的记忆功能开始:记忆是实现Agent个性化的有效手段,但正确实现可能颇具挑战。通常采用基于文件的简易记忆系统,追踪一组特定的Agent偏好参数,这些参数会随时间推移不断保存和优化。每次Agent运行时,都会将这些偏好参数加载至上下文环境中。
- 针对可并行化任务考虑多Agent方案:Agent间通信技术尚处早期阶段,协调多Agent团队仍存在困难。但这并不意味着应该放弃多Agent构想。正如 Anthropic 多Agent研究员的案例所示,当任务能够轻松实现并行化且子Agent间无需严格协调时,就应当考虑采用多Agent架构。
看了这么多内容之后我们发现上下文管理在构建健壮、可靠AIAgent中非常的重要基本处于核心地位,
同时上下文工程是个平衡的艺术,由于上下文长度的限制(虽然在越来越长),我们需要在性能、成本和准确性之间取得平衡。
我们需要在提示与指令、文档或外部数据(例如 RAG)、任何状态、工具调用、结果或其他历史记录、相关但独立的历史/对话(记忆)中的任何过往消息或事件、应输出何种结构化数据的指令都进行优化。
上下文就是一切,LLMs 是将输入转化为输出的无状态函数。要获得最佳输出,就必须提供最佳输入。
如果你能构建良好的语境,并懂得如何清晰表达需求,就会得到出色的回应。
写作不易希望可以获得你的点赞👍和小心心🩷,谢谢各位!
参考信息:
https://x.com/karpathy/status/1937902205765607626
https://x.com/tobi/status/1935533422589399127
https://rlancemartin.github.io/2025/06/23/context_engineering/
https://x.com/hwchase17/status/1937648042985030145
https://cognition.ai/blog/dont-build-multi-agents
https://www.anthropic.com/engineering/built-multi-agent-research-system
(文:归藏的AI工具箱)